PostgreSQL, también conocida como la base de datos de código abierto más avanzada del mundo, tiene una nueva versión de lanzamiento desde el pasado 24 de septiembre de 2020, y ahora que está madura, podemos revisar las novedades allí para comenzar a pensar en una plano de migracion PostgreSQL 13 está disponible con muchas funciones y mejoras nuevas. En este blog, mencionaremos algunas de estas nuevas funciones y veremos cómo implementar o actualizar su versión actual de PostgreSQL.
Nuevas características y mejoras de PostgreSQL 13
Empecemos mencionando algunas de las nuevas características y mejoras de esta versión de PostgreSQL 13 que puedes ver en la Documentación Oficial.
Particionamiento
-
Permitir la poda de particiones y uniones entre particiones en más casos
-
Admite disparadores ANTES de nivel de fila en tablas particionadas
-
Permitir que las tablas particionadas se repliquen lógicamente a través de la publicación
-
Permitir replicación lógica en tablas particionadas en suscriptores
-
Permitir el uso de variables de fila completa en expresiones de partición
Índices
-
Almacenar duplicados de manera más eficiente en índices de árbol B
-
Permitir índices GiST y SP-GiST en columnas de cuadro para admitir consultas de punto <-> de cuadro ORDER BY
-
¡Permita que los índices GIN manejen de manera más eficiente! (NOT) cláusulas en búsquedas tsquery
-
Permitir que las clases de operadores de índice tomen parámetros
Optimizador
-
Mejorar la estimación de selectividad del optimizador para operadores de contención/coincidencia
-
Permitir establecer el objetivo de estadísticas para estadísticas extendidas
-
Permitir el uso de múltiples objetos de estadísticas extendidas en una sola consulta
-
Permitir el uso de objetos de estadísticas extendidas para cláusulas OR y listas de constantes IN/ANY
-
Permitir que las funciones en las cláusulas FROM se extraigan (en línea) si se evalúan como constantes
Rendimiento
-
Implemente la ordenación incremental y mejore el rendimiento de la ordenación de valores inet
-
Permitir agregación de hash para usar almacenamiento en disco para grandes conjuntos de resultados de agregación
-
Permitir inserciones, no solo actualizaciones y eliminaciones, para activar la actividad de aspiración en autovacuum
-
Agregue el parámetro maintenance_io_concurrency para controlar la concurrencia de E/S para las operaciones de mantenimiento
-
Permitir que se omitan las escrituras WAL durante una transacción que crea o reescribe una relación, si wal_level es mínimo
-
Mejore el rendimiento al reproducir comandos DROP DATABASE cuando se utilizan muchos espacios de tablas
-
Acelere las conversiones de enteros a texto
-
Reduzca el uso de memoria para cadenas de consulta y secuencias de comandos de extensión que contienen muchas instrucciones SQL
Monitoreo
-
Permitir EXPLAIN, auto_explain, autovacuum y pg_stat_statements para realizar un seguimiento de las estadísticas de uso de WAL
-
Permitir registrar una muestra de sentencias SQL, en lugar de todas las sentencias
-
Agregue el tipo de backend a csvlog y, opcionalmente, la salida de registro log_line_prefix
-
Mejore el control del registro de parámetros de declaraciones preparadas
-
Agregue leader_pid a pg_stat_activity para informar un proceso de líder de trabajador paralelo
-
Agregue la vista del sistema pg_stat_progress_basebackup para informar el progreso de las copias de seguridad de la base de transmisión
-
Agregue la vista del sistema pg_stat_progress_analyze para informar el progreso de ANALYZE
-
Agregue la vista del sistema pg_shmem_allocations para mostrar el uso de la memoria compartida
Replicación y recuperación
-
Permitir cambiar los ajustes de configuración de la replicación de transmisión mediante la recarga
-
Permitir que los receptores WAL usen una ranura de replicación temporal cuando no se especifica una permanente
-
Permitir que el almacenamiento WAL para las ranuras de replicación esté limitado por max_slot_wal_keep_size
-
Permitir promoción en espera para cancelar cualquier pausa solicitada
-
Genera un error si la recuperación no alcanza el objetivo de recuperación especificado
-
Permite controlar la cantidad de memoria utilizada por la decodificación lógica antes de que se derrame en el disco
-
Permitir que la recuperación continúe incluso si WAL hace referencia a páginas no válidas
Comandos de utilidad
-
Permitir que VACUUM procese los índices de una tabla en paralelo
-
Informar el uso del búfer en tiempo de planificación en la salida BUFFER de EXPLAIN
-
Haga que CREATE TABLE LIKE propague la propiedad NO INHERIT de una restricción CHECK a la tabla creada
-
Agregue ALTER TABLE... DROP EXPRESSION para permitir eliminar la propiedad GENERATED de una columna
-
Agregue la sintaxis ALTER VIEW para cambiar el nombre de las columnas de vista
-
Agregue opciones ALTER TYPE para modificar las propiedades TOAST de un tipo base y las funciones de soporte
-
Añadir opción CREAR BASE DE DATOS LOCAL
-
Permitir DROP DATABASE para desconectar sesiones utilizando la base de datos de destino, lo que permite que la eliminación se realice correctamente
Y muchos cambios más. Solo mencionamos algunos de ellos para evitar una publicación de blog más grande. Ahora, veamos cómo implementar esta nueva versión.
