Si tu sistema se basa en PostgreSQL y buscas soluciones de clustering para Alta Disponibilidad, queremos adelantarte que es una tarea compleja pero no imposible de lograr.
Teniendo en cuenta sus requisitos de tolerancia a fallas, aquí hay algunas soluciones de agrupación en clústeres de alta disponibilidad para elegir que pueden ayudar.
PostgreSQL no es compatible de forma nativa con ninguna solución de agrupación en clústeres multimaestro como MySQL u Oracle. Sin embargo, muchos productos comerciales y comunitarios ofrecen esta implementación, incluida la replicación y el equilibrio de carga para PostgreSQL.
Para empezar, repasemos algunos conceptos básicos:
¿Qué es la alta disponibilidad?
La alta disponibilidad se refiere a la cantidad de tiempo que un servicio está disponible y generalmente se define por el nivel de rendimiento acordado de una empresa.
La redundancia es la base de la alta disponibilidad; en caso de incidente, puede continuar operando y accediendo a los sistemas sin problemas.
Recuperación continua
Cuando ocurre un incidente, si tiene que restaurar una copia de seguridad y luego aplicar los registros WAL (Write-Ahead Logging), el tiempo de recuperación sería muy alto y no tendría alta disponibilidad.
Sin embargo, si tiene las copias de seguridad y los registros archivados en un servidor de contingencia, puede aplicar los registros a medida que llegan. Si los logs se envían y aplican cada minuto, la base de contingencia estaría en recuperación continua y tendría un estado de desactualización a la producción de como máximo un minuto.
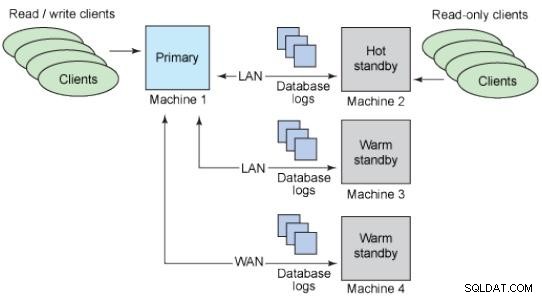
Bases de datos en espera
La idea de una base de datos standby es mantener una copia de una base de datos de producción que siempre tiene los mismos datos y está lista para usarse en caso de un incidente.
Hay varias formas de clasificar una base de datos en espera.
Por la naturaleza de la replicación:
-
Standby físicos:se copian bloques de disco.
-
Esperas lógicas:Streaming de los cambios de datos.
Por la sincronicidad de las transacciones:
-
Asíncrono:existe la posibilidad de pérdida de datos.
-
Sincrónico:No hay posibilidad de pérdida de datos; Los commits en el maestro esperan la respuesta del standby.
Por el uso:
-
Esperas cálidas:no admiten conexiones.
-
Hot standbys:Admite conexiones de solo lectura.
Clústeres
Un clúster es un grupo de hosts que trabajan juntos y se ven como uno solo. Esto proporciona una forma de lograr escalabilidad horizontal y la capacidad de procesar más trabajo agregando servidores.
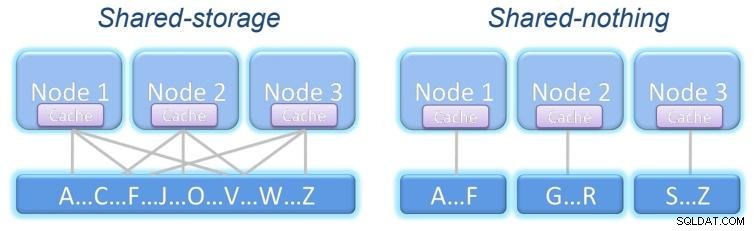
Puede resistir la falla de un nodo y continuar trabajando de forma transparente. Según lo que se comparta, existen dos modelos de clúster:
-
Almacenamiento compartido:Todos los nodos acceden al mismo almacenamiento con la misma información.
-
Nada compartido:cada nodo tiene su propio almacenamiento, que puede o no tener la misma información que el otro nodos, dependiendo de la estructura de nuestro sistema.
Revisemos ahora algunas de las opciones de agrupación que tenemos en PostgreSQL.
