En la primera parte de este blog, cubrimos un tutorial de implementación de MySQL InnoDB Cluster con un ejemplo de cómo las aplicaciones pueden conectarse al clúster a través de un puerto de lectura/escritura dedicado.
En este tutorial de operaciones, mostraremos ejemplos sobre cómo monitorear, administrar y escalar el clúster de InnoDB como parte de las operaciones de mantenimiento del clúster en curso. Usaremos el mismo clúster que implementamos en la primera parte del blog. El siguiente diagrama muestra nuestra arquitectura:
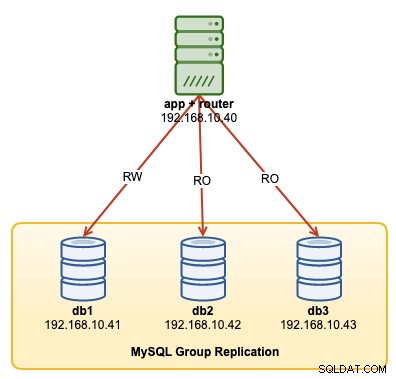
Tenemos una replicación de grupo MySQL de tres nodos y un servidor de aplicaciones ejecutándose con Enrutador MySQL. Todos los servidores se ejecutan en Ubuntu 18.04 Bionic.
Opciones de comandos de clúster de MySQL InnoDB
Antes de continuar con algunos ejemplos y explicaciones, es bueno saber que puede obtener una explicación de cada función en el clúster de MySQL para el componente de clúster mediante el uso de la función de ayuda(), como se muestra a continuación:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()La siguiente lista muestra las funciones disponibles en MySQL Shell 8.0.18, para MySQL Community Server 8.0.18:
- addInstance(instancia[, opciones]):agrega una instancia al clúster.
- checkInstanceState(instance)- Verifica el estado de gtid de la instancia en relación con el clúster.
- describe()- Describe la estructura del clúster.
- disconnect()- Desconecta todas las sesiones internas utilizadas por el objeto del clúster.
- dissolve([opciones]):desactiva la replicación y anula el registro de los ReplicaSets del clúster.
- forceQuorumUsingPartitionOf(instancia[, contraseña]):restaura el clúster de la pérdida de quórum.
- getName()- Recupera el nombre del clúster.
- help([member]):proporciona ayuda sobre esta clase y sus miembros
- opciones([opciones]):enumera las opciones de configuración del clúster.
- rejoinInstance(instancia[, opciones])- Vuelve a unir una instancia al clúster.
- removeInstance(instancia[, opciones]):elimina una instancia del clúster.
- rescan([options])- vuelve a escanear el clúster.
- resetRecoveryAccountsPassword(opciones)- Restablece la contraseña de las cuentas de recuperación del clúster.
- setInstanceOption(instancia, opción, valor)- Cambia el valor de una opción de configuración en un miembro del clúster.
- setOption(opción, valor)- Cambia el valor de una opción de configuración para todo el clúster.
- setPrimaryInstance(instancia):elige un miembro de clúster específico como el nuevo principal.
- status([options]):describe el estado del clúster.
- switchToMultiPrimaryMode():cambia el clúster al modo multiprincipal.
- switchToSinglePrimaryMode([instancia]):cambia el clúster al modo primario único.
Vamos a analizar la mayoría de las funciones disponibles para ayudarnos a monitorear, administrar y escalar el clúster.
Supervisión de las operaciones de clúster de MySQL InnoDB
Estado del clúster
Para verificar el estado del clúster, primero use la línea de comandos del shell de MySQL y luego conéctese como ejemplo@sqldat.com{uno-de-los-nodos-db}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Luego, cree un objeto llamado "clúster" y declárelo como objeto global "dba" que proporciona acceso a las funciones de administración del clúster de InnoDB mediante AdminAPI (consulte los documentos de MySQL Shell API):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Luego, podemos usar el nombre del objeto para llamar a las funciones API para el objeto "dba":
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}La salida es bastante larga pero podemos filtrarla usando la estructura del mapa. Por ejemplo, si quisiéramos ver el retraso de replicación solo para db3, podríamos hacer lo siguiente:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Tenga en cuenta que el retraso de la replicación es algo que sucederá en la replicación grupal, según la intensidad de escritura del miembro principal en el conjunto de réplicas y las variables group_replication_flow_control_*. No vamos a tratar este tema en detalle aquí. Consulte esta publicación de blog para obtener más información sobre el rendimiento de la replicación de grupos y el control de flujo.
