El conocimiento de la replicación es imprescindible para cualquiera que administre bases de datos. Es un tema que probablemente hayas visto una y otra vez pero nunca pasa de moda. En este blog, revisaremos un poco la historia de las funciones de replicación integradas de PostgreSQL y profundizaremos en cómo funciona la replicación de transmisión.
Cuando hablemos de replicación, hablaremos mucho de WAL. Entonces, repasemos rápidamente un poco acerca de los registros de escritura anticipada.
Registro de escritura anticipada (WAL)
Un registro de escritura anticipada es un método estándar para garantizar la integridad de los datos y se habilita automáticamente de manera predeterminada.
Los WAL son los registros REDO en PostgreSQL. Pero, ¿qué son exactamente los registros REDO?
Los registros REDO contienen todos los cambios realizados en la base de datos y se utilizan para la replicación, la recuperación, la copia de seguridad en línea y la recuperación de un punto en el tiempo (PITR). Cualquier cambio que no se haya aplicado a las páginas de datos se puede rehacer desde los registros REDO.
El uso de WAL da como resultado una cantidad significativamente reducida de escrituras en disco porque solo el archivo de registro debe vaciarse en el disco para garantizar que se confirme una transacción, en lugar de cada archivo de datos modificado por la transacción.
Un registro WAL especificará los cambios realizados en los datos, bit a bit. Cada registro WAL se adjuntará a un archivo WAL. La posición de inserción es un Número de secuencia de registro (LSN), un desplazamiento de bytes en los registros, que aumenta con cada nuevo registro.
Los WAL se almacenan en el directorio pg_wal (o pg_xlog en versiones de PostgreSQL <10) en el directorio de datos. Estos archivos tienen un tamaño predeterminado de 16 MB (puede cambiar el tamaño modificando la opción de configuración --with-wal-segsize al crear el servidor). Tienen un nombre incremental único en el siguiente formato:"00000001 00000000 00000000".
La cantidad de archivos WAL contenidos en pg_wal dependerá del valor asignado al parámetro checkpoint_segments (o min_wal_size y max_wal_size, según la versión) en el archivo de configuración postgresql.conf.
Un parámetro que debe configurar al configurar todas sus instalaciones de PostgreSQL es wal_level. El wal_level determina cuánta información se escribe en el WAL. El valor predeterminado es mínimo, que escribe solo la información necesaria para recuperarse de un bloqueo o apagado inmediato. El archivo agrega el registro requerido para el archivo WAL; hot_standby agrega además la información necesaria para ejecutar consultas de solo lectura en un servidor en espera; lógico agrega la información necesaria para admitir la decodificación lógica. Este parámetro requiere un reinicio, por lo que puede ser difícil cambiarlo al ejecutar bases de datos de producción si lo ha olvidado.
Para más información, puedes consultar la documentación oficial aquí o aquí. Ahora que hemos cubierto el WAL, revisemos el historial de replicación en PostgreSQL.
Historial de replicación en PostgreSQL
El primer método de replicación (espera cálida) que implementó PostgreSQL (versión 8.2, allá por 2006) se basó en el método de envío de registros.
Esto significa que los registros WAL se mueven directamente de un servidor de base de datos a otro para ser aplicados. Podemos decir que es un PITR continuo.
PostgreSQL implementa el envío de registros basado en archivos mediante la transferencia de registros WAL de un archivo (segmento WAL) a la vez.
Esta implementación de replicación tiene la desventaja:si hay una falla importante en los servidores primarios, las transacciones que aún no se hayan enviado se perderán. Por lo tanto, hay una ventana para la pérdida de datos (puede ajustar esto usando el parámetro archive_timeout, que puede configurarse en tan solo unos segundos. Sin embargo, una configuración tan baja aumentará sustancialmente el ancho de banda requerido para el envío de archivos).
