¿Se pregunta qué son los esquemas de Postgresql y por qué son importantes y cómo puede usar los esquemas para hacer que las implementaciones de su base de datos sean más sólidas y fáciles de mantener? Este artículo presentará los conceptos básicos de los esquemas en Postgresql y le mostrará cómo crearlos con algunos ejemplos básicos. Los artículos futuros profundizarán en ejemplos de cómo asegurar y usar esquemas para aplicaciones reales.
En primer lugar, para aclarar una posible confusión de terminología, entendamos que en el mundo de Postgresql, el término "esquema" quizás esté un poco sobrecargado. En el contexto más amplio de los sistemas de administración de bases de datos relacionales (RDBMS), el término "esquema" puede entenderse como una referencia al diseño lógico o físico general de la base de datos, es decir, la definición de todas las tablas, columnas, vistas y otros objetos. que constituyen la definición de la base de datos. En ese contexto más amplio, un esquema podría expresarse en un diagrama entidad-relación (ER) o un script de declaraciones de lenguaje de definición de datos (DDL) que se utilizan para instanciar la base de datos de la aplicación.
En el mundo de Postgresql, el término "esquema" podría entenderse mejor como un "espacio de nombres". De hecho, en las tablas del sistema Postgresql, los esquemas se registran en columnas de tabla llamadas "espacio de nombres", que, en mi humilde opinión, es una terminología más precisa. Como cuestión práctica, cada vez que veo "esquema" en el contexto de Postgresql, lo reinterpreto silenciosamente como si dijera "espacio de nombres".
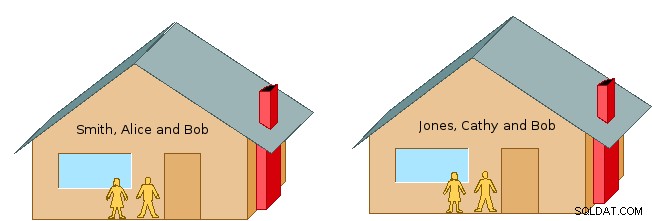
Pero puede preguntar:"¿Qué es un espacio de nombres?" En general, un espacio de nombres es un medio bastante flexible para organizar e identificar información por nombre. Por ejemplo, imagine dos hogares vecinos, los Smith, Alice y Bob, y los Jones, Bob y Cathy (cf. Figura 1). Si usáramos solo nombres de pila, podría confundirse a qué persona nos referimos cuando hablamos de Bob. Pero al agregar el apellido, Smith o Jones, identificamos de manera única a qué persona nos referimos.
A menudo, los espacios de nombres se organizan en una jerarquía anidada. Esto permite una clasificación eficiente de grandes cantidades de información en una estructura de grano muy fino, como, por ejemplo, el sistema de nombres de dominio de Internet. En el nivel superior, “.com”, “.net”, “.org”, “.edu”, etc. definen amplios espacios de nombres dentro de los cuales se registran nombres para entidades específicas, por ejemplo, “severalnines.com” y “postgresql.org” están definidos de forma única. Pero debajo de cada uno de ellos hay una serie de subdominios comunes como "www", "mail" y "ftp", por ejemplo, que por sí solos son duplicados, pero dentro de los respectivos espacios de nombres son únicos.
Los esquemas de Postgresql tienen el mismo propósito de organizar e identificar; sin embargo, a diferencia del segundo ejemplo anterior, los esquemas de Postgresql no se pueden anidar en una jerarquía. Si bien una base de datos puede contener muchos esquemas, solo hay un nivel y, por lo tanto, dentro de una base de datos, los nombres de esquema deben ser únicos. Además, cada base de datos debe incluir al menos un esquema. Cada vez que se instancia una nueva base de datos, se crea un esquema predeterminado llamado "público". El contenido de un esquema incluye todos los demás objetos de la base de datos, como tablas, vistas, procedimientos almacenados, disparadores, etc. Para visualizar, consulte la Figura 2, que representa una anidación similar a una muñeca matryoshka que muestra dónde encajan los esquemas en la estructura de un esquema. Base de datos Postgresql.
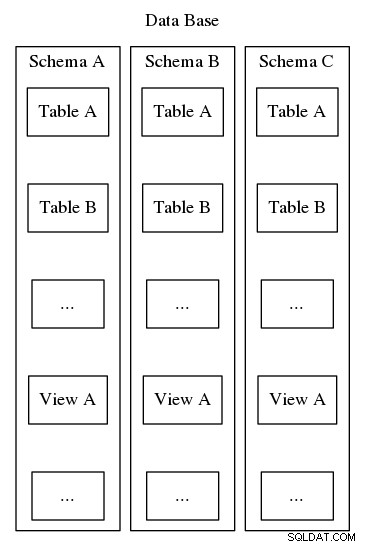
Además de simplemente organizar los objetos de la base de datos en grupos lógicos para hacerlos más manejables, los esquemas tienen el propósito práctico de evitar la colisión de nombres. Un paradigma operativo consiste en definir un esquema para cada usuario de la base de datos para proporcionar cierto grado de aislamiento, un espacio donde los usuarios pueden definir sus propias tablas y vistas sin interferir entre sí. Otro enfoque es instalar herramientas de terceros o extensiones de bases de datos en esquemas individuales para mantener todos los componentes relacionados lógicamente juntos. Un artículo posterior de esta serie detallará un enfoque novedoso para el diseño robusto de aplicaciones, empleando esquemas como un medio indirecto para limitar la exposición del diseño físico de la base de datos y, en su lugar, presentará una interfaz de usuario que resuelve claves sintéticas y facilita el mantenimiento a largo plazo y la gestión de la configuración. a medida que evolucionan los requisitos del sistema.
