PostgreSQL es un proyecto impresionante y evoluciona a un ritmo asombroso. Nos centraremos en la evolución de las capacidades de tolerancia a fallas en PostgreSQL a lo largo de sus versiones con una serie de publicaciones de blog. Esta es la cuarta publicación de la serie y hablaremos sobre la confirmación sincrónica y sus efectos en la tolerancia a fallas y la confiabilidad de PostgreSQL.
Si desea presenciar el progreso de la evolución desde el principio, consulte las tres primeras publicaciones de blog de la serie a continuación. Cada publicación es independiente, por lo que no es necesario leer una para comprender la otra.
- Evolución de la tolerancia a fallos en PostgreSQL
- Evolución de la tolerancia a fallos en PostgreSQL:Fase de replicación
- Evolución de la tolerancia a fallos en PostgreSQL:viaje en el tiempo
Confirmación sincrónica
De forma predeterminada, PostgreSQL implementa la replicación asincrónica, donde los datos se transmiten cuando sea conveniente para el servidor. Esto puede significar la pérdida de datos en caso de conmutación por error. Es posible pedirle a Postgres que requiera uno (o más) dispositivos de reserva para reconocer la replicación de los datos antes de la confirmación, esto se denomina replicación sincrónica (confirmación sincrónica ) .
Con la replicación síncrona, el retraso de la replicación directamente afecta el tiempo transcurrido de las transacciones en el maestro. Con la replicación asíncrona, el maestro puede continuar a toda velocidad.
La replicación síncrona garantiza que los datos se escriban en al menos dos nodos antes de que se le informe al usuario o a la aplicación que se ha confirmado una transacción.
El usuario puede seleccionar el modo de compromiso de cada transacción , de modo que sea posible tener transacciones de confirmación sincrónicas y asincrónicas ejecutándose simultáneamente.
Esto permite compensaciones flexibles entre el rendimiento y la certeza de la durabilidad de la transacción.
Configuración de confirmación síncrona
Para configurar la replicación síncrona en Postgres necesitamos configurar synchronous_commit parámetro en postgresql.conf.
El parámetro especifica si la confirmación de la transacción esperará a que los registros WAL se escriban en el disco antes de que el comando devuelva un éxito. indicación al cliente. Los valores válidos son on , aplicación_remota , remote_write , local y apagado . Discutiremos cómo funcionan las cosas en términos de replicación síncrona cuando configuremos synchronous_commit parámetro con cada uno de los valores definidos.
Comencemos con la documentación de Postgres (9.6):
Aquí entendemos el concepto de confirmación sincrónica, como describimos en la parte de introducción de la publicación, puede configurar la replicación sincrónica, pero si no lo hace, siempre existe el riesgo de perder datos. Pero sin riesgo de crear inconsistencias en la base de datos, a diferencia de desactivar fsync off – sin embargo eso es tema para otro post -. Por último, llegamos a la conclusión de que, si es necesario, no queremos perder ningún dato entre los retrasos de replicación y queremos estar seguros de que los datos se escriben en al menos dos nodos antes de que se informe al usuario/aplicación que la transacción se ha confirmado. , tenemos que aceptar perder algo de rendimiento.
Veamos cómo funcionan las diferentes configuraciones para diferentes niveles de sincronización. Antes de comenzar, hablemos de cómo la replicación de PostgreSQL procesa la confirmación. El cliente ejecuta consultas en el nodo maestro, los cambios se escriben en un registro de transacciones (WAL) y se copian a través de la red en WAL en el nodo en espera. El proceso de recuperación en el nodo en espera luego lee los cambios de WAL y los aplica a los archivos de datos al igual que durante la recuperación de fallas. Si el modo de espera está en modo de espera activo modo, los clientes pueden emitir consultas de solo lectura en el nodo mientras esto sucede. Para obtener más detalles sobre cómo funciona la replicación, puede consultar la publicación de blog sobre replicación de esta serie.