Dispositivo de bloque replicado distribuido
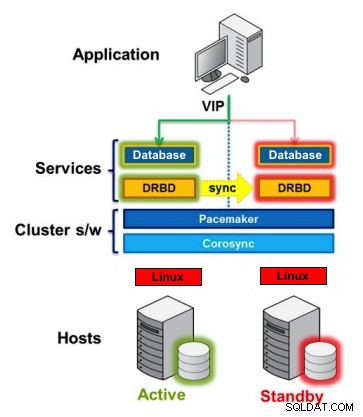
DRBD es un módulo del kernel de Linux que implementa la replicación de bloques síncrona usando la red. En realidad, no implementa un clúster y no maneja la conmutación por error ni la supervisión. Necesita un software complementario para eso, por ejemplo, Corosync + Pacemaker + DRBD.
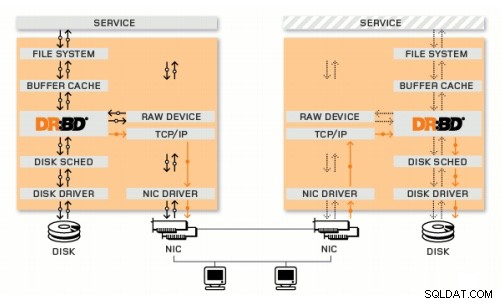
Ejemplo:
-
Corosync:maneja mensajes entre hosts.
-
Marcapasos:inicia y detiene los servicios, asegurándose de que se ejecuten solo en un host.
-
DRBD:Sincroniza los datos a nivel de dispositivos de bloque.
Control de clúster
ClusterControl es un software de gestión y automatización sin agentes para clústeres de bases de datos. Ayuda a implementar, monitorear, administrar y escalar su servidor/clúster de base de datos directamente desde su interfaz de usuario. Puede manejar la mayoría de las tareas de administración necesarias para mantener servidores de bases de datos o clústeres.
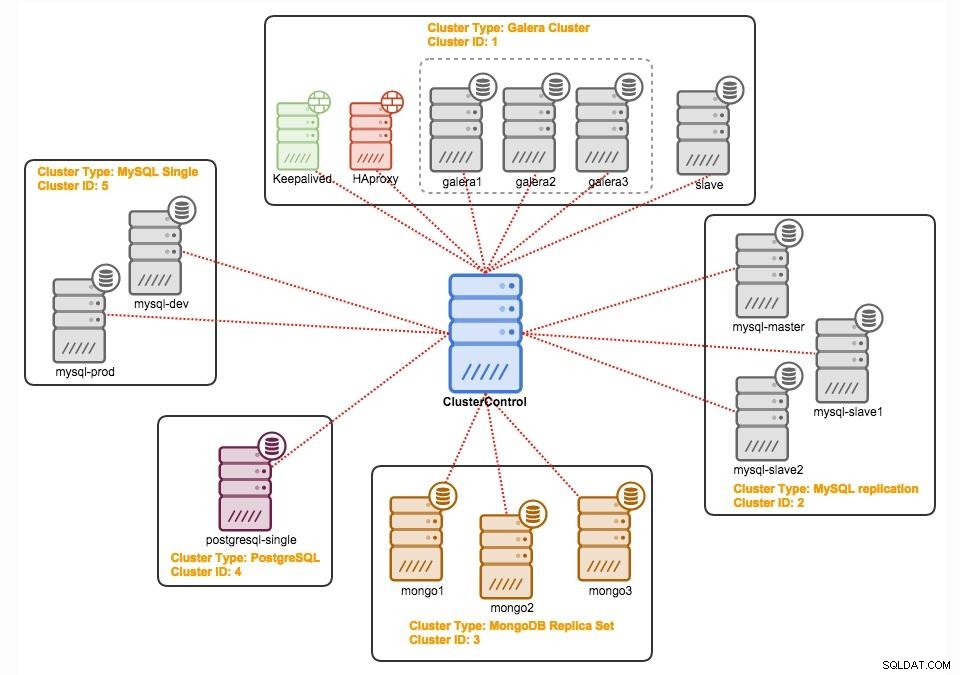
Con ClusterControl, puede:
-
Implemente bases de datos independientes, replicadas o agrupadas en la pila de tecnología de su elección.
