Este artículo brinda una guía paso a paso para utilizar las capacidades de Machine Learning con 2UDA. En el artículo, usaremos un ejemplo de animales para predecir si son mamíferos, aves, peces o insectos.
Versiones de software
Vamos a utilizar la versión 11.6-1 de 2UDA para implementar el modelo de aprendizaje automático. 2UDA versión 11.6-1 combina:
- PostgreSQL 11.6
- Naranja 3.23.0
Puede encontrar la última versión de 2UDA aquí.
Paso 1:Cargue el conjunto de datos de entrenamiento en PostgreSQL
El conjunto de datos de muestra que se usa para entrenar nuestro modelo está disponible en el repositorio oficial de Orange GitHub aquí.
Siga estos pasos para cargar los datos de entrenamiento en las tablas de PostgreSQL:
- Conéctese a PostgreSQL a través de psql, OmniDB o cualquier otra herramienta con la que esté familiarizado.
- Crear una tabla para almacenar nuestros datos de entrenamiento . Aquí se llama training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insertar datos de entrenamiento en la tabla a través de la consulta COPY. Antes de ejecutar la consulta COPY, asegúrese de que PostgreSQL haya requerido permisos de lectura en el archivo de datos; de lo contrario, la operación COPY fallará.
NOTA: Asegúrate de escribir una tabulación espacio entre comillas simples después del delimitador palabra clave.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Encuentre la captura de pantalla del conjunto de datos de entrenamiento a continuación
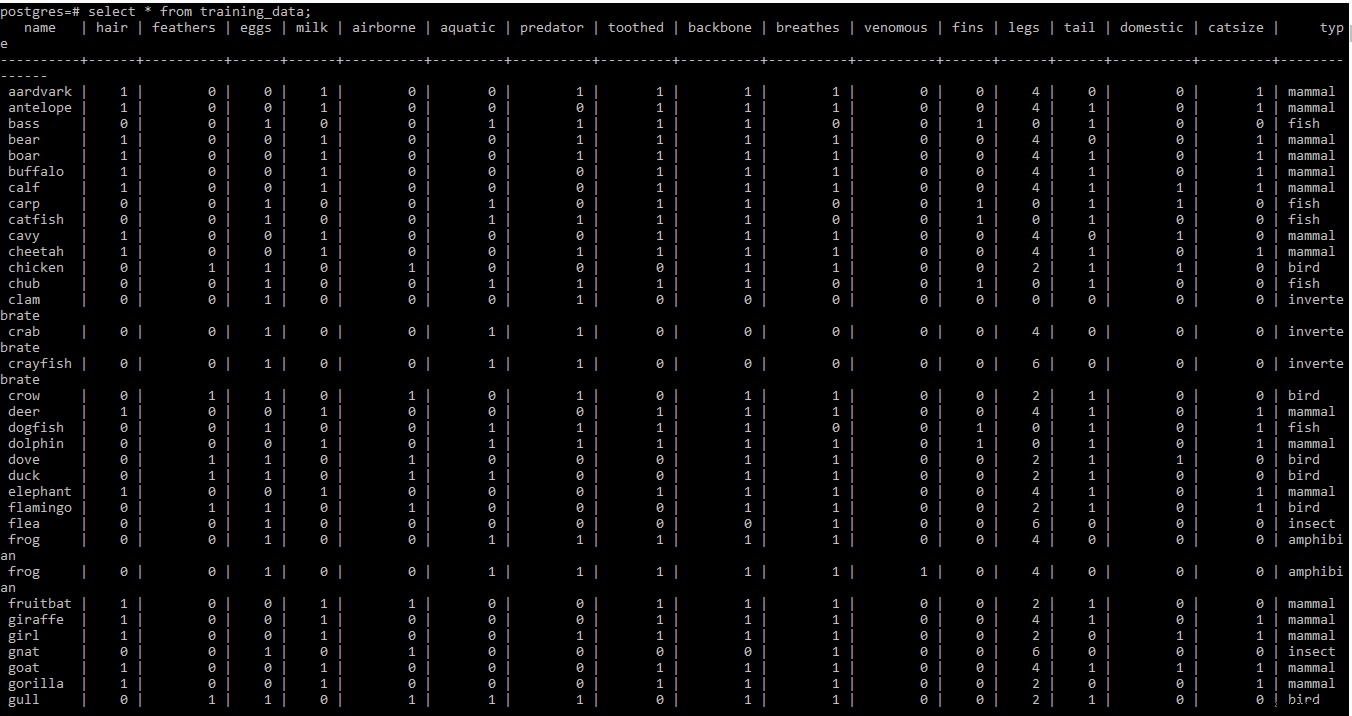
NOTA: Filas dos y tres del conjunto de datos de entrenamiento en .tab El archivo contiene algo de metainformación. Dado que no es necesario en este momento, se ha eliminado del archivo.
Paso 2:Cree un flujo de trabajo con Orange
- Vaya al escritorio y haga doble clic en el icono naranja.
- Así es como se ve la página de inicio. Seleccione Nuevo opción y creará un proyecto en blanco.

Ahora está listo para aplicar el modelo de aprendizaje automático en el conjunto de datos.
Paso 3:seleccione el modelo de aprendizaje automático para entrenar los datos
Para este artículo, k-más cercano vecinos (KNN) El modelo de aprendizaje automático se utiliza para entrenar los datos. Una vez que se completa el proceso de entrenamiento de datos, en el siguiente paso, los datos de prueba se pasan a Predicción widget para comprobar la precisión de las predicciones.