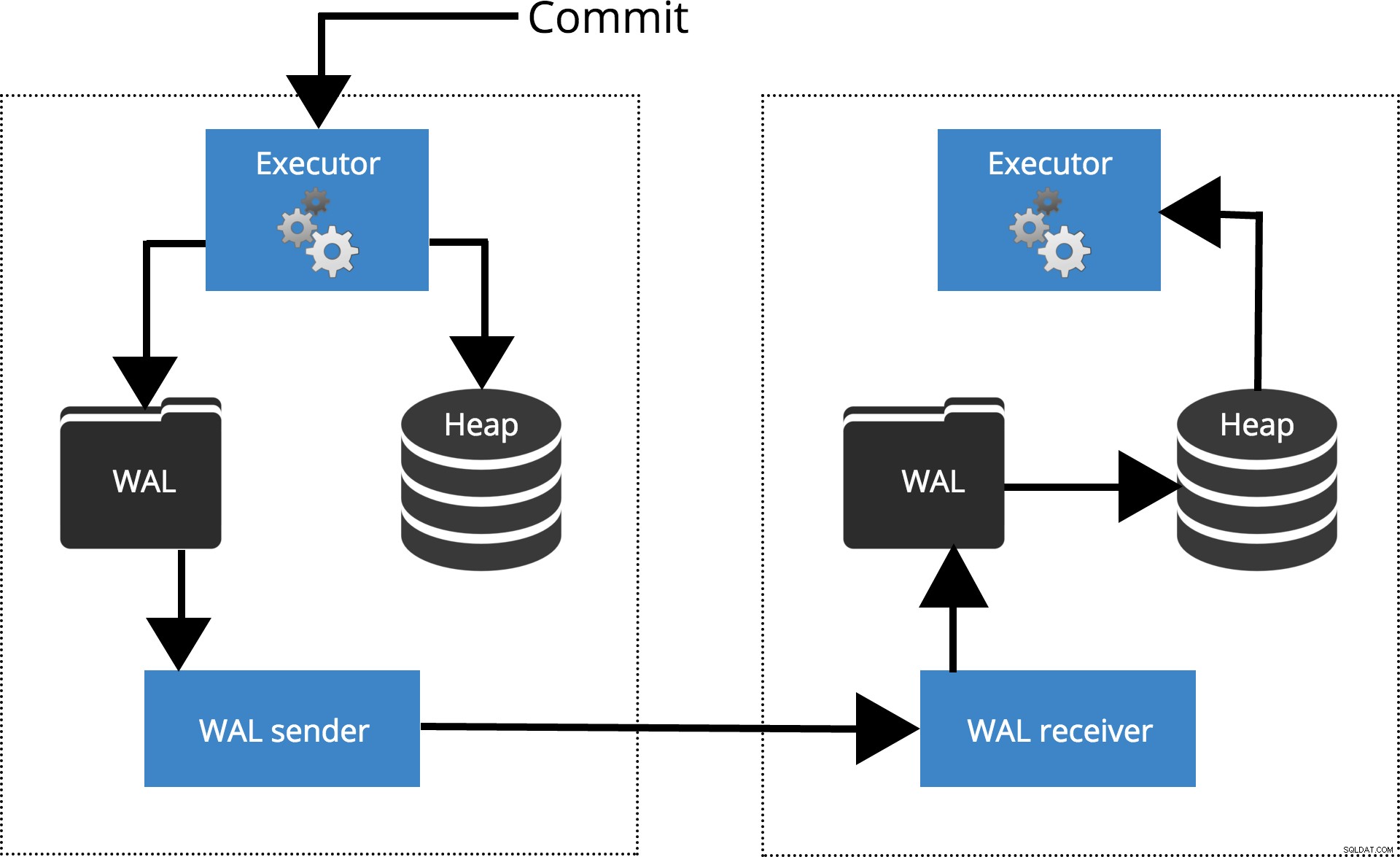
Fig.1 Cómo funciona la replicación
commit_sincrónico =desactivado
Cuando configuramos sychronous_commit = off, el COMMIT no espera a que el registro de la transacción se vacíe en el disco. Esto se destaca en la Fig. 2 a continuación.
