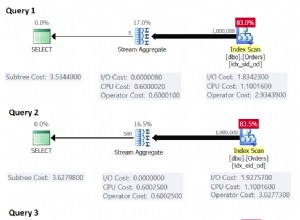
Ansible es simplemente genial y PostgreSQL es sin duda increíble, ¡veamos cómo funcionan juntos de manera increíble!

====================¡Anuncio en hora de máxima audiencia! ====================
La PGConf Europa 2015 tendrá lugar del 27 al 30 de octubre en Viena este año.
Supongo que posiblemente esté interesado en la administración de la configuración, la orquestación del servidor, la implementación automatizada (es por eso que está leyendo esta publicación de blog, ¿verdad?) y le gusta trabajar con PostgreSQL (seguro) en AWS (opcionalmente), entonces quizás desee unirse a mi charla "Administración de PostgreSQL con Ansible" el 28 de octubre, 15-15:50.
¡Consulte el increíble calendario y no pierda la oportunidad de asistir al mayor evento de PostgreSQL de Europa!
Espero verte allí, sí, me gusta tomar café después de las charlas 🙂
====================¡Anuncio en hora de máxima audiencia! ====================
¿Qué es Ansible y cómo funciona?
El lema de Ansible es "automatización de TI de código abierto simple, sin agentes y potente". ” citando documentos de Ansible.
Como se puede ver en la figura a continuación, la página de inicio de Ansible establece que las principales áreas de uso de Ansible son:aprovisionamiento, administración de configuración, implementación de aplicaciones, entrega continua, seguridad y cumplimiento, orquestación. El menú de descripción general también muestra en qué plataformas podemos integrar Ansible, es decir, AWS, Docker, OpenStack, Red Hat, Windows.
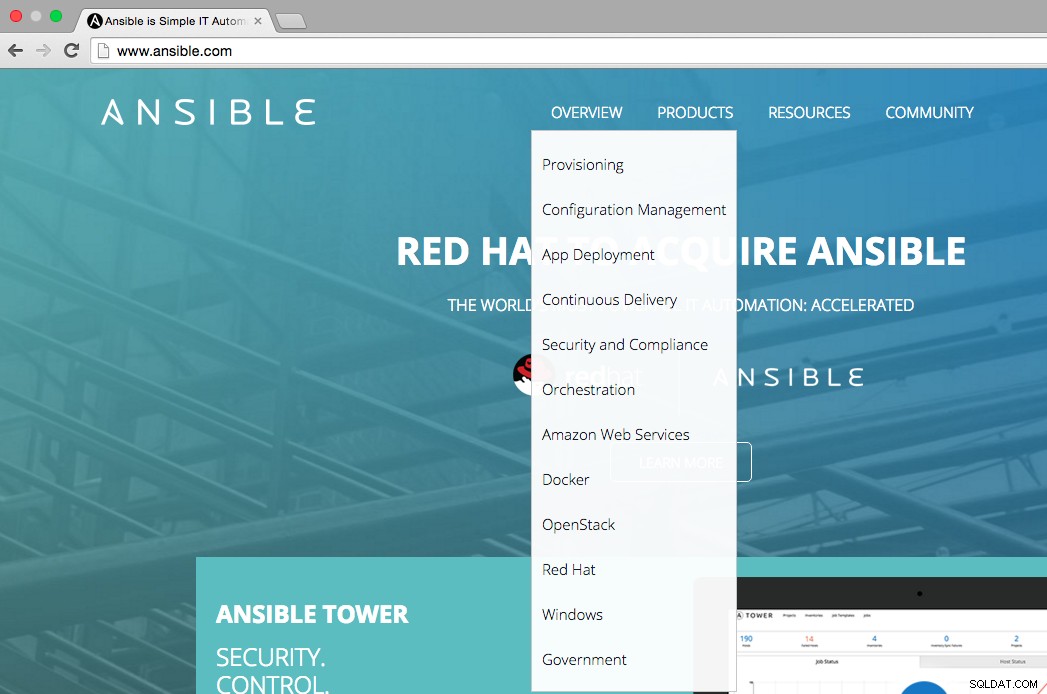
Revisemos los principales casos de uso de Ansible para comprender cómo funciona y qué tan útil es para los entornos de TI.