Paso 4:Importar datos de entrenamiento de PostgreSQL a Orange
Este conjunto de datos de entrenamiento se usará para entrenar el modelo de Machine Learning.
- Arrastrar y soltar Tabla SQL widget de Datos menú.
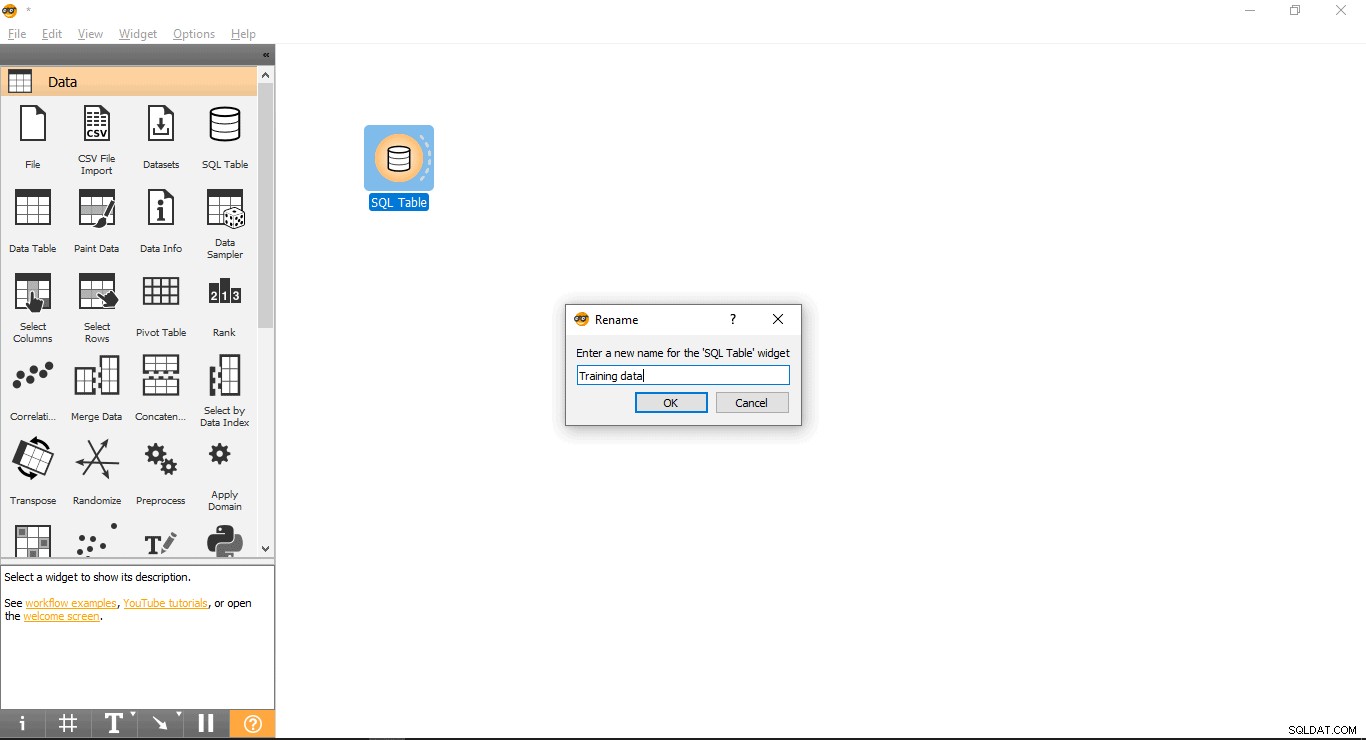
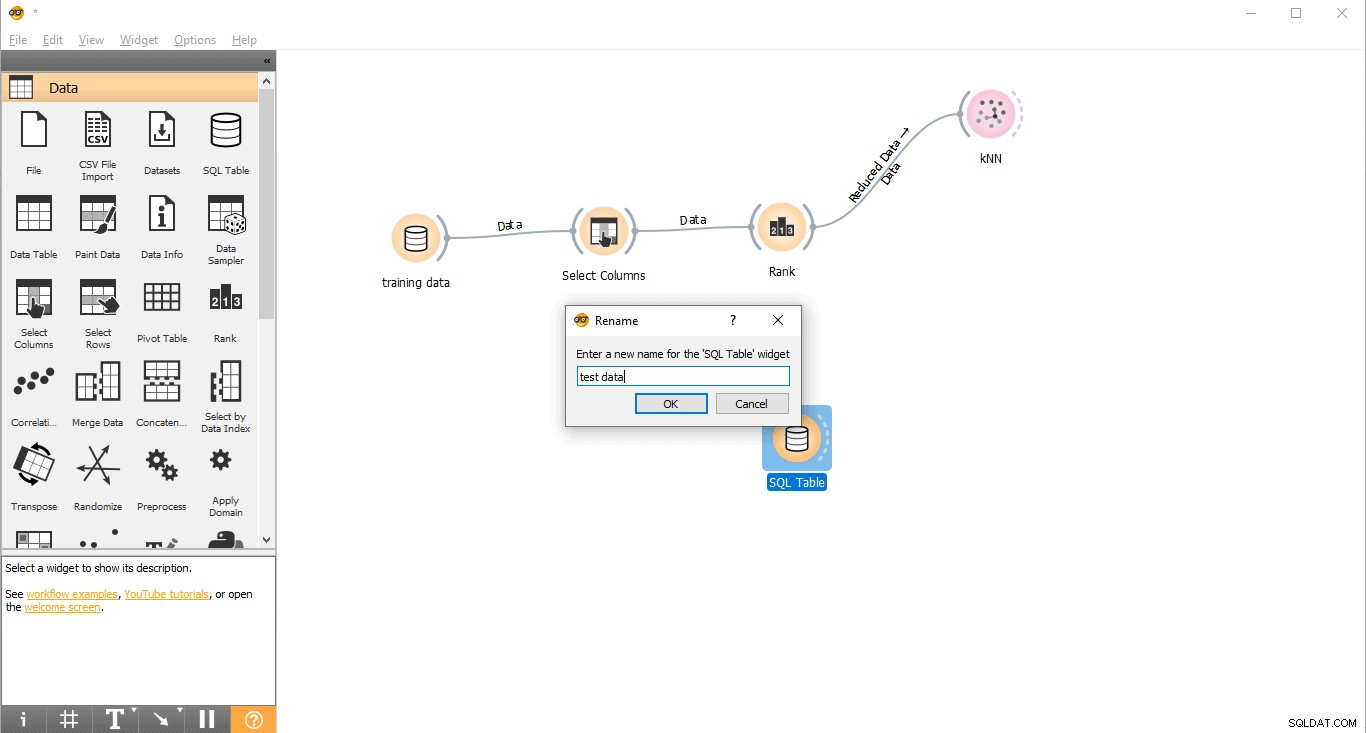
