Todos ustedes han oído hablar de la escala:su arquitectura debe ser escalable, debe poder escalar para satisfacer la demanda, etc. ¿Qué significa cuando hablamos de bases de datos? ¿Cómo se ve la escala detrás de escena? Este tema es muy amplio y no hay manera de cubrir todos los aspectos. Esta serie de publicaciones de dos blogs es un intento de brindarle una idea del tema de la escalabilidad de la base de datos.
¿Por qué escalamos?
Primero, veamos de qué se trata la escalabilidad. En resumen, estamos hablando de la capacidad de manejar una mayor carga por parte de sus sistemas de base de datos. Puede ser una cuestión de lidiar con picos de actividad de corta duración, puede ser una cuestión de lidiar con una carga de trabajo que aumenta gradualmente en su entorno de base de datos. Puede haber numerosas razones para considerar escalar. La mayoría de ellos vienen con sus propios desafíos. Podemos pasar algún tiempo revisando ejemplos de la situación en la que es posible que deseemos escalar horizontalmente.
Aumento del consumo de recursos
Este es el más genérico:su carga ha aumentado hasta el punto en que sus recursos existentes ya no son capaces de manejarla. Puede ser cualquier cosa. La carga de la CPU ha aumentado y su clúster de base de datos ya no puede entregar datos con un tiempo de ejecución de consultas razonable y estable. La utilización de la memoria ha crecido hasta el punto de que la base de datos ya no está vinculada a la CPU, sino a la E/S y, como tal, el rendimiento de los nodos de la base de datos se ha reducido significativamente. La red también puede ser un cuello de botella. Es posible que se sorprenda al ver qué límites relacionados con las redes tienen asignadas sus instancias en la nube. De hecho, este puede convertirse en el límite más común con el que debe lidiar, ya que la red lo es todo en la nube, no solo los datos enviados entre la aplicación y la base de datos, sino también el almacenamiento conectado a través de la red. También puede ser el uso del disco:simplemente se está quedando sin espacio en el disco o, más probablemente, dado que hoy en día podemos tener discos bastante grandes, el tamaño de la base de datos superó el tamaño "manejable". El mantenimiento, como el cambio de esquema, se convierte en un desafío, el rendimiento se reduce debido al tamaño de los datos, las copias de seguridad tardan años en completarse. Todos esos casos pueden ser un caso válido para la necesidad de ampliación.
Aumento repentino de la carga de trabajo
Otro caso de ejemplo donde se requiere escalar es un aumento repentino en la carga de trabajo. Por alguna razón (ya sea por esfuerzos de marketing, contenido que se vuelve viral, emergencia o una situación similar), su infraestructura experimenta un aumento significativo en la carga del clúster de la base de datos. La carga de la CPU se dispara, la E/S del disco ralentiza las consultas, etc. Casi todos los recursos que mencionamos en la sección anterior pueden sobrecargarse y comenzar a causar problemas.
Operación planificada
La tercera razón que nos gustaría destacar es la más genérica:algún tipo de operación planificada. Puede ser una actividad de marketing planificada que espera atraer más tráfico, Black Friday, pruebas de carga o prácticamente cualquier cosa que sepa de antemano.
Cada una de esas razones tiene sus propias características. Si puede planificar con anticipación, puede preparar el proceso en detalle, probarlo y ejecutarlo cuando lo desee. Lo más probable es que le guste hacerlo en un período de "bajo tráfico", siempre que exista algo así en sus cargas de trabajo (no tiene por qué existir). Por otro lado, los picos repentinos en la carga, especialmente si son lo suficientemente significativos como para afectar la producción, forzarán una reacción inmediata, sin importar qué tan preparado esté y qué tan seguro sea; si sus servicios ya se vieron afectados, es mejor que simplemente hazlo en lugar de esperar.
Tipos de escalado de bases de datos
Hay dos tipos principales de escalado:vertical y horizontal. Ambos tienen pros y contras, ambos son útiles en diferentes situaciones. Echemos un vistazo a ellos y analicemos los casos de uso para ambos escenarios.
Escalado vertical
Este método de escalado es probablemente el más antiguo:si su hardware no es lo suficientemente robusto como para manejar la carga de trabajo, amplíelo. Aquí estamos hablando simplemente de agregar recursos a los nodos existentes con la intención de hacerlos lo suficientemente capaces para hacer frente a las tareas asignadas. Esto tiene algunas repercusiones que nos gustaría repasar.
Ventajas del escalado vertical
Lo más importante es que todo permanece igual. Tenía tres nodos en un clúster de base de datos, todavía tiene tres nodos, solo que más capaces. No hay necesidad de rediseñar su entorno, cambiar la forma en que la aplicación debe acceder a la base de datos; todo permanece exactamente igual porque, en cuanto a la configuración, nada ha cambiado realmente.
