En esta publicación de blog, analizaremos algunas métricas y estados clave al monitorear un servidor Percona para MySQL para ayudarnos a ajustar la configuración del servidor MySQL a largo plazo. Solo como advertencia, Percona Server tiene algunas métricas de monitoreo que solo están disponibles en esta compilación. Al comparar con la versión 8.0.20, los siguientes 51 estados solo están disponibles en Percona Server para MySQL, que no están disponibles en el servidor comunitario MySQL de Oracle anterior:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_ejecutado
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_actual
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_evited
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Consulte la página Estado extendido de InnoDB para obtener más información sobre cada una de las métricas de monitoreo anteriores. Tenga en cuenta que algunos estados adicionales, como el grupo de subprocesos, solo están disponibles en MySQL Enterprise de Oracle. Consulte la documentación de Percona Server para MySQL 8.0 para ver todas las mejoras específicas para esta compilación sobre MySQL Community Server 8.0 de Oracle.
Para recuperar el estado global de MySQL, simplemente use una de las siguientes declaraciones:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Estado de la base de datos y descripción general
Comenzaremos con el estado de tiempo de actividad, la cantidad de segundos que el servidor ha estado activo.
Todos los estados com_* son las variables contadoras de sentencias que indican el número de veces que se ha ejecutado cada sentencia. Hay una variable de estado para cada tipo de declaración. Por ejemplo, com_delete y com_update cuentan sentencias DELETE y UPDATE, respectivamente. com_delete_multi y com_update_multi son similares, pero se aplican a las declaraciones DELETE y UPDATE que usan sintaxis de tablas múltiples.
Para enumerar todo el proceso en ejecución de MySQL, simplemente ejecute una de las siguientes declaraciones:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Conexiones y Roscas
Conexiones actuales
La proporción de conexiones actualmente abiertas (hilo de conexión). Si la proporción es alta, indica que hay muchas conexiones simultáneas al servidor MySQL y podría generar un error de "Demasiadas conexiones". Para obtener el porcentaje de conexión:
Current connections(%) = (threads_connected / max_connections) x 100Un buen valor debe ser del 80% o menos. Intente aumentar la variable max_connections o inspeccione las conexiones usando SHOW FULL PROCESSLIST. Cuando ocurren errores de "Demasiadas conexiones", el servidor de la base de datos MySQL no estará disponible para el no superusuario hasta que se liberen algunas conexiones. Tenga en cuenta que aumentar la variable max_connections también podría aumentar potencialmente la huella de memoria de MySQL.
Conexiones máximas jamás vistas
La proporción de conexiones máximas al servidor MySQL que se haya visto alguna vez. Un cálculo simple sería:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100El buen valor debe estar por debajo del 80 %. Si la proporción es alta, indica que MySQL alguna vez alcanzó una gran cantidad de conexiones que conducirían a un error de "demasiadas conexiones". Inspeccione la proporción de conexiones actuales para ver si realmente se mantiene baja de manera constante. De lo contrario, aumente la variable max_connections. Verifique el estado de max_used_connections_time para indicar cuándo el estado de max_used_connections alcanzó su valor actual.
Tasa de aciertos de caché de subprocesos
El estado de threads_created es la cantidad de subprocesos creados para manejar las conexiones. Si threads_created es grande, es posible que desee aumentar el valor de thread_cache_size. La tasa de aciertos/fallos de caché se puede calcular como:
Threads cache hit rate (%) = (threads_created / connections) x 100Es una fracción que da una indicación de la tasa de aciertos de caché de subprocesos. Cuanto más cerca menos del 50%, mejor. Si su servidor ve cientos de conexiones por segundo, normalmente debería configurar thread_cache_size lo suficientemente alto para que la mayoría de las conexiones nuevas usen hilos almacenados en caché.
Rendimiento de consultas
Exploración completa de la tabla
La proporción de exploraciones de tablas completas, una operación que requiere leer todo el contenido de una tabla, en lugar de solo partes seleccionadas mediante un índice. Este valor es alto si realiza muchas consultas que requieren la clasificación de resultados o análisis de tablas. Generalmente, esto sugiere que las tablas no están indexadas correctamente o que sus consultas no están escritas para aprovechar los índices que tiene. Para calcular el porcentaje de escaneos completos de la tabla:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100El buen valor debe estar por debajo del 25 %. Examine la salida del registro de consultas lentas de MySQL para descubrir las consultas subóptimas.