Cómo implementar PostgreSQL 13
Para esto, asumiremos que tiene instalado ClusterControl, de lo contrario, puede seguir la documentación correspondiente para instalarlo.
Para realizar un deployment desde ClusterControl, simplemente seleccione la opción Deploy y siga las instrucciones que aparecen.
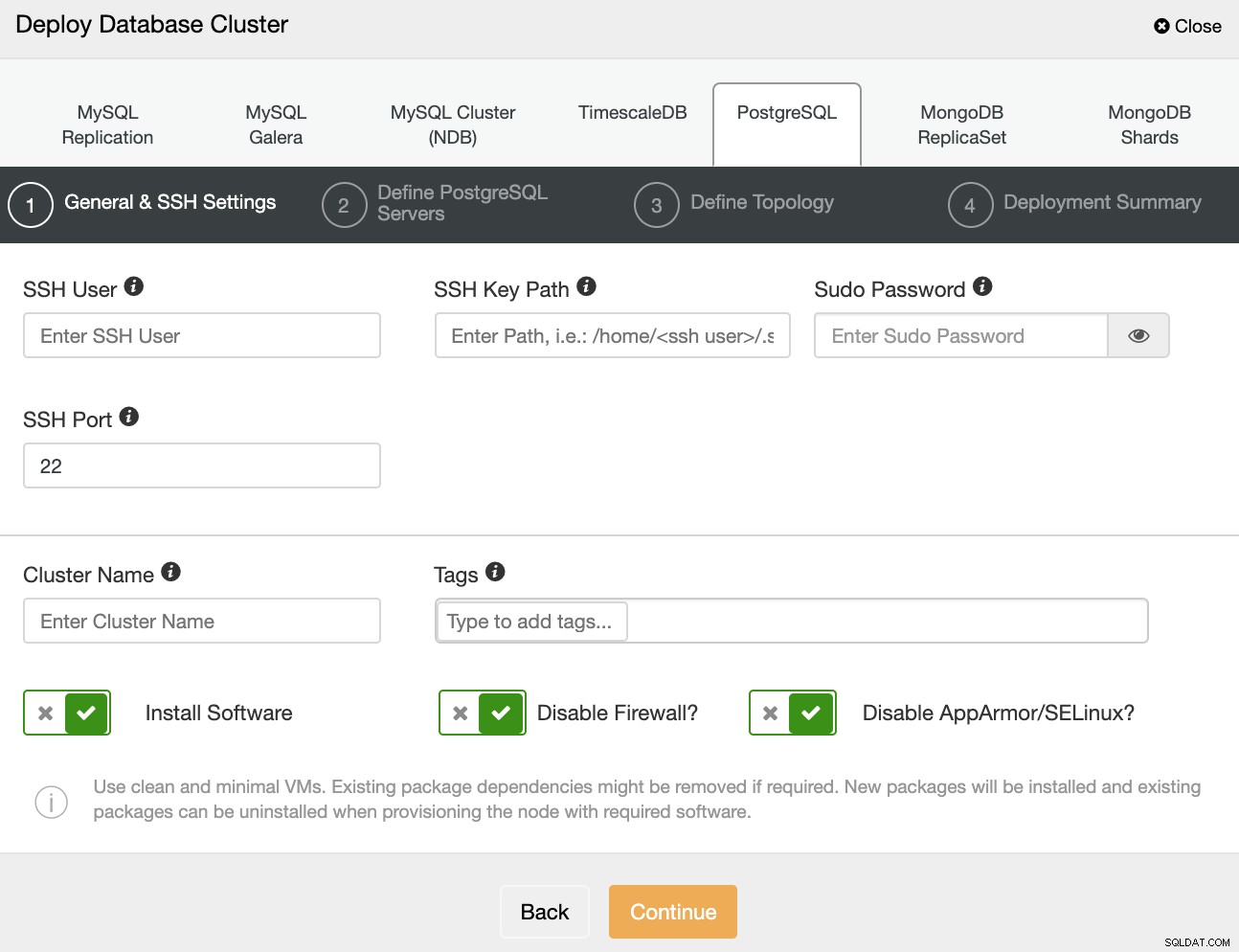
