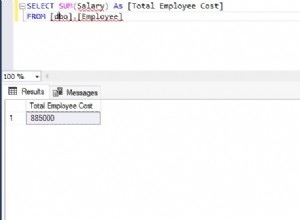
Como un RDBMS moderno, PostgreSQL viene con muchos parámetros para realizar ajustes. Una de las áreas a considerar es cómo PostgreSQL debe registrar sus actividades. El registro a menudo se pasa por alto en la administración de la base de datos de Postgres y, si no se ignora, generalmente se configura incorrectamente. Esto sucede porque la mayoría de las veces, el propósito del registro no está claro. Por supuesto, la razón fundamental para el registro es bien conocida, pero lo que a veces falta es una comprensión de cómo se utilizarán los registros.
Los requisitos de registro de cada organización son únicos y, por lo tanto, la forma en que se debe configurar el registro de PostgreSQL también será diferente. Lo que una empresa de servicios financieros necesita capturar dentro de los registros de su base de datos será diferente de lo que necesita registrar una empresa que maneja información de salud crítica. Y en algunos casos, también pueden ser similares.
En este artículo, cubriré algunas prácticas fundamentales para aprovechar al máximo los registros de PostgreSQL. Este blog no es un libro de reglas estrictas y rápidas; los lectores son más que bienvenidos a compartir sus pensamientos en la sección de comentarios. Sin embargo, para obtener el mejor valor, le pido al lector que piense en cómo quiere usar los registros del servidor de la base de datos de PostgreSQL:
- Razón de cumplimiento legal donde se necesita capturar información específica
- Auditoría de seguridad donde los detalles específicos del evento deben estar presentes
- Resolución de problemas de rendimiento donde se registrarán las consultas y sus parámetros
- Apoyo operativo diario donde se debe monitorear una cantidad determinada de métricas
Dicho esto, comencemos.
No realice cambios manuales en postgresql.conf
Cualquier cambio en el archivo postgresql.conf debe realizarse mediante un sistema de administración de configuración como Puppet, Ansible o Chef. Esto garantiza que los cambios sean rastreables y se puedan revertir de forma segura a una versión anterior si es necesario. Esto es cierto cuando realiza cambios en los parámetros de registro.
Los DBA a menudo crean varias copias del archivo postgresql.conf, cada una con parámetros ligeramente diferentes, cada una para un propósito diferente. La gestión manual de diferentes archivos de configuración es una tarea engorrosa si no es propensa a errores. Por otro lado, se puede hacer que un sistema de administración de configuración cambie el nombre y use diferentes versiones del archivo postgresql.conf en función de un parámetro que se le haya pasado. Este parámetro dictará el propósito de la versión actual. Cuando se completa la necesidad, el archivo de configuración anterior se puede volver a colocar cambiando el mismo parámetro de entrada.
Por ejemplo, si desea registrar todas las declaraciones que se ejecutan en su instancia de PostgreSQL, se puede usar un archivo de configuración con el valor del parámetro "log_statement=all". Cuando no hay necesidad de registrar todas las declaraciones, tal vez después de un ejercicio de solución de problemas, se puede restablecer el archivo de configuración anterior.
Usar archivos de registro separados para PostgreSQL
Recomiendo habilitar el recopilador de registro nativo de PostgreSQL durante las operaciones normales. Para habilitar el registro nativo de PostgreSQL, establezca el siguiente parámetro en:
logging_collector = onHay dos razones para ello:
En primer lugar, en sistemas ocupados, es posible que el sistema operativo no registre de manera consistente los mensajes de PostgreSQL en syslog (suponiendo una instalación basada en nix) y, a menudo, deje caer mensajes. Con el registro nativo de PostgreSQL, un demonio separado se encarga de registrar los eventos. Cuando PostgreSQL está ocupado, este proceso aplazará la escritura en los archivos de registro para permitir que finalicen los hilos de consulta. Esto puede bloquear todo el sistema hasta que se escriba el evento de registro. Por lo tanto, es útil registrar mensajes menos detallados en el registro (como veremos más adelante) y usar prefijos de línea de registro abreviados.