- Renombrar widget (opcional)
- Haga clic derecho en la tabla SQL widget.
- Seleccione Renombrar .
- Conéctese con PostgreSQL para cargar el conjunto de datos de entrenamiento:
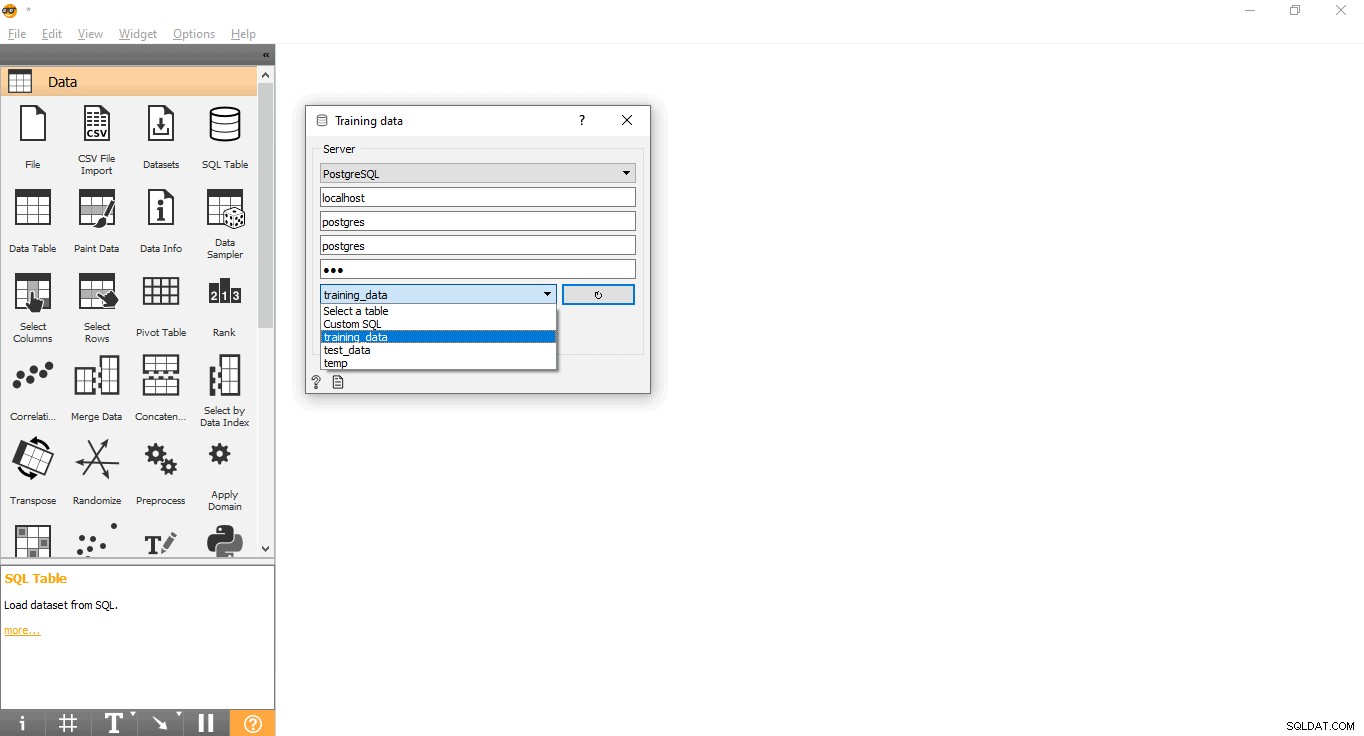
- Haz doble clic en Datos de entrenamiento widget.
