La escalabilidad es la propiedad de un sistema para manejar una cantidad creciente de demandas mediante la adición de recursos. Los motivos de esta cantidad de demandas pueden ser temporales, por ejemplo, si estás lanzando un descuento en una venta, o permanentes, por aumento de clientes o empleados. En cualquier caso, debería poder agregar o eliminar recursos para administrar estos cambios en las demandas o el aumento del tráfico.
Hay diferentes enfoques disponibles para escalar su base de datos. En este blog, veremos cuáles son estos enfoques y cómo escalar su base de datos PostgreSQL usando Connection Poolers y Load Balancers.
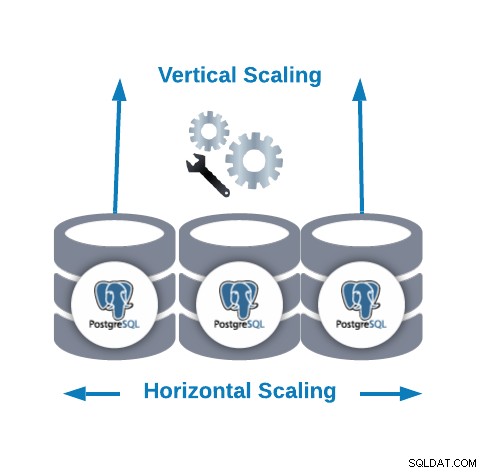
Escalado horizontal y vertical
Hay dos formas principales de escalar su base de datos.
- Escalado horizontal (scale-out):Se realiza agregando más nodos de base de datos creando o aumentando un clúster de base de datos. Puede ayudarlo a mejorar el rendimiento de lectura equilibrando el tráfico entre los nodos.
- Escalado vertical (ampliación):se realiza agregando más recursos de hardware (CPU, memoria, disco) a un nodo de base de datos existente. Podría ser necesario cambiar algún parámetro de configuración para permitir que PostgreSQL use un recurso de hardware nuevo o mejor.
Agrupadores de conexiones y equilibradores de carga
Tanto en el escalado horizontal como en el vertical, podría ser útil agregar una herramienta externa para reducir la carga en su base de datos, lo que mejorará el rendimiento. Tal vez no sea suficiente, pero es un buen punto de partida. Para ello, es buena idea implementar un agrupador de conexiones y un equilibrador de carga. Dije "y" porque están diseñados para diferentes roles.
Una agrupación de conexiones es un método para crear un conjunto de conexiones y reutilizarlas evitando abrir nuevas conexiones a la base de datos todo el tiempo, lo que aumentará considerablemente el rendimiento de sus aplicaciones. PgBouncer es un agrupador de conexiones popular diseñado para PostgreSQL.
Usar un Load Balancer es una forma de tener alta disponibilidad en la topología de su base de datos y también es útil para aumentar el rendimiento al equilibrar el tráfico entre los nodos disponibles. Para esto, HAProxy es una buena opción para PostgreSQL, ya que es un proxy de código abierto que se puede usar para implementar alta disponibilidad, equilibrio de carga y proxy para aplicaciones basadas en TCP y HTTP.
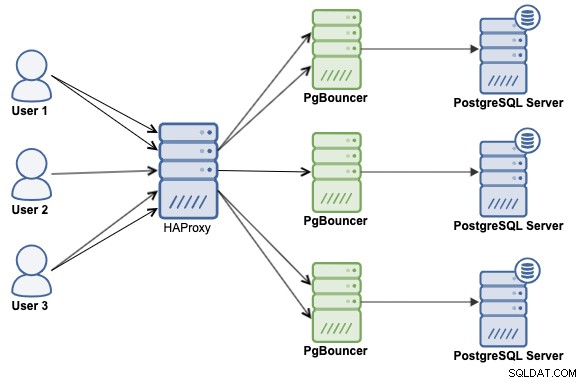
Cómo implementar una combinación de HAProxy, PgBouncer y PostgreSQL
Una combinación de ambas tecnologías, HAProxy y PgBouncer, es probablemente la mejor manera de escalar y mejorar el rendimiento en su entorno PostgreSQL. Entonces, veremos cómo implementarlo usando la siguiente arquitectura:
Supondremos que tiene instalado ClusterControl, si no, puede ir a el sitio oficial, o incluso consultar la documentación oficial para instalarlo.