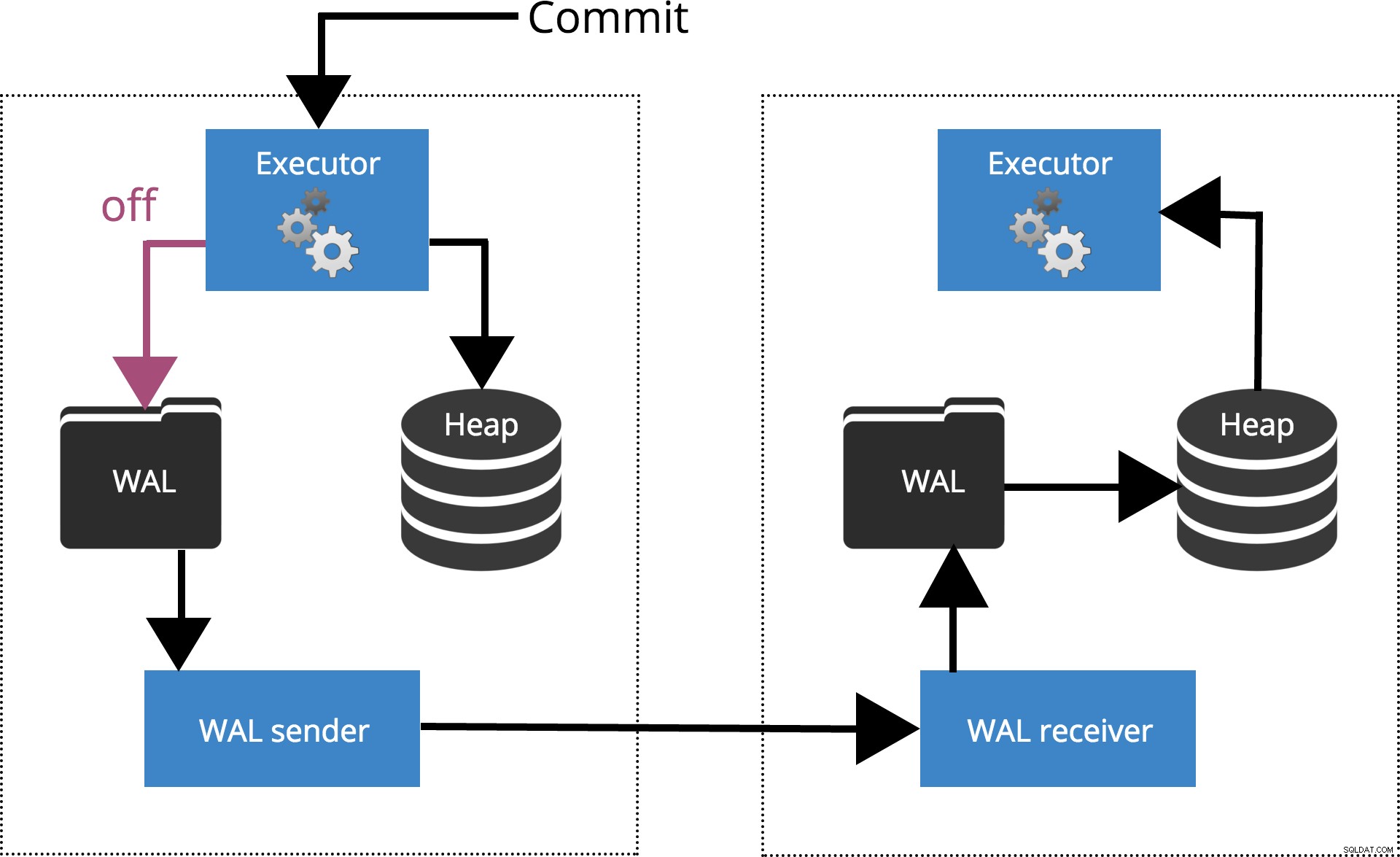
Fig.2 synchronous_commit =off
compromiso_sincrónico =local
Cuando configuramos synchronous_commit = local, el COMMIT espera hasta que el registro de la transacción se vacía en el disco local. Esto se destaca en la Fig. 3 a continuación.