¡Hagamos algo de código!
Descargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoEl comando más simple para crear un esquema dentro de una base de datos es
CREATE SCHEMA hollywood;Este comando requiere privilegios de creación en la base de datos, y el esquema recién creado "hollywood" será propiedad del usuario que invoque el comando. Una invocación más compleja puede incluir elementos opcionales que especifican un propietario diferente, e incluso puede incluir instrucciones DDL que instancian objetos de la base de datos dentro del esquema, ¡todo en un solo comando!
El formato general es
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]donde "nombre de usuario" es quién será el propietario del esquema y "elemento_esquema" puede ser uno de ciertos comandos DDL (consulte la documentación de Postgresql para obtener detalles). Se requieren privilegios de superusuario para usar la opción AUTORIZACIÓN.
Entonces, por ejemplo, para crear un esquema llamado "hollywood" que contenga una tabla llamada "películas" y una vista llamada "ganadores" en un solo comando, podría hacer
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Posteriormente, se pueden crear directamente objetos de base de datos adicionales, por ejemplo, se agregaría una tabla adicional al esquema con
CREATE TABLE hollywood.actors (name text, dob date, gender text);Tenga en cuenta en el ejemplo anterior el prefijo del nombre de la tabla con el nombre del esquema. Esto es necesario porque de forma predeterminada, es decir, sin una especificación de esquema explícita, los nuevos objetos de la base de datos se crean dentro del esquema actual, que trataremos a continuación.
Recuerde cómo en el ejemplo de espacio de nombre anterior, teníamos dos personas llamadas Bob, y describimos cómo eliminar conflictos o distinguirlos al incluir el apellido. Pero dentro de cada uno de los hogares de Smith y Jones por separado, cada familia entiende que "Bob" se refiere al que va con ese hogar en particular. Entonces, por ejemplo, en el contexto de cada hogar respectivo, Alice no necesita dirigirse a su esposo como Bob Jones, y Cathy no necesita referirse a su esposo como Bob Smith:cada uno puede decir simplemente "Bob".
El esquema actual de Postgresql es algo así como el hogar en el ejemplo anterior. Los objetos en el esquema actual se pueden referenciar sin calificar, pero hacer referencia a objetos con nombres similares en otros esquemas requiere calificar el nombre anteponiendo el nombre del esquema como se indicó anteriormente.
El esquema actual se deriva del parámetro de configuración "search_path". Este parámetro almacena una lista de nombres de esquema separados por comas y se puede examinar con el comando
SHOW search_path;o establece un nuevo valor con
SET search_path TO schema [, schema, ...];El primer nombre de esquema en la lista es el "esquema actual" y es donde se crean nuevos objetos si se especifican sin calificación de nombre de esquema.
La lista de nombres de esquema separados por comas también sirve para determinar el orden de búsqueda mediante el cual el sistema localiza los objetos con nombre no calificado existentes. Por ejemplo, volviendo al vecindario de Smith and Jones, una entrega de paquete dirigida solo a "Bob" requeriría visitar cada hogar hasta que se encuentre al primer residente llamado "Bob". Tenga en cuenta que este podría no ser el destinatario previsto. La misma lógica se aplica a Postgresql. El sistema busca tablas, vistas y otros objetos dentro de los esquemas en el orden de ruta_búsqueda y, a continuación, se utiliza el primer objeto de coincidencia de nombre encontrado. Los objetos con nombre calificados por el esquema se usan directamente sin referencia a la ruta_búsqueda.
En la configuración predeterminada, consultar la variable de configuración search_path revela este valor
SHOW search_path;
Search_path
--------------
"$user", publicEl sistema interpreta el primer valor que se muestra arriba como el nombre de usuario conectado actual y acomoda el caso de uso mencionado anteriormente donde a cada usuario se le asigna un esquema de nombre de usuario para un espacio de trabajo separado de otros usuarios. Si no se ha creado tal esquema con nombre de usuario, esa entrada se ignora y el esquema "público" se convierte en el esquema actual donde se crean nuevos objetos.
Por lo tanto, volviendo a nuestro ejemplo anterior de creación de la tabla "hollywood.actors", si no hubiéramos calificado el nombre de la tabla con el nombre del esquema, entonces la tabla se habría creado en el esquema público. Si anticipábamos la creación de todos los objetos dentro de un esquema específico, sería conveniente establecer la variable search_path como
SET search_path TO hollywood,public;facilitando la taquigrafía de escribir nombres no calificados para crear o acceder a objetos de base de datos.
También hay una función de información del sistema que devuelve el esquema actual con una consulta
select current_schema();En caso de errores ortográficos, el propietario de un esquema puede cambiar el nombre, siempre que el usuario también tenga privilegios de creación para la base de datos, con la
ALTER SCHEMA old_name RENAME TO new_name;Y, por último, para eliminar un esquema de una base de datos, hay un comando de eliminación
DROP SCHEMA schema_name;El comando DROP fallará si el esquema contiene objetos, por lo que deben eliminarse primero, o puede eliminar recursivamente un esquema todo su contenido con la opción CASCADE
DROP SCHEMA schema_name CASCADE;¡Estos conceptos básicos lo ayudarán a comenzar a comprender los esquemas!