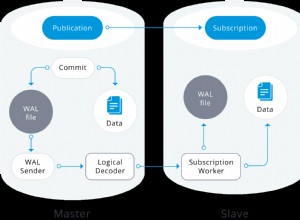
Hoy en día, es bastante común tener una base de datos replicada en otro servidor/centro de datos, y también es imprescindible en algunos casos. Hay diferentes razones para replicar sus bases de datos en un entorno totalmente separado.
- Migrar a otro centro de datos.
- Requisitos de actualización (hardware/software).
- Mantenga un sistema operativo totalmente sincronizado en un sitio de recuperación ante desastres (DR) que pueda hacerse cargo en cualquier momento
- Mantenga una base de datos esclava como parte de un plan DR de menor costo.
- Para los requisitos de ubicación geográfica (los datos deben ser locales en un país específico).
- Tenga un entorno de prueba.
- Propósito de solución de problemas.
- Base de datos de informes.
Y hay diferentes formas de realizar esta tarea de replicación:
- Copia de seguridad/Restauración :Hacer una copia de seguridad de una base de datos de producción y restaurarla en un nuevo servidor/entorno es la forma clásica de hacerlo, pero también es una forma anticuada, ya que no mantendrá sus datos actualizados y tendrá que esperar. para cada proceso de restauración si necesita algunos datos recientes. Si tiene un clúster (maestro-esclavo, multimaestro) y desea volver a crearlo, debe restaurar la copia de seguridad inicial y luego volver a crear el resto de los nodos, lo que podría llevar mucho tiempo.
- Clonar clúster :Es similar al anterior pero el proceso de copia de seguridad y restauración es para todo el clúster, no solo para un servidor de base de datos específico. De esta forma, puedes clonar todo el clúster en una misma tarea y no necesitas volver a crear el resto de nodos manualmente. Este método todavía tiene el problema de mantener los datos actualizados entre clones.
- Replicación :esta forma incluye la opción de copia de seguridad/restauración, pero después de la restauración inicial, el proceso de replicación mantendrá sus datos sincronizados con el nodo principal. De esta forma, si tiene un clúster de base de datos, debe restaurar la copia de seguridad en un nodo y volver a crear todos los nodos manualmente.
En este blog, veremos una nueva característica de ClusterControl 1.7.4 que le permite usar una combinación del método que mencionamos anteriormente para mejorar esta tarea.
¿Qué es la replicación de clúster a clúster?
La replicación entre dos clústeres no es lo mismo que extender un clúster para que se ejecute en dos centros de datos. Al configurar la replicación entre dos clústeres, en realidad tenemos 2 sistemas separados que pueden operar de forma autónoma. La replicación se usa para mantenerlos sincronizados, de modo que el sistema esclavo tenga un estado actualizado y pueda asumir el control.
Desde ClusterControl 1.7.4, es posible crear un nuevo clúster clonando directamente un clúster de origen en ejecución o usando una copia de seguridad reciente del clúster de origen.
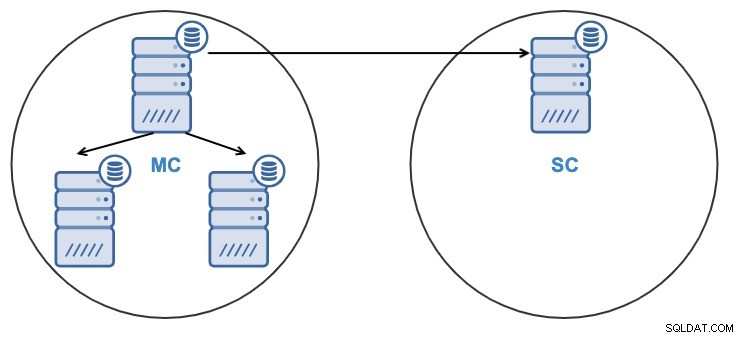
Después de clonar el clúster, tendrá un clúster esclavo (SC) que recibe datos y un clúster maestro (MC) que envía cambios al esclavo.
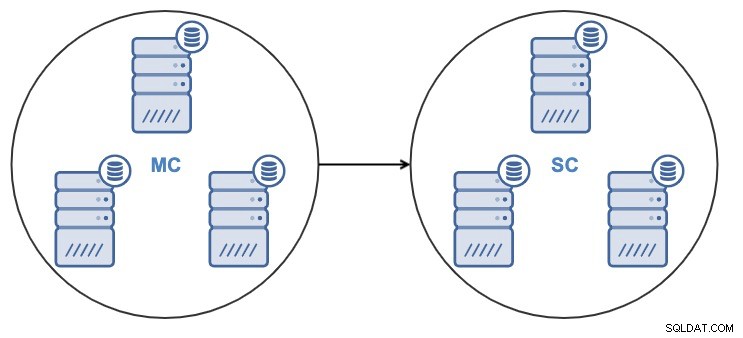
ClusterControl admite la replicación de clúster a clúster para los siguientes tipos de clúster:
- Percona XtraDB Cluster versión 5.6.x y posterior.