- Ingrese las credenciales para conectarse a la base de datos de PostgreSQL.
- Presione el botón de recarga para cargar todas las tablas disponibles de la base de datos dada.
- Seleccione la tabla training_data del menú desplegable y cierre la ventana emergente.
Paso 5:Agregue la columna Objetivo
Este paso es importante porque el modelo de Machine Learning intentará predecir los datos para esta variable/columna de destino:
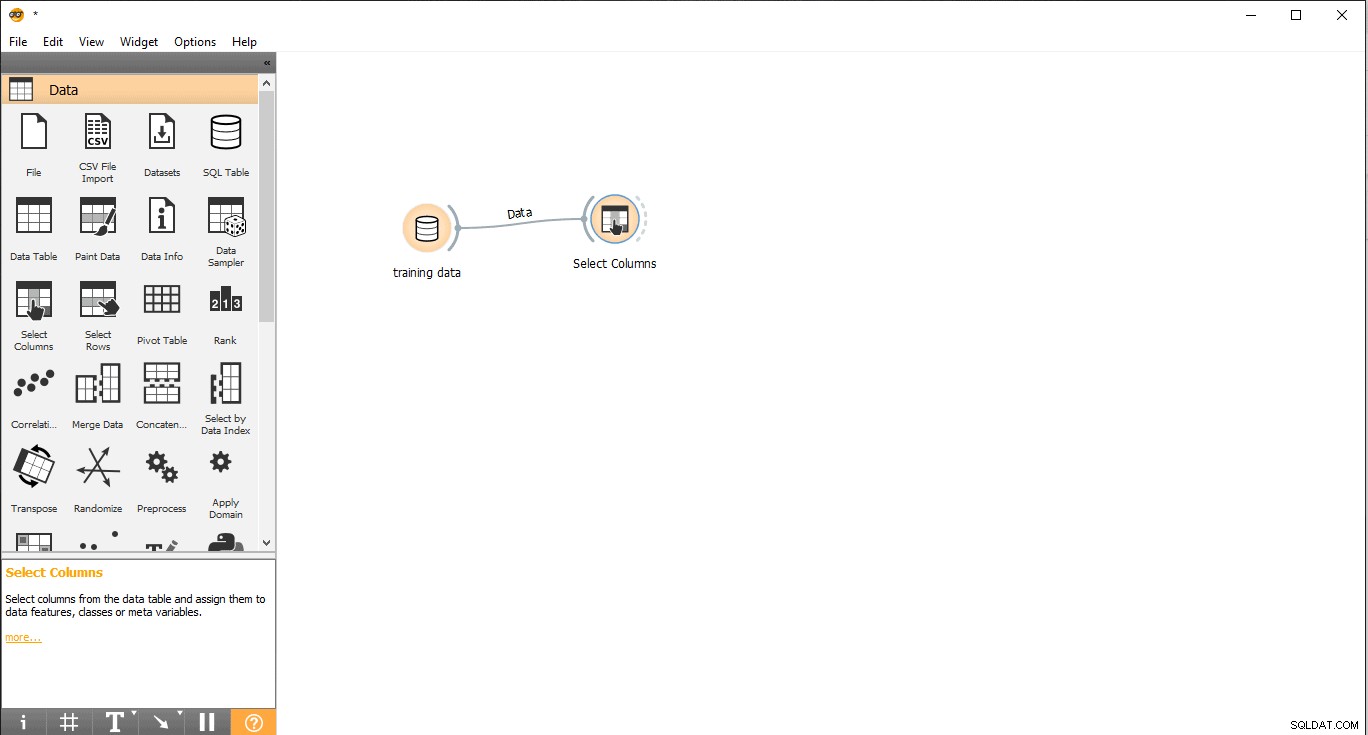
- Arrastrar y soltar Seleccionar columnas widget de los datos menú.
- Haga doble clic en Seleccionar columnas widget.
