Es posible que haya oído hablar del término "conmutación por error" en el contexto de la replicación de MySQL. Tal vez te preguntaste qué es cuando estás comenzando tu aventura con las bases de datos. ¿Quizás sabe qué es pero no está seguro de los posibles problemas relacionados con él y cómo se pueden resolver?
En esta publicación de blog, intentaremos brindarle una introducción al manejo de conmutación por error en MySQL y MariaDB.
Discutiremos qué es la conmutación por error, por qué es inevitable, cuál es la diferencia entre conmutación por error y conmutación. Discutiremos el proceso de conmutación por error en la forma más genérica. También tocaremos un poco los diferentes problemas con los que tendrá que lidiar en relación con el proceso de conmutación por error.
¿Qué significa "conmutación por error"?
La replicación de MySQL es un colectivo de nodos, cada uno de ellos puede cumplir una función a la vez. Puede convertirse en un maestro o una réplica. Solo hay un nodo maestro en un momento dado. Este nodo recibe tráfico de escritura y replica las escrituras en sus réplicas.
Como puede imaginar, al ser un único punto de entrada para los datos en el clúster de replicación, el nodo principal es muy importante. ¿Qué pasaría si fallara y dejara de estar disponible?
Esta es una condición bastante grave para un clúster de replicación. No puede aceptar ninguna escritura en un momento dado. Como es de esperar, una de las réplicas tendrá que hacerse cargo de las tareas del maestro y comenzar a aceptar escrituras. Es posible que el resto de la topología de replicación también deba cambiar:las réplicas restantes deben cambiar su maestro del nodo anterior que falló al recién elegido. Este proceso de "promover" una réplica para que se convierta en un maestro después de que el antiguo maestro haya fallado se denomina "conmutación por error".
Por otro lado, el "cambio" ocurre cuando el usuario activa la promoción de la réplica. Un nuevo maestro se promociona desde una réplica señalada por el usuario y el antiguo maestro, por lo general, se convierte en una réplica del nuevo maestro.
La diferencia más importante entre "conmutación por error" y "conmutación" es el estado del antiguo maestro. Cuando se realiza una conmutación por error, el antiguo maestro, de alguna manera, no es accesible. Puede haberse bloqueado, puede haber sufrido una partición de red. No se puede usar en un momento dado y su estado es, típicamente, desconocido.
Por otro lado, cuando se realiza un cambio, el antiguo maestro está vivo y bien. Esto tiene graves consecuencias. Si no se puede acceder a un maestro, puede significar que algunos de los datos aún no se han enviado a los esclavos (a menos que se haya usado una replicación semisincrónica). Algunos de los datos pueden haber sido dañados o enviados parcialmente.
Existen mecanismos para evitar la propagación de tales corrupciones en los esclavos, pero el punto es que algunos de los datos pueden perderse en el proceso. Por otro lado, mientras se realiza un cambio, el antiguo maestro está disponible y se mantiene la consistencia de los datos.
Proceso de conmutación por error
Pasemos un tiempo discutiendo cómo es exactamente el proceso de conmutación por error.
Se detecta un bloqueo maestro
Para empezar, un maestro debe bloquearse antes de que se realice la conmutación por error. Una vez que no está disponible, se activa una conmutación por error. Hasta ahora, parece sencillo, pero la verdad es que ya estamos en terreno resbaladizo.
En primer lugar, ¿cómo se prueba la salud del maestro? ¿Se prueba desde una ubicación o se distribuyen las pruebas? ¿El software de administración de conmutación por error solo intenta conectarse al maestro o implementa verificaciones más avanzadas antes de que se declare la falla del maestro?
