UUID
devuelve un identificador único universal
(esperemos que también sea único si también se importa a otra base de datos).
Para citar de MySQL doc (énfasis mío):
Por otro lado, simplemente INT clave de identificación principal (por ejemplo, AUTO_INCREMENT ) devolverá un entero único para la base de datos específica y la tabla de base de datos, pero que no es universalmente única (Entonces, si se importa a otra base de datos, es probable que haya conflictos de clave principal).
En términos de rendimiento, no debería haber ninguna diferencia notable usando auto-increment sobre UUID . La mayoría de las publicaciones (incluidas algunas de los autores de este sitio) se declaran como tales. Por supuesto UUID puede tomar un poco más de tiempo (y espacio), pero esto no es un cuello de botella de rendimiento en la mayoría de los casos (si no en todos). Tener una columna como Primary Key debe hacer que ambas opciones sean iguales al rendimiento. Consulte las referencias a continuación:
- Para
UUIDo no aUUID? - Mitos,
GUIDvsAutoincrement - Rendimiento:
UUIDvsauto-incrementen cakephp-mysql UUIDrendimiento en MySQL?- Claves primarias:
IDs frente aGUIDs (codificando horror)
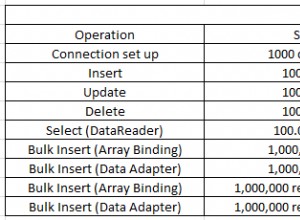
(UUID vs auto-increment resultados de rendimiento, adaptados de Mitos, GUID vs Autoincrement
)

UUID pros/contras (adaptado de Claves primarias:ID s frente a GUID s
)
Nota
Leería atentamente las referencias mencionadas y decidiría si usar UUID o no dependiendo de mi caso de uso. Dicho esto, en muchos casos UUID s sería de hecho preferible. Por ejemplo, uno puede generar UUID s sin usar/acceder a la base de datos en absoluto, o incluso usar UUID s que han sido previamente calculados y/o almacenados en otro lugar. Además, puede generalizar/actualizar fácilmente el esquema de su base de datos y/o el esquema de agrupación sin tener que preocuparse por ID s rompiendo y causando conflictos.
En términos de posibles colisiones, por ejemplo usando v4 UUIDS (aleatorio), la probabilidad de encontrar un duplicado dentro de 103 billones de UUID versión 4 es uno en mil millones.