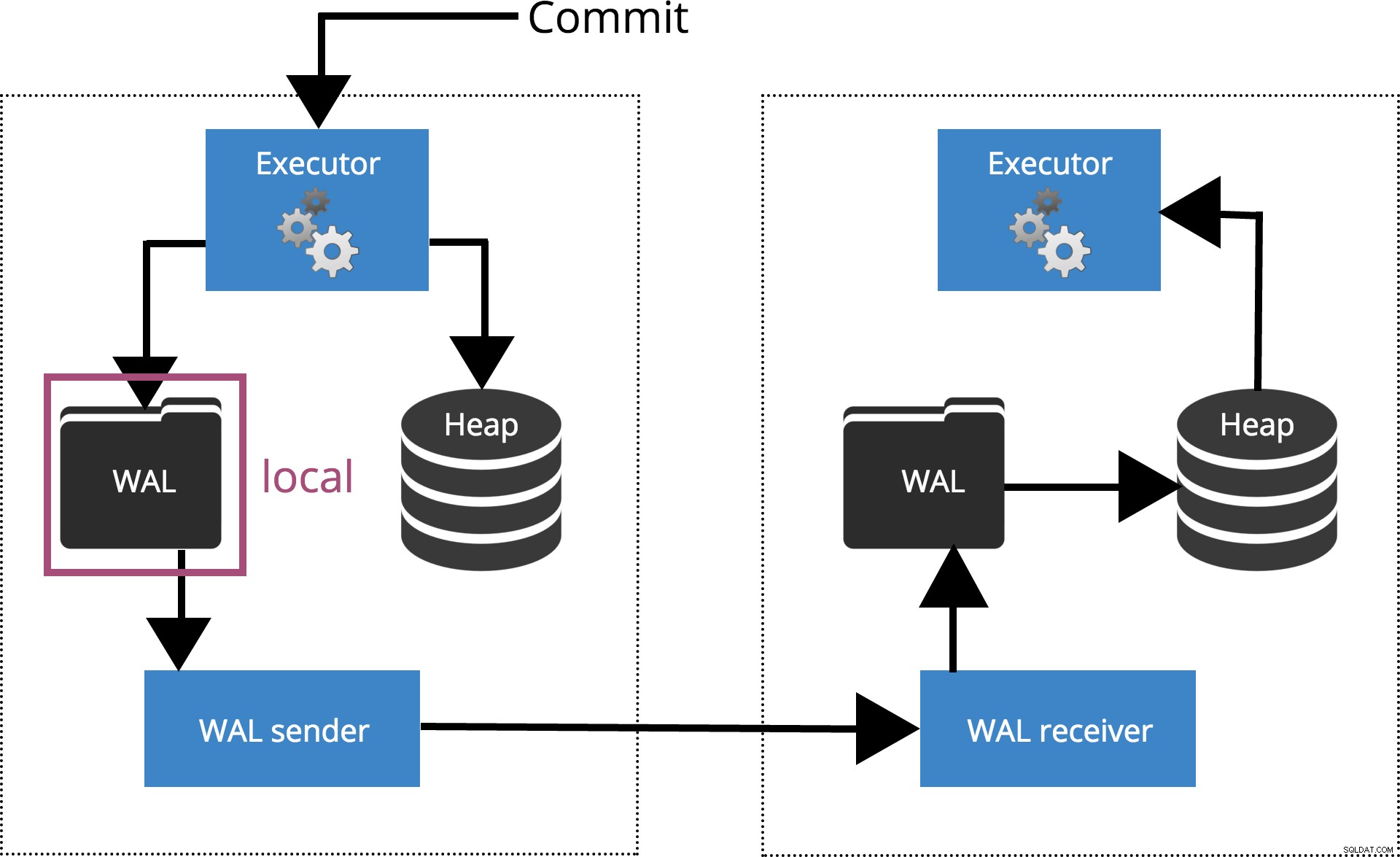
Fig.3 synchronous_commit =local
synchronous_commit =activado (predeterminado)
Cuando activamos synchronous_commit = on, el COMMIT esperará hasta que los servidores especificados por synchronous_standby_names confirme que el registro de la transacción se escribió de forma segura en el disco. Esto se destaca en la Fig. 4 a continuación.
synchronous_standby_names está vacío, esta configuración se comporta igual que synchronous_commit = local .