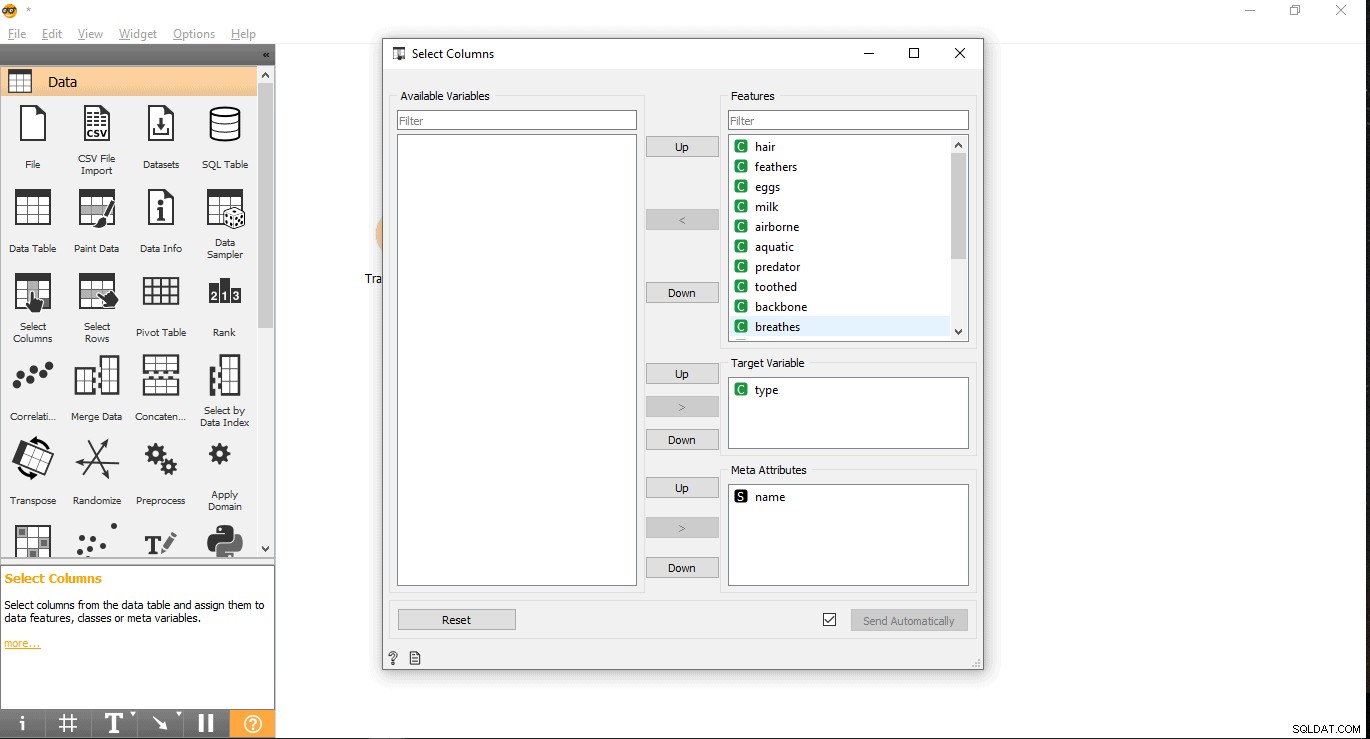
- Busque su columna de destino en la etiqueta Características. Aquí, se usa tipo como una variable de destino porque necesitamos ver de qué tipo es un animal determinado.
- Arrástrelo y suéltelo debajo de Variable objetivo cuadro y cierre la ventana emergente.
Paso 6:Clasificación de columnas
Puede Clasificar o puntuar la variable/columnas de entrenamiento según su correlación con la columna de destino.
- Arrastrar y soltar Clasificación widget de los datos menú.
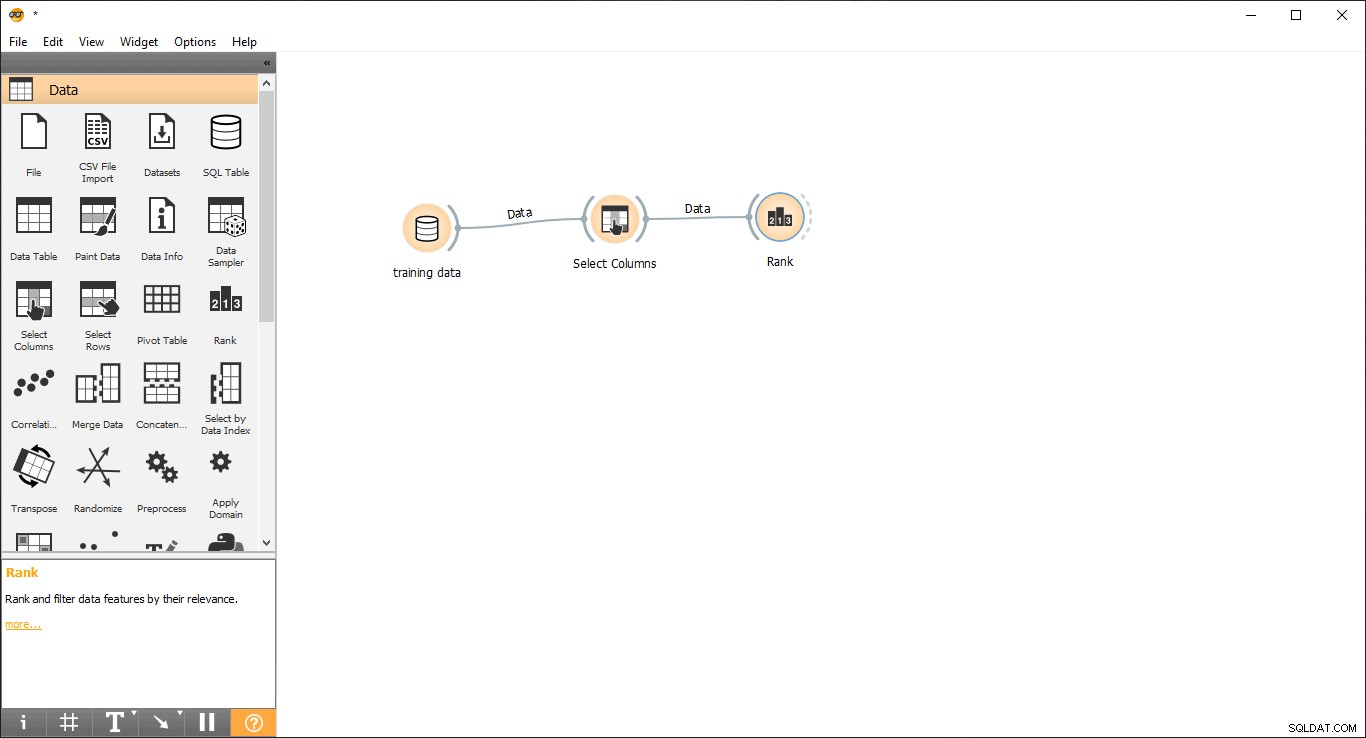
- Dibuje una línea de enlace desde Seleccionar columnas widget para clasificar aparato .