Otra función similar es la función describe(), pero esta es un poco más simple. Describe la estructura del clúster incluyendo toda su información, ReplicaSets e Instancias:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}De manera similar, podemos filtrar la salida JSON usando la estructura del mapa:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryCuando el nodo principal dejó de funcionar (en este caso, es db1), la salida devolvió lo siguiente:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Preste atención al estado OK_NO_TOLERANCE, donde el clúster todavía está en funcionamiento pero no puede tolerar más fallas después de que uno de los tres nodos no esté disponible. La función principal ha sido asumida por db2 automáticamente, y las conexiones de la base de datos desde la aplicación se redirigirán al nodo correcto si se conectan a través del enrutador MySQL. Una vez que db1 vuelva a estar en línea, deberíamos ver el siguiente estado:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Muestra que db1 ahora está disponible pero sirvió como secundario con solo lectura habilitado. La función principal todavía está asignada a db2 hasta que algo sale mal en el nodo, donde se conmutará automáticamente al siguiente nodo disponible.
Comprobar estado de instancia
Podemos verificar el estado de un nodo MySQL antes de planear agregarlo al clúster usando la función checkInstanceState(). Analiza los GTID ejecutados de la instancia con los GTID ejecutados/purgados en el clúster para determinar si la instancia es válida para el clúster.
A continuación se muestra el estado de la instancia de db3 cuando estaba en modo independiente, antes de formar parte del clúster:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Si el nodo ya forma parte del clúster, debería obtener lo siguiente:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Supervisar cualquier estado "consultable"
Con MySQL Shell, ahora podemos usar el comando integrado \show y \watch para monitorear cualquier consulta administrativa en tiempo real. Por ejemplo, podemos obtener el valor en tiempo real de los hilos conectados usando:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';O obtenga la lista de procesos de MySQL actual:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTPodemos usar el comando \watch para ejecutar un informe de la misma manera que el comando \show, pero actualiza los resultados a intervalos regulares hasta que cancela el comando usando Ctrl + C. Como se muestra en los siguientes ejemplos:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTEl intervalo de actualización predeterminado es de 2 segundos. Puede cambiar el valor usando la marca --interval y especificando un valor desde 0.1 hasta 86400.
Operaciones de administración de clústeres de MySQL InnoDB
Conmutación principal
La instancia principal es el nodo que puede considerarse líder en un grupo de replicación, que tiene la capacidad de realizar operaciones de lectura y escritura. Solo se permite una instancia principal por clúster en el modo de topología principal único. Esta topología también se conoce como conjunto de réplicas y es el modo de topología recomendado para la replicación de grupos con protección contra conflictos de bloqueo.
Para realizar el cambio de instancia principal, inicie sesión en uno de los nodos de la base de datos como usuario clusteradmin y especifique el nodo de la base de datos que desea promocionar mediante la función setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Acabamos de promocionar db1 como el nuevo componente principal, reemplazando db2 mientras que db3 permanece como el nodo secundario.
Cierre del clúster
La mejor manera de cerrar el clúster correctamente deteniendo primero el servicio de enrutador MySQL (si se está ejecutando) en el servidor de aplicaciones:
$ myrouter/stop.shEl paso anterior proporciona protección de clúster contra escrituras accidentales por parte de las aplicaciones. Luego apague un nodo de la base de datos a la vez usando el comando de parada estándar de MySQL, o realice el apagado del sistema como desee:
$ systemctl stop mysqlInicio del clúster después de un apagado
Si su clúster sufre una interrupción total o desea iniciar el clúster después de un apagado limpio, puede asegurarse de que se reconfigure correctamente mediante la función dba.rebootClusterFromCompleteOutage(). Simplemente vuelve a poner un clúster EN LÍNEA cuando todos los miembros están FUERA DE LÍNEA. En el caso de que un clúster se haya detenido por completo, se deben iniciar las instancias y solo entonces se puede iniciar el clúster.