En segundo lugar, y como veremos más adelante, los registros deben recopilarse, analizarse, indexarse y analizarse con una utilidad de administración de registros. Hacer que PostgreSQL registre sus eventos en syslog significará crear una capa adicional de filtrado y coincidencia de patrones en la parte de administración de registros para filtrar todos los "mensajes de ruido". La mayoría de las herramientas pueden analizar e indexar fácilmente los archivos de registro dedicados para eventos.
Establecer destino de registro en stderr
Consideremos el parámetro "log_destination". Puede tener cuatro valores:
log_destination = stderr | syslog | csv | eventlog
A menos que haya una buena razón para guardar los eventos de registro en formato separado por comas o el registro de eventos en Windows, recomiendo establecer este parámetro en stderr. Esto se debe a que con un destino de archivo CSV, un valor de parámetro personalizado "log_line_prefix" no tendrá ningún efecto y, sin embargo, se puede hacer que el prefijo contenga información valiosa.
Sin embargo, por otro lado, un registro CSV se puede importar fácilmente a una tabla de base de datos y luego consultarlo usando SQL estándar. Algunos usuarios de PostgreSQL lo encuentran más conveniente que manejar archivos de registro sin formato. Como veremos más adelante, las soluciones modernas de gestión de registros pueden analizar de forma nativa los registros de PostgreSQL y crear automáticamente información significativa a partir de ellos. Con CSV, el usuario debe realizar manualmente los informes y la visualización.
En última instancia, todo se reduce a su elección. Si se siente cómodo creando su propia canalización de ingesta de datos para cargar los registros CSV en las tablas de la base de datos, limpiar y transformar los datos y crear informes personalizados que se adapten a sus necesidades comerciales, asegúrese de que "log_destination" esté configurado en CSV.
Usar nombres de archivo de registro significativos
Cuando los archivos de registro de PostgreSQL se guardan localmente, puede que no parezca necesario seguir un estilo de nomenclatura. El estilo de nombre de archivo predeterminado es "postgresql-%Y-%m-%d_%H%M%S.log" para registros sin formato CSV, que es suficiente para la mayoría de los casos.
La asignación de nombres se vuelve importante cuando se guardan archivos de registro de varios servidores en una ubicación central, como un servidor de registro dedicado, un volumen NFS montado o un depósito S3. Recomiendo usar dos parámetros en tal caso:
log_directory log_filename
Para almacenar archivos de registro de varias instancias en un solo lugar, primero cree una jerarquía de directorios separada para cada instancia. Esto puede ser algo como lo siguiente:
/<Application_Name>/<Environment_Name>/<Instance_Name>
El "directorio_de_registro" de cada instancia de PostgreSQL se puede señalar a su carpeta designada.
Cada instancia puede usar el mismo valor de parámetro "log_filename". El valor predeterminado creará un archivo como
postgresql_2020-08-25_2359.log
Para usar un nombre más significativo, establezca "log_filename" en algo como esto:
log_filename = "postgresql_%A-%d-%B_%H%M"
Los archivos de registro se nombrarán como:
postgresql_sábado-23-agosto_2230
Usar un prefijo de línea de registro significativo
Los prefijos de línea de registro de PostgreSQL pueden contener la información más valiosa además del mensaje real. La documentación de Postgres muestra varios caracteres de escape para la configuración de prefijos de eventos de registro. Estas secuencias de escape se sustituyen con varios valores de estado en tiempo de ejecución. Algunas aplicaciones como pgBadger esperan un prefijo de línea de registro específico.