Seleccione Unión total
El estado de select_full_join es el número de uniones que realizan exploraciones de tablas porque no usan índices. Si este valor no es 0, debe verificar cuidadosamente los índices de sus tablas.
Seleccionar verificación de rango
El estado de select_range_check es el número de uniones sin claves que verifican el uso de claves después de cada fila. Si esto no es 0, debe verificar cuidadosamente los índices de sus tablas.
Ordenar pases
La proporción de pases de combinación que ha tenido que hacer el algoritmo de ordenación. Si este valor es alto, debería considerar aumentar el valor de sort_buffer_size y read_rnd_buffer_size. Un cálculo de proporción simple es:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Un valor de relación inferior a 3 debería ser un buen valor. Si desea aumentar sort_buffer_size o read_rnd_buffer_size, intente aumentar en pequeños incrementos hasta alcanzar la proporción aceptable.
Rendimiento de InnoDB
Tasa de aciertos del grupo de búfer de InnoDB
La proporción de la frecuencia con la que sus páginas se recuperan de la memoria en lugar del disco. Si el valor es bajo durante el inicio temprano de MySQL, espere un tiempo para que el grupo de búfer se caliente. Para obtener la tasa de aciertos del grupo de búfer, utilice la instrucción SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...El mejor valor es una tasa de aciertos de 1000/10000. Para un valor más bajo, por ejemplo, la tasa de aciertos de 986/1000 indica que de 1000 lecturas de página, pudo leer páginas en RAM 986 veces. Las 14 veces restantes, MySQL tuvo que leer las páginas del disco. En pocas palabras, 1000/1000 es el mejor valor que estamos tratando de lograr aquí, lo que significa que los datos a los que se accede con frecuencia caben completamente en la RAM.
Aumentar la variable innodb_buffer_pool_size ayudará mucho a acomodar más espacio para que funcione MySQL. Sin embargo, asegúrese de tener suficientes recursos de RAM de antemano. La eliminación de índices redundantes también podría ayudar. Si tiene varias instancias de grupos de búfer, asegúrese de que la tasa de aciertos de cada instancia llegue a 1000/1000.
Páginas sucias de InnoDB
La proporción de la frecuencia con la que se debe vaciar InnoDB. Durante la carga de muchas escrituras, es normal que este porcentaje aumente.
Un cálculo simple sería:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Un buen valor debe ser del 75% o menos. Si el porcentaje de páginas sucias se mantiene alto durante mucho tiempo, es posible que desee aumentar el grupo de búfer u obtener discos más rápidos para evitar cuellos de botella en el rendimiento.
InnoDB espera el punto de control
La proporción de la frecuencia con la que InnoDB necesita leer o crear una página donde no hay páginas limpias disponibles. Normalmente, las escrituras en el InnoDB Buffer Pool ocurren en segundo plano. Sin embargo, si es necesario leer o crear una página y no hay páginas limpias disponibles, también es necesario esperar a que las páginas se vacíen primero. El contador innodb_buffer_pool_wait_free cuenta cuántas veces ha sucedido esto. Para calcular la proporción de esperas de InnoDB para el punto de control, podemos usar el siguiente cálculo:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsSi innodb_buffer_pool_wait_free es mayor que 0, es un fuerte indicador de que el grupo de búfer de InnoDB es demasiado pequeño y las operaciones tuvieron que esperar en un punto de control. El aumento de innodb_buffer_pool_size generalmente disminuirá innodb_buffer_pool_wait_free, así como esta proporción. Un buen valor de relación debe permanecer por debajo de 1.
InnoDB espera por Redolog
La proporción de contención del registro de rehacer. Verifique innodb_log_waits y, si continúa aumentando, aumente innodb_log_buffer_size. También puede significar que los discos son demasiado lentos y no pueden mantener la E/S del disco, quizás debido a la carga máxima de escritura. Utilice el siguiente cálculo para calcular la relación de espera del registro de rehacer:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesUn buen valor de relación debe ser inferior a 1. De lo contrario, aumente innodb_log_buffer_size.