Otra ventaja importante del escalado vertical es que puede ser muy rápido, especialmente en entornos de nube. Todo el proceso consiste, básicamente, en detener el nodo existente, realizar el cambio en el hardware y volver a iniciar el nodo. Para configuraciones locales clásicas, sin ninguna virtualización, esto puede ser complicado:es posible que no tenga CPU más rápidas disponibles para intercambiar, actualizar discos a más grandes o más rápidos también puede llevar mucho tiempo, pero para entornos en la nube, ya sea público o privado, esto puede ser tan fácil como ejecutar tres comandos:detener la instancia, actualizar la instancia a un tamaño más grande, iniciar la instancia. Las direcciones IP virtuales y los volúmenes que se pueden volver a conectar facilitan el traslado de datos entre instancias.
Desventajas del escalado vertical
La principal desventaja del escalado vertical es que, simplemente, tiene sus límites. Si está ejecutando en el tamaño de instancia más grande disponible, con los volúmenes de disco más rápidos, no hay mucho más que pueda hacer. Tampoco es tan fácil aumentar significativamente el rendimiento de su clúster de base de datos. Depende principalmente del tamaño de la instancia inicial, pero si ya está ejecutando nodos con un rendimiento bastante alto, es posible que no pueda lograr un escalado horizontal de 10x mediante el escalado vertical. Los nodos que serían 10 veces más rápidos pueden, simplemente, no existir.
Escala horizontal
La escala horizontal es una bestia diferente. En lugar de aumentar el tamaño de la instancia, nos mantenemos en el mismo nivel pero nos expandimos horizontalmente agregando más nodos. De nuevo, hay pros y contras de este método.
Ventajas de la escala horizontal
La principal ventaja de la escala horizontal es que, teóricamente, el cielo es el límite. No existe un límite duro artificial de escalamiento horizontal, aunque existen límites, principalmente debido a que la comunicación dentro del clúster es cada vez mayor con cada nuevo nodo que se agrega al clúster.
Otra ventaja significativa sería que puede ampliar el clúster sin necesidad de tiempo de inactividad. Si desea actualizar el hardware, debe detener la instancia, actualizarla y luego comenzar de nuevo. Si desea agregar más nodos al clúster, todo lo que necesita hacer es aprovisionar esos nodos, instalar el software que necesite, incluida la base de datos, y permitir que se una al clúster. Opcionalmente (dependiendo de si el clúster tiene métodos internos para aprovisionar nuevos nodos con los datos), es posible que deba aprovisionarlo con datos por su cuenta. Sin embargo, normalmente es un proceso automatizado.
Desventajas de la escala horizontal
El principal problema con el que debe lidiar es que agregar más y más nodos dificulta la administración de todo el entorno. Debe poder saber qué nodos están disponibles, dicha lista debe mantenerse y actualizarse con cada nuevo nodo creado. Es posible que necesite soluciones externas como el servicio de directorio (Consul o Etcd) para realizar un seguimiento de los nodos y su estado. Esto, obviamente, aumenta la complejidad de todo el entorno.
Otro problema potencial es que el proceso de escalado lleva tiempo. Agregar nuevos nodos y aprovisionarlos con software y, especialmente, datos requiere tiempo. Cuánto depende del hardware (principalmente E/S y rendimiento de la red) y el tamaño de los datos. Para configuraciones grandes, esto puede ser una cantidad significativa de tiempo y esto puede ser un obstáculo para situaciones en las que la ampliación tiene que ocurrir de inmediato. Las horas de espera para agregar nuevos nodos pueden no ser aceptables si el clúster de la base de datos se ve afectado en la medida en que las operaciones no se realizan correctamente.
Requisitos previos de escala
Replicación de datos
Antes de que se pueda intentar escalar, su entorno debe cumplir con un par de requisitos. Para empezar, su aplicación debe poder aprovechar más de un nodo. Si puede usar solo un nodo, sus opciones están bastante limitadas a la escala vertical. Puede aumentar el tamaño de dicho nodo o agregar algunos recursos de hardware al servidor bare metal y hacerlo más eficiente, pero eso es lo mejor que puede hacer:siempre estará limitado por la disponibilidad de hardware con mayor rendimiento y, eventualmente, encontrará usted mismo sin una opción para escalar aún más.
Por otro lado, si tiene los medios para utilizar varios nodos de base de datos en su aplicación, puede beneficiarse del escalado horizontal. Detengámonos aquí y discutamos qué es lo que necesita para usar múltiples nodos en todo su potencial.