Al seleccionar PostgreSQL, debe especificar Usuario, Clave o Contraseña y Puerto para conectarse por SSH a sus servidores. También puede agregar un nombre para su nuevo clúster y si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
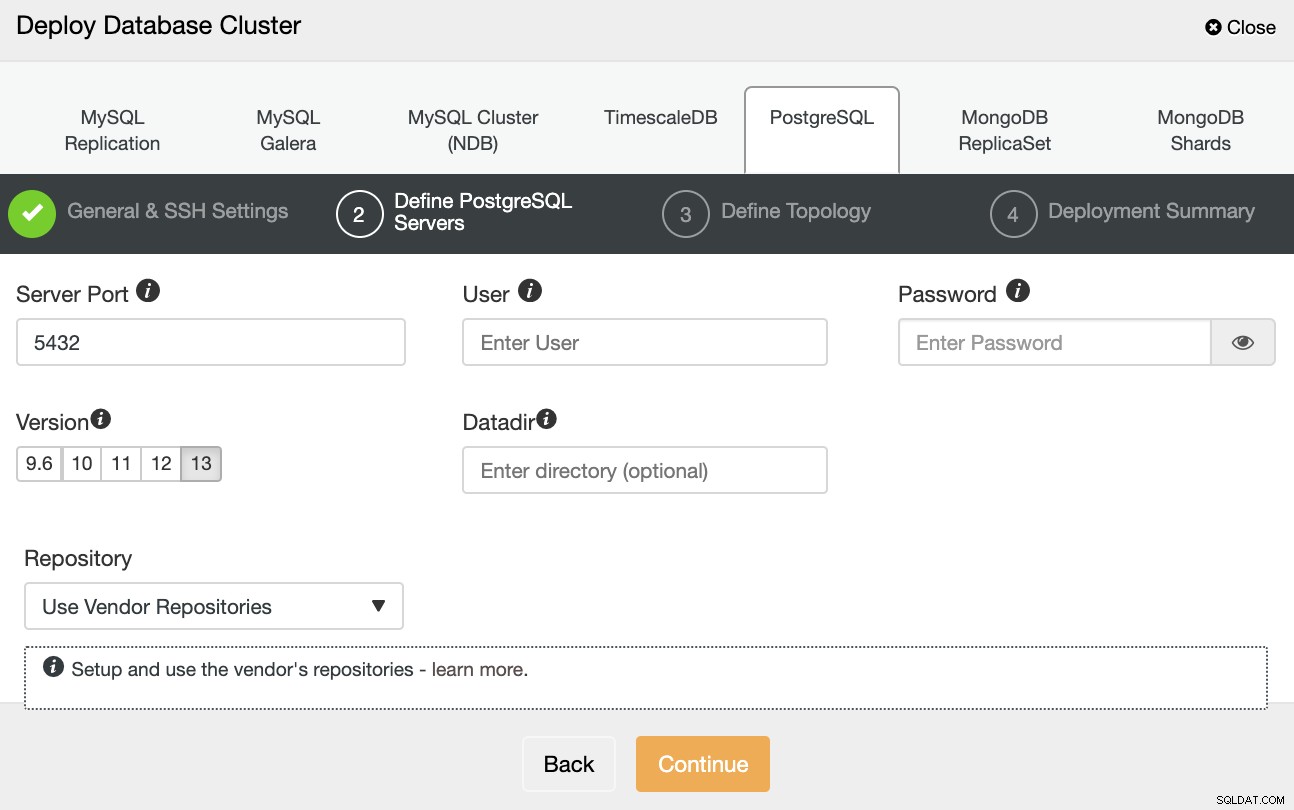
Después de configurar la información de acceso SSH, debe definir las credenciales de la base de datos , versión y datadir (opcional). También puede especificar qué repositorio usar.
