Durante los últimos meses, en 2ndQuadrant hemos estado trabajando en la fusión de PostgreSQL 9.6 en Postgres-XL, lo que resultó ser un gran desafío por varias razones y tomó más tiempo del planeado inicialmente debido a varios cambios invasivos en la parte superior. Si está interesado, consulte el repositorio oficial aquí (consulte la rama "maestra" por ahora).
Todavía queda bastante trabajo por hacer:fusionar algunos bits restantes de upstream, corregir errores conocidos y fallas de regresión, realizar pruebas, etc. Si está considerando contribuir a Postgres-XL, esta es una oportunidad ideal (envíeme un e-mail y te ayudo con los primeros pasos).
Pero en general, Postgres-XL 9.6 es claramente un gran paso adelante en varias áreas importantes.
Nuevas funciones en Postgres-XL 9.6
Entonces, ¿qué características nuevas obtiene Postgres-XL de la fusión de PostgreSQL 9.6? Simplemente podría indicarle las notas de la versión anterior:la mayoría de las mejoras se aplican directamente a XL 9.6, con la excepción de las relacionadas con las funciones que no son compatibles con XL.
La principal mejora visible para el usuario en PostgreSQL 9.6 fue claramente la consulta en paralelo, y eso también se aplica a Postgres-XL 9.6.
Paralelismo intranodo
Antes de PostgreSQL 9.6, Postgres-XL era una de las formas de obtener consultas paralelas (colocando múltiples nodos de Postgres-XL en la misma máquina). Desde PostgreSQL 9.6 eso ya no es necesario, pero también significa que Postgres-XL gana capacidad de paralelismo dentro de los nodos.
A modo de comparación, esto es lo que Postgres-XL 9.5 le permitió hacer:distribuir una consulta a múltiples nodos de datos, pero cada nodo de datos aún estaba sujeto al límite de "un servidor por consulta", al igual que PostgreSQL simple.
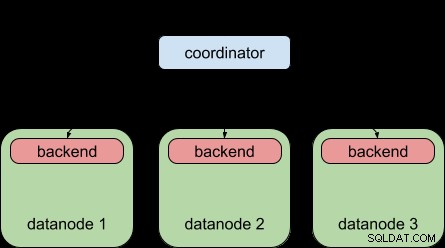
Gracias a la función de consulta paralela de PostgreSQL 9.6, Postgres-XL 9.6 ahora puede hacer esto:
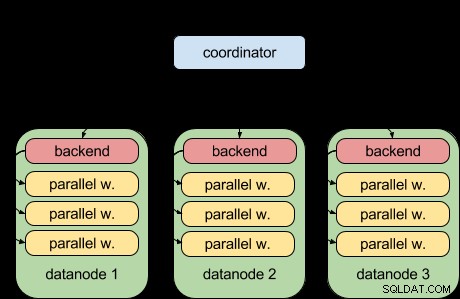
Es decir, cada nodo de datos ahora puede ejecutar su parte de la consulta en paralelo, utilizando la infraestructura de consulta paralela ascendente. Eso es genial y hace que Postgres-XL sea mucho más poderoso cuando se trata de cargas de trabajo analíticas.
Mantenimiento de un tenedor
Mencioné que esta fusión resultó ser más desafiante de lo que inicialmente esperábamos, por varias razones.
En primer lugar, el mantenimiento de bifurcaciones en general es difícil, especialmente cuando el proyecto ascendente avanza tan rápido como PostgreSQL. Debe desarrollar características específicas para su bifurcación, razón por la cual existen las bifurcaciones en primer lugar. Pero también desea mantenerse al día con la corriente, de lo contrario, se queda atrás sin remedio. Es por eso que algunas de las bifurcaciones existentes todavía están atascadas en PostgreSQL 8.x, y se pierden todas las cosas valiosas que se han cometido desde entonces.
En segundo lugar, la fusión se realizó en un gran bloque, al igual que todos los anteriores (9.5, 9.2, …). Es decir, todas las confirmaciones ascendentes se fusionaron en un solo comando git merge. Eso está bastante garantizado para causar muchos conflictos de fusión, en la medida en que el código ni siquiera se compila, sin mencionar la ejecución de pruebas de regresión o algo por el estilo.