Aprovisionamiento
Ansible es su fiel amigo cuando desea automatizar todo en su sistema. No tiene agente y simplemente puede administrar sus cosas (es decir, servidores, balanceadores de carga, conmutadores, firewalls) a través de SSH. Ya sea que sus sistemas se ejecuten en servidores bare-metal o en la nube, Ansible estará allí y lo ayudará a aprovisionar sus instancias. Sus características idempotentes aseguran que siempre estarás en el estado que deseabas (y esperabas).
Gestión de la configuración
Una de las cosas más difíciles es no repetirse en tareas operativas repetitivas y aquí Ansible vuelve a la mente como salvador. En los viejos tiempos, cuando los tiempos eran malos, los administradores de sistemas escribían muchos scripts y se conectaban a muchos servidores para aplicarlos y obviamente no era lo mejor en sus vidas. Como todos sabemos, las tareas manuales son propensas a errores y generan un entorno heterogéneo en lugar de uno homogéneo y más manejable, lo que definitivamente hace que nuestra vida sea más estresante.
Con Ansible puede escribir playbooks simples (con la ayuda de documentación muy informativa y el apoyo de su gran comunidad) y una vez que escribe sus tareas puede llamar a una amplia gama de módulos (es decir, AWS, Nagios, PostgreSQL, SSH, APT, File módulos). Como resultado, puede concentrarse en actividades más creativas que en la administración manual de configuraciones.
Implementación de aplicaciones
Teniendo los artefactos listos, es muy fácil implementarlos en varios servidores. Dado que Ansible se comunica a través de SSH, no es necesario extraer datos de un repositorio en cada servidor ni preocuparse por métodos antiguos como copiar archivos a través de FTP. Ansible puede sincronizar artefactos y garantizar que solo se transfieran archivos nuevos o actualizados y que se eliminen los archivos obsoletos. Esto también acelera las transferencias de archivos y ahorra mucho ancho de banda.
Además de transferir archivos, Ansible también ayuda a preparar los servidores para su uso en producción. Antes de la transferencia, puede pausar el monitoreo, eliminar servidores de los balanceadores de carga y detener servicios. Después de la implementación, puede iniciar servicios, agregar servidores a balanceadores de carga y reanudar el monitoreo.
Todo esto no tiene que suceder a la vez para todos los servidores. Ansible puede funcionar en un subconjunto de servidores a la vez para proporcionar implementaciones sin tiempo de inactividad. Por ejemplo, al mismo tiempo puede implementar 5 servidores a la vez y luego puede implementarse en los siguientes 5 servidores cuando hayan terminado.
Después de implementar este escenario, se puede ejecutar en cualquier lugar. Los desarrolladores o miembros del equipo de control de calidad pueden realizar implementaciones en sus propias máquinas con fines de prueba. Además, para revertir una implementación por cualquier motivo, todo lo que Ansible necesita es la ubicación de los últimos artefactos de trabajo conocidos. Luego puede volver a implementarlos fácilmente en servidores de producción para volver a poner el sistema en un estado estable.
Entrega continua
La entrega continua significa adoptar un enfoque rápido y simple para los lanzamientos. Para lograr ese objetivo, es crucial utilizar las mejores herramientas que permitan lanzamientos frecuentes sin tiempos de inactividad y requieran la menor intervención humana posible. Dado que hemos aprendido sobre las capacidades de implementación de aplicaciones de Ansible anteriormente, es bastante fácil realizar implementaciones sin tiempo de inactividad. El otro requisito para la entrega continua son menos procesos manuales y eso significa automatización. Ansible puede automatizar cualquier tarea, desde el aprovisionamiento de servidores hasta la configuración de servicios para estar listos para la producción. Después de crear y probar escenarios en Ansible, se vuelve trivial ponerlos frente a un sistema de integración continua y dejar que Ansible haga su trabajo.
Seguridad y Cumplimiento
La seguridad siempre se considera lo más importante, pero mantener los sistemas seguros es una de las cosas más difíciles de lograr. Debe estar seguro de la seguridad de sus datos, así como de la seguridad de los datos de sus clientes. Para estar seguro de la seguridad de sus sistemas, definir la seguridad no es suficiente, debe poder aplicar esa seguridad y monitorear constantemente sus sistemas para garantizar que sigan cumpliendo con esa seguridad.