Para empezar, la capacidad de dividir las lecturas de las escrituras. Tradicionalmente, la aplicación se conecta a un solo nodo. Ese nodo se usa para manejar todas las escrituras y todas las lecturas ejecutadas por la aplicación.

Agregar un segundo nodo al clúster, desde el punto de vista de la escala, no cambia nada . Debe tener en cuenta que, si un nodo falla, el otro tendrá que manejar el tráfico, por lo que en ningún momento la suma de la carga en ambos nodos debe ser demasiado alta para que la maneje un solo nodo.

Con tres nodos disponibles, puede utilizar completamente dos nodos. Esto nos permite escalar horizontalmente parte del tráfico de lectura:si un nodo tiene una capacidad del 100 % (y preferimos ejecutar como máximo el 70 %), entonces dos nodos representan el 200 %. Tres nodos:300%. Si un nodo está inactivo y empujamos los nodos restantes casi al límite, podemos decir que podemos trabajar con 170 - 180% de la capacidad de un solo nodo si el clúster se degrada. Eso nos da una buena carga del 60 % en cada nodo si los tres nodos están disponibles.
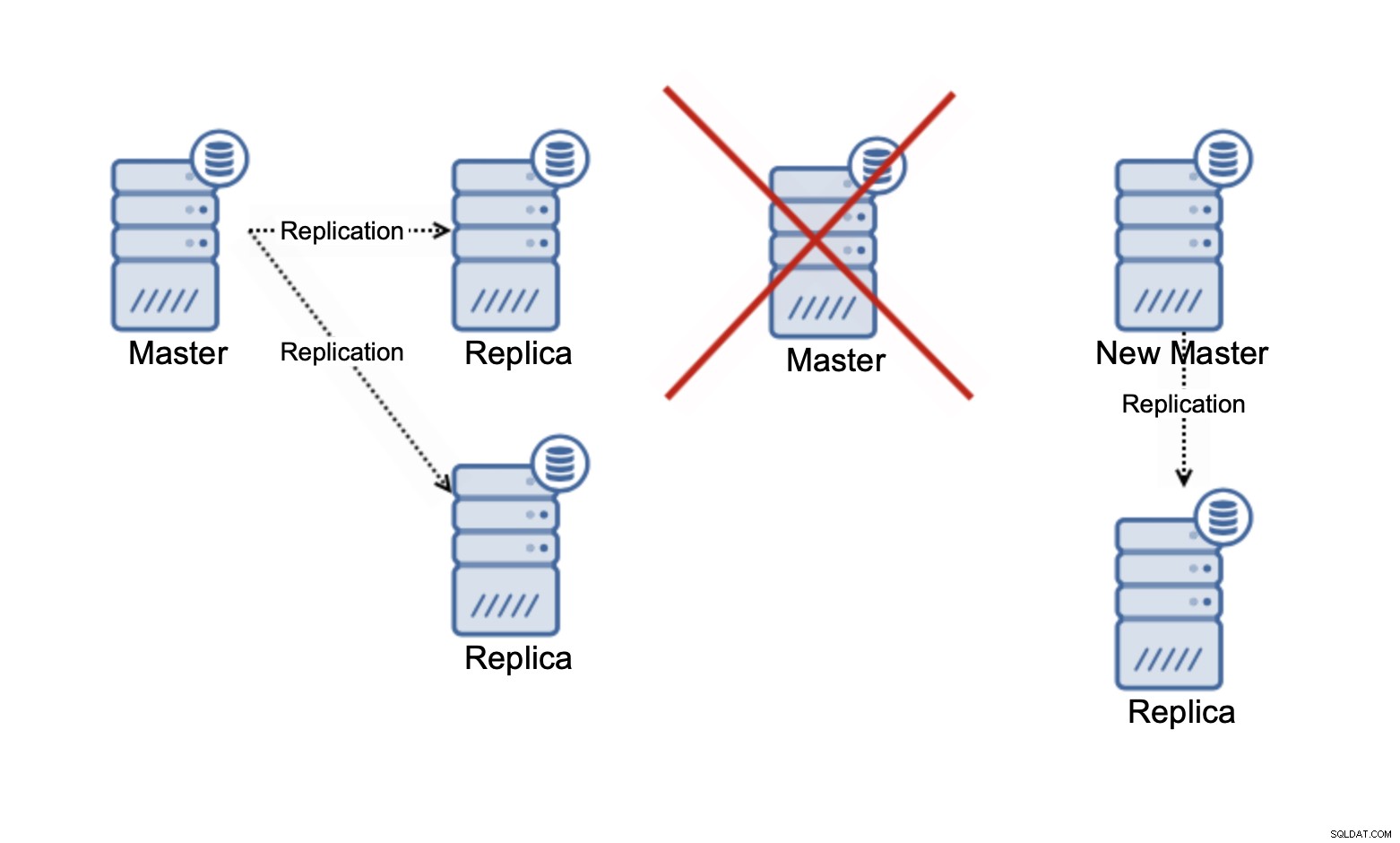
Por favor, tenga en cuenta que solo estamos hablando de escalar lecturas en este momento . En ningún momento la replicación puede mejorar su capacidad de escritura. En la replicación asíncrona, solo tiene un escritor (maestro), y para la replicación síncrona, como Galera, donde el conjunto de datos se comparte entre todos los nodos, cada escritura que ocurre en un nodo deberá realizarse en los nodos restantes del grupo.