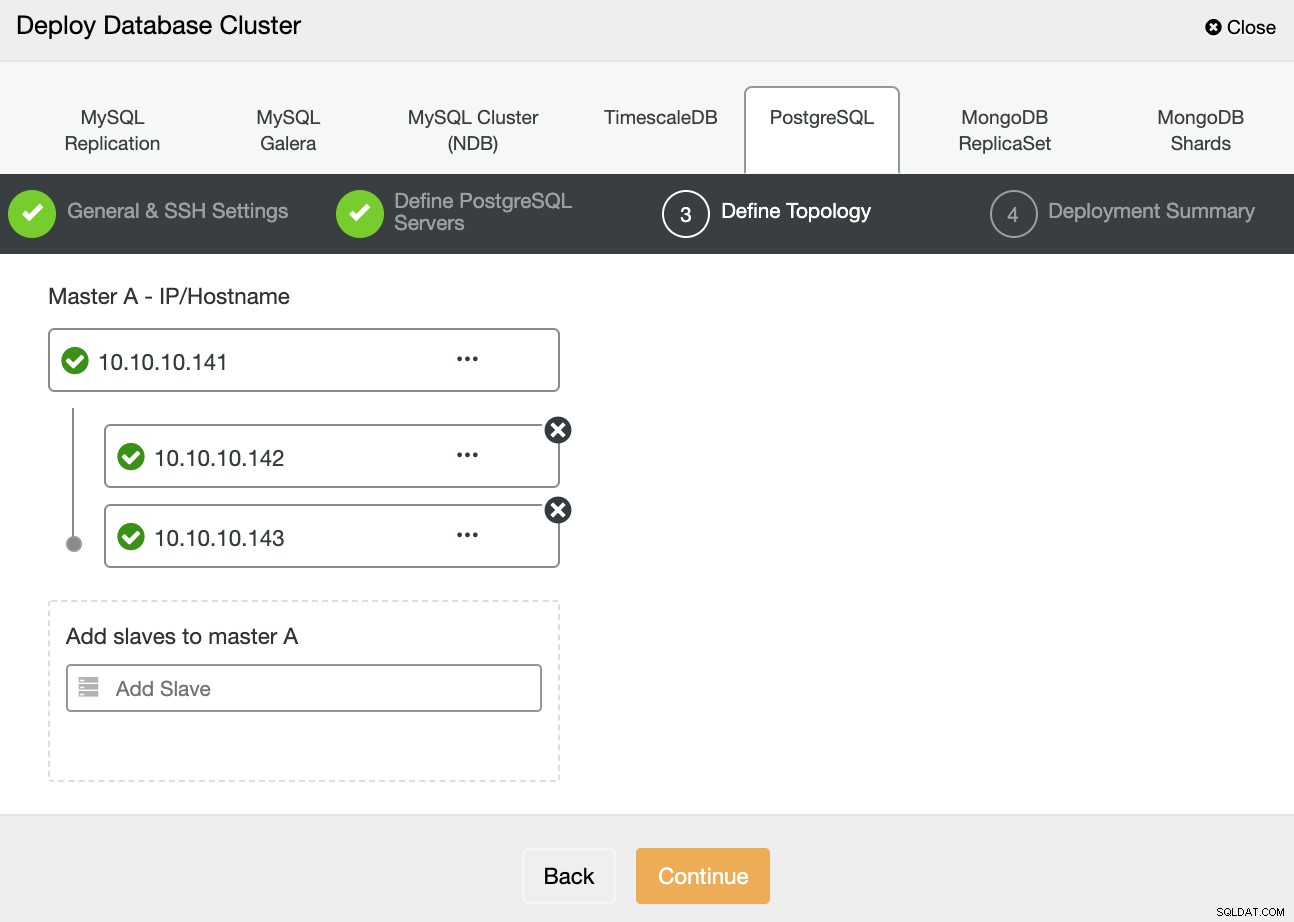
En el siguiente paso, debe agregar sus servidores al clúster que va a crear utilizando la dirección IP o el nombre de host.