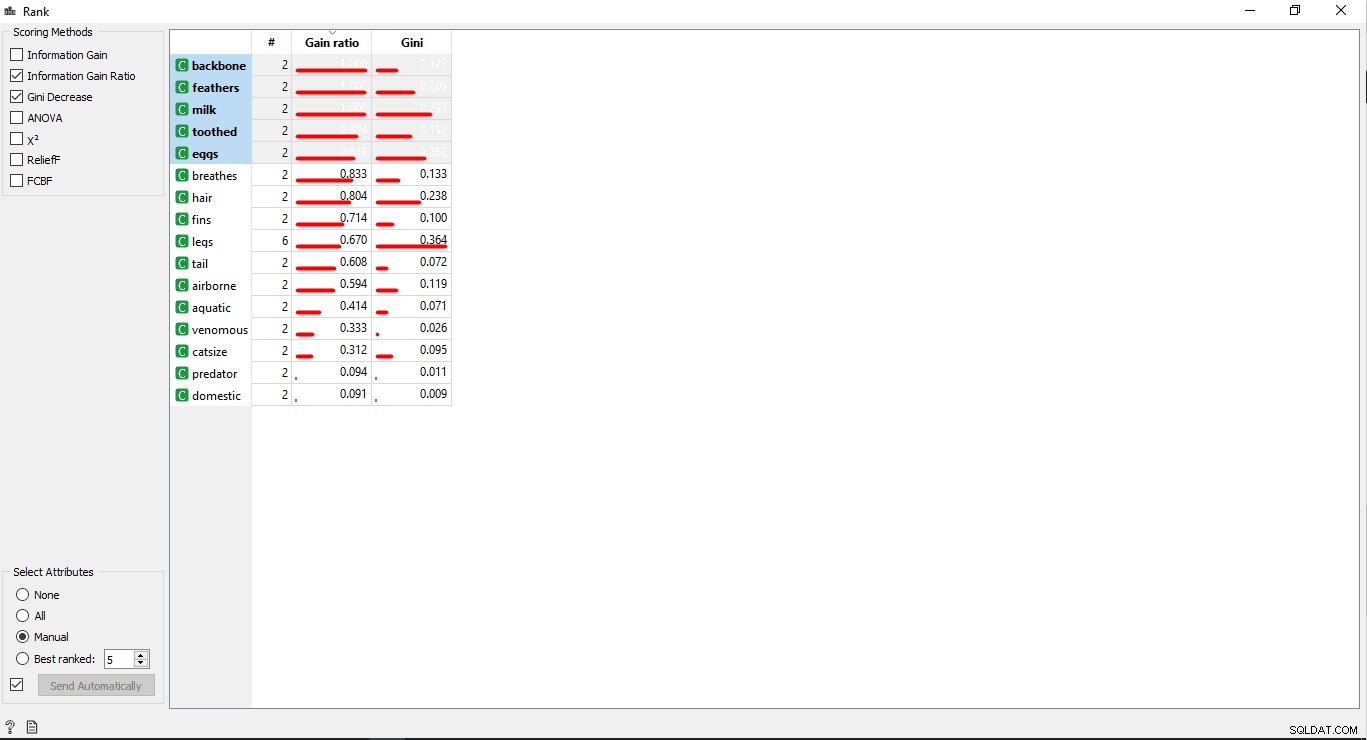
- Haga doble clic en el Clasificación widget para ver las columnas más relacionadas en la tabla de datos de entrenamiento. Seleccionará las 5 columnas principales de forma predeterminada.