Recomiendo incluir la siguiente información en el prefijo:
- La hora del evento (sin milisegundos):%t
- Nombre de cliente remoto o dirección IP:%h
- Nombre de usuario:%u
- Acceso a la base de datos:%d
- Nombre de la aplicación:%a
- Identificación del proceso:%p
- Terminando la salida del proceso que no es de sesión:%q
- El número de línea de registro para cada sesión o proceso, comenzando en 1:%l
Para comprender de qué se trata cada campo en el prefijo, podemos agregar una pequeña cadena literal antes del campo. Por lo tanto, el valor del ID del proceso puede estar precedido por el literal "PID=", el nombre de la base de datos puede tener el prefijo "db=", etc. Aquí hay un ejemplo:
log_line_prefix = 'time=%t, pid=%p %q db=%d, usr=%u, client=%h , app=%a, line=%l '
Dependiendo de dónde provenga el evento, el prefijo de la línea de registro mostrará diferentes valores. Tanto los procesos en segundo plano como los procesos de usuario registrarán sus mensajes en el archivo de registro. Para los procesos del sistema, he especificado %q, que suprimirá cualquier texto después del ID del proceso (%p). Cualquier otra sesión mostrará el nombre de la base de datos, el nombre de usuario, la dirección del cliente, el nombre de la aplicación y una línea numerada para cada evento.
Además, incluí un solo espacio después del prefijo de la línea de registro. Este espacio separa el prefijo del evento de registro del mensaje del evento real. No tiene que ser un carácter de espacio; se puede usar algo como dos puntos dobles (::), un guión (-) u otro separador significativo.
Además, establezca el parámetro "log_hostname" en 1:
log_hostname = 1
Sin esto, solo se mostrará la dirección IP del cliente. En los sistemas de producción, normalmente será la dirección del proxy, el equilibrador de carga o el agrupador de conexiones. A menos que conozca de memoria las direcciones IP de estos sistemas, puede valer la pena registrar sus nombres de host. Sin embargo, la búsqueda de DNS también agregará tiempo adicional para que el demonio de registro escriba en el archivo.
Otro parámetro que debe establecerse junto con el "log_line_prefix" es "log_timezone". Establecer esto en la zona horaria local del servidor garantizará que los eventos registrados sean fáciles de seguir desde su marca de tiempo en lugar de convertirlos primero a la hora local. En el fragmento de código a continuación, estamos configurando log_timzeone en la zona horaria estándar del este de Australia:
log_timezone = 'Australia/Sydney'
Registrar solo conexiones
Dos parámetros controlan cómo PostgreSQL registra las conexiones y desconexiones de los clientes. Ambos parámetros están desactivados por defecto. En función de los requisitos de seguridad de su organización, es posible que desee establecer uno de estos en 1 y el otro en 0 (a menos que esté utilizando una herramienta como pgBadger, más sobre eso más adelante).
log_connections = 1 log_disconnections = 0
Establecer log_connections en 1 registrará todas las conexiones autorizadas, así como las intentadas conexiones Obviamente, esto es bueno para la auditoría de seguridad:un ataque de fuerza bruta se puede identificar fácilmente a partir de los registros. Sin embargo, con esta configuración habilitada, un entorno PostgreSQL ocupado con miles o incluso cientos de conexiones válidas de corta duración podría ver cómo se inunda el archivo de registro.
Sin embargo, también puede identificar problemas de aplicación que de otra manera no serían obvios. Una gran cantidad de intentos de conexión de muchas direcciones de clientes válidas diferentes puede indicar que la instancia necesita un equilibrador de carga o un servicio de agrupación de conexiones delante de ella. Una gran cantidad de intentos de conexión desde una sola dirección de cliente puede descubrir una aplicación con demasiados subprocesos que necesitan algún tipo de limitación.
Registrar operaciones DDL y DML únicamente
Hay mucho debate sobre lo que debe registrarse en el registro de Postgres, es decir, cuál debe ser el valor del parámetro "log_statement". Puede tener tres valores:
log_statement = 'off' | 'ddl' | 'mod' | 'all'
Puede ser tentador establecer esto en "todos" para capturar todas las sentencias SQL que se ejecutan en el servidor, pero esto no siempre es una buena idea en la realidad.