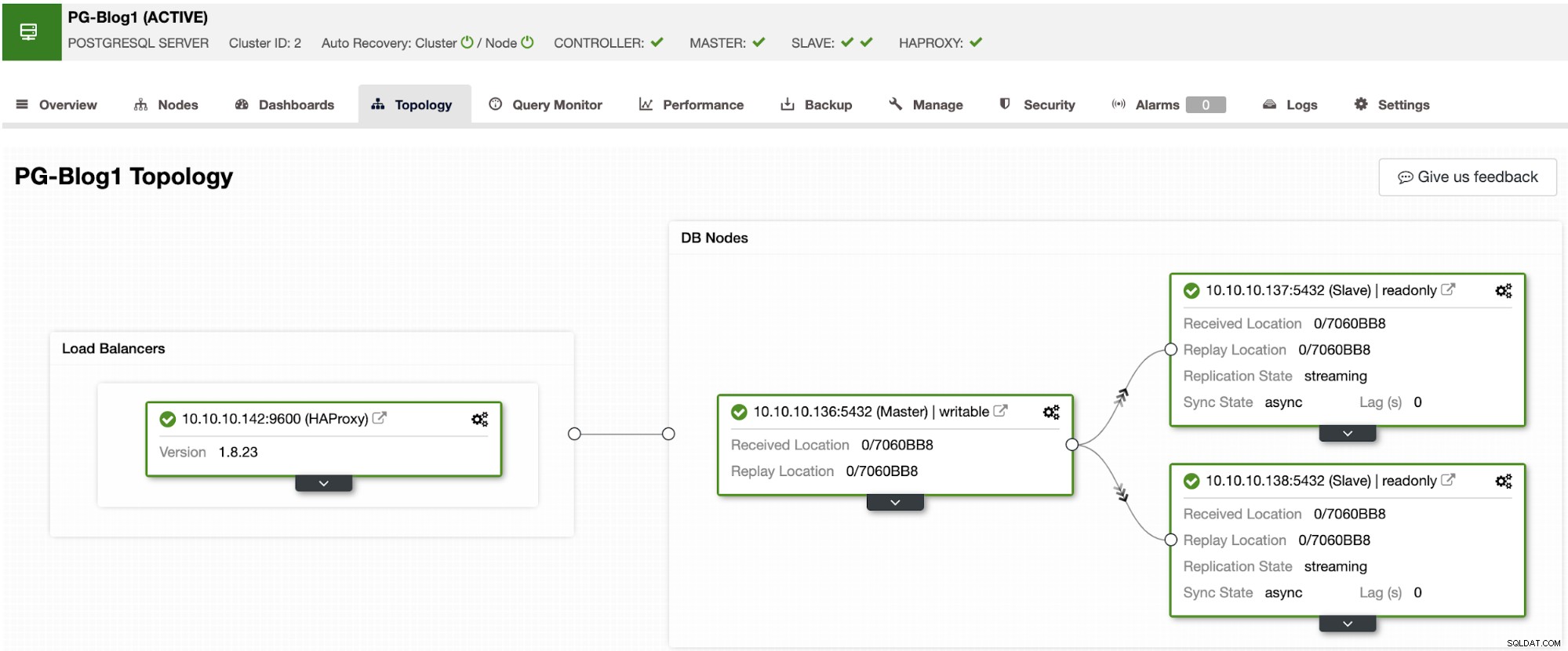
Primero, debe implementar su clúster de PostgreSQL con HAProxy al frente. Para ello, siga los pasos de esta publicación de blog para implementar tanto PostgreSQL como HAProxy mediante ClusterControl.
En este punto, tendrá algo como esto:
Ahora, puede instalar PgBouncer en cada nodo de base de datos o en una máquina externa .
Para obtener el software PgBouncer puede ir a la sección de descargas de PgBouncer, o usar los repositorios RPM o DEB. Para este ejemplo, usaremos CentOS 8 y lo instalaremos desde el repositorio oficial de PostgreSQL.
Primero, descargue e instale el repositorio correspondiente del sitio de PostgreSQL (si aún no lo tiene instalado):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmLuego, instale el paquete PgBouncer:
$ yum install pgbouncerCuando se complete, tendrá un nuevo archivo de configuración ubicado en /etc/pgbouncer/pgbouncer.ini. Como archivo de configuración predeterminado, puede usar el siguiente ejemplo:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbY el archivo de autenticación:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"Este es solo un ejemplo básico. Para obtener todos los parámetros disponibles, puede consultar la documentación oficial.
Entonces, en este caso, instalé PgBouncer en el mismo nodo de la base de datos, escuchando todas las direcciones IP, y se conecta a una base de datos PostgreSQL llamada "mundo". También administro los usuarios permitidos en el archivo userlist.txt con una contraseña de texto sin formato que se puede cifrar si es necesario.
Para iniciar el servicio PgBouncer, solo necesita ejecutar el siguiente comando:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniAhora, ejecute el siguiente comando utilizando su información local (puerto, host, nombre de usuario y nombre de la base de datos) para acceder a la base de datos de PostgreSQL:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#Esta es una topología básica. Puede mejorarlo, por ejemplo, agregando dos o más nodos de balanceador de carga para evitar un punto único de falla y usando alguna herramienta como "Keepalived", para garantizar la disponibilidad. También se puede hacer usando ClusterControl.
Para obtener más información sobre PgBouncer y cómo usarlo, puede consultar esta publicación de blog.
Conclusión
Si necesita escalar su clúster de PostgreSQL, agregar HAProxy y PgBouncer es una buena manera de escalar horizontal y verticalmente al mismo tiempo, ya que puede agregar más nodos de espera activos para equilibrar el tráfico. y mejorarás el rendimiento reutilizando conexiones abiertas.
ClusterControl proporciona una amplia gama de características, desde monitoreo, alertas, conmutación por error automática, copia de seguridad, recuperación de un momento dado, verificación de copia de seguridad, hasta escalado de réplicas de lectura. Esto puede ayudarlo a escalar su base de datos PostgreSQL de forma horizontal o vertical desde una interfaz de usuario amigable e intuitiva.