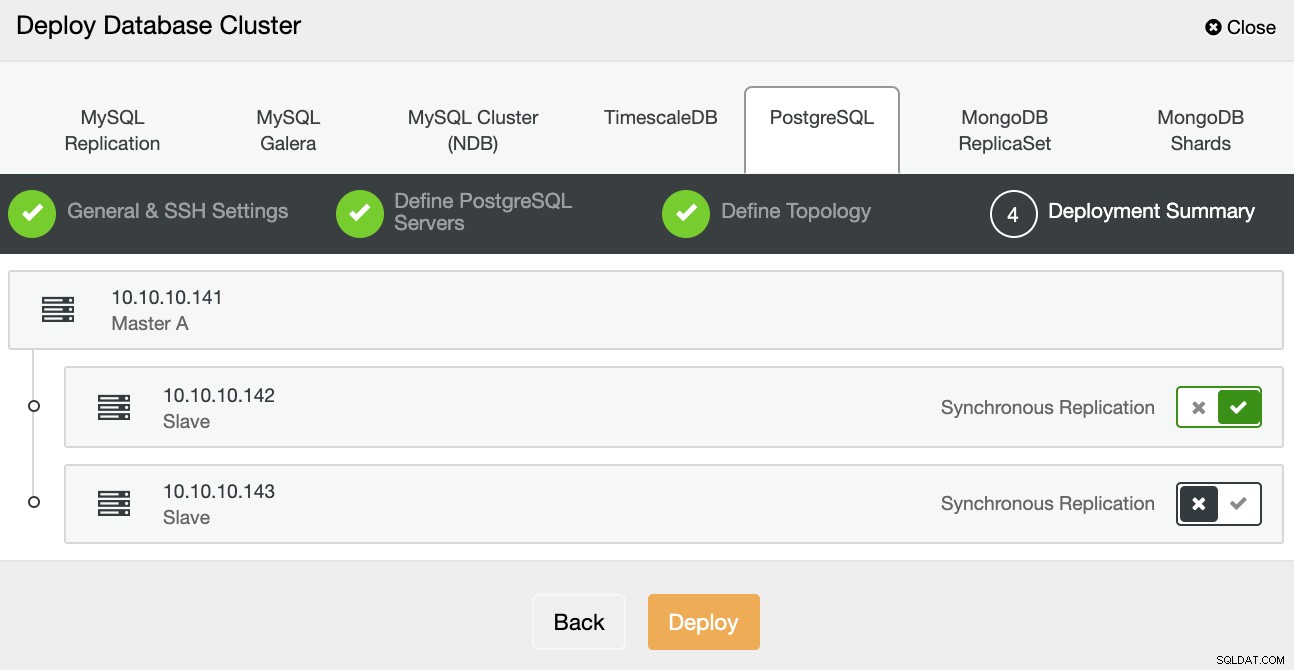
En el último paso, puede elegir si su replicación será Síncrona o Asíncrono, y luego simplemente presione Implementar.
Una vez finalizada la tarea, puede ver su nuevo clúster de PostgreSQL en la pantalla principal de ClusterControl.

Ahora que ha creado su clúster, puede realizar varias tareas en él, como agregar balanceadores de carga (HAProxy), agrupadores de conexión (PgBouncer) o nuevos esclavos de replicación desde la misma interfaz de usuario de ClusterControl.
Actualización a PostgreSQL 13
Si desea actualizar su versión actual de PostgreSQL a esta nueva, tiene tres opciones principales que realizarán esta tarea.
-
Pg_dump:Es una herramienta de respaldo lógico que le permite volcar sus datos y restaurarlos en el nuevo PostgreSQL versión. Aquí tendrá un período de inactividad que variará según el tamaño de sus datos. Debe detener el sistema o evitar nuevos datos en el nodo principal, ejecutar pg_dump, mover el volcado generado al nuevo nodo de la base de datos y restaurarlo. Durante este tiempo, no puede escribir en su base de datos principal de PostgreSQL para evitar inconsistencias en los datos.
-
Pg_upgrade:es una herramienta de PostgreSQL para actualizar su versión de PostgreSQL en el lugar. Podría ser peligroso en un entorno de producción y no recomendamos este método en ese caso. Con este método, también tendrá tiempo de inactividad, pero probablemente será considerablemente menor que con el método pg_dump anterior.
-
Replicación lógica:desde PostgreSQL 10, puede usar este método de replicación que le permite realizar actualizaciones de versiones principales con cero (o casi cero) tiempo de inactividad. De esta forma, puede agregar un nodo en espera en la última versión de PostgreSQL, y cuando la replicación esté actualizada, puede realizar un proceso de conmutación por error para promover el nuevo nodo de PostgreSQL.
Para obtener información más detallada sobre las nuevas características de PostgreSQL 13, puede consultar la Documentación oficial.