Los sistemas de producción ocupados en su mayoría ejecutan declaraciones SELECT, a veces miles de ellas por hora. La instancia podría estar funcionando perfectamente bien, sin ningún problema de rendimiento. Establecer este parámetro en "todos" en tales casos sería una carga innecesaria para el demonio de registro, ya que tiene que escribir todas esas declaraciones en el archivo.
Sin embargo, lo que desea capturar es cualquier corrupción de datos o cambios en la estructura de la base de datos que hayan causado algún tipo de problema. Los cambios de base de datos no deseados o no autorizados causan más problemas de aplicación que la selección de datos; por eso recomiendo configurar este parámetro en "mod". Con esta configuración, PostgreSQL registrará todos los cambios de DDL y DML en el archivo de registro.
Si su instancia de PostgreSQL está moderadamente ocupada (docenas de consultas por hora), no dude en establecer este parámetro en "todos". Cuando esté solucionando problemas con consultas SELECT de ejecución lenta o buscando acceso a datos no autorizados, también puede establecer esto en "todos" temporalmente. Algunas aplicaciones como pgBadger también esperan que establezcas esto en "todos".
Registrar mensajes de "advertencia" y más
Si el parámetro "log_statement" decide qué tipo de declaraciones se registrarán, los siguientes dos parámetros dictan qué tan detallado será el mensaje:
log_min_messages log_min_error_statement
Cada evento de PostgreSQL tiene un nivel de mensaje asociado. El nivel del mensaje puede ser cualquier cosa, desde DEBUG detallado hasta PANIC conciso. Cuanto más bajo sea el nivel, más detallado será el mensaje. El valor predeterminado para el parámetro "log_min_messages" es "ADVERTENCIA". Recomiendo mantenerlo en este nivel a menos que también desee registrar mensajes informativos.
El parámetro "log_min_error_statement" controla qué sentencias SQL arrojan errores que se registrarán. Al igual que "log_min_message", se registrará cualquier instrucción SQL que tenga un nivel de gravedad de error igual o superior al valor especificado en "log_min_error_statement". El valor predeterminado es "ERROR", y recomiendo mantener el valor predeterminado.
Mantener los parámetros de duración del registro por defecto
Entonces tenemos los siguientes dos parámetros:
log_duration log_min_duration_statement
El parámetro “log_duration” toma un valor booleano. Cuando se establece en 1, se registrará la duración de cada estado de cuenta completado. Si se establece en 0, la duración de la declaración no se registrará. Este es el valor predeterminado y recomiendo mantenerlo en 0 a menos que esté solucionando problemas de rendimiento. Calcular y registrar la duración de las declaraciones hace que el motor de la base de datos haga un trabajo adicional (sin importar cuán pequeño sea), y cuando se extrapola a cientos o miles de consultas, los ahorros pueden ser significativos.
Por último, tenemos el parámetro “log_min_duration_statement”. Cuando se establece este parámetro (sin ninguna unidad, se toma como milisegundos), se registrará la duración de cualquier declaración que dure igual o más que el valor del parámetro. Establecer el valor de este parámetro en 0 registrará la duración de todas las declaraciones completadas. Establecer esto en -1 deshabilitará el registro de duración de la declaración. Este es el valor predeterminado y recomiendo mantenerlo así.
La única vez que desea establecer este parámetro en 0 es cuando desea crear una línea de base de rendimiento para las consultas que se ejecutan con frecuencia. Sin embargo, tenga en cuenta que si se establece el parámetro "log_statement", las declaraciones que se registran no se repetirán en los mensajes de registro que muestran las duraciones. Por lo tanto, deberá cargar los archivos de registro en una tabla de base de datos, luego unir los valores de ID de proceso e ID de sesión de los prefijos de línea de registro para identificar declaraciones relacionadas y sus duraciones.