-
Automatice las tareas diarias, de recuperación y de conmutación por error de manera uniforme en bases de datos políglotas e infraestructuras dinámicas.
-
Cree copias de seguridad completas o incrementales manualmente o prográmelas.
-
Haga un monitoreo unificado y completo en tiempo real de toda su base de datos e infraestructura de servidor.
-
Agregue o elimine fácilmente un nodo con una sola acción.
-
Clonar su clúster en otro centro de datos/proveedor de la nube
Si tiene un incidente en PostgreSQL, su nodo Standby puede ser promovido a Primario automáticamente.
Es una herramienta completa que ofrece administración y automatización del ciclo de vida de operaciones completas a través de un único panel de vidrio. ClusterControl también ofrece una prueba gratuita de 30 días para que pueda evaluarlo, sin condiciones.
Rep.Rubí
Rubyrep es una solución que proporciona replicación asíncrona, multimaestro, multiplataforma (implementada en Ruby o JRuby) y multi-DBMS (MySQL o PostgreSQL).
Se basa en activadores y no es compatible con DDL, usuarios ni concesiones. La sencillez de uso y administración es su principal objetivo.
Algunas características incluyen:
-
Configuración sencilla
-
Instalación sencilla
-
Independiente de la plataforma, independiente del diseño de la mesa.
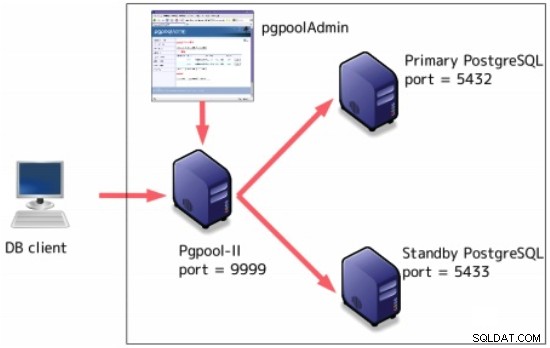
Pgpool-II
Pgpool-II es un middleware que funciona entre servidores PostgreSQL y un cliente de base de datos PostgreSQL.
Algunas características incluyen:
-
Grupo de conexiones
-
Replicación
-
Equilibrio de carga
-
Conmutación automática por error
-
Consultas paralelas
Se puede configurar además de la replicación de transmisión:
Bucardo
Bucardo ofrece replicación maestro-esclavo en cascada asíncrona, basada en filas, usando activadores y colas en la base de datos, y replicación asíncrona maestro-maestro, basada en filas, usando disparadores y resolución de conflictos personalizada.
Bucardo requiere una base de datos dedicada y se ejecuta como un demonio Perl que se comunica con esta base de datos y todas las demás bases de datos involucradas en la replicación. Puede ejecutarse como multimaestro o multiesclavo.
La replicación maestro-esclavo involucra una o más fuentes que van a uno o más destinos. El origen debe ser PostgreSQL, pero los destinos pueden ser PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite o MongoDB.
Algunas características incluyen:
-
Equilibrio de carga
-
Los esclavos no están restringidos y se pueden escribir
-
Replicación parcial
-
Replicación bajo demanda (los cambios se pueden enviar automáticamente o cuando se desee)
-
Los esclavos se pueden "precalentar" para una configuración rápida
Inconvenientes:
-
No se puede manejar DDL
-
No puede manejar objetos grandes
-
No se pueden replicar tablas de forma incremental sin una clave única
-
No funcionará en versiones anteriores a Postgres 8
Postgres-XC
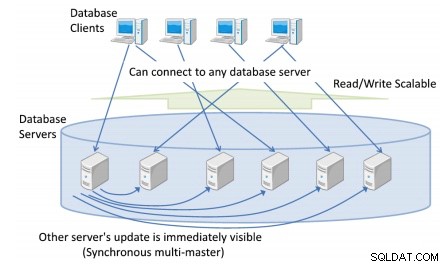
Postgres-XC es un proyecto de código abierto para proporcionar una solución de clúster de PostgreSQL escalable, síncrona, simétrica y transparente. Es una colección de componentes de base de datos estrechamente acoplados que se pueden instalar en más de un hardware o máquina virtual.
