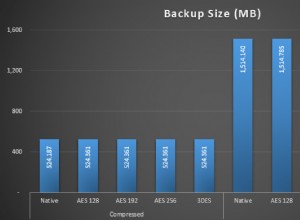
Me encantaría dar una respuesta específica, pero necesitaría ayuda para comprender su proceso de pensamiento...
Comienza escribiendo:
Pero luego sigues escribiendo:
Para mí, la última especificación tiene poco sentido a la luz de la primera observación.
Imho, lo que realmente quieres es que los usuarios tengan la misma cantidad de oportunidades para votar en cada automóvil. O más precisamente, votar por cada automóvil en comparación con otros automóviles.
Si asume que las variables (automóvil) son independientes, entonces debe llevar la cuenta de cuántas veces surgió una opción, en lugar de cuántas veces se votó, y ajustar su proceso de decisión en consecuencia. Es un problema matemático, no es tan feo, y luego se puede traducir a SQL para bien o para mal; me atrevo a decir que probablemente será peor.
Si asume, como yo, que no son independientes, también debe tener en cuenta las correlaciones y almacenar cuántas veces se encontraron entre sí. Porque, bueno, hay una posibilidad infinitamente pequeña de que no prefiera este Mercedes en lugar de ese Tata, ese Xinkai o ese AvtoVAZ. Pero ante la posibilidad de elegir entre el mismo Mercedes, un BMW, un Porsche y un Ferrari, la decisión podría no ser tan clara.
En otras palabras, su especificación no responde en absoluto al problema tal como lo presentó.
Actualmente estoy rogando estar de acuerdo con la respuesta publicada hace dos horas:selecciónelos realmente al azar y estará satisfecho sin código adicional...
Como nota al margen, si sus identificaciones realmente no tienen espacios, genere cuatro identificaciones en php o lo que sea y obténgalas usando un in() declaración. No será más eficiente que eso.