- MariaDB Galera Cluster versión 10.x y posterior.
- PostgreSQL 9.6 y posterior.
Replicación de clúster a clúster para Percona XtraDB / MariaDB Galera Cluster
Para los motores basados en MySQL, se requiere GTID para usar esta función y se usará la replicación asíncrona entre el clúster Maestro y Esclavo.
Hay un par de acciones que realizar para preparar el clúster actual para este trabajo. Primero, al menos un nodo en el clúster actual debe tener habilitados los registros binarios. Luego, debe agregar el usuario de respaldo configurado en el nodo de la base de datos en el archivo de configuración de ClusterControl, que se utilizará para las tareas de administración. Todas estas acciones se pueden realizar mediante la interfaz de usuario de ClusterControl o la CLI de ClusterControl.
Ahora está listo para crear la replicación de clúster a clúster de Percona XtraDB/MariaDB Galera. Cuando termine el trabajo, tendrá:
- Un nodo en el clúster esclavo se replicará desde un nodo en el clúster maestro.
- La replicación será bidireccional entre los clústeres.
- Todos los nodos en el clúster esclavo serán de solo lectura de forma predeterminada. Es posible deshabilitar el indicador de solo lectura en los nodos uno por uno.
- La agrupación en clústeres activo-activo solo se recomienda si las aplicaciones solo tocan conjuntos de datos separados en cualquiera de los clústeres, ya que el motor no ofrece detección o resolución de conflictos.
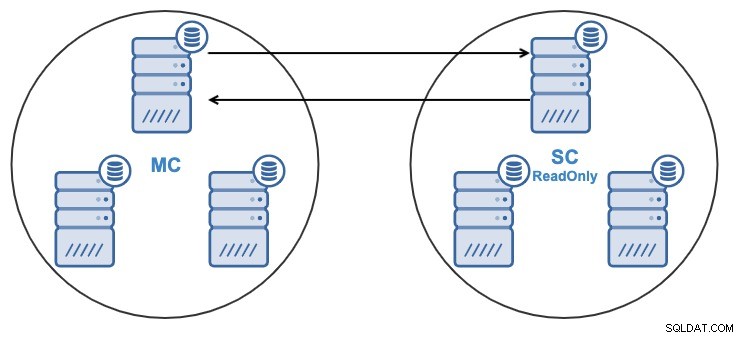
Desde la interfaz de usuario de ClusterControl o la CLI de ClusterControl, podrá:
- Cree este clúster de replicación.
- Habilite la configuración Activo-Activo.
- Cambie la topología del clúster.
- Reconstruir un clúster de replicación.
- Detener/Iniciar un esclavo de replicación.
- Reset Replication Slave (solo implementado usando ClusterControl CLI atm).
Consideraciones
- El usuario de respaldo debe agregarse manualmente en el archivo de configuración de ClusterControl.
- Las credenciales de usuario de respaldo deben ser las mismas tanto en el clúster actual como en el nuevo.
- La contraseña raíz de MySQL especificada al crear el Clúster esclavo debe ser la misma que la contraseña raíz utilizada en el Clúster maestro.
Limitaciones conocidas
- La conmutación por error automática aún no es compatible. Si el maestro falla, entonces es responsabilidad del administrador realizar la conmutación por error a otro maestro.
- Solo es posible "RESTABLECER" un esclavo de replicación desde la CLI de ClusterControl, ya que aún no está implementado en la interfaz de usuario de ClusterControl.
- Solo es posible reconstruir un clúster que está en modo de solo lectura. Todos los nodos en un clúster deben ser de solo lectura para contar como clúster de solo lectura.
Replicación de clúster a clúster para PostgreSQL
ClusterControl La replicación de clúster a clúster es compatible con PostgreSQL mediante la replicación de transmisión.
Como requisito, debe haber un servidor PostgreSQL con el rol de ClusterControl 'maestro', y cuando configura el Clúster esclavo, las credenciales de administrador deben ser idénticas a las del Clúster maestro.
Ahora está listo para crear la replicación de clúster a clúster de PostgreSQL. Cuando termine el trabajo, tendrá:
- Un nodo en el clúster esclavo se replicará desde un nodo en el clúster maestro.
- La replicación será unidireccional entre los clústeres.
- El nodo en el clúster esclavo será de solo lectura.
Desde la interfaz de usuario de ClusterControl o la CLI de ClusterControl, podrá:
- Cree este clúster de replicación.
- Reconstruir un clúster de replicación.
- Detener/Iniciar un esclavo de replicación.
Consideración
- Las credenciales de administrador deben ser idénticas en el clúster maestro y esclavo.
Limitaciones conocidas
- El tamaño máximo del clúster esclavo es un nodo.
- El clúster esclavo no puede organizarse desde una copia de seguridad.
- Los cambios de topología no son compatibles.
- Solo se admite la replicación unidireccional.
Conclusión
Al utilizar esta nueva característica de ClusterControl, no necesita realizar cada paso para crear una replicación de clúster por separado o manualmente y, como resultado de su uso, ahorrará tiempo y esfuerzo. ¡Pruébalo!