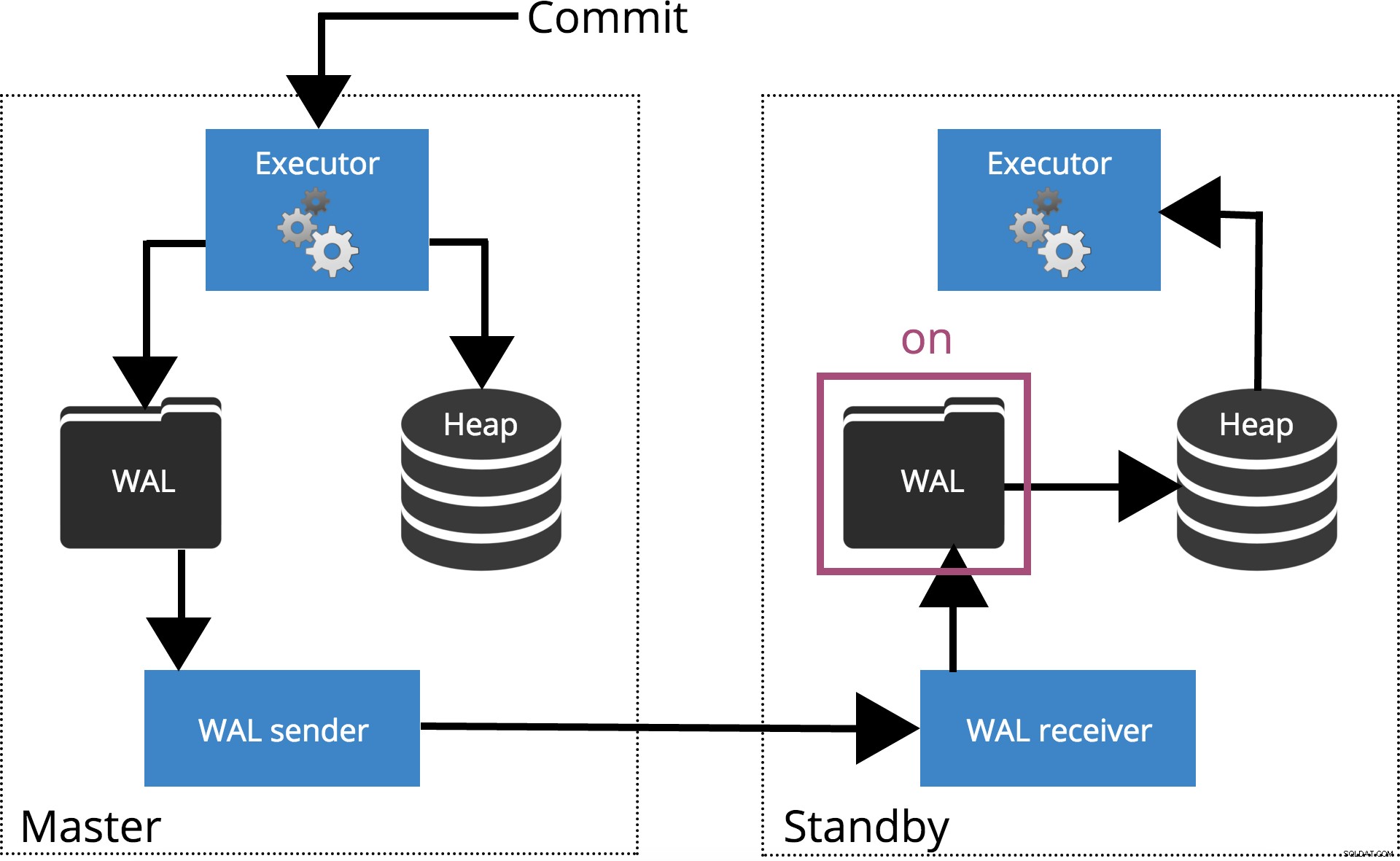
Fig.4 synchronous_commit =activado
commit_sincrónico =escritura_remota
Cuando configuramos synchronous_commit = remote_write, el COMMIT esperará hasta que los servidores especificados por synchronous_standby_names confirme la escritura del registro de la transacción en el sistema operativo, pero no necesariamente ha llegado al disco. Esto se destaca en la figura 5 a continuación.