Entonces, el primer lote de correcciones se trata de ponerlo en un estado compilable, el siguiente lote se trata de hacer que se ejecute realmente sin fallas de segmento inmediatas, y finalmente comienza la corrección "regular" (ejecutar pruebas de regresión, solucionar problemas, enjuagar y repetir) .
Estas complejidades son inherentes al mantenimiento de la bifurcación (y una razón por la que probablemente debería reconsiderar iniciar otra bifurcación y, en su lugar, contribuir directamente a Postgres y/o Postgres-XL).
Pero hay formas de reducir significativamente el impacto; por ejemplo, planeamos hacer la próxima fusión (con PostgreSQL 10) en partes más pequeñas. Eso debería minimizar el alcance de los conflictos de fusión y permitirnos resolver las fallas mucho más rápido.
Más cerca de PostgreSQL
Curiosamente, la adopción del paralelismo del upstream también nos permitió deshacernos de una gran cantidad de código de la base de código XL; un excelente ejemplo de esto es el código agregado paralelo, que reemplazó fácilmente el código específico de XL.
Otro ejemplo de un cambio ascendente que afectó significativamente el código XL es la "patificación" del planificador superior, impulsada al final del ciclo de desarrollo 9.6. Esto resultó ser un cambio muy invasivo (de hecho, es probable que varios de los errores abiertos estén relacionados con él), pero al final nos permitió simplificar el código de planificación (esencialmente construir rutas adecuadas en lugar de modificar el plan resultante).
Cuando digo que la fusión nos permitió simplificar el código XL y acercarlo a PostgreSQL, ¿qué quiero decir con eso? La forma más sencilla de cuantificar el cambio es hacer "git diff -stat" contra la rama ascendente coincidente y comparar los números. Para las ramas 9.5 y 9.6, los resultados se ven así:
| versión | archivos cambiados | adiciones | eliminaciones |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Claramente, la fusión 9.6 reduce significativamente el delta frente a upstream (en ~14 % en total). ¿De dónde viene esta diferencia?
En primer lugar, parte de esa reducción se debe a una genuina simplificación del código. Un buen ejemplo de esto es el agregado paralelo, que es prácticamente un reemplazo 1:1 de la implementación original de Postgres-XL. Así que lo eliminamos y usamos la implementación anterior en su lugar. Esperamos encontrar más lugares de este tipo en el futuro y utilizar la implementación anterior en lugar de mantener la nuestra.
En segundo lugar, gran parte de la reducción proviene de la eliminación del código muerto. No solo hemos reducido algunos fragmentos de código muertos o inalcanzables, también hemos descubierto bastantes archivos fuente que ni siquiera estaban compilados, y así sucesivamente.
¿Qué sigue?
En este punto, hemos fusionado los cambios hasta b5bce6c1, que es el lugar donde PostgreSQL 9.6 se separó del maestro. Entonces, para ponernos al día con PostgreSQL 9.6.2, necesitamos fusionar los cambios restantes en la rama 9.6. Teniendo en cuenta que en su mayoría solo debería haber correcciones de errores, debería ser (con suerte) un trabajo bastante simple en comparación con la fusión completa.
Por supuesto, habrá errores. De hecho, todavía hay algunas pruebas de regresión que fallan en este punto. Eso debe corregirse antes de hacer un lanzamiento oficial de XL 9.6. Y necesitamos hacer más pruebas, por lo que si está interesado en ayudar a Postgres-XL, esto sería extremadamente beneficioso.
Una molestia de la que seguimos escuchando son los paquetes, o la falta de ellos. Es posible que haya notado que los últimos paquetes disponibles son bastante antiguos y solo hay .rpm, nada más. Planeamos abordar esto y comenzar a ofrecer paquetes actualizados en múltiples sabores (por ejemplo, .rpm y .deb).
También planeamos hacer algunos cambios en la forma en que se organiza el proceso de desarrollo, para que sea más fácil contribuir y participar en el proceso de desarrollo. Ese es realmente un tema separado que no está relacionado con la rama 9.6, por lo que publicaré más detalles al respecto en unos días.