Con Disaster Recovery, nuestro objetivo es configurar sistemas para manejar cualquier cosa que pueda salir mal con nuestra base de datos. ¿Qué sucede si la base de datos falla? ¿Qué sucede si un desarrollador trunca accidentalmente una tabla? ¿Qué sucede si descubrimos que algunos datos se eliminaron la semana pasada pero no nos dimos cuenta hasta hoy? Estas cosas suceden, y tener un plan y un sistema sólidos hará que el DBA se vea como un héroe cuando los corazones de todos los demás ya se han detenido cuando un desastre asoma su fea cabeza.
Cualquier base de datos que tenga algún tipo de valor debe tener una forma de implementar una o más opciones de recuperación ante desastres. PostgreSQL tiene un sistema de replicación muy sólido incorporado y es lo suficientemente flexible como para configurarse en muchas configuraciones para ayudar con la recuperación ante desastres, en caso de que algo salga mal. Nos centraremos en escenarios como los cuestionados anteriormente, cómo configurar nuestras opciones de recuperación ante desastres y los beneficios de cada solución.
Alta disponibilidad
Con la replicación de transmisión en PostgreSQL, la alta disponibilidad es fácil de configurar y mantener. El objetivo es proporcionar un sitio de conmutación por error que se pueda promocionar a maestro si la base de datos principal deja de funcionar por algún motivo, como una falla de hardware, una falla de software o incluso una interrupción de la red. Alojar una réplica en otro host es excelente, pero alojarla en otro centro de datos es aún mejor.
Para obtener información específica sobre la configuración de la replicación de transmisión, Variousnines tiene una inmersión profunda detallada disponible aquí. La documentación oficial de replicación de transmisión de PostgreSQL tiene información detallada sobre el protocolo de replicación de transmisión y cómo funciona.
Una configuración estándar se verá así, una base de datos maestra que acepta conexiones de lectura/escritura, con una base de datos réplica que recibe toda la actividad de WAL casi en tiempo real, reproduciendo toda la actividad de cambio de datos localmente.
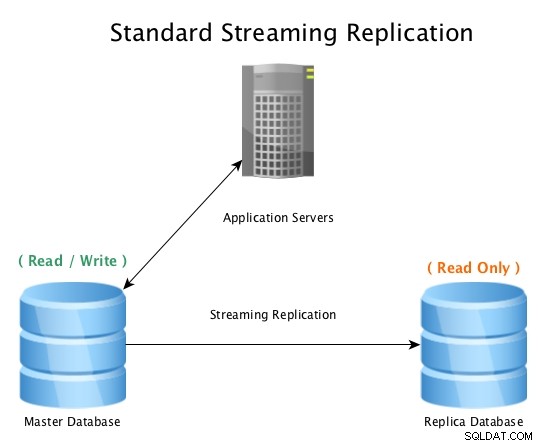 Replicación de transmisión estándar con PostgreSQL
Replicación de transmisión estándar con PostgreSQL Cuando la base de datos maestra se vuelve inutilizable, se inicia un procedimiento de conmutación por error para desconectarla y promover la base de datos réplica a maestra, y luego apuntar todas las conexiones al host recién promovido. Esto se puede hacer reconfigurando un equilibrador de carga, la configuración de la aplicación, los alias de IP u otras formas inteligentes de redirigir el tráfico.
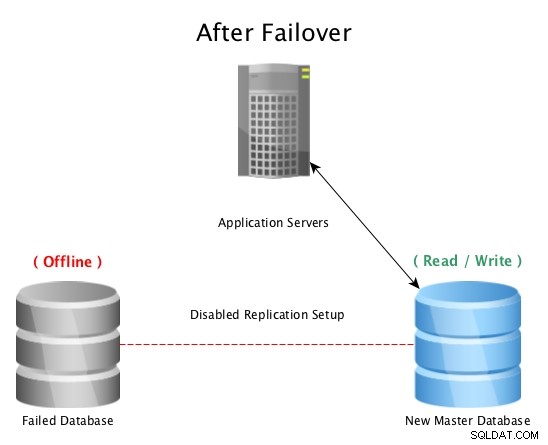 Después de una conmutación por error con PostgreSQL Streaming Replication
Después de una conmutación por error con PostgreSQL Streaming Replication Cuando un desastre golpea una base de datos maestra (como una falla del disco duro, un corte de energía o cualquier cosa que impida que la maestra funcione según lo previsto), la conmutación por error a un modo de espera en caliente es la forma más rápida de permanecer en línea y atender consultas a aplicaciones o clientes sin problemas serios. falta del tiempo. Entonces comienza la carrera para reparar el host de la base de datos que falló o traer una nueva réplica en línea para mantener la red de seguridad de tener una reserva lista para funcionar. Tener varios modos de espera garantizará que la ventana después de una falla desastrosa también esté lista para una falla secundaria, por improbable que parezca.