Imaginemos la siguiente topología:
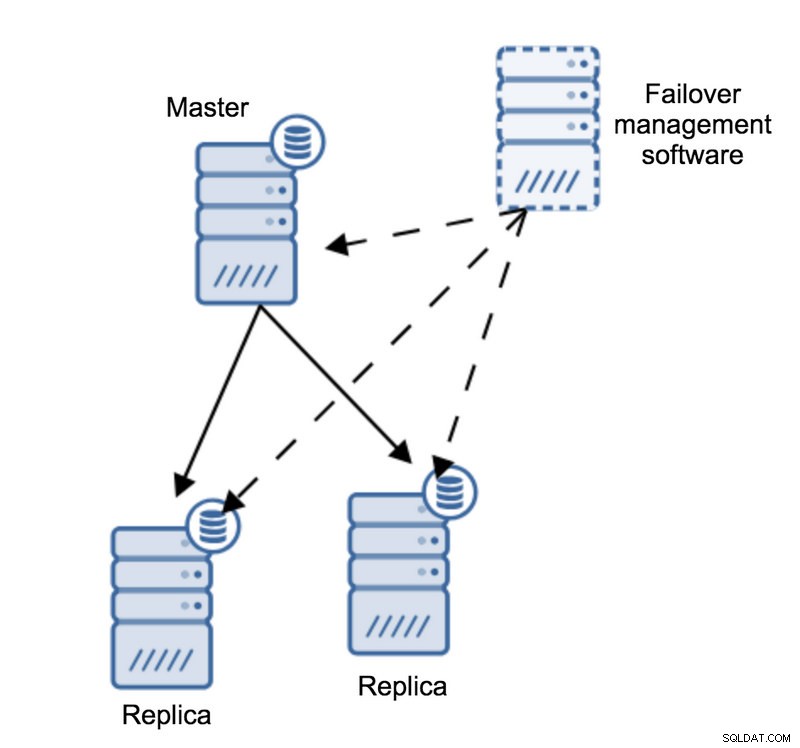
Tenemos un maestro y dos réplicas. También tenemos un software de gestión de conmutación por error ubicado en algún host externo. ¿Qué sucedería si fallara una conexión de red entre el host con el software de conmutación por error y el maestro?
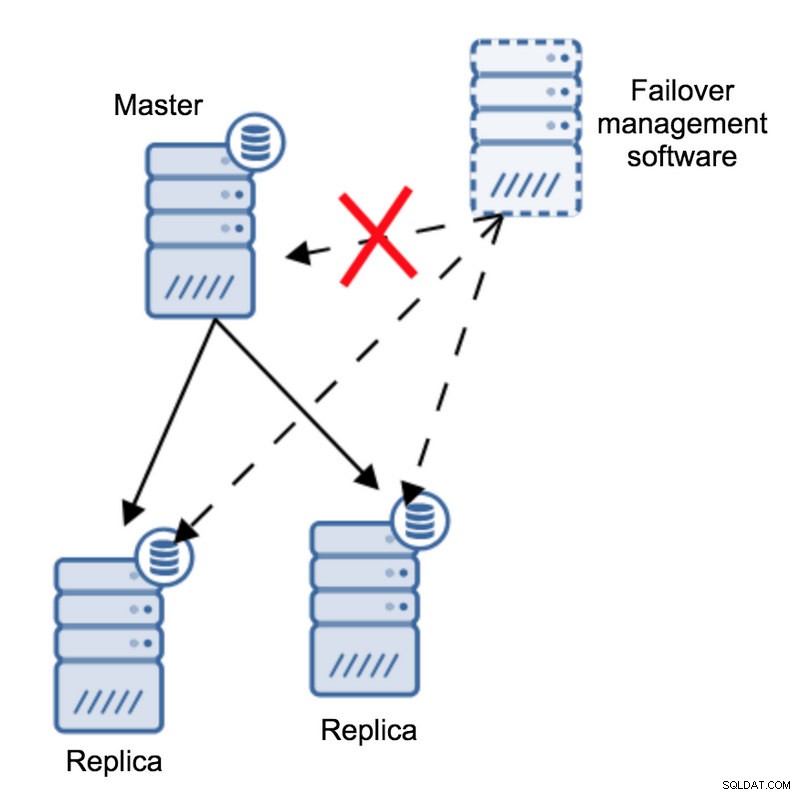
De acuerdo con el software de administración de conmutación por error, el maestro se bloqueó:no hay conectividad con él. Aún así, la replicación en sí está funcionando bien. Lo que debería suceder aquí es que el software de administración de conmutación por error intentaría conectarse a las réplicas y ver cuál es su punto de vista.