Ansible es fácil de usar, ya sea para configurar reglas de firewall, bloquear usuarios y grupos o aplicar políticas de seguridad personalizadas. Es seguro por su naturaleza, ya que puede aplicar repetidamente la misma configuración y solo realizará los cambios necesarios para que el sistema vuelva a cumplir.
Orquestación
Ansible se asegura de que todas las tareas asignadas estén en el orden correcto y establece una armonía entre todos los recursos que administra. Orquestar implementaciones complejas de varios niveles es más fácil con las capacidades de implementación y administración de configuración de Ansible. Por ejemplo, considerando la implementación de una pila de software, preocupaciones como asegurarse de que todos los servidores de bases de datos estén listos antes de activar los servidores de aplicaciones o configurar la red antes de agregar servidores al balanceador de carga ya no son problemas complicados.
Ansible también ayuda a la orquestación de otras herramientas de orquestación como CloudFormation de Amazon, Heat de OpenStack, Swarm de Docker, etc. De esta manera, en lugar de aprender diferentes plataformas, idiomas y reglas; los usuarios solo pueden concentrarse en la sintaxis YAML de Ansible y en los potentes módulos.
¿Qué es un módulo Ansible?
Los módulos o bibliotecas de módulos proporcionan a Ansible medios para controlar o administrar recursos en servidores locales o remotos. Realizan una variedad de funciones. Por ejemplo, un módulo puede ser responsable de reiniciar una máquina o simplemente puede mostrar un mensaje en la pantalla.
Ansible permite a los usuarios escribir sus propios módulos y también proporciona módulos básicos o extras listos para usar.
¿Qué pasa con los libros de jugadas de Ansible?
Ansible nos permite organizar nuestro trabajo de varias maneras. En su forma más directa, podemos trabajar con los módulos de Ansible usando el “ansible ” herramienta de línea de comandos y el archivo de inventario.
Inventario
Uno de los conceptos más importantes es el inventario . Necesitamos un archivo de inventario para que Ansible sepa qué servidores necesita conectarse mediante SSH, qué información de conexión requiere y, opcionalmente, qué variables están asociadas con esos servidores.
El archivo de inventario está en un formato similar a INI. En el archivo de inventario, podemos especificar más de un host y agruparlos en más de un grupo de host.
Nuestro ejemplo de archivo de inventario hosts.ini es como el siguiente:
[dbservers]
db.example.com
Aquí tenemos un solo host llamado "db.example.com" en un grupo de hosts llamado "dbservers". En el archivo de inventario, también podemos incluir puertos SSH personalizados, nombres de usuario SSH, claves SSH, información de proxy, variables, etc.
Dado que tenemos un archivo de inventario listo, para ver los tiempos de actividad de nuestros servidores de bases de datos, podemos invocar el "comando de Ansible ” y ejecute el módulo “uptime Comando en esos servidores:
ansible dbservers -i hosts.ini -m command -a "uptime"
Aquí le indicamos a Ansible que lea los hosts del archivo hosts.ini, los conecte usando SSH, ejecute el "tiempo de actividad ” comando en cada uno de ellos, y luego imprima su salida en la pantalla. Este tipo de ejecución de módulo se denomina comando ad-hoc .
La salida del comando será como:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Sin embargo, si nuestra solución contiene más de un solo paso, se vuelve difícil administrarlos solo mediante el uso de comandos ad-hoc.
Aquí vienen los libros de jugadas de Ansible. Nos permite organizar nuestra solución en un archivo de playbook al integrar todos los pasos por medio de tareas, variables, roles, plantillas, controladores y un inventario.
Echemos un breve vistazo a algunos de estos términos para entender cómo nos pueden ayudar.
Tareas
Otro concepto importante son las tareas. Cada tarea de Ansible contiene un nombre, un módulo al que llamar, parámetros del módulo y, opcionalmente, condiciones previas y posteriores. Nos permiten llamar a módulos de Ansible y pasar información a tareas consecutivas.