Podemos representar este método de envío de registros basado en archivos con la siguiente imagen:
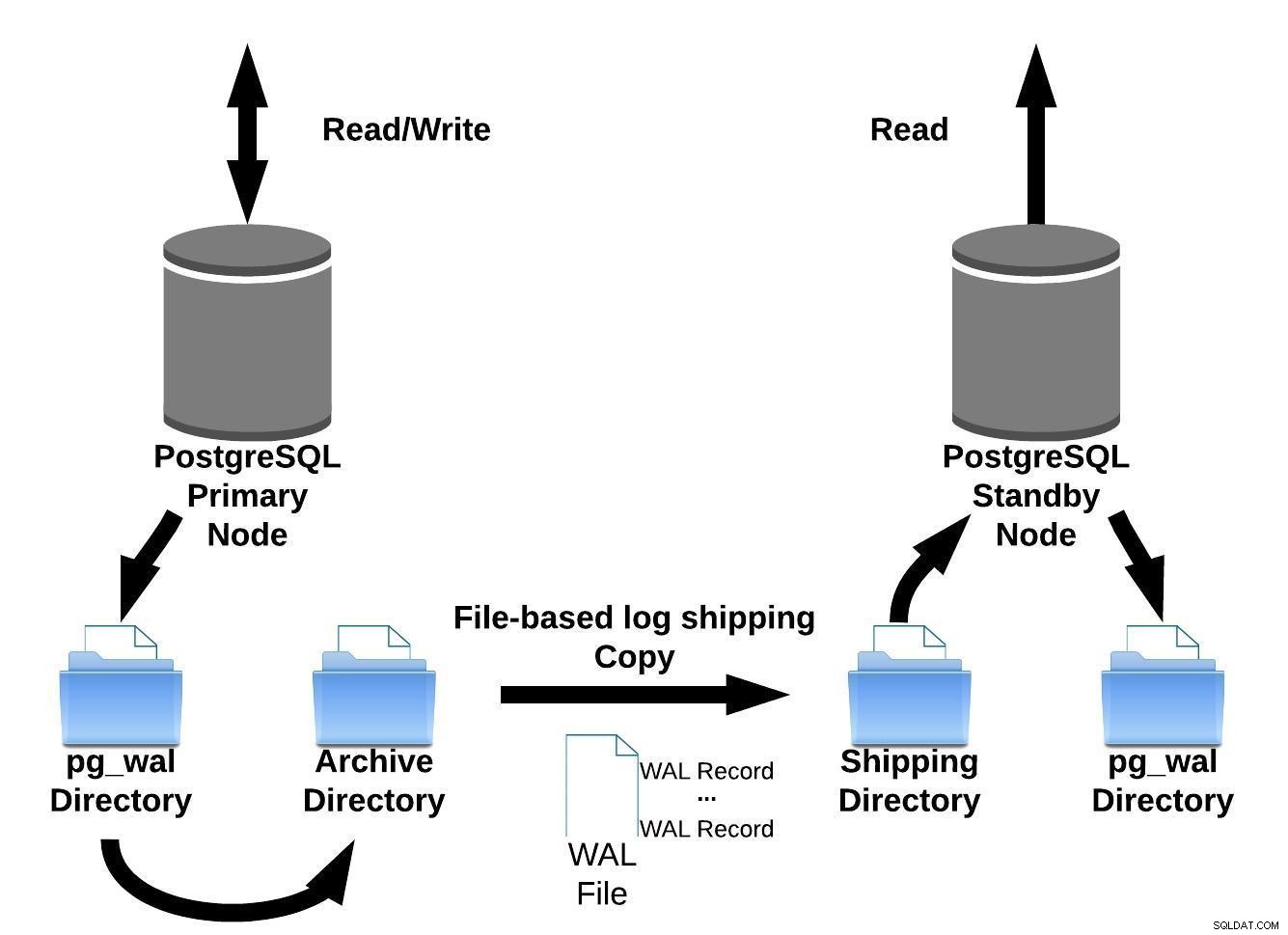 Envío de registros basado en archivos PostgreSQL
Envío de registros basado en archivos PostgreSQLLuego, en la versión 9.0 (en 2010 ), se introdujo la replicación de transmisión.
La replicación de transmisión le permite mantenerse más actualizado de lo que es posible con el trasvase de registros basado en archivos. Esto funciona mediante la transferencia de registros WAL (un archivo WAL se compone de registros WAL) sobre la marcha (envío de registros basado en registros) entre un servidor principal y uno o varios servidores en espera sin esperar a que se llene el archivo WAL.
En la práctica, un proceso denominado receptor WAL, que se ejecuta en el servidor de reserva, se conectará al servidor principal mediante una conexión TCP/IP. En el servidor primario existe otro proceso, llamado WAL sender, y se encarga de enviar los registros WAL al servidor standby a medida que ocurren.
El siguiente diagrama representa la replicación de transmisión:
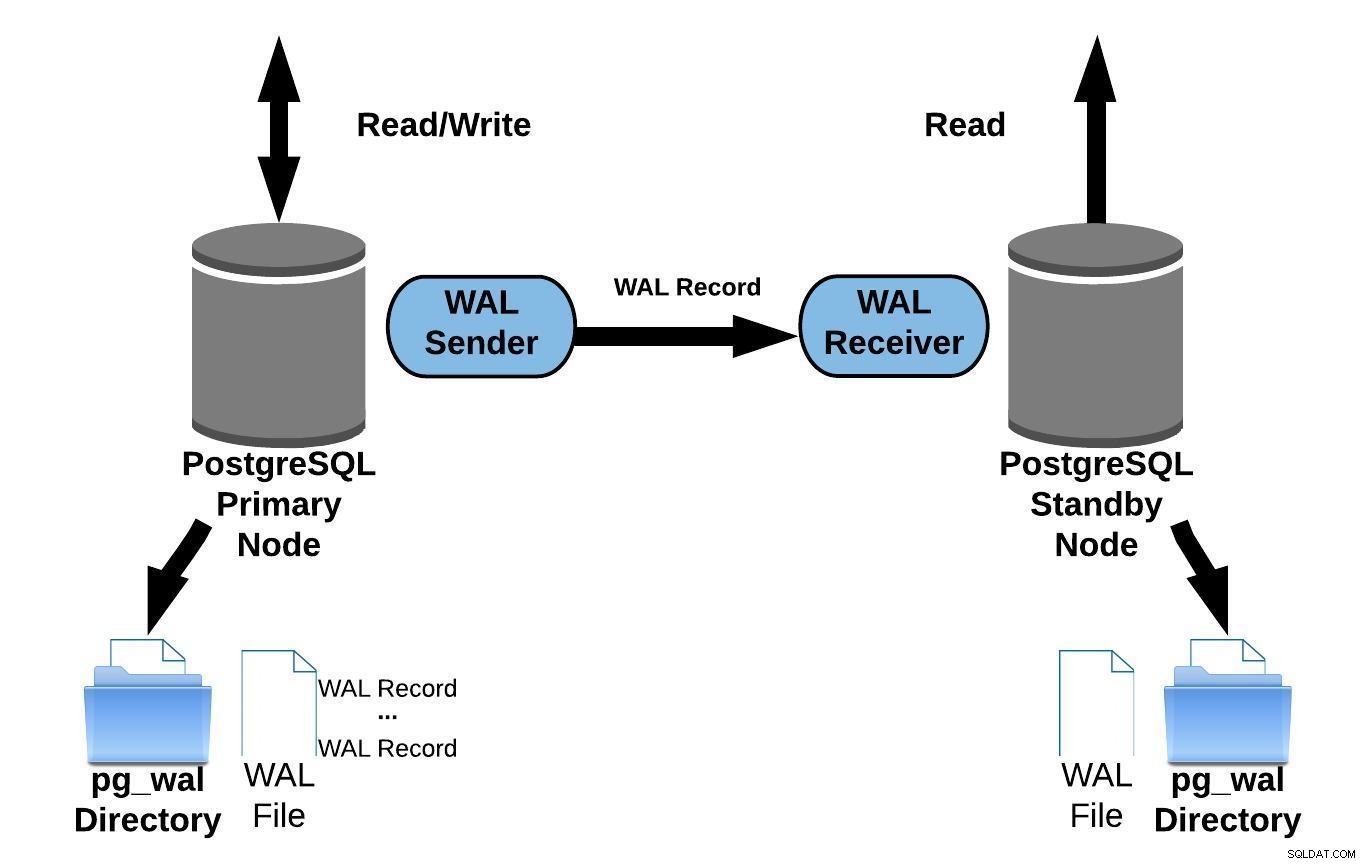 Replicación de transmisión de PostgreSQL
Replicación de transmisión de PostgreSQLSi observa el diagrama anterior, es posible que se pregunte qué sucede cuando falla la comunicación entre el remitente WAL y el receptor WAL?
Al configurar la replicación de transmisión, tiene la opción de habilitar el archivado WAL.
Este paso no es obligatorio pero es extremadamente importante para una configuración de replicación sólida. Es necesario evitar que el servidor principal recicle archivos WAL antiguos que aún no se han aplicado al servidor de reserva. Si esto ocurre, deberá volver a crear la réplica desde cero.
Al configurar la replicación con archivado continuo, se inicia desde una copia de seguridad. Para alcanzar el estado sincronizado con el principal, debe aplicar todos los cambios alojados en el WAL que ocurrieron después de la copia de seguridad. Durante este proceso, el standby primero restaurará todos los WAL disponibles en la ubicación del archivo (lo cual se hace llamando a restore_command). El comando de restauración fallará cuando llegue al último registro WAL archivado, por lo que después de eso, el recurso en espera buscará en el directorio pg_wal para ver si el cambio existe allí (esto funciona para evitar la pérdida de datos cuando los servidores primarios fallan y algunos cambios que ya se han movido y aplicado a la réplica aún no se han archivado).
Si eso falla y el registro solicitado no existe allí, comenzará a comunicarse con el servidor principal a través de la replicación de transmisión.
Siempre que falla la replicación de transmisión, volverá al paso 1 y restaurará los registros del archivo nuevamente. Este bucle de reintentos desde el archivo, pg_wal y a través de la replicación de transmisión continúa hasta que el servidor se detiene o un archivo desencadenante activa la conmutación por error.
El siguiente diagrama representa una configuración de replicación de transmisión con archivado continuo:
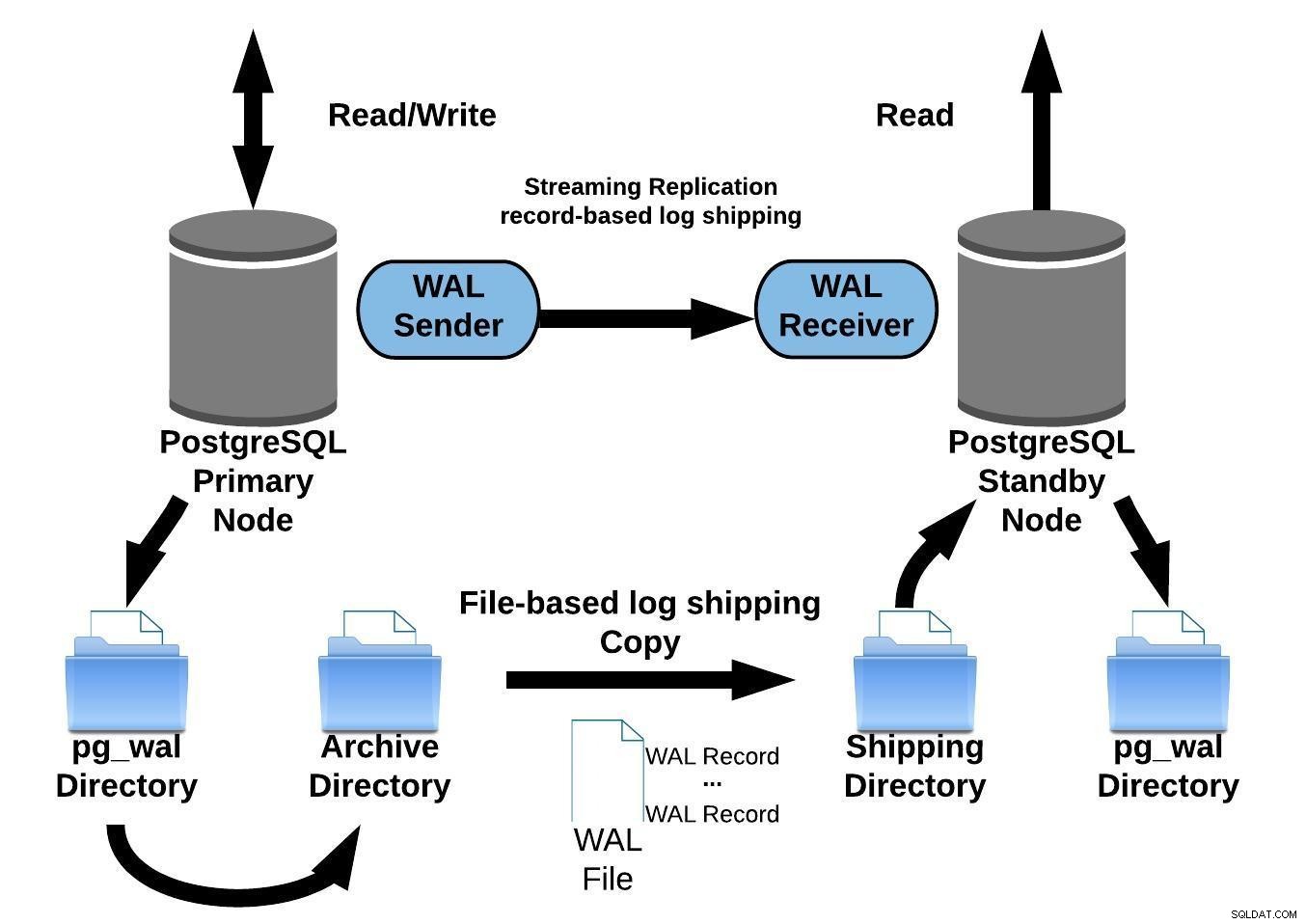 Replicación de transmisión de PostgreSQL con archivado continuo
Replicación de transmisión de PostgreSQL con archivado continuoLa replicación de transmisión es asíncrona de forma predeterminada, por lo que en en cualquier momento, puede tener algunas transacciones que se pueden confirmar en el servidor principal y aún no replicar en el servidor de reserva. Esto implica una posible pérdida de datos.
Sin embargo, se supone que este retraso entre la confirmación y el impacto de los cambios en la réplica es muy pequeño (algunos milisegundos), asumiendo, por supuesto, que el servidor de réplica es lo suficientemente potente como para mantenerse al día. la carga.
Para los casos en los que incluso el riesgo de una pequeña pérdida de datos no es aceptable, la versión 9.1 introdujo la función de replicación síncrona.
En la replicación síncrona, cada compromiso de una transacción de escritura espera hasta que se recibe la confirmación de que el compromiso se escribe en el registro de escritura anticipada en el disco del servidor primario y en espera.
Este método minimiza la posibilidad de pérdida de datos; para que eso suceda, necesitará que tanto el principal como el de reserva fallen simultáneamente.
La desventaja obvia de esta configuración es que aumenta el tiempo de respuesta para cada transacción de escritura, ya que debe esperar hasta que todas las partes hayan respondido. Entonces, el tiempo para una confirmación es, como mínimo, el viaje de ida y vuelta entre el principal y la réplica. Las transacciones de solo lectura no se verán afectadas por esto.
Para configurar la replicación síncrona, debe especificar un nombre de aplicación en la información de conexión principal de la recuperación para cada archivo server.conf en espera:Primary_conninfo ='... nombre_aplicación=standbyX' .
También debe especificar la lista de servidores en espera que participarán en la replicación síncrona:synchronous_standby_name ='standbyX,standbyY'.
Puede configurar uno o varios servidores sincrónicos, y este parámetro también especifica qué método (PRIMERO y CUALQUIERA) para elegir los modos de espera sincrónicos de los enumerados. Para obtener más información sobre cómo configurar el modo de replicación síncrona, consulte este blog. También es posible configurar la replicación síncrona cuando se implementa a través de ClusterControl.
Una vez que haya configurado su replicación y esté funcionando, deberá implementar el monitoreo
Supervisión de la replicación de PostgreSQL
La vista pg_stat_replication en el servidor maestro tiene mucha información relevante:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Veamos esto en detalle:
-
pid:ID de proceso del proceso walsender.
-
usesysid:OID del usuario que se utiliza para la replicación de transmisión.
-
usename:Nombre del usuario que se utiliza para la replicación de transmisión.
-
application_name:Nombre de la aplicación conectada al maestro.
-
client_addr:dirección de la replicación en espera/transmisión.
-
client_hostname:nombre de host del standby.
-
client_port:número de puerto TCP en el que se comunica en espera con el remitente WAL.
-
backend_start:Hora de inicio cuando SR se conectó al principal.
-
estado:estado actual del remitente WAL, es decir, transmisión.
-
sent_lsn:ubicación de la última transacción enviada al modo de espera.
-
write_lsn:última transacción escrita en el disco en espera.
-
flush_lsn:Descarga de la última transacción en el disco en espera.
-
replay_lsn:última transacción vaciada en el disco en espera.
-
sync_priority:Prioridad del servidor en espera elegido como espera sincrónica.
-
sync_state:estado de sincronización del modo de espera (es asíncrono o síncrono).
También puede ver los procesos de envío/recepción de WAL que se ejecutan en los servidores.
Remitente (nodo principal):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Receptor (nodo en espera):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Una forma de verificar qué tan actualizada está su replicación es verificar la cantidad de registros WAL generados en el servidor principal, pero que aún no se han aplicado en el servidor de reserva.
Primaria:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)En espera:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Puede usar la siguiente consulta en el nodo en espera para obtener el retraso en segundos:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Y también puedes ver el último mensaje recibido:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Supervisión de la replicación de PostgreSQL con ClusterControl
Para monitorear su clúster de PostgreSQL, puede usar ClusterControl, que le permite monitorear y realizar varias tareas de administración adicionales como implementación, copias de seguridad, escalamiento horizontal y más.
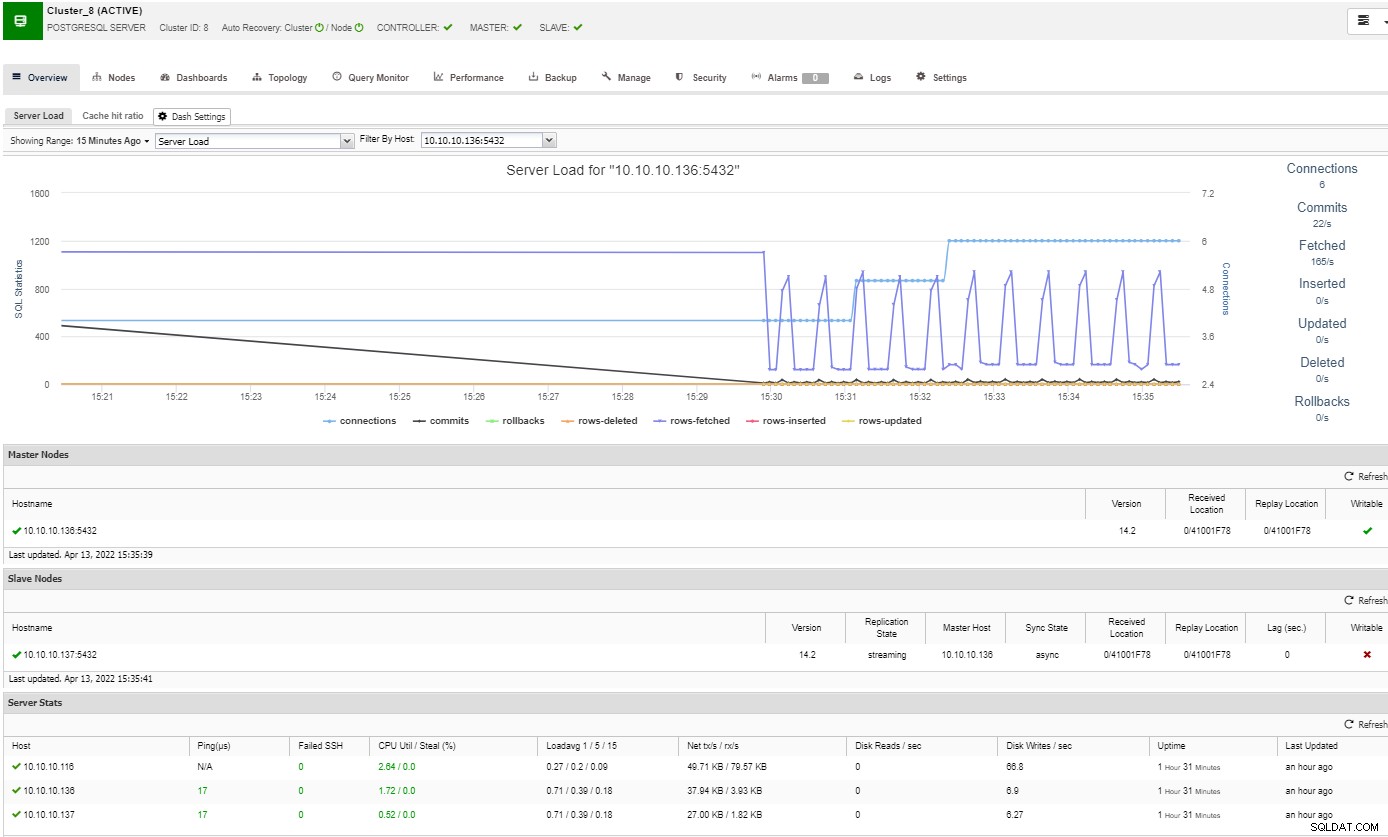
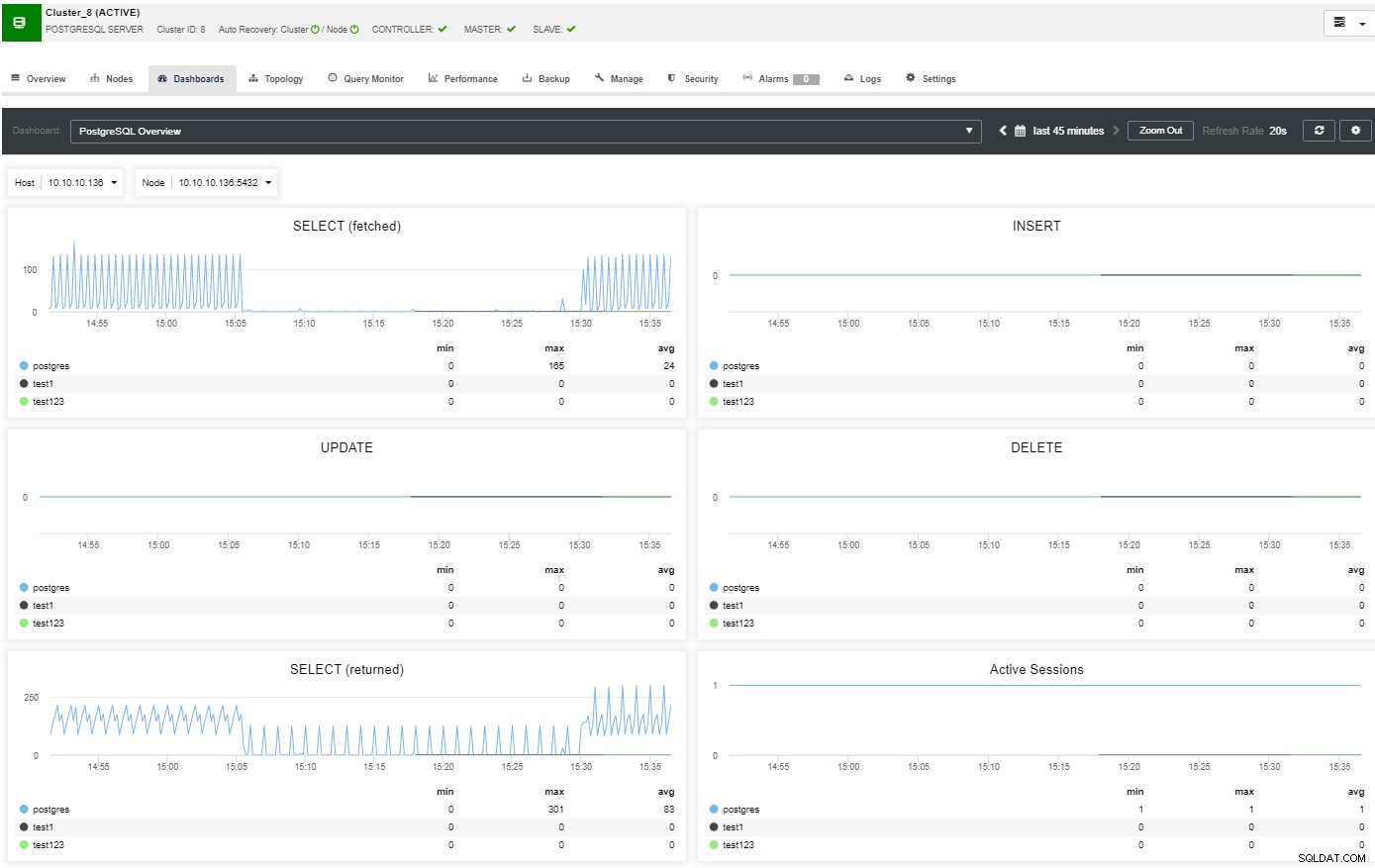
En la sección de descripción general, tendrá una imagen completa del clúster de su base de datos estado actual. Para ver más detalles, puede acceder a la sección del panel de control, donde verá mucha información útil separada en diferentes gráficos.
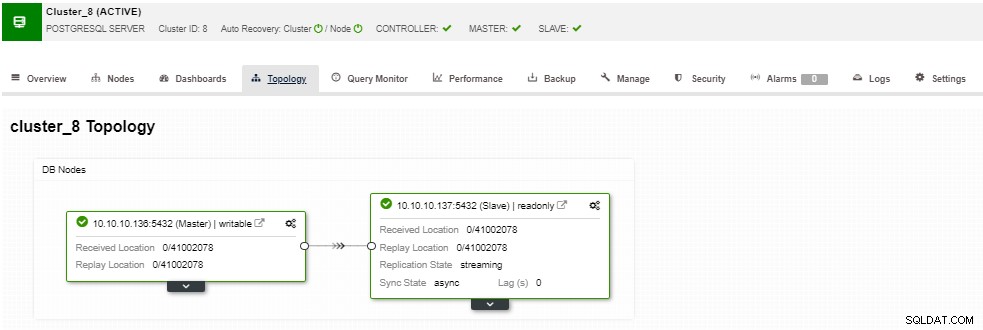
En la sección de topología, puede ver su topología actual en un usuario- manera amigable, y también puede realizar diferentes tareas sobre los nodos usando el botón Acción de nodo.
La replicación de transmisión se basa en enviar los registros WAL y aplicarlos al servidor en espera servidor, dicta qué bytes agregar o cambiar en qué archivo. Como resultado, el servidor en espera es en realidad una copia bit a bit del servidor principal. Sin embargo, aquí existen algunas limitaciones bien conocidas:
-
No puede replicar en una versión o arquitectura diferente.
-
No puede cambiar nada en el servidor en espera.
-
No tienes mucha granularidad en lo que replicas.
Entonces, para superar estas limitaciones, PostgreSQL 10 ha agregado soporte para replicación lógica
Replicación lógica
La replicación lógica también utilizará la información del archivo WAL, pero la decodificará en cambios lógicos. En lugar de saber qué byte ha cambiado, sabrá con precisión qué datos se han insertado en qué tabla.
Se basa en un modelo de "publicación" y "suscripción" con uno o más suscriptores que se suscriben a una o más publicaciones en un nodo de editor que se ve así:
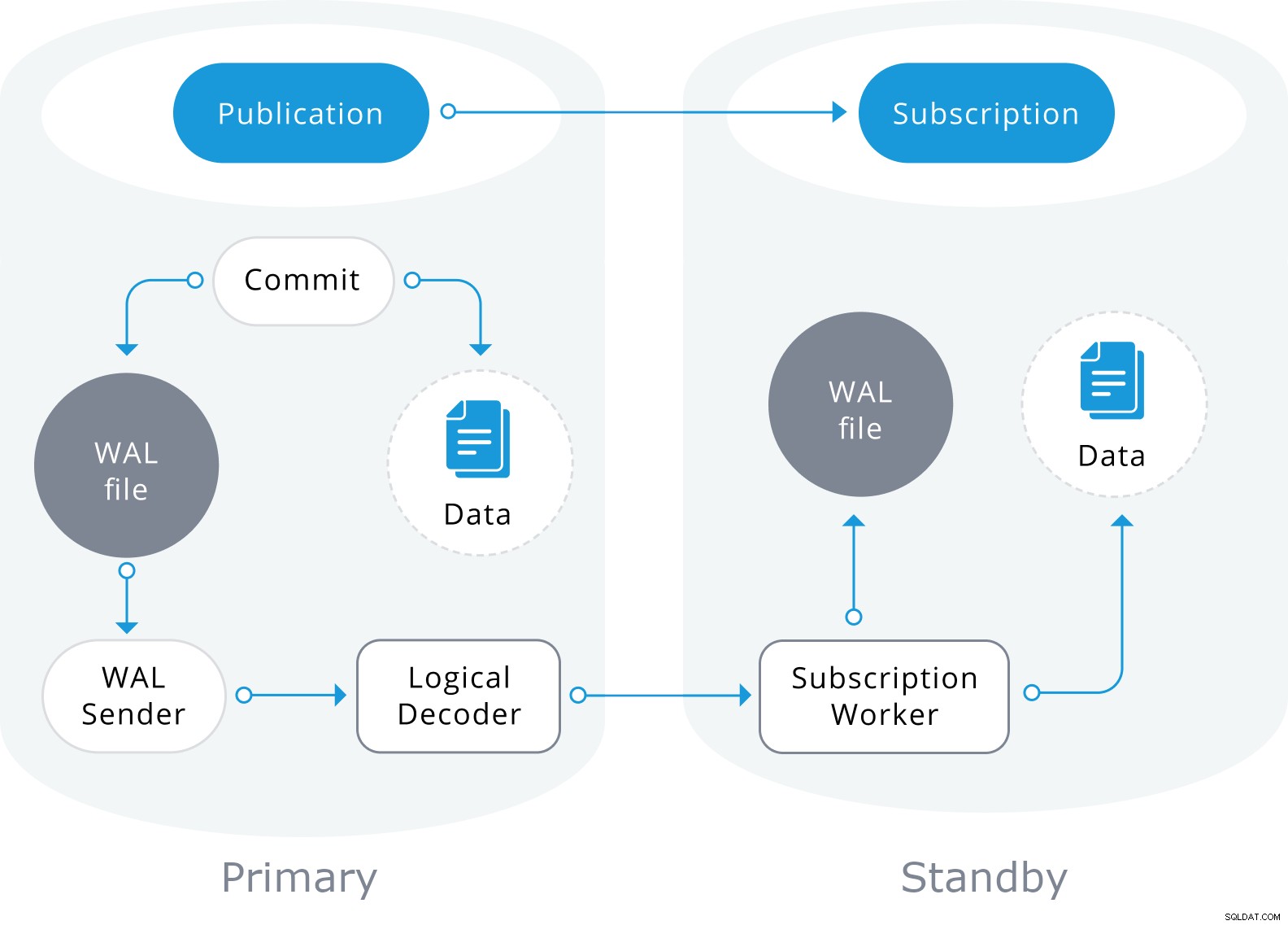
Conclusión
Con la replicación de transmisión, puede enviar y aplicar continuamente registros WAL a sus servidores en espera, lo que garantiza que la información actualizada en el servidor principal se transfiera al servidor en espera en tiempo real, lo que permite que ambos permanezcan sincronizados .
ClusterControl simplifica la configuración de la replicación de transmisión y puede evaluarla de forma gratuita durante 30 días.
Si desea obtener más información sobre la replicación lógica en PostgreSQL, asegúrese de consultar esta descripción general de la replicación lógica y esta publicación sobre las mejores prácticas de replicación de PostgreSQL.
Para obtener más consejos y mejores prácticas para administrar su base de datos basada en código abierto, síganos en Twitter y LinkedIn, y suscríbase a nuestro boletín para recibir actualizaciones periódicas.