Cualquiera que sea el medio, una vez que tenga una línea de base para cada consulta que se ejecuta con frecuencia, puede establecer el parámetro "log_min_duration_statement" en el valor más alto de la línea de base. Ahora, cualquier consulta que se ejecute por más tiempo que el valor de referencia más alto será candidata para un ajuste fino.
Mantener la verbosidad del mensaje de error en el valor predeterminado
El parámetro “log_error_verbosity” puede tener tres valores posibles:
log_error_verbosity = terse | standard | verbose
Este parámetro controla la cantidad de información que PostgreSQL registrará para cada evento registrado en el archivo de registro. A menos que se depure una aplicación de base de datos, es mejor mantener este parámetro en "predeterminado". El modo detallado será útil cuando necesite capturar el archivo o el nombre de la función y el número de línea que generó el error. Establecer esto en "conciso" suprimirá el registro de la consulta, lo que tampoco puede ser útil.
Encuentre una política de rotación de registros que funcione para su Caso de uso
Recomiendo crear una política de rotación de registros basada en el tamaño o la antigüedad del archivo de registro, pero no en ambos. Dos parámetros de configuración de PostgreSQL dictan cómo se archivan los registros antiguos y cómo se crean los nuevos:
log_rotation_age = <number of minutes> log_rotation_size = <number of kilobytes>
El valor predeterminado para "log_rotation_age" es 24 horas y el valor predeterminado para "log_rotation_size" es 10 megabytes.
En la mayoría de los casos, tener una política de rotación de tamaño no siempre garantiza que el último mensaje de registro en el archivo de registro archivado esté completamente contenido solo en ese archivo.
Si "log_rotation_age" se mantiene en su valor predeterminado de 24 horas, cada archivo se puede identificar fácilmente y examinar individualmente, ya que cada archivo contendrá los eventos de un día. Sin embargo, esto tampoco garantiza que cada archivo sea una unidad independiente de registros de las últimas 24 horas. A veces, una consulta de rendimiento lento puede tardar más de 24 horas en finalizar; los eventos podrían estar ocurriendo cuando se cierra el archivo anterior y se genera el nuevo. Este puede ser el caso durante un trabajo por lotes nocturno, lo que da como resultado que algunas partes de las consultas se registren en un archivo y el resto en otro.
Nuestra recomendación es encontrar un período de rotación de registros que funcione para su caso de uso Consulta la diferencia horaria entre dos periodos consecutivos de menor actividad (por ejemplo, entre un sábado y el siguiente). A continuación, puede establecer el valor "log_rotation_age" en esa diferencia horaria y, durante uno de esos períodos, reiniciar el servicio de PostgreSQL. De esa forma, PostgreSQL rotará el archivo de registro actual cuando ocurra el próximo período de calma. Sin embargo, si necesita reiniciar el servicio entre estos períodos, la rotación de registros volverá a estar sesgada. Tendrás que repetir este proceso entonces. Pero como muchas otras cosas en PostgreSQL, la prueba y el error dictarán el mejor valor. Además, si está utilizando una utilidad de administración de registros, la edad o el tamaño de la rotación de registros no importará porque el agente del administrador de registros recopilará cada evento del archivo a medida que se agregue.
Usar herramientas como pgBadger
pgBadger es un potente analizador de registros de PostgreSQL que puede crear información muy útil a partir de archivos de registro de Postgres. Es una herramienta de código abierto escrita en Perl con una huella muy pequeña en la máquina donde se ejecuta. La herramienta se ejecuta desde la línea de comandos y viene con una gran cantidad de opciones. Tomará uno o más registros como entrada y puede generar un informe HTML con estadísticas detalladas sobre:
- Consultas en espera más frecuentes.
- Consultas que generan la mayoría de los archivos temporales o los archivos temporales más grandes
- Consultas de ejecución más lenta
- Duración media de la consulta
- Consultas ejecutadas con más frecuencia
- Errores más frecuentes en consultas
- Usuarios y aplicaciones que ejecutan consultas
- Estadísticas de puntos de control.
- Vacío automático y análisis automático de estadísticas.