¿Se quejan de una replicación rota o están replicando felizmente?
Las cosas pueden volverse aún más complejas. ¿Qué pasaría si agregáramos un proxy (o un conjunto de proxies)? Se utilizará para enrutar el tráfico:escribe en el maestro y lee en las réplicas. ¿Qué pasa si un proxy no puede acceder al maestro? ¿Qué pasa si ninguno de los proxies puede acceder al maestro?
Esto significa que la aplicación no puede funcionar en esas condiciones. ¿Debería activarse la conmutación por error (en realidad, sería más una conmutación ya que el maestro está técnicamente vivo)?
Técnicamente, el maestro está vivo pero la aplicación no puede usarlo. Aquí, la lógica de negocios tiene que entrar y se tiene que tomar una decisión.
Evitar que el viejo maestro se escape
No importa cómo y por qué, si se decide promocionar una de las réplicas para que se convierta en un nuevo maestro, el antiguo maestro debe detenerse e, idealmente, no debería poder comenzar de nuevo.
Cómo se puede lograr esto depende de los detalles del entorno particular; por lo tanto, esta parte del proceso de conmutación por error suele reforzarse con scripts externos integrados en el proceso de conmutación por error a través de diferentes ganchos.
Esos scripts pueden diseñarse para usar las herramientas disponibles en el entorno particular para detener al antiguo maestro. Puede ser una llamada CLI o API que detenga una VM; puede ser un código de shell que ejecuta comandos a través de algún tipo de dispositivo de "gestión de luces apagadas"; puede ser un script que envía trampas SNMP a la Unidad de distribución de energía que desactiva las tomas de corriente que usa el maestro anterior (sin energía eléctrica, podemos estar seguros de que no volverá a comenzar).
Si un software de administración de conmutación por error es parte de un producto más complejo, que también maneja la recuperación de nodos (como es el caso de ClusterControl), el antiguo maestro puede marcarse como excluido de las rutinas de recuperación.
Quizás se pregunte por qué es tan importante evitar que el antiguo maestro vuelva a estar disponible.
El problema principal es que en las configuraciones de replicación, solo se puede usar un nodo para escrituras. Por lo general, se asegura de eso habilitando una variable de solo lectura (y super_solo lectura, si corresponde) en todas las réplicas y manteniéndola deshabilitada solo en el maestro.
Una vez que se promueve un nuevo maestro, tendrá deshabilitado read_only. El problema es que, si el antiguo maestro no está disponible, no podemos volver a cambiarlo a read_only=1. Si MySQL o un host fallan, esto no es un gran problema, ya que las buenas prácticas son tener my.cnf configurado con esa configuración para que, una vez que se inicie MySQL, siempre se inicie en modo de solo lectura.
El problema se muestra cuando no se trata de un bloqueo sino de un problema de red. El antiguo maestro todavía se está ejecutando con read_only deshabilitado, simplemente no está disponible. Cuando las redes converjan, terminará con dos nodos grabables. Esto puede o no ser un problema. Algunos de los servidores proxy utilizan la configuración de solo lectura como indicador de si un nodo es un maestro o una réplica. Dos maestros que aparecen en el momento dado pueden resultar en un gran problema ya que los datos se escriben en ambos hosts, pero las réplicas obtienen solo la mitad del tráfico de escritura (la parte que llega al nuevo maestro).
A veces se trata de configuraciones codificadas en algunos de los scripts que están configurados para conectarse solo a un host determinado. Normalmente fallarían y alguien notaría que el maestro ha cambiado.
Con el antiguo maestro disponible, felizmente se conectarán a él y surgirán discrepancias de datos. Como puede ver, asegurarse de que el antiguo maestro no se inicie es un elemento de alta prioridad.