Paso 7:Entrenamiento de datos
En este paso, se entrenará el modelo de aprendizaje automático (KNN) con el conjunto de datos de entrenamiento. Siga los siguientes pasos:
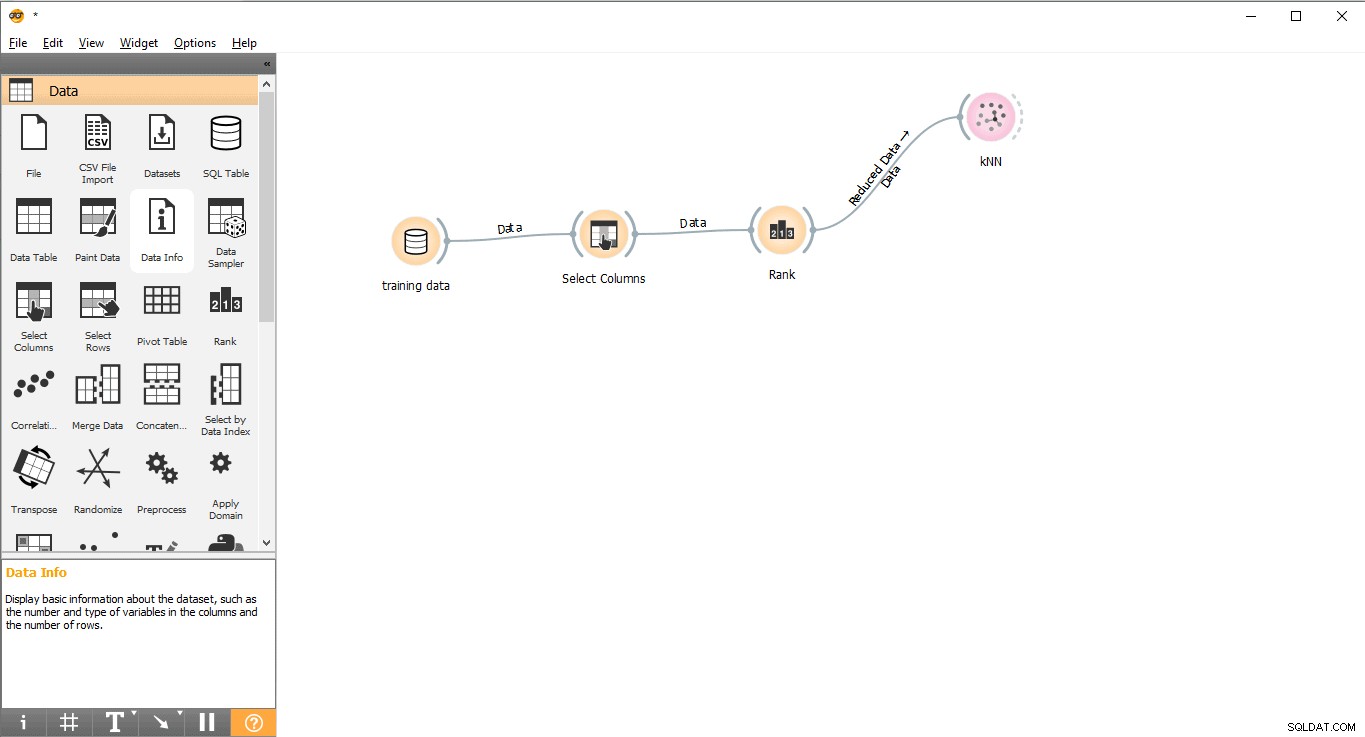
- Arrastra y suelta KNN widget del Modelo menú.
- Dibuje una línea de enlace desde Clasificación widget para KNN widget.
Paso 8:Cargue el conjunto de datos de prueba en PostgreSQL
Se crea un conjunto de datos de prueba separado para realizar predicciones. Siga los pasos para cargar el conjunto de datos de prueba en la tabla de PostgreSQL.
- Cree una tabla para almacenar nuestros datos de prueba . Aquí se nombra como test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Insertar datos de prueba en la tabla de prueba a través de COPY consulta. Antes de ejecutar COPIAR consulta, asegúrese de que PostgreSQL haya requerido permisos de lectura en el archivo de datos; de lo contrario, la operación COPY fallará.
NOTA: Asegúrate de escribir una tabulación espacio entre comillas simples después del delimitador palabra clave. Se colocó intencionalmente un signo de interrogación en el tipo columna del conjunto de datos de prueba porque necesitamos averiguar el tipo de un animal determinado con nuestro modelo de aprendizaje automático.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Encuentre la captura de pantalla del conjunto de datos de prueba a continuación

Paso 9:Importe los datos de prueba de PostgreSQL a Orange
Siga los siguientes pasos para aplicar las predicciones.
- Arrastrar y soltar Tabla SQL widget de los datos menú.
- Renombrar widget (opcional)
- Haga clic derecho en la tabla SQL widget.
- Seleccione Renombrar .
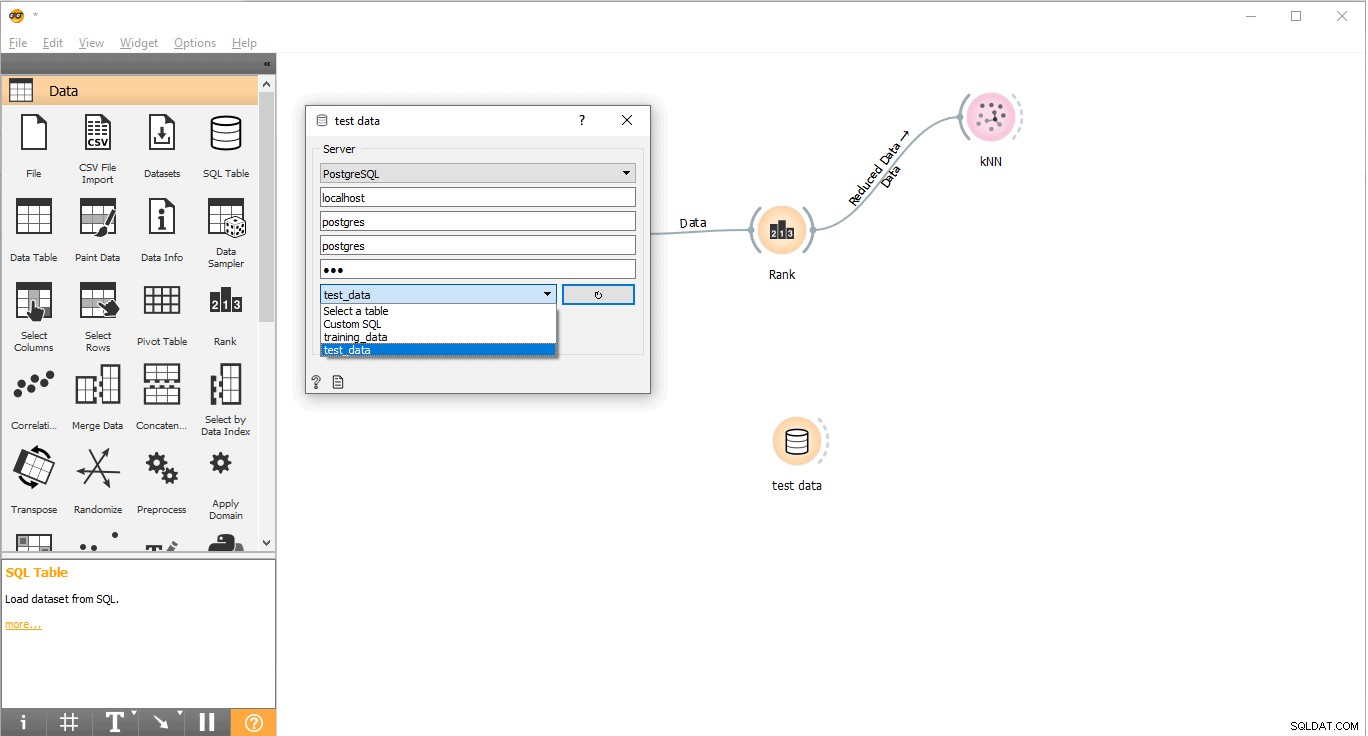
- Conéctese con PostgreSQL para cargar datos de prueba.