Por lo tanto, asegúrese de que todos los servidores MySQL estén iniciados y funcionando. En cada nodo de la base de datos, vea si el proceso mysqld se está ejecutando:
$ ps -ef | grep -i mysqlLuego, elija un servidor de base de datos para que sea el nodo principal y conéctese a él a través de MySQL shell:
MySQL|JS> shell.connect("example@sqldat.com:3306");Ejecute el siguiente comando desde ese host para iniciarlos:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Se le presentarán las siguientes preguntas:
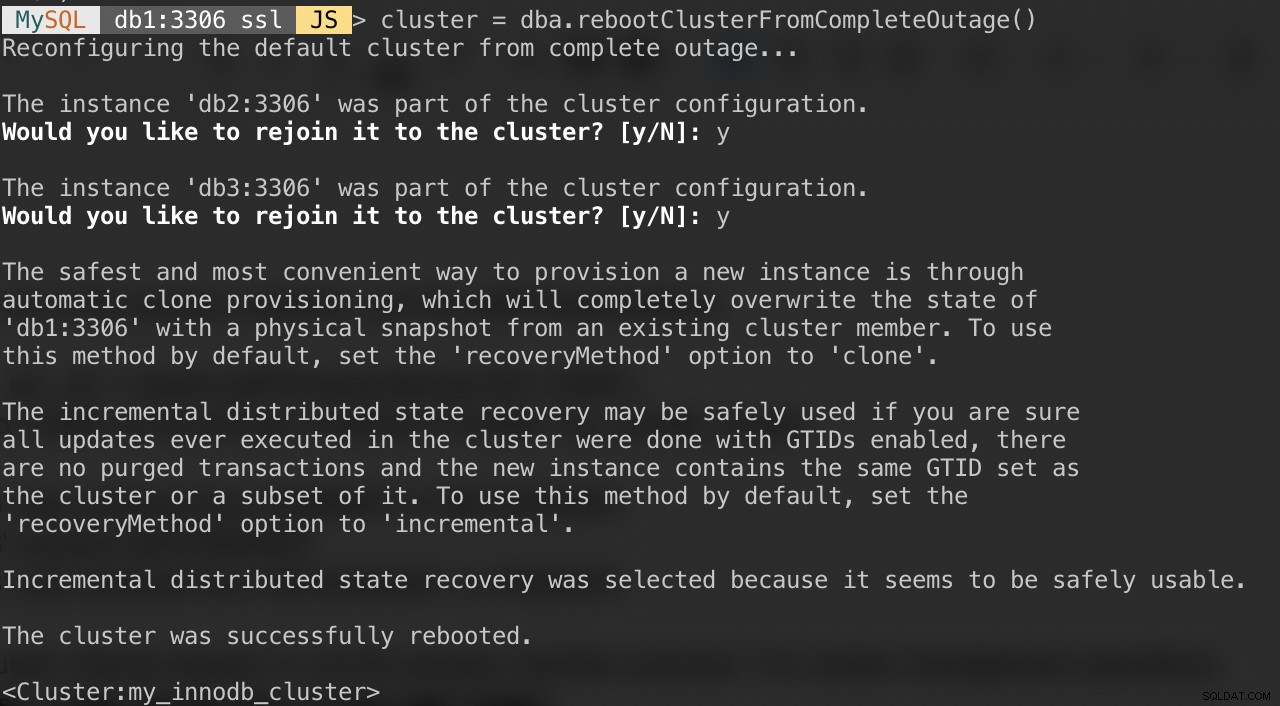
Una vez que se completa lo anterior, puede verificar el estado del clúster:
MySQL|db1:3306 ssl|JS> cluster.status()En este punto, db1 es el nodo principal y el escritor. El resto serán los miembros secundarios. Si desea iniciar el clúster con db2 o db3 como principal, puede usar la función shell.connect() para conectarse al nodo correspondiente y realizar rebootClusterFromCompleteOutage() desde ese nodo en particular.
A continuación, puede iniciar el servicio de enrutador MySQL (si no se ha iniciado) y dejar que la aplicación se conecte de nuevo al clúster.
Configuración de opciones de miembros y clústeres
Para obtener las opciones de todo el clúster, simplemente ejecute:
MySQL|db1:3306 ssl|JS> cluster.options()Lo anterior enumerará las opciones globales para el conjunto de réplicas y también las opciones individuales por miembro en el clúster. Esta función cambia una opción de configuración de InnoDB Cluster en todos los miembros del clúster. Las opciones admitidas son:
- clusterName:valor de cadena para definir el nombre del clúster.
- exitStateAction:valor de cadena que indica la acción del estado de salida de la replicación del grupo.
- memberWeight:valor entero con una ponderación porcentual para la elección primaria automática en caso de conmutación por error.