Decidir sobre un candidato a maestro
El viejo maestro está caído y no regresará de su tumba, ahora es el momento de decidir qué host debemos usar como nuevo maestro. Por lo general, hay más de una réplica para elegir, por lo que se debe tomar una decisión. Hay muchas razones por las que una réplica puede elegirse sobre otra, por lo que se deben realizar comprobaciones.
Listas blancas y listas negras
Para empezar, un equipo que administra bases de datos puede tener sus razones para elegir una réplica sobre otra al decidir sobre un candidato maestro. Tal vez esté usando un hardware más débil o tenga asignada una tarea en particular (esa réplica ejecuta copias de seguridad, consultas analíticas, los desarrolladores tienen acceso y ejecutan consultas personalizadas y hechas a mano). Tal vez sea una réplica de prueba donde una nueva versión se somete a pruebas de aceptación antes de continuar con la actualización. La mayoría del software de administración de conmutación por error admite listas blancas y negras, que se pueden utilizar para definir con precisión qué réplicas deben o no usarse como candidatas maestras.
Replicación semisincrónica
Una configuración de replicación puede ser una combinación de réplicas asincrónicas y semisincrónicas. Hay una gran diferencia entre ellos:se garantiza que la réplica semisincrónica contiene todos los eventos del maestro. Es posible que una réplica asíncrona no haya recibido todos los datos, por lo que la conmutación por error puede provocar la pérdida de datos. Preferiríamos promover las réplicas semisincrónicas.
Retraso de replicación
Aunque una réplica semisincrónica contendrá todos los eventos, es posible que esos eventos residan únicamente en los registros de retransmisión. Con mucho tráfico, todas las réplicas, sin importar si son semisincronizadas o asíncronas, pueden retrasarse.
El problema con el retraso de la replicación es que, cuando promueve una réplica, debe restablecer la configuración de la replicación para que no intente conectarse al antiguo maestro. Esto también eliminará todos los registros de retransmisión, incluso si aún no se han aplicado, lo que provoca la pérdida de datos.
Incluso si no restablece la configuración de replicación, aún no puede abrir un nuevo maestro a las conexiones si no ha aplicado todos los eventos de su registro de retransmisión. De lo contrario, correrá el riesgo de que las nuevas consultas afecten las transacciones del registro de retransmisión, provocando todo tipo de problemas (por ejemplo, una aplicación puede eliminar algunas filas a las que acceden las transacciones del registro de retransmisión).
Tomando todo esto en consideración, la única opción segura es esperar a que se aplique el registro de retransmisión. Aún así, puede tomar un tiempo si la réplica se retrasó mucho. Se deben tomar decisiones sobre qué réplica sería una mejor copia maestra:asíncrona, pero con un pequeño retraso o semisincrónica, pero con un retraso que requeriría una cantidad significativa de tiempo para aplicar.
Transacciones erroneas
Aunque no se debe escribir en las réplicas, aún podría suceder que alguien (o algo) haya escrito en ellas.
Es posible que haya sido solo una forma de transacción única en el pasado, pero aún puede tener un efecto grave en la capacidad de realizar una conmutación por error. El problema está estrictamente relacionado con el ID de transacción global (GTID), una función que asigna un ID distinto a cada transacción ejecutada en un nodo MySQL determinado.
Hoy en día es una configuración bastante popular ya que brinda grandes niveles de flexibilidad y permite un mejor rendimiento (con réplicas de subprocesos múltiples).
El problema es que, mientras se vuelve a vincular a un nuevo maestro, la replicación de GTID requiere que todos los eventos de ese maestro (que no se hayan ejecutado en la réplica) se repliquen en la réplica.
Consideremos el siguiente escenario:en algún momento en el pasado, ocurrió una escritura en una réplica. Fue hace mucho tiempo y este evento se eliminó de los registros binarios de la réplica. En algún momento, un maestro falló y la réplica se designó como un nuevo maestro. Todas las réplicas restantes se esclavizarán del nuevo maestro. Le preguntarán sobre las transacciones ejecutadas en el nuevo maestro. Responderá con una lista de GTID que provienen del maestro anterior y el GTID único relacionado con esa escritura anterior. Los GTID del antiguo maestro no son un problema, ya que todas las réplicas restantes contienen al menos la mayoría (si no todas) y todos los eventos faltantes deben ser lo suficientemente recientes como para estar disponibles en los registros binarios del nuevo maestro.