- Haga doble clic en Datos de prueba widget.
- Conéctelo con datos de prueba tabla de PostgreSQL.
Ahora estamos listos para realizar predicciones.
Paso 10:Predicciones
Predicción el widget intentará predecir los datos de prueba en función de los datos de entrenamiento de KNN .
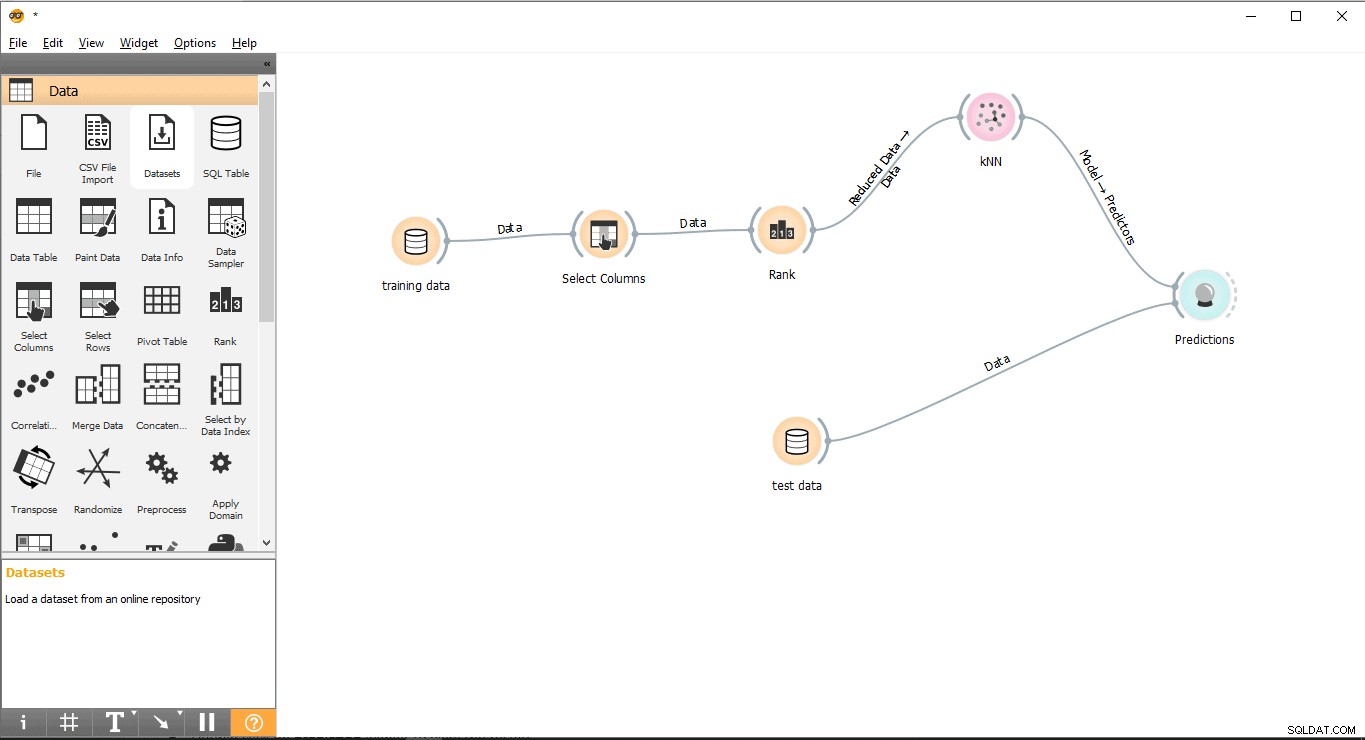
- Arrastra y suelta Predicción widget de Evaluar menú.
- Dibujar un formulario de línea de vínculo Datos de prueba widget para Predicción widget.
- Dibuje una línea de enlace desde KNN widget para Predicción widget.
Paso 11:Resultados