- failoverConsistency:valor de cadena que indica las garantías de coherencia que proporciona el clúster.
- consistencia: valor de cadena que indica las garantías de consistencia que proporciona el clúster.
- expelTimeout:valor entero para definir el período de tiempo en segundos que los miembros del clúster deben esperar a un miembro que no responde antes de expulsarlo del clúster.
- autoRejoinTries:valor entero para definir la cantidad de veces que una instancia intentará volver a unirse al clúster después de ser expulsada.
- disableClone:valor booleano utilizado para deshabilitar el uso de clones en el clúster.
Similar a otras funciones, la salida se puede filtrar en la estructura del mapa. El siguiente comando solo enumerará las opciones para db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]También puede obtener la lista anterior utilizando la función de ayuda():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")El siguiente comando muestra un ejemplo para configurar una opción llamada memberWeight a 60 (de 50) en todos los miembros:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.También podemos realizar la gestión de la configuración automáticamente a través de MySQL Shell utilizando la función setInstanceOption() y pasar el host de la base de datos, el nombre de la opción y el valor correspondiente:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Las opciones admitidas son:
- exitStateAction: valor de cadena que indica la acción del estado de salida de la replicación del grupo.
- memberWeight:valor entero con una ponderación porcentual para la elección primaria automática en caso de conmutación por error.
- autoRejoinTries:valor entero para definir la cantidad de veces que una instancia intentará volver a unirse al clúster después de ser expulsada.
- etiqueta un identificador de cadena de la instancia.
Cambiar al modo primario múltiple/primario único
De forma predeterminada, InnoDB Cluster está configurado con un solo miembro principal, solo un miembro capaz de realizar lecturas y escrituras en un momento dado. Esta es la forma más segura y recomendada de ejecutar el clúster y es adecuada para la mayoría de las cargas de trabajo.
Sin embargo, si la lógica de la aplicación puede manejar escrituras distribuidas, probablemente sea una buena idea cambiar al modo principal múltiple, donde todos los miembros del clúster pueden procesar lecturas y escrituras al mismo tiempo. Para cambiar del modo primario único al modo primario múltiple, simplemente use la función switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Verifique con:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}En el modo multiprimario, todos los nodos son primarios y pueden procesar lecturas y escrituras. Al enviar una nueva conexión a través del enrutador MySQL en el puerto de un solo escritor (6446), la conexión se enviará a un solo nodo, como en este ejemplo, db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Si la aplicación se conecta al puerto de múltiples escritores (6447), la conexión se equilibrará mediante un algoritmo de operación por turnos para todos los miembros:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Como puede ver en el resultado anterior, todos los nodos son capaces de procesar lecturas y escrituras con read_only =OFF. Puede distribuir escrituras seguras a todos los miembros conectándose al puerto de escritura múltiple (6447) y enviar las escrituras conflictivas o pesadas al puerto de escritura única (6446).
Para volver al modo principal único, utilice la función switchToSinglePrimaryMode() y especifique un miembro como nodo principal. En este ejemplo, elegimos db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.En este punto, db1 ahora es el nodo principal configurado con solo lectura deshabilitado y el resto se configurará como secundario con solo lectura habilitado.
Operaciones de escalado de clúster de MySQL InnoDB
Ampliar (agregar un nuevo nodo de base de datos)
Al agregar una nueva instancia, primero se debe aprovisionar un nodo antes de que se le permita participar con el grupo de replicación. El proceso de aprovisionamiento será manejado automáticamente por MySQL. Además, puede verificar primero el estado de la instancia si el nodo es válido para unirse al clúster usando la función checkInstanceState() como se explicó anteriormente.
Para agregar un nuevo nodo de base de datos, use la función addInstances() y especifique el host:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Lo siguiente es lo que obtendría al agregar una nueva instancia:
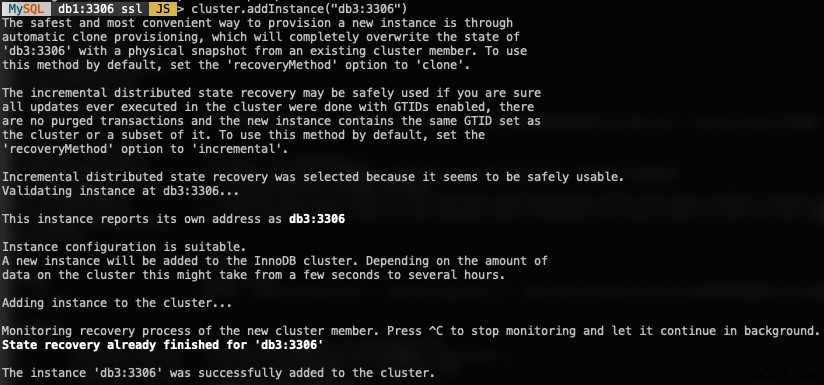
Verifique el nuevo tamaño del clúster con:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router incluirá automáticamente el nodo agregado, db3 en el conjunto de equilibrio de carga.