En el peor de los casos, algunos eventos faltantes se leerán de los registros binarios y se transferirán a las réplicas. El problema es con esa escritura anterior:sucedió solo en un maestro nuevo, mientras que todavía era una réplica, por lo tanto, no existe en los hosts restantes. Es un evento antiguo, por lo que no hay forma de recuperarlo de los registros binarios. Como resultado, ninguna de las réplicas podrá esclavizar al nuevo maestro. La única solución aquí es realizar una acción manual e inyectar un evento vacío con ese GTID problemático en todas las réplicas. También significará que, dependiendo de lo que suceda, es posible que las réplicas no estén sincronizadas con el nuevo maestro.
Como puede ver, es muy importante realizar un seguimiento de las transacciones erráticas y determinar si es seguro promocionar una réplica dada para que se convierta en un nuevo maestro. Si contiene transacciones erróneas, puede que no sea la mejor opción.
Manejo de conmutación por error para la aplicación
Es crucial tener en cuenta que el interruptor maestro, forzado o no, tiene un efecto en toda la topología. Las escrituras deben redirigirse a un nuevo nodo. Esto se puede hacer de varias maneras y es fundamental garantizar que este cambio sea lo más transparente posible para la aplicación. En esta sección, veremos algunos de los ejemplos de cómo la conmutación por error se puede hacer transparente para la aplicación.
DNS
Una de las formas en que una aplicación puede apuntar a un maestro es mediante la utilización de entradas DNS. Con un TTL bajo, es posible cambiar la dirección IP a la que apunta una entrada de DNS como "master.dc1.example.com". Dicho cambio se puede realizar a través de scripts externos ejecutados durante el proceso de conmutación por error.
Descubrimiento de servicios
Herramientas como Consul o etc.d también se pueden usar para dirigir el tráfico a una ubicación correcta. Dichas herramientas pueden contener información de que la IP del maestro actual está configurada en algún valor. Algunos de ellos también brindan la capacidad de usar búsquedas de nombres de host para apuntar a una IP correcta. Una vez más, las entradas en las herramientas de detección de servicios deben mantenerse y una de las formas de hacerlo es realizar esos cambios durante el proceso de conmutación por error, utilizando ganchos ejecutados en diferentes etapas de la conmutación por error.
Proxy
Los proxies también se pueden usar como una fuente de verdad sobre la topología. En términos generales, no importa cómo descubran la topología (puede ser un proceso automático o el proxy debe reconfigurarse cuando cambia la topología), deben contener el estado actual de la cadena de replicación, ya que de lo contrario no podrían enrutar las consultas correctamente.
El enfoque de usar un proxy como fuente de verdad puede ser bastante común junto con el enfoque de ubicar proxies en hosts de aplicaciones. Existen numerosas ventajas en la ubicación conjunta de servidores proxy y web:comunicación rápida y segura mediante un socket Unix, mantener una capa de almacenamiento en caché (ya que algunos de los servidores proxy, como ProxySQL, también pueden realizar el almacenamiento en caché) cerca de la aplicación. En tal caso, tiene sentido que la aplicación simplemente se conecte al proxy y asuma que enrutará las consultas correctamente.
Conmutación por error en ClusterControl
ClusterControl aplica las mejores prácticas de la industria para asegurarse de que el proceso de conmutación por error se realice correctamente. También garantiza que el proceso sea seguro:la configuración predeterminada está diseñada para cancelar la conmutación por error si se detectan posibles problemas. El usuario puede anular esas configuraciones si desea priorizar la conmutación por error sobre la seguridad de los datos.
Una vez que ClusterControl detecta una falla maestra, se inicia un proceso de conmutación por error y se ejecuta inmediatamente un primer gancho de conmutación por error:

A continuación, se prueba la disponibilidad del maestro.