Variables
También hay variables. Son muy útiles para reutilizar la información que proporcionamos o recopilamos. Podemos definirlos en el inventario, en archivos YAML externos o en libros de jugadas.
Libro de jugadas
Los playbooks de Ansible se escriben con la sintaxis YAML. Puede contener más de una jugada. Cada juego contiene el nombre de los grupos anfitriones a los que conectarse y las tareas que debe realizar. También puede contener variables/roles/controladores, si están definidos.
Ahora podemos mirar un libro de jugadas muy simple para ver cómo se puede estructurar:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeEn este libro de jugadas muy simple, le dijimos a Ansible que debería operar en servidores definidos en el grupo de host "dbservers". Creamos una variable llamada “quién” y luego definimos nuestras tareas. Observe que en la primera tarea en la que imprimimos un mensaje de depuración, usamos la variable "quién" e hicimos que Ansible imprimiera "Hello World" en la pantalla. En la segunda tarea, le dijimos a Ansible que se conectara a cada host y luego ejecutara el comando "tiempo de actividad" allí.
Módulos PostgreSQL de Ansible
Ansible proporciona una serie de módulos para PostgreSQL. Algunos de ellos se encuentran en los módulos principales, mientras que otros se pueden encontrar en los módulos adicionales.
Todos los módulos PostgreSQL requieren que el paquete Python psycopg2 esté instalado en la misma máquina con el servidor PostgreSQL. Psycopg2 es un adaptador de base de datos PostgreSQL en el lenguaje de programación Python.
En los sistemas Debian/Ubuntu, el paquete psycopg2 se puede instalar usando el siguiente comando:
apt-get install python-psycopg2
Ahora vamos a examinar estos módulos en detalle. A modo de ejemplo, trabajaremos en un servidor PostgreSQL en el host db.example.com en el puerto 5432 con postgres usuario y una contraseña vacía.
postgresql_db
Este módulo central crea o elimina una base de datos PostgreSQL determinada. En la terminología de Ansible, asegura que una base de datos PostgreSQL dada esté presente o ausente.
La opción más importante es el parámetro requerido “nombre ”. Representa el nombre de la base de datos en un servidor PostgreSQL. Otro parámetro significativo es “estado ”. Requiere uno de dos valores:presente o ausente . Esto nos permite crear o eliminar una base de datos que se identifica por el valor dado en el nombre parámetro.
Algunos flujos de trabajo también pueden requerir la especificación de parámetros de conexión como login_host , puerto , usuario_usuario y contraseña_de_inicio de sesión .
Vamos a crear una base de datos llamada “module_test ” en nuestro servidor PostgreSQL agregando las siguientes líneas a nuestro archivo de libro de jugadas:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Aquí, nos conectamos a nuestro servidor de base de datos de prueba en db.example.com con el usuario; postgres . Sin embargo, no tiene que ser el postgres user como nombre de usuario puede ser cualquier cosa.
Eliminar la base de datos es tan fácil como crearla:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Tenga en cuenta el valor "ausente" en el parámetro "estado".
postgresql_ext
Se sabe que PostgreSQL tiene extensiones muy útiles y poderosas. Por ejemplo, una extensión reciente es tsm_system_rows lo que ayuda a obtener el número exacto de filas en el muestreo de tablas. (Para obtener más información, puede consultar mi publicación anterior sobre métodos de muestreo de tablas).
Este módulo de extras agrega o elimina extensiones de PostgreSQL de una base de datos. Requiere dos parámetros obligatorios:db y nombre . La base de datos el parámetro se refiere al nombre de la base de datos y al nombre El parámetro hace referencia al nombre de la extensión. También tenemos el estado parámetro que necesita presente o ausente valores y los mismos parámetros de conexión que en el módulo postgresql_db.
Comencemos por crear la extensión de la que hablamos:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
usuario_postgresql
Este módulo central permite agregar o eliminar usuarios y roles de una base de datos PostgreSQL.
Es un módulo muy poderoso porque mientras asegura que un usuario esté presente en la base de datos, también permite la modificación de privilegios o roles al mismo tiempo.