Reducción de escala (eliminación de un nodo)
Para eliminar un nodo, conéctese a cualquiera de los nodos de la base de datos excepto al que vamos a eliminar y use la función removeInstance() con el nombre de la instancia de la base de datos:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Lo siguiente es lo que obtendría al eliminar una instancia:
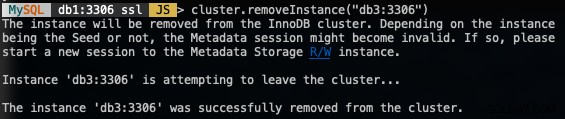
Verifique el nuevo tamaño del clúster con:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()El enrutador MySQL excluirá automáticamente el nodo eliminado, db3 del conjunto de equilibrio de carga.
Adición de un nuevo esclavo de replicación
Podemos escalar el clúster de InnoDB con réplicas de esclavos de replicación asincrónica desde cualquiera de los nodos del clúster. Un esclavo está débilmente acoplado al clúster y podrá manejar una carga pesada sin afectar el rendimiento del clúster. El esclavo también puede ser una copia en vivo de la base de datos para fines de recuperación ante desastres. En el modo primario múltiple, puede usar el esclavo como el procesador de solo lectura de MySQL dedicado para escalar la carga de trabajo de lecturas, realizar operaciones de análisis o como un servidor de respaldo dedicado.
En el servidor esclavo, descargue el paquete de configuración APT más reciente, instálelo (elija MySQL 8.0 en el asistente de configuración), instale la clave APT, actualice repolist e instale el servidor MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellModifique el archivo de configuración de MySQL para preparar el servidor para el esclavo de replicación. Abra el archivo de configuración a través del editor de texto:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfY agregue las siguientes líneas:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Reinicie el servidor MySQL en el esclavo para aplicar los cambios:
$ systemctl restart mysqlEn uno de los servidores de InnoDB Cluster (elegimos db3), cree un usuario esclavo de replicación y, a continuación, un volcado completo de MySQL:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlTransferir el archivo de volcado de db3 al esclavo:
$ scp dump.sql example@sqldat.com:~Y realice la restauración en el esclavo:
$ mysql -uroot -p < dump.sqlCon master-data=1, nuestro archivo de volcado de MySQL configurará automáticamente el valor GTID ejecutado y purgado. Podemos verificarlo con la siguiente declaración en el servidor esclavo después de la restauración:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Se ve bien. Luego podemos configurar el enlace de replicación e iniciar los subprocesos de replicación en el esclavo:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Verifique el estado de replicación y asegúrese de que el siguiente estado devuelva 'Sí':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...En este punto, nuestra arquitectura se ve así:
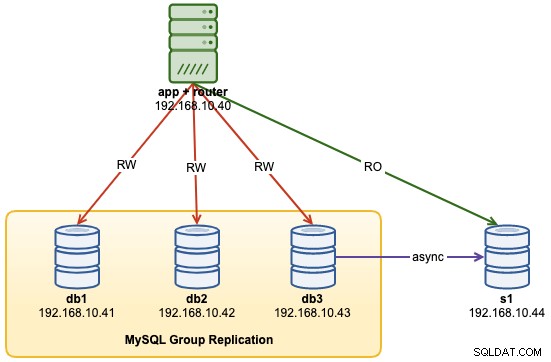
Problemas comunes con los clústeres MySQL InnoDB
Memoria agotada
Al usar MySQL Shell con MySQL 8.0, recibíamos constantemente el siguiente error cuando las instancias estaban configuradas con 1 GB de RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Actualizar la RAM de cada host a 2 GB de RAM resolvió el problema. Aparentemente, los componentes de MySQL 8.0 requieren más RAM para funcionar de manera eficiente.
Se perdió la conexión con el servidor MySQL
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Conclusión
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).