ClusterControl realiza pruebas exhaustivas para asegurarse de que el maestro no esté disponible. Este comportamiento está habilitado por defecto y es administrado por la siguiente variable:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Como siguiente paso, ClusterControl se asegura de que el antiguo maestro esté inactivo y, de no ser así, que ClusterControl no intentará recuperarlo:

El siguiente paso es determinar qué host se puede usar como candidato maestro. ClusterControl comprueba si se ha definido una lista blanca o una lista negra.
Puede hacerlo usando las siguientes variables en el archivo de configuración cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.También es posible configurar ClusterControl para buscar diferencias en los filtros de registros binarios en todas las réplicas. Se puede hacer usando la variable replication_check_binlog_filtration_bf_failover. De forma predeterminada, esas comprobaciones están deshabilitadas. ClusterControl también verifica que no haya transacciones erráticas que puedan causar problemas.

También puede pedirle a ClusterControl que reconstruya automáticamente las réplicas que no pueden replicarse desde el nuevo maestro utilizando la siguiente configuración en el archivo de configuración de cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Luego se ejecuta un segundo script:se define en la configuración replication_pre_failover_script. A continuación, un candidato se somete a un proceso de preparación.


ClusterControl espera a que se apliquen los registros de rehacer (asegurándose de que la pérdida de datos sea mínima). También comprueba si hay otras transacciones disponibles en las réplicas restantes que no se hayan aplicado al candidato principal. Ambos comportamientos pueden ser controlados por el usuario, usando las siguientes configuraciones en el archivo de configuración cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Como puede ver, puede forzar una conmutación por error aunque no se hayan aplicado todos los eventos del registro de rehacer; permite al usuario decidir qué tiene mayor prioridad:coherencia de datos o velocidad de conmutación por error.


Finalmente, se elige el maestro y se ejecuta el último script (un script que se puede definir como replication_post_failover_script.
