Percona XtraDB Cluster es una solución de alta disponibilidad muy conocida en el mundo MySQL. Se basa en Galera Cluster y proporciona replicación virtualmente síncrona en varios nodos. Como con toda base de datos, es fundamental realizar un seguimiento de lo que sucede en el sistema, si el rendimiento está en los niveles esperados y, en caso contrario, cuál es el cuello de botella. Esto es de suma importancia para poder reaccionar adecuadamente en la situación, donde el rendimiento se ve afectado. Por supuesto, Percona XtraDB Cluster viene con múltiples métricas y no siempre está claro cuáles de ellas son las más importantes para rastrear el estado de la base de datos. En este blog, analizaremos un par de métricas clave que desea controlar mientras trabaja con PXC.
Para que quede claro, nos centraremos en las métricas exclusivas de PXC y Galera, no cubriremos las métricas para MySQL o InnoDB. Esas métricas se han discutido en nuestros blogs anteriores.
Echemos un vistazo a la información más importante que nos presenta PXC.
Control de flujo
El control de flujo es prácticamente la métrica más importante que puede monitorear en cualquier clúster de Galera, por lo tanto, veamos un poco de historia. Galera es un clúster multimaestro virtualmente síncrono. Es posible ejecutar escrituras en cualquiera de los nodos de la base de datos que la forman. Cada escritura debe enviarse a todos los nodos del clúster para garantizar que se pueda aplicar; este proceso se denomina certificación. No se puede aplicar ninguna transacción antes de que todos los nodos acuerden que se puede confirmar. Si alguno de los nodos tiene problemas de rendimiento que le impiden hacer frente al tráfico, comenzará a emitir mensajes de control de flujo destinados a informar al resto del clúster sobre los problemas de rendimiento y pedirles que reduzcan la carga de trabajo y ayuden a los nodos retrasados. nodo para ponerse al día con el resto del clúster.
Puede rastrear cuándo los nodos tuvieron que introducir una pausa artificial para permitir que sus pares rezagados se pusieran al día usando la métrica de pausa de control de flujo (wsrep_flow_control_paused):