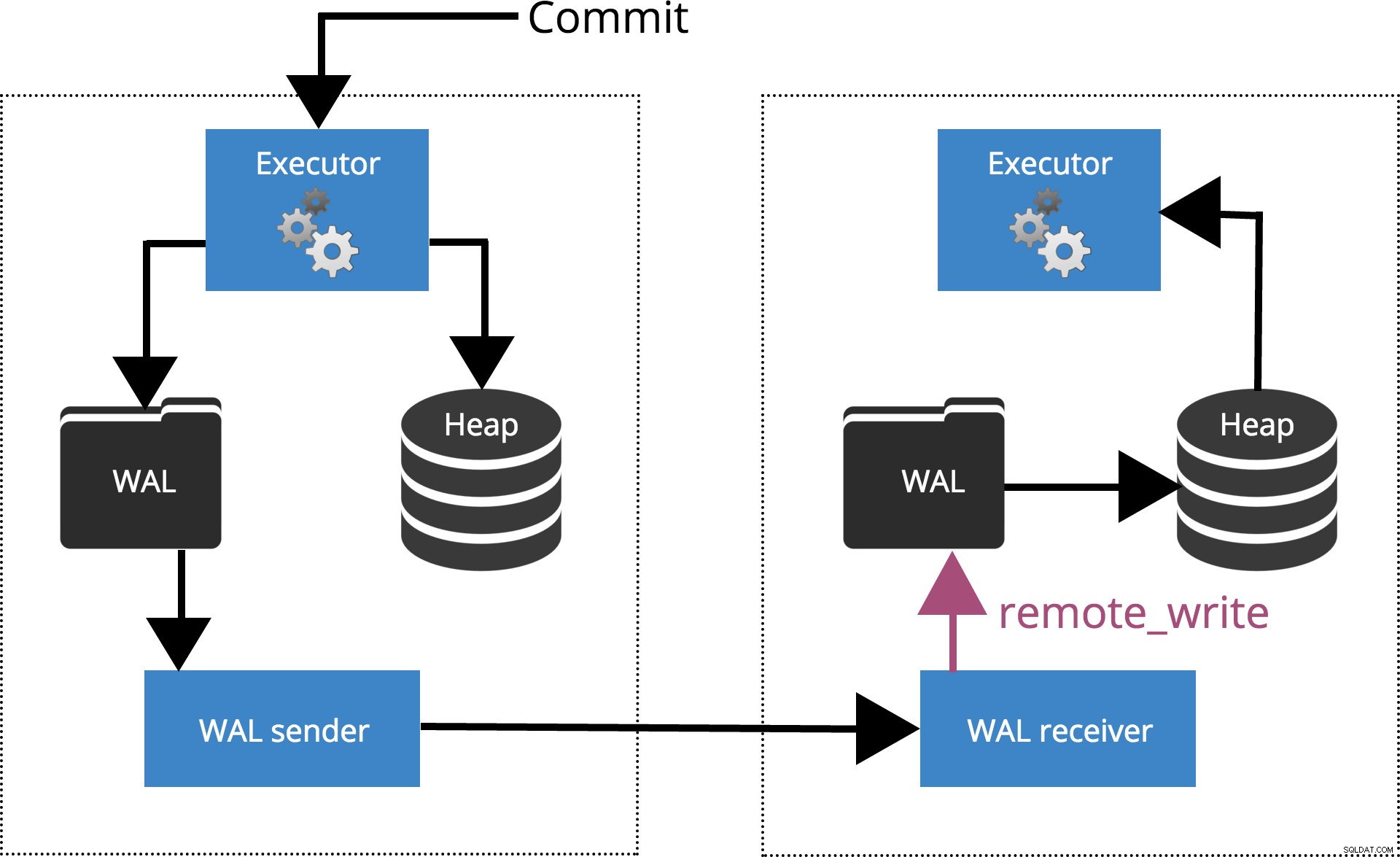
Fig.5 synchronous_commit =remote_write
compromiso_sincrónico =aplicación_remota
Cuando establecemos synchronous_commit = remote_apply, el COMMIT esperará hasta que los servidores especificados por synchronous_standby_names confirmar que el registro de transacciones se aplicó a la base de datos. Esto se destaca en la Fig. 6 a continuación.