Escritura escalable significa que Postgres-XC se puede configurar con tantos servidores de base de datos como desee y manejar muchas más escrituras (actualización de sentencias SQL) en comparación con lo que puede hacer un solo servidor de base de datos.
Puede tener más de un servidor de base de datos al que se conecten los clientes, lo que proporciona una vista única y uniforme de la base de datos en todo el clúster.
Cualquier actualización de base de datos desde cualquier servidor de base de datos es inmediatamente visible para cualquier otra transacción que se ejecute en diferentes maestros.
Transparente significa que no tiene que preocuparse por cómo se almacenan sus datos en más de un servidor de base de datos internamente.
Puede configurar Postgres-XC para que se ejecute en varios servidores. Tus datos se almacenan de forma distribuida, particionada o replicada, según tu elección para cada tabla. Cuando emite consultas, Postgres-XC determina dónde se almacenan los datos de destino y emite las consultas correspondientes a los servidores que contienen los datos de destino.
Citus
Citus es un reemplazo directo para PostgreSQL con funciones integradas de alta disponibilidad, como fragmentación automática y replicación. Citus fragmenta su base de datos y replica varias copias de cada fragmento en el grupo de nodos de productos básicos. Si un nodo del clúster deja de estar disponible, Citus redirige de forma transparente cualquier escritura o consulta a uno de los otros nodos que albergan una copia del fragmento afectado.
Algunas características incluyen:
-
Partición lógica automática
-
Replicación integrada
-
Replicación compatible con centros de datos para recuperación ante desastres
-
Tolerancia a errores de consulta media con equilibrio de carga avanzado
Puede aumentar el tiempo de actividad de sus aplicaciones en tiempo real con tecnología de PostgreSQL y minimizar el impacto de las fallas de hardware en el rendimiento. Puede lograr esto con herramientas integradas de alta disponibilidad que minimizan la intervención manual costosa y propensa a errores.
PostgresXL
PostgresXL es una solución de agrupamiento multimaestro que no comparte nada y que puede distribuir de manera transparente una tabla en un conjunto de nodos y ejecutar consultas en paralelo con esos nodos. Tiene un componente adicional llamado Global Transaction Manager (GTM) para proporcionar una vista globalmente consistente del clúster.
PostgresXL es un clúster de base de datos SQL de código abierto escalable horizontalmente, lo suficientemente flexible como para manejar diferentes cargas de trabajo de base de datos:
-
Cargas de trabajo de escritura intensiva de OLTP
-
Business Intelligence que requiere paralelismo MPP
-
Almacén de datos operativo
-
Almacén de clave-valor
-
GIS Geoespacial
-
Entornos de carga de trabajo mixta
-
Entornos hospedados por proveedores de múltiples inquilinos

Componentes:
-
Global Transaction Monitor (GTM):Global Transaction Monitor garantiza la consistencia de las transacciones en todo el clúster.
-
Coordinador:El Coordinador administra las sesiones de usuario e interactúa con GTM y los nodos de datos.
-
Nodo de datos:El nodo de datos es donde se almacenan los datos reales.
Conclusión
Hay muchos más productos disponibles para implementar su entorno de alta disponibilidad para PostgreSQL, pero debe tener cuidado con:
-
Nuevos productos, no suficientemente probados
-
Proyectos descontinuados
-
Limitaciones
-
Costos de licencia
-
Implementaciones muy complejas
-
Soluciones inseguras
Al seleccionar la solución que usará, también tenga en cuenta su infraestructura. Si solo tienes un servidor de aplicaciones, por mucho que hayas configurado la alta disponibilidad de las bases de datos, si el servidor de aplicaciones falla, eres inaccesible. Debe analizar bien los puntos únicos de falla en la infraestructura e intentar solucionarlos.
Teniendo en cuenta estos puntos, puede encontrar una solución de clúster de alta disponibilidad que se adapte a sus necesidades y requisitos, sin dolores de cabeza. Si está buscando recursos HA adicionales para su base de datos PG, consulte esta publicación sobre la implementación de PostgreSQL para alta disponibilidad.
Para mantenerse actualizado sobre las mejores prácticas y soluciones de administración de bases de datos, síganos en Twitter y LinkedIn y suscríbase a nuestro boletín.