En un clúster de Galera de tres nodos, si escribe una fila, de hecho escribe tres filas, una para cada nodo. Agregar más nodos o réplicas no hará la diferencia. En lugar de escribir la misma fila en tres nodos, la escribirá en cinco. Esta es la razón por la que dividir sus escrituras en un clúster multimaestro, donde el conjunto de datos se comparte entre todos los nodos (hay clústeres multimaestros donde los datos se fragmentan, por ejemplo MySQL NDB Cluster; aquí la historia de escalabilidad de escritura es totalmente diferente), no tiene demasiado sentido. Agrega la sobrecarga de lidiar con posibles conflictos de escritura en todos los nodos, mientras que en realidad no cambia nada con respecto a la capacidad de escritura total.
Equilibrio de carga y división de lectura/escritura
La capacidad de dividir las lecturas de las escrituras es imprescindible si desea escalar sus lecturas en configuraciones de replicación asincrónica. Debe poder enviar tráfico de escritura a un nodo y luego enviar las lecturas a todos los nodos en la topología de replicación. Como mencionamos anteriormente, esta funcionalidad también es bastante útil en los clústeres multimaestros, ya que nos permite eliminar los conflictos de escritura que pueden ocurrir si intenta distribuir las escrituras en varios nodos del clúster. ¿Cómo podemos realizar la división de lectura/escritura? Hay varios métodos que puede utilizar para hacerlo. Profundicemos un poco en este tema.
División L/E del nivel de la aplicación
El escenario más simple, el menos frecuente también:su aplicación puede configurar qué nodos deben recibir escrituras y qué nodos deben recibir lecturas. Esta funcionalidad se puede configurar de varias maneras, la más simple es la lista codificada de los nodos, pero también podría ser algo similar al inventario de nodos dinámicos actualizado por subprocesos en segundo plano. El principal problema con este enfoque es que toda la lógica debe escribirse como parte de la aplicación. Con una lista codificada de nodos, el escenario más simple requeriría cambios en el código de la aplicación para cada cambio en la topología de replicación. Por otro lado, las soluciones más avanzadas, como implementar un descubrimiento de servicios, serían más complejas de mantener a largo plazo.
División R/W en conector
Otra opción sería usar un conector para realizar una división de lectura/escritura. No todos tienen esta opción, pero algunos sí. Un ejemplo sería php-mysqlnd o Connector/J. Cómo se integra en la aplicación, puede diferir según el conector en sí. En algunos casos, la configuración debe realizarse en la aplicación, en otros casos, debe realizarse en un archivo de configuración separado para el conector. La ventaja de este enfoque es que incluso si tiene que ampliar su aplicación, la mayor parte del código nuevo está listo para usar y mantenido por fuentes externas. Facilita el manejo de dicha configuración y tiene que escribir menos código (si corresponde).
División R/W en el equilibrador de carga
Finalmente, una de las mejores soluciones:los balanceadores de carga. La idea es simple:pase sus datos a través de un equilibrador de carga que podrá distinguir entre lecturas y escrituras y enviarlos a una ubicación adecuada. Esta es una gran mejora desde el punto de vista de la usabilidad, ya que podemos separar el descubrimiento de la base de datos y el enrutamiento de consultas de la aplicación. Lo único que tiene que hacer la aplicación es enviar el tráfico de la base de datos a un punto final único que consta de un nombre de host y un puerto. El resto sucede en segundo plano. Los equilibradores de carga están trabajando para enrutar las consultas a los nodos de una base de datos de back-end. Los equilibradores de carga también pueden hacer descubrimiento de topología de replicación o puede implementar un inventario de servicio adecuado usando etcd o consul y actualizarlo a través de sus herramientas de orquestación de infraestructura como Ansible.
Esto concluye la primera parte de este blog. En el segundo, discutiremos los desafíos que enfrentamos al escalar el nivel de la base de datos. También discutiremos algunas formas en las que podemos escalar nuestros clústeres de bases de datos.