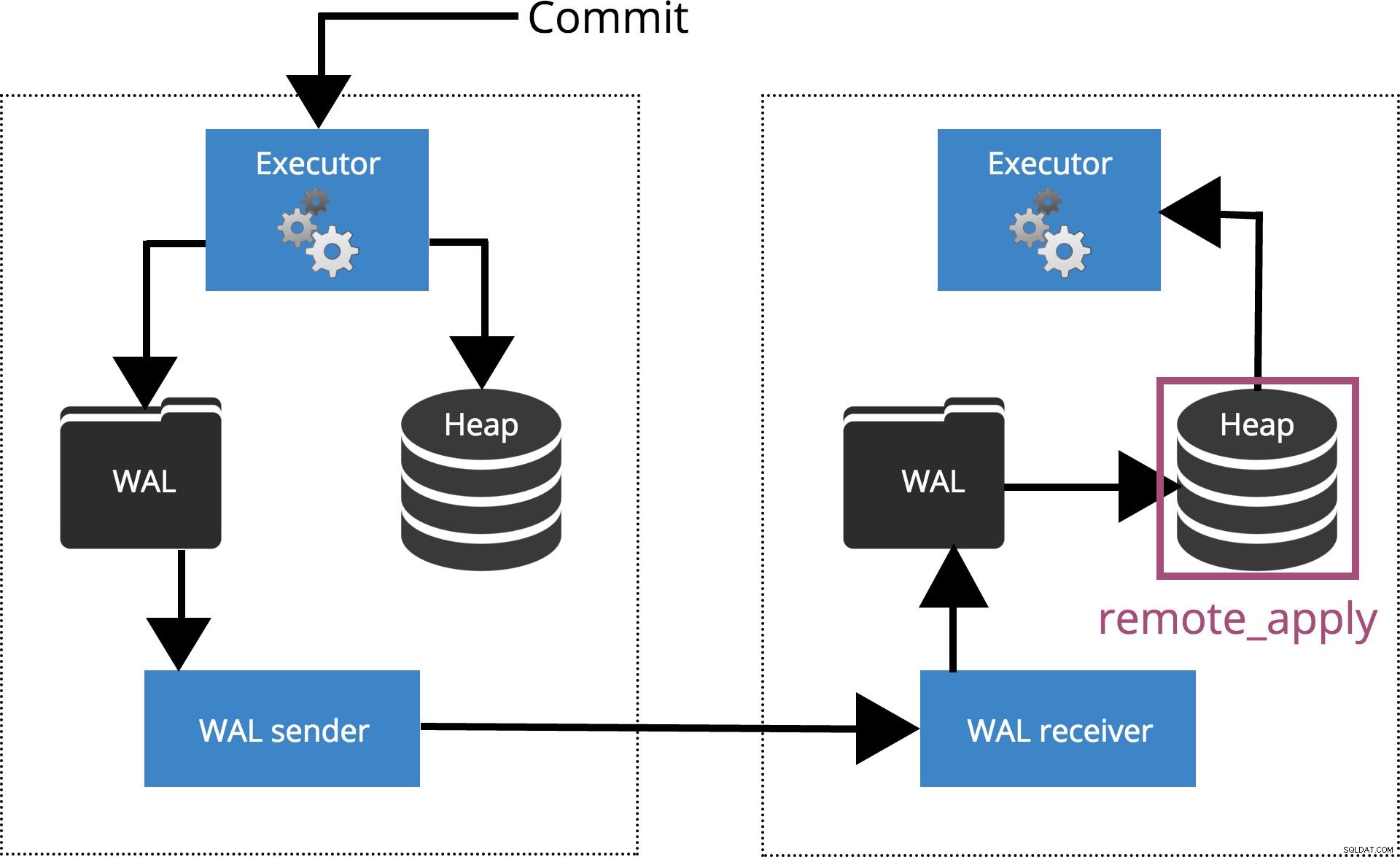
Fig.6 synchronous_commit =aplicación_remota
Ahora, echemos un vistazo a sychronous_standby_names parámetro en detalles, al que se hace referencia anteriormente al establecer synchronous_commit como on , remote_apply o remote_write .
nombres_de_espera_sincrónicos ='nombre_de_espera [, ...]'
La confirmación síncrona esperará la respuesta de uno de los standby enumerados en el orden de prioridad. Esto significa que si el primer modo de espera está conectado y está transmitiendo, la confirmación síncrona siempre esperará su respuesta, incluso si el segundo modo de espera ya respondió. El valor especial de * se puede usar como stanby_name que coincidirá con cualquier modo de espera conectado.
synchronous_standby_names =‘num (standby_name [, …])’
La confirmación síncrona esperará la respuesta de al menos num número de standby enumerados en orden de prioridad. Se aplican las mismas reglas que las anteriores. Entonces, por ejemplo, establecer synchronous_standby_names = '2 (*)' hará que la confirmación síncrona espere la respuesta de cualquiera de los 2 servidores en espera.
synchronous_standby_names está vacío
Si este parámetro está vacío como se muestra, cambia el comportamiento de establecer synchronous_commit a on , remote_write o remote_apply comportarse igual que local (es decir, el COMMIT solo esperará a que se vacíe al disco local).
Conclusión
En esta publicación de blog, discutimos la replicación síncrona y describimos los diferentes niveles de protección que están disponibles en Postgres. Continuaremos con la replicación lógica en la próxima entrada del blog.
Referencias
Un agradecimiento especial a mi colega Petr Jelinek por darme la idea de las ilustraciones.
Documentación de PostgreSQL
Libro de recetas de administración de PostgreSQL 9:segunda edición