También puede rastrear si el nodo está enviando o recibiendo mensajes de control de flujo (wsrep_flow_control_recv y wsrep_flow_control_sent).
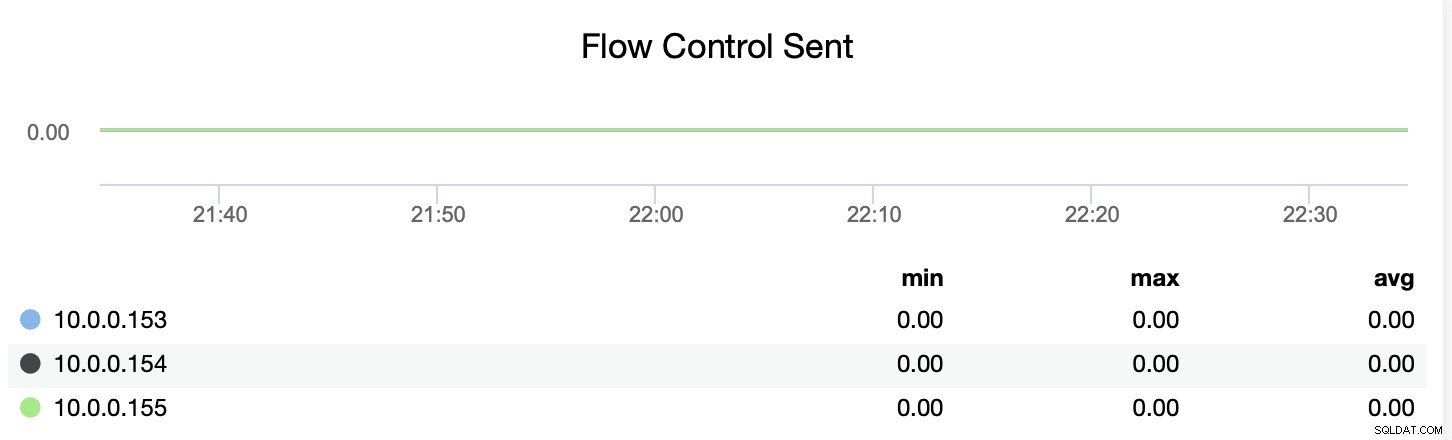
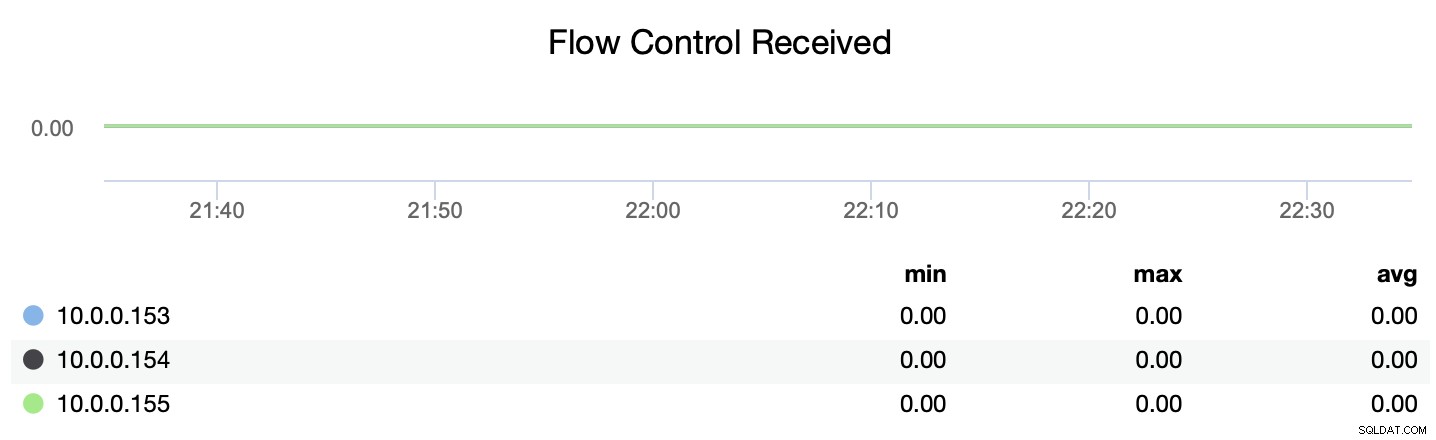
Esta información lo ayudará a comprender mejor qué nodo no funciona en el mismo nivel como sus pares. Luego puede concentrarse en ese nodo e intentar comprender cuál es el problema y cómo eliminar el cuello de botella.
Colas de envío y recepción
Esas métricas están relacionadas con el control de flujo. Como hemos discutido, un nodo puede estar rezagado con respecto a otros nodos en el clúster. Puede ser causado por una división desigual de la carga de trabajo o por otras razones (algún proceso que se ejecuta en segundo plano, copia de seguridad o algunas consultas pesadas personalizadas). Antes de que se active el control de flujo, los nodos retrasados intentarán almacenar los conjuntos de escritura entrantes en la cola de recepción (wsrep_local_recv_queue) con la esperanza de que el impacto en el rendimiento sea transitorio y pueda ponerse al día muy pronto. Solo si la cola se vuelve demasiado grande (se rige por la configuración gcs.fc_limit), los mensajes de control de flujo comienzan a enviarse a través del clúster.

Puede pensar en una cola de recepción como el marcador temprano que muestra que hay hay problemas con el rendimiento y el control de flujo puede activarse.

Por otro lado, la cola de envío (wsrep_local_send_queue) le indicará que el nodo no puede enviar los conjuntos de escritura a otros miembros del clúster, lo que puede indicar problemas con la conectividad de la red (empujando los conjuntos de escritura a la red no requiere muchos recursos).
Métricas de paralelización
El clúster Percona XtraDB se puede configurar para usar múltiples subprocesos para aplicar los conjuntos de escritura entrantes, lo que le permite manejar mejor los múltiples subprocesos que se conectan al clúster y emiten escrituras al mismo tiempo. Hay dos métricas principales que tal vez desee vigilar.