Comencemos mirando los parámetros. El único parámetro obligatorio aquí es "nombre ”, que hace referencia a un usuario o un nombre de rol. Además, como en la mayoría de los módulos de Ansible, el "estado El parámetro ” es importante. Puede tener uno de presente o ausente valores y su valor predeterminado es presente .
Además de los parámetros de conexión como en los módulos anteriores, algunos otros parámetros opcionales importantes son:
- bd :Nombre de la base de datos donde se otorgarán los permisos
- contraseña :Contraseña del usuario
- privado :Privilegios en "priv1/priv2" o privilegios de tabla en formato "table:priv1,priv2,..."
- role_attr_flags :Atributos de rol. Los valores posibles son:
- [NO]SUPERUSUARIO
- [NO]CREATEROLA
- [NO]CREAR USUARIO
- [NO]CREADOB
- [NO]HEREDAR
- [NO]INICIAR SESIÓN
- [SIN]REPLICACIÓN
Para crear un nuevo usuario llamado ada con contraseña lovelace y un privilegio de conexión a la base de datos module_test , podemos agregar lo siguiente a nuestro libro de jugadas:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Ahora que tenemos al usuario listo, podemos asignarle algunos roles. Para permitir que “ada” inicie sesión y cree bases de datos:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
También podemos otorgar privilegios globales o basados en tablas como “INSERT ”, “ACTUALIZAR ”, “SELECCIONAR ”, y “ELIMINAR ” usando el priv parámetro. Un punto importante a considerar es que un usuario no puede ser eliminado hasta que todos los privilegios otorgados sean revocados primero.
postgresql_privs
Este módulo central otorga o revoca privilegios sobre los objetos de la base de datos de PostgreSQL. Los objetos admitidos son:tabla , secuencia , función , base de datos , esquema , idioma , espacio de tabla y grupo .
Los parámetros requeridos son "base de datos"; nombre de la base de datos para otorgar/revocar privilegios y “roles”; una lista de nombres de roles separados por comas.
Los parámetros opcionales más importantes son:
- tipo :Tipo de objeto sobre el que establecer privilegios. Puede ser uno de:tabla, secuencia, función, base de datos, esquema, idioma, tablespace, grupo . El valor predeterminado es tabla .
- objetos :Objetos de base de datos para establecer privilegios. Puede tener varios valores. En ese caso, los objetos se separan mediante una coma.
- privilegios :Lista separada por comas de privilegios para otorgar o revocar. Los valores posibles incluyen:TODOS , SELECCIONAR , ACTUALIZAR , INSERTAR .
Veamos cómo funciona esto otorgando todos los privilegios en el "público ” esquema a “ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Una de las características más poderosas de PostgreSQL es su compatibilidad con prácticamente cualquier lenguaje para ser utilizado como lenguaje de procedimiento. Este módulo de extras agrega, elimina o cambia lenguajes de procedimiento con una base de datos PostgreSQL.
El único parámetro obligatorio es “lang ”; nombre del lenguaje de procedimiento para agregar o quitar. Otras opciones importantes son “db ”; el nombre de la base de datos donde se agrega o elimina el idioma, y "confiar ”; opción para hacer que el idioma sea confiable o no confiable para la base de datos seleccionada.
Habilitemos el lenguaje PL/Python para nuestra base de datos:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Poniéndolo todo junto
Ahora que sabemos cómo está estructurado un libro de jugadas de Ansible y qué módulos de PostgreSQL están disponibles para que los usemos, ahora podemos combinar nuestros conocimientos en un libro de jugadas de Ansible.
La forma final de nuestro playbook main.yml es como la siguiente:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Ahora podemos ejecutar nuestro libro de jugadas usando el comando "ansible-playbook":
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Puede encontrar el inventario y el archivo del libro de estrategias en mi repositorio de GitHub creado para esta publicación de blog. También hay otro libro de jugadas llamado "remove.yml" que deshace todo lo que hicimos en el libro de jugadas principal.
Para obtener más información sobre Ansible:
- Echa un vistazo a sus documentos bien escritos.
- Mire el video de inicio rápido de Ansible, que es un tutorial muy útil.
- Siga su calendario de seminarios web, hay algunos próximos seminarios web interesantes en la lista.