Nota:cuando se realiza una conmutación por error a una réplica de transmisión, continuará donde la dejó la maestra anterior, por lo que esto ayuda a mantener la base de datos en línea, pero no a recuperar los datos perdidos accidentalmente.
Recuperación de un punto en el tiempo
Otra opción de recuperación ante desastres es la recuperación en un punto en el tiempo (PITR). Con PITR, se puede recuperar una copia de la base de datos en cualquier momento que queramos, siempre que tengamos una copia de seguridad base anterior a ese momento y todos los segmentos WAL necesarios hasta ese momento.
Una opción de recuperación de un punto en el tiempo no se pone en línea tan rápidamente como un modo de espera en caliente, sin embargo, el principal beneficio es poder recuperar una instantánea de la base de datos antes de un gran evento, como una tabla eliminada, la inserción de datos incorrectos o incluso una corrupción de datos inexplicable. . Cualquier cosa que destruya datos de tal manera que querríamos obtener una copia antes de esa destrucción, PITR salva el día.
Point in Time Recovery funciona creando instantáneas periódicas de la base de datos, generalmente mediante el uso del programa pg_basebackup, y manteniendo copias archivadas de todos los archivos WAL generados por el maestro
Configuración de recuperación de un punto en el tiempo
La configuración requiere algunas opciones de configuración establecidas en el maestro, algunas de las cuales son buenas para ir con los valores predeterminados en la última versión actual, PostgreSQL 11. En este ejemplo, copiaremos el archivo de 16 MB directamente a nuestro host PITR remoto usando rsync y comprimiéndolos en el otro lado con un trabajo cron.
Archivo WAL
Maestro postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'
[Opcional] Comprima los archivos WAL archivados:
Cada configuración variará un poco, pero a menos que la base de datos en cuestión sea muy ligera en las actualizaciones de datos, la acumulación de archivos de 16 MB llenará el espacio del disco con bastante rapidez. Una secuencia de comandos de compresión fácil, configurada a través de cron, podría verse a continuación.
comprimir_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]
Copias de seguridad básicas
Uno de los componentes clave de una copia de seguridad de PITR es la copia de seguridad base y la frecuencia de las copias de seguridad base. Estos pueden ser por hora, diarios, semanales, mensuales, pero elija la mejor opción según las necesidades de recuperación, así como el tráfico de la rotación de datos de la base de datos. Si tenemos copias de seguridad semanales todos los domingos y necesitamos recuperar todo el camino hasta el sábado por la tarde, ponemos en línea la copia de seguridad base del domingo anterior con todos los archivos WAL entre esa copia de seguridad y el sábado por la tarde. Si este proceso de recuperación tarda 10 horas en procesarse, es probable que sea demasiado largo. Las copias de seguridad base diarias reducirán ese tiempo de recuperación, ya que la copia de seguridad base sería de esa mañana, pero también aumentará la cantidad de trabajo en el host para la copia de seguridad base. mismo.
Si la recuperación de archivos WAL de una semana toma solo unos minutos, porque la base de datos ve poca rotación, entonces las copias de seguridad semanales están bien. Los mismos datos existirán al final, pero la rapidez con la que pueda acceder a ellos es la clave.