- Estadísticas de bloqueo
- Eventos de error (pánico, fatal, error y advertencia).
- Perfiles de conexión y sesión (por base de datos, usuario, aplicación)
- Perfiles de sesión
- Perfiles de consulta (tipos de consulta, consultas por base de datos/aplicación)
- Estadísticas de E/S
- etc.
Como mencioné antes, algunos de los parámetros de configuración relacionados con el registro deben estar habilitados para capturar todos los eventos de registro para que pgBadger pueda analizar esos registros de manera efectiva. Dado que esto puede producir archivos de registro grandes con muchos eventos, pgBadger solo debe usarse para crear puntos de referencia o solucionar problemas de rendimiento. Una vez que se han generado los registros detallados, los parámetros de configuración se pueden volver a cambiar a sus valores originales. Para un análisis de registros continuo, es mejor usar una aplicación de administración de registros dedicada.
Si se siente más cómodo haciendo cosas en el símbolo del sistema y haciendo uso de las vistas del sistema, querrá usar pg_stat_statements. De hecho, esto debería estar habilitado en cualquier instalación de producción de PostgreSQL.
pg_stat_statements es una extensión de PostgreSQL y ahora tiene la instalación predeterminada. Para habilitarlo, el parámetro de configuración “shared_preload_libraries” debe tener pg_stat_statements como uno de sus valores. Luego se puede instalar como cualquier otra extensión usando el comando "CREAR EXTENSIÓN". La extensión crea la vista pg_stat_statement que proporciona información valiosa relacionada con las consultas.
Utilice una aplicación de gestión de registros para obtener información
Hay muchas utilidades de administración de registros en el mercado y la mayoría de las organizaciones usan una o más en estos días. Independientemente de la herramienta que esté instalada, recomiendo utilizarla para recopilar y administrar los registros de PostgreSQL.
Hay algunas razones para ello:
Es mucho más fácil analizar, analizar y filtrar el ruido de los archivos de registro con una herramienta automatizada. A veces, un evento puede abarcar varios archivos de registro según la duración del evento y la antigüedad o el tamaño de rotación del registro. Tener un administrador de registros hace que sea mucho más sencillo presentar esta información como un todo.
Las soluciones de administración de registros de hoy en día generalmente vienen con la capacidad integrada de analizar los registros de PostgreSQL. Algunos también vienen con paneles que pueden mostrar las métricas más comunes extraídas de estos registros.
La mayoría de las aplicaciones modernas de gestión de registros también ofrecen potentes funciones de búsqueda, filtro, coincidencia de patrones, correlación de eventos y análisis de tendencias habilitadas para IA. Lo que no es visible para los ojos comunes puede hacerse evidente fácilmente con estas herramientas.
Finalmente, usar un administrador de registros para almacenar registros de PostgreSQL también significará que los eventos se guardarán para la posteridad, incluso si los archivos originales se eliminan de forma accidental o malintencionada.
Aunque hay ventajas obvias de usar una aplicación de administración de registros, muchas organizaciones tienen restricciones sobre dónde sus troncos pueden vivir. Este es un caso típico con soluciones basadas en SaaS donde los registros a menudo se guardan fuera de los límites geográficos de una organización, algo que puede no cumplir con los requisitos reglamentarios.
En tales casos, recomiendo elegir un proveedor con presencia en un centro de datos local, si es posible, o usar un administrador de registros autogestionado alojado en la red de la organización, como una pila ELK.
Palabras finales
Los registros del servidor PostgreSQL pueden ser una mina de oro de información cuando se configuran adecuadamente. El truco consiste en determinar qué registrar y cuánto registrar y, lo que es más importante, probar si los registros pueden proporcionar la información correcta cuando sea necesario. Será una cuestión de prueba y error, pero lo que he discutido aquí hoy debería dar un comienzo bastante decente. Como dije al principio, estaría más que feliz de conocer su experiencia al configurar el registro de PostgreSQL para obtener resultados óptimos.