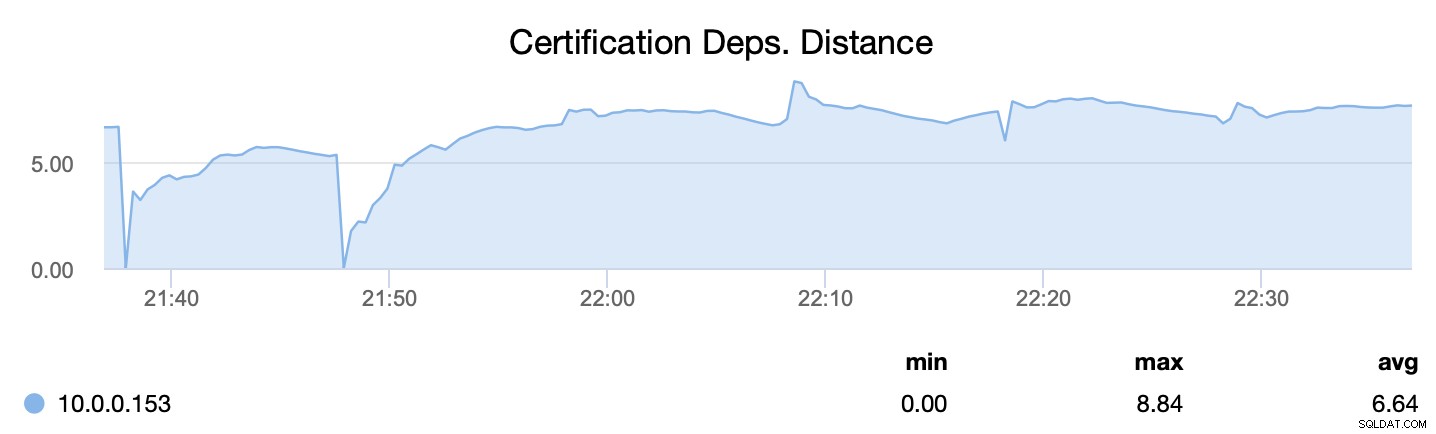
Primero, wsrep_cert_deps_distance, nos dice cuál es el potencial de paralelización:cuántos conjuntos de escritura pueden, potencialmente, aplicarse al mismo tiempo. En función de este valor, puede configurar la cantidad de subprocesos esclavos paralelos (wsrep_slave_threads) que funcionarán al aplicar conjuntos de escritura entrantes. La regla general es que no tiene sentido configurar más subprocesos que el valor de wsrep_cert_deps_distance.
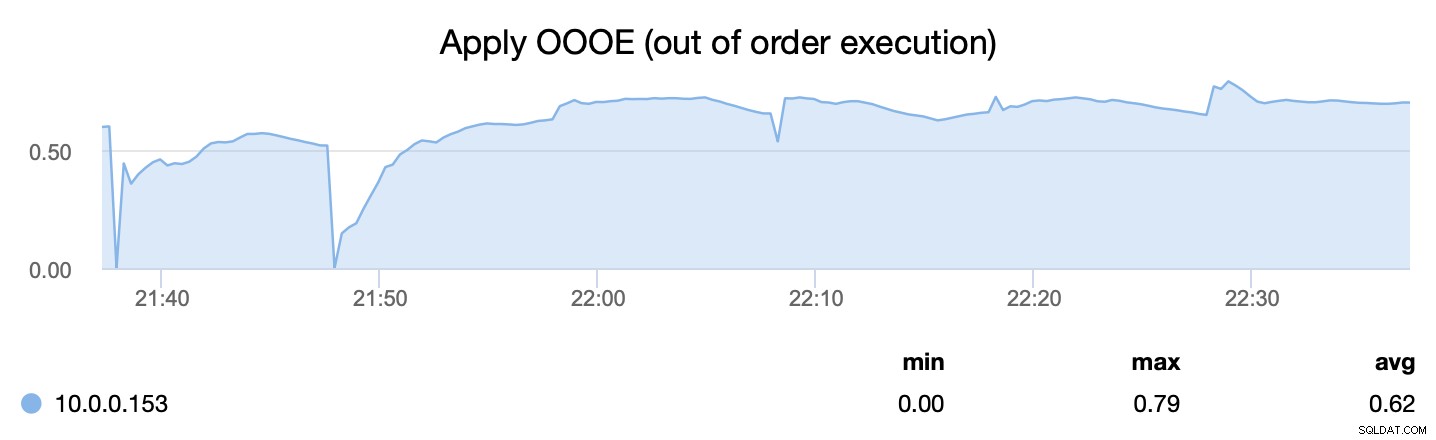
La segunda métrica, por otro lado, nos dice qué tan eficientemente pudimos paralelizar el proceso de aplicar conjuntos de escritura:wsrep_apply_oooe nos dice con qué frecuencia el aplicador comenzó a aplicar conjuntos de escritura desordenados (lo que apunta hacia una mejor paralelización ).
Conclusión
Como puede ver, hay un par de métricas que vale la pena analizar en Percona XtraDB Cluster. Por supuesto, como dijimos al comienzo de este blog, esas son métricas estrictamente relacionadas con PXC y Galera Cluster en general.
También debe estar atento a las métricas regulares de MySQL e InnoDB para comprender mejor el estado de su base de datos. Y recuerde, puede monitorear esta tecnología de forma gratuita utilizando ClusterControl Community Edition.