En nuestro ejemplo, configuraremos una copia de seguridad base semanal y, dado que usamos Streaming Replication para alta disponibilidad, además de reducir la carga en el maestro, crearemos la copia de seguridad base a partir de la base de datos de réplica.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -z
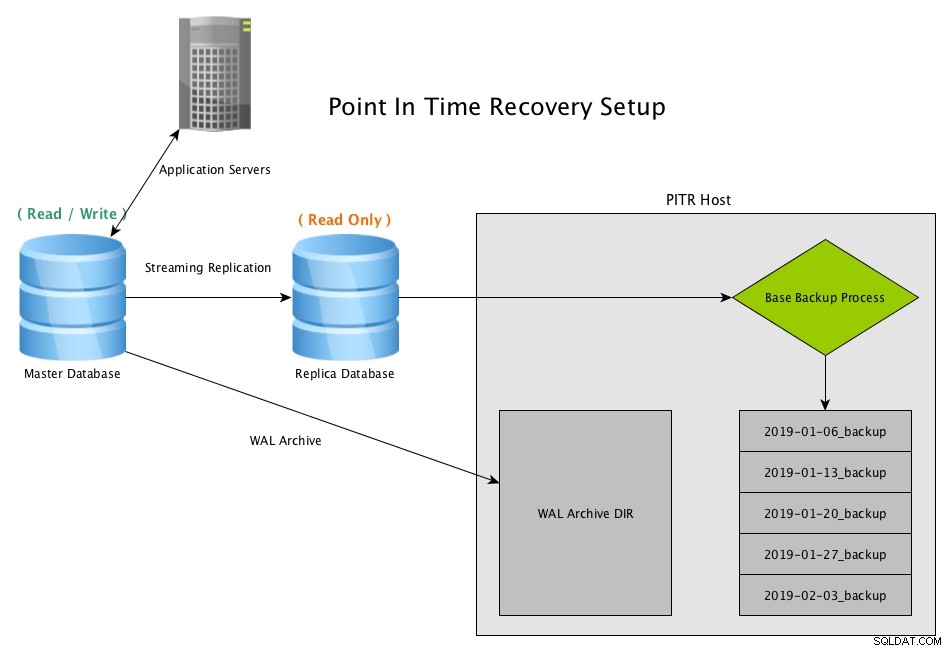 Recuperación en un punto en el tiempo (PITR) de una réplica de transmisión con PostgreSQLDescargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlMás información lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargue el Whitepaper
Recuperación en un punto en el tiempo (PITR) de una réplica de transmisión con PostgreSQLDescargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlMás información lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargue el Whitepaper Escenario de recuperación de PITR
Configurar Point In Time Recovery es solo una parte del trabajo, tener que recuperar datos es la otra parte. Con buena suerte, es posible que esto nunca tenga que suceder, sin embargo, se recomienda encarecidamente realizar una restauración periódica de una copia de seguridad de PITR para validar que el sistema funciona y para asegurarse de que el proceso se conozca o esté correctamente programado.
En nuestro escenario de prueba, elegiremos un punto en el tiempo para recuperar e iniciar el proceso de recuperación. Por ejemplo:el viernes por la mañana, un desarrollador envía un nuevo cambio de código a producción sin pasar por una revisión del código y destruye una gran cantidad de datos importantes del cliente. Dado que nuestro Hot Standby siempre está sincronizado con el maestro, fallar no solucionaría nada, ya que serían los mismos datos. Las copias de seguridad de PITR es lo que nos salvará.
El impulso del código entró a las 11 a. m., por lo que necesitamos restaurar la base de datos justo antes de esa hora, decidimos a las 10:59 a. m. y, afortunadamente, hacemos copias de seguridad diarias, por lo que tenemos una copia de seguridad desde la medianoche de esta mañana. Como no sabemos qué fue lo que se destruyó, también decidimos hacer una restauración completa de esta base de datos en nuestro host PITR y ponerla en línea como maestro, ya que tiene las mismas especificaciones de hardware que el maestro, por si acaso esto escenario sucedió.
Apaga al Maestro
Dado que decidimos restaurar completamente desde una copia de seguridad y promocionarla a maestra, no hay necesidad de mantener esto en línea. Lo apagamos, pero lo mantenemos cerca en caso de que necesitemos tomar algo de él más tarde, por si acaso.
Configurar la copia de seguridad base para la recuperación
Luego, en nuestro host PITR, buscamos nuestra copia de seguridad base más reciente antes del evento, que es la copia de seguridad '2018-12-21_backup'.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Con esto, la copia de seguridad base, así como los archivos WAL provistos por pg_basebackup están listos para funcionar, si lo ponemos en línea ahora, se recuperará hasta el punto en que se realizó la copia de seguridad, pero queremos recuperar todas las transacciones WAL entre medianoche y las 11:59 a. m., por lo que configuramos nuestro archivo recovery.conf.