Tablas
Uso de caché de tablas
La proporción de uso de caché de tabla para todos los subprocesos. Un cálculo simple sería:
Table cache usage(%) = (opened_tables / table_open_cache) x 100El buen valor debe ser inferior al 80 %. Aumente la variable table_open_cache hasta que el porcentaje alcance un buen valor.
Proporción de aciertos de caché de tabla
La proporción del uso de aciertos de caché de tabla. Un cálculo simple sería:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Un buen valor de índice de aciertos debe ser del 90 % o más. De lo contrario, aumente la variable table_open_cache hasta que la proporción de aciertos alcance un buen valor.
Monitoreo de Métricas con ClusterControl
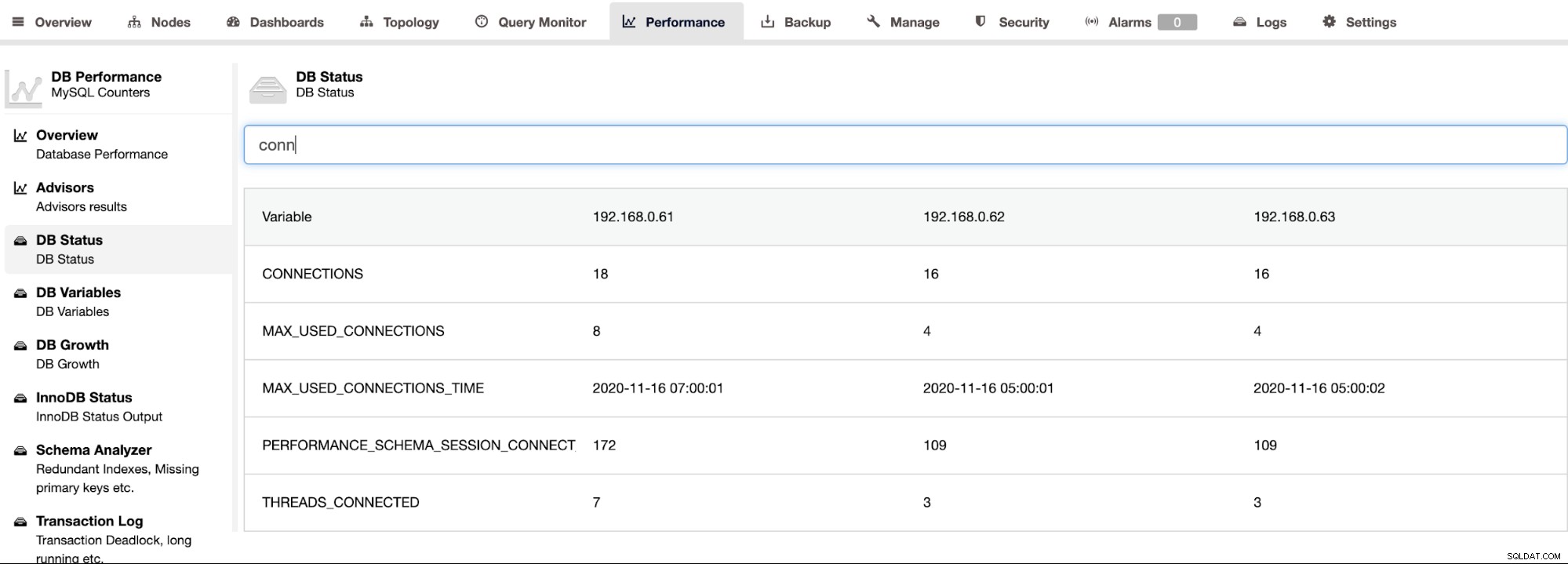
ClusterControl es compatible con Percona Server para MySQL y proporciona una vista agregada de todos los nodos en un clúster en la página ClusterControl -> Rendimiento -> Estado de la base de datos. Esto proporciona un enfoque centralizado para buscar todo el estado en todos los hosts con la capacidad de filtrar el estado, como se muestra en la siguiente captura de pantalla:
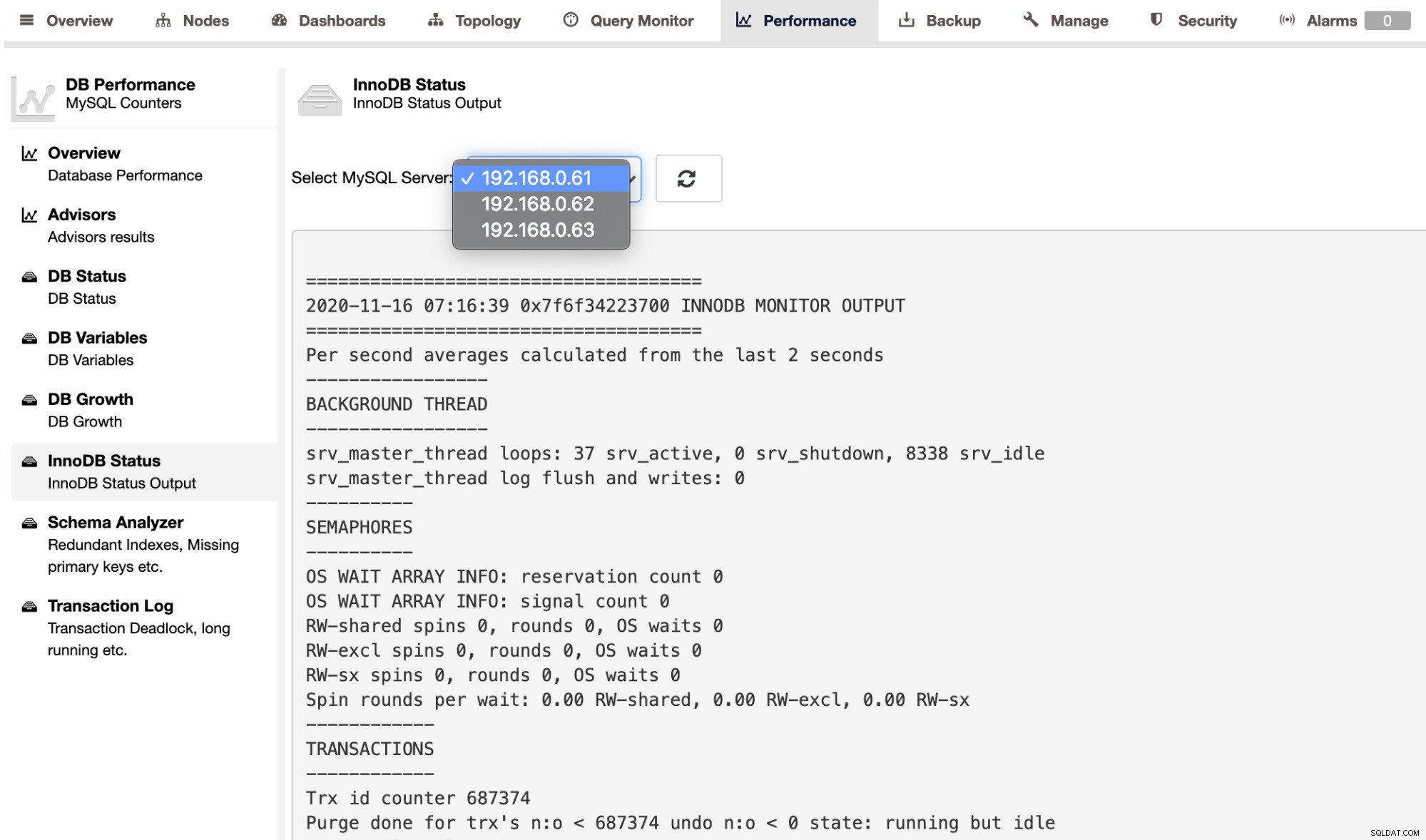
Para recuperar la salida SHOW ENGINE INNODB STATUS para un servidor individual, puede utilice la página Rendimiento -> Estado de InnoDB, como se muestra a continuación:
ClusterControl también proporciona asesores integrados que puede usar para rastrear su base de datos actuación. Se puede acceder a esta función en ClusterControl -> Rendimiento -> Asesores:
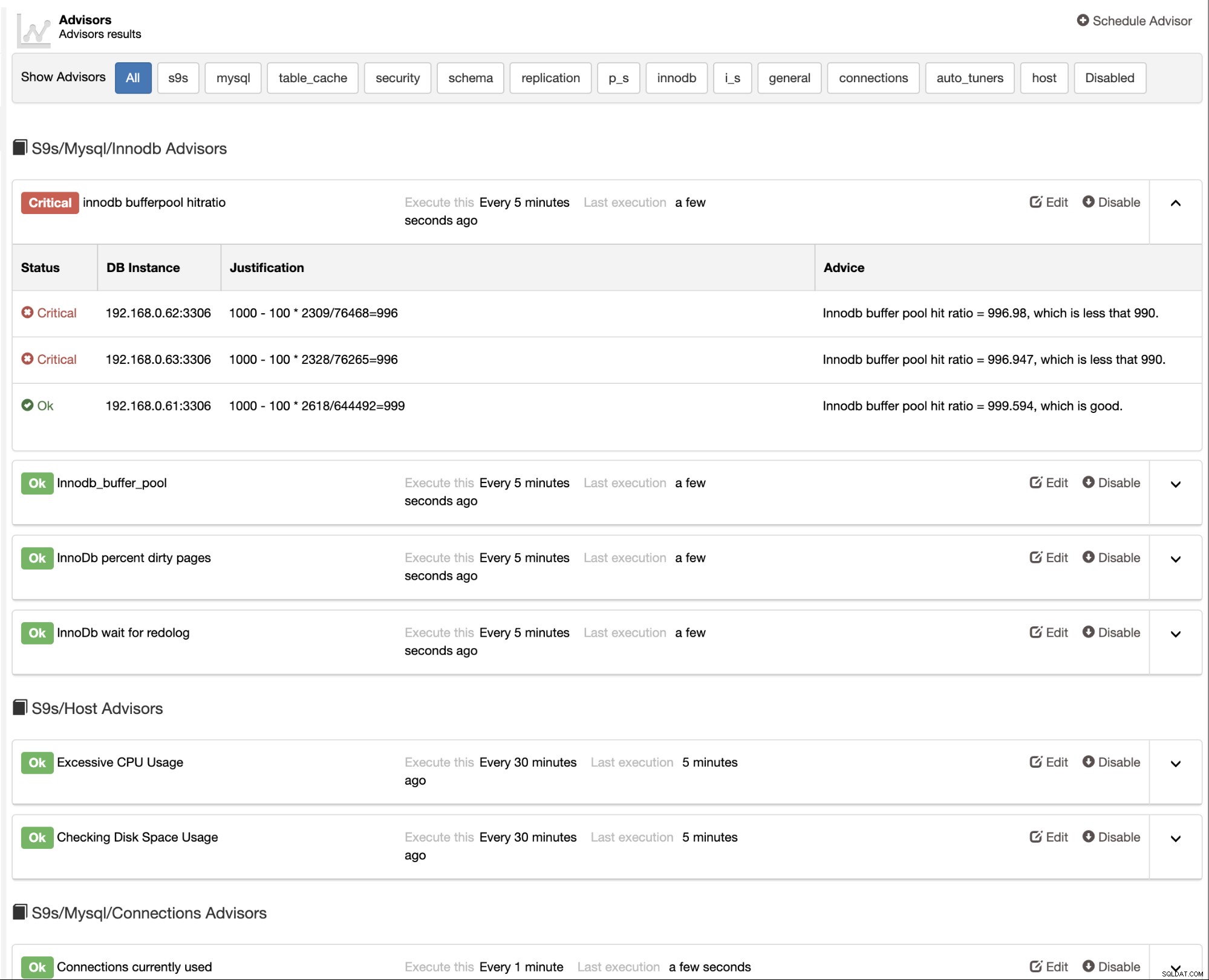
Los asesores son básicamente miniprogramas ejecutados por ClusterControl en un tiempo programado como cron trabajos. Puede programar un asesor haciendo clic en el botón "Programar asesor" y elegir cualquier asesor existente del árbol de objetos de Developer Studio:
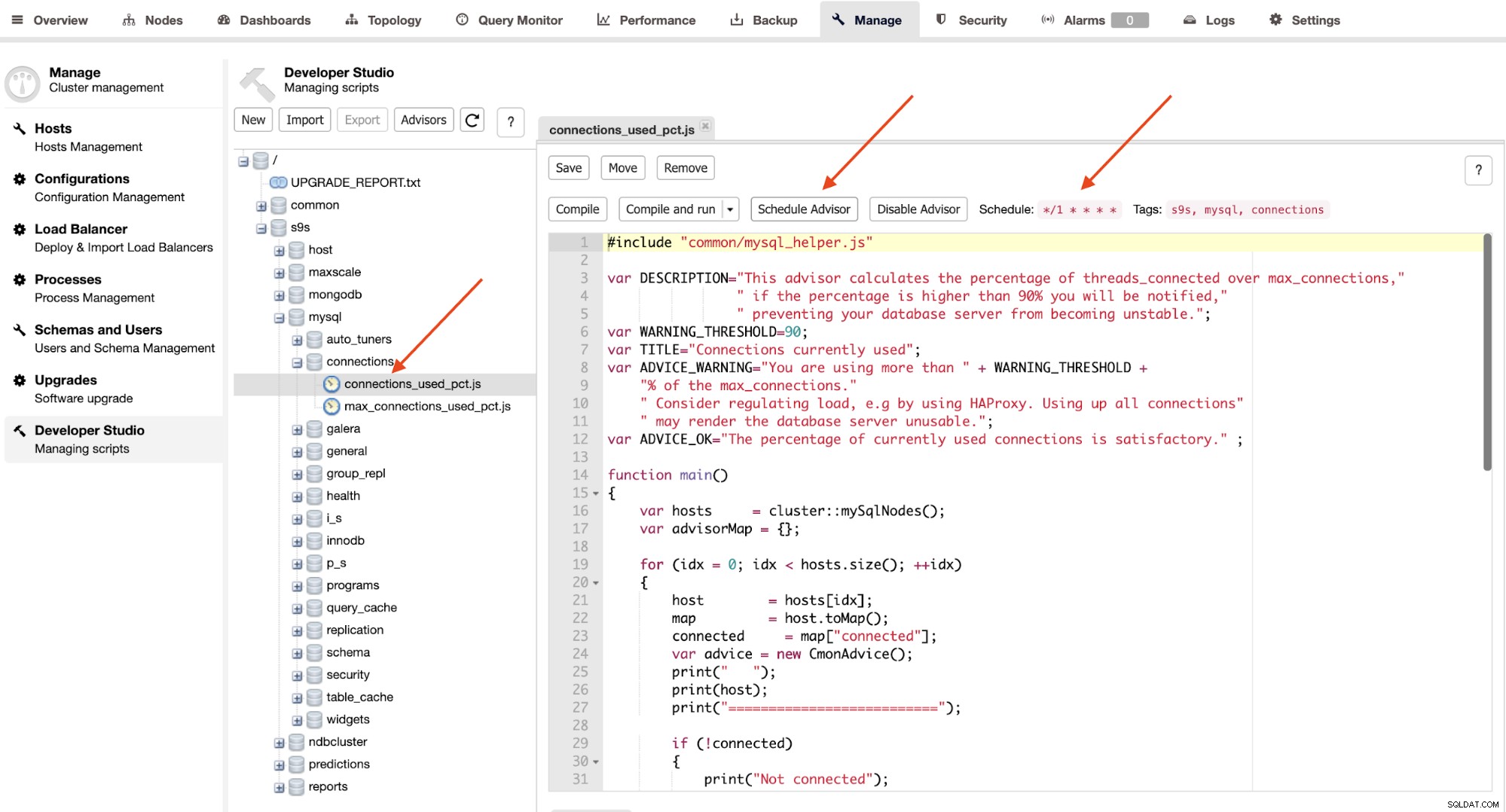
Haga clic en el botón "Asesor de programación" para establecer el argumento de programación en pase y también las etiquetas del asesor. También puede compilar el asesor para ver el resultado inmediatamente haciendo clic en el botón "Compilar y ejecutar", donde debería ver el siguiente resultado debajo de "Mensajes" debajo:

Puede crear su propio asesor consultando esta Guía para desarrolladores, escrita en Lenguaje específico de dominio de ClusterControl (muy similar a Javascript), o personalice un asesor existente para que se adapte a sus políticas de monitoreo. En resumen, el deber de monitoreo de ClusterControl se puede ampliar con posibilidades ilimitadas a través de ClusterControl Advisors.