Si aún no has probado ClusterControl, te animo a que lo descargues (es gratis) y lo pruebes.
Detección maestra en ClusterControl
ClusterControl le brinda la capacidad de implementar una pila completa de alta disponibilidad, incluidas las capas de base de datos y proxy. El descubrimiento de maestros es siempre uno de los temas a tratar.
¿Cómo funciona en ClusterControl?
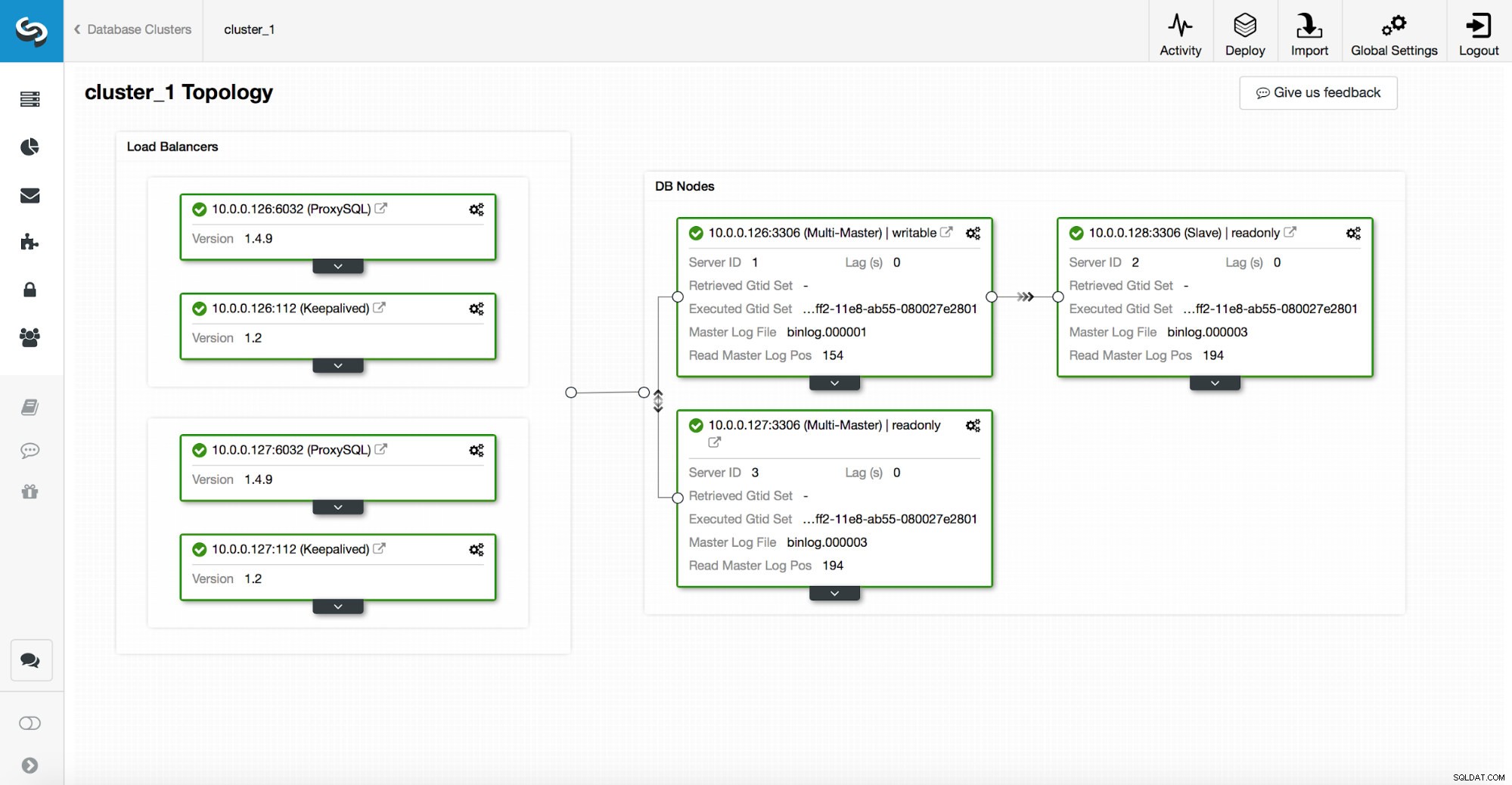
Una pila de alta disponibilidad, implementada a través de ClusterControl, consta de tres piezas:
- capa de base de datos
- capa de proxy que puede ser HAProxy o ProxySQL
- capa de mantenimiento, que, con el uso de IP virtual, garantiza una alta disponibilidad de la capa de proxy
Los proxies se basan en variables de solo lectura en los nodos.
Como puede ver en la captura de pantalla anterior, solo un nodo en la topología está marcado como "escribible". Este es el maestro y este es el único nodo que recibirá escrituras.
Un proxy (en este ejemplo, ProxySQL) monitoreará esta variable y se reconfigurará automáticamente.
En el otro lado de esa ecuación, ClusterControl se encarga de los cambios de topología:conmutación por error y conmutación. Hará los cambios necesarios en el valor de solo lectura para reflejar el estado de la topología después del cambio. Si se promueve un nuevo maestro, se convertirá en el único nodo grabable. Si se elige un maestro después de la conmutación por error, tendrá deshabilitado read_only.
Además de la capa de proxy, se implementa keepalived. Despliega un VIP y monitorea el estado de los nodos proxy subyacentes. Puntos VIP a un nodo proxy en un momento dado. Si este nodo deja de funcionar, la IP virtual se redirige a otro nodo, lo que garantiza que el tráfico dirigido a VIP llegará a un nodo proxy en buen estado.
En resumen, una aplicación se conecta a la base de datos mediante una dirección IP virtual. Esta IP apunta a uno de los proxies. Los proxies redirigen el tráfico de acuerdo con la estructura de la topología. La información sobre la topología se deriva del estado de solo lectura. Esta variable es administrada por ClusterControl y se establece en función de los cambios de topología solicitados por el usuario o ClusterControl realizados automáticamente.