Crear recovery.conf
Dado que esta copia de seguridad en realidad proviene de una réplica de transmisión, es probable que ya exista un archivo recovery.conf con la configuración de la réplica. Lo sobrescribiremos con nuevas configuraciones. Una lista de información detallada para todas las diferentes opciones está disponible en la documentación de PostgreSQL aquí.
Teniendo cuidado con los archivos WAL, el comando de restauración copiará los archivos comprimidos que necesita en el directorio de restauración, los descomprimirá y luego se trasladará a donde PostgreSQL los necesite para la recuperación. Los archivos WAL originales permanecerán donde están en caso de que se necesiten por cualquier otro motivo.
Nuevo recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Iniciar el proceso de recuperación
Ahora que todo está configurado, comenzaremos el proceso de recuperación. Cuando esto sucede, es una buena idea seguir el registro de la base de datos para asegurarse de que se está restaurando según lo previsto.
Iniciar la base de datos:
pg_ctl -D /var/lib/pgsql/11/data startSiga los registros:
Habrá muchas entradas de registro que mostrarán que la base de datos se está recuperando de los archivos comprimidos y, en cierto punto, mostrará una línea que dice "recuperación detenida antes de confirmar la transacción..."
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07En este punto, el proceso de recuperación ha ingerido todos los archivos WAL, pero también necesita una revisión antes de que se conecte como maestro. En este ejemplo, el registro indica que la siguiente transacción después de la hora objetivo de recuperación de las 11:59:00 fue a las 11:59:01 y no se recuperó. Para verificar, inicie sesión en la base de datos y eche un vistazo, la base de datos en ejecución debe ser una instantánea a las 11:59 exactamente.
Cuando todo pinta bien, llega el momento de impulsar la recuperación como un maestro.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Ahora, la base de datos está en línea, recuperada hasta el punto que decidimos, y acepta conexiones de lectura/escritura como un nodo maestro. Asegúrese de que todos los parámetros de configuración sean correctos y estén listos para la producción.
La base de datos está en línea, ¡pero el proceso de recuperación aún no ha terminado! Ahora que esta copia de seguridad de PITR está en línea como el maestro, se debe configurar una nueva configuración de espera y PITR, hasta entonces, este nuevo maestro puede estar en línea y sirviendo aplicaciones, pero no está a salvo de otro desastre hasta que todo esté configurado nuevamente.
Otros escenarios de recuperación en un momento dado
Recuperar una copia de seguridad de PITR para una base de datos completa es un caso extremo, pero hay otros escenarios en los que solo falta un subconjunto de datos, está dañado o es incorrecto. En estos casos, podemos ser creativos con nuestras opciones de recuperación. Sin desconectar el maestro y reemplazarlo con una copia de seguridad, podemos poner una copia de seguridad de PITR en línea en el momento exacto que queramos en otro host (u otro puerto si el espacio no es un problema) y exportar los datos recuperados de la copia de seguridad directamente. en la base de datos maestra. Esto podría usarse para recuperar un puñado de filas, un puñado de tablas o cualquier configuración de datos necesaria.
Con la replicación de transmisión y la recuperación a un punto en el tiempo, PostgreSQL nos brinda una gran flexibilidad para asegurarnos de que podamos recuperar cualquier dato que necesitemos, siempre que tengamos hosts en espera listos para funcionar como maestros o copias de seguridad listas para recuperar. Una buena opción de recuperación ante desastres se puede ampliar aún más con otras opciones de copia de seguridad, más nodos de réplica, múltiples sitios de copia de seguridad en diferentes centros de datos y continentes, pg_dumps periódicos en otra réplica, etc.
Estas opciones pueden sumarse, pero la verdadera pregunta es "¿qué tan valiosos son los datos y cuánto está dispuesto a gastar para recuperarlos?". En muchos casos, la pérdida de datos es el final de un negocio, por lo que se deben implementar buenas opciones de recuperación ante desastres para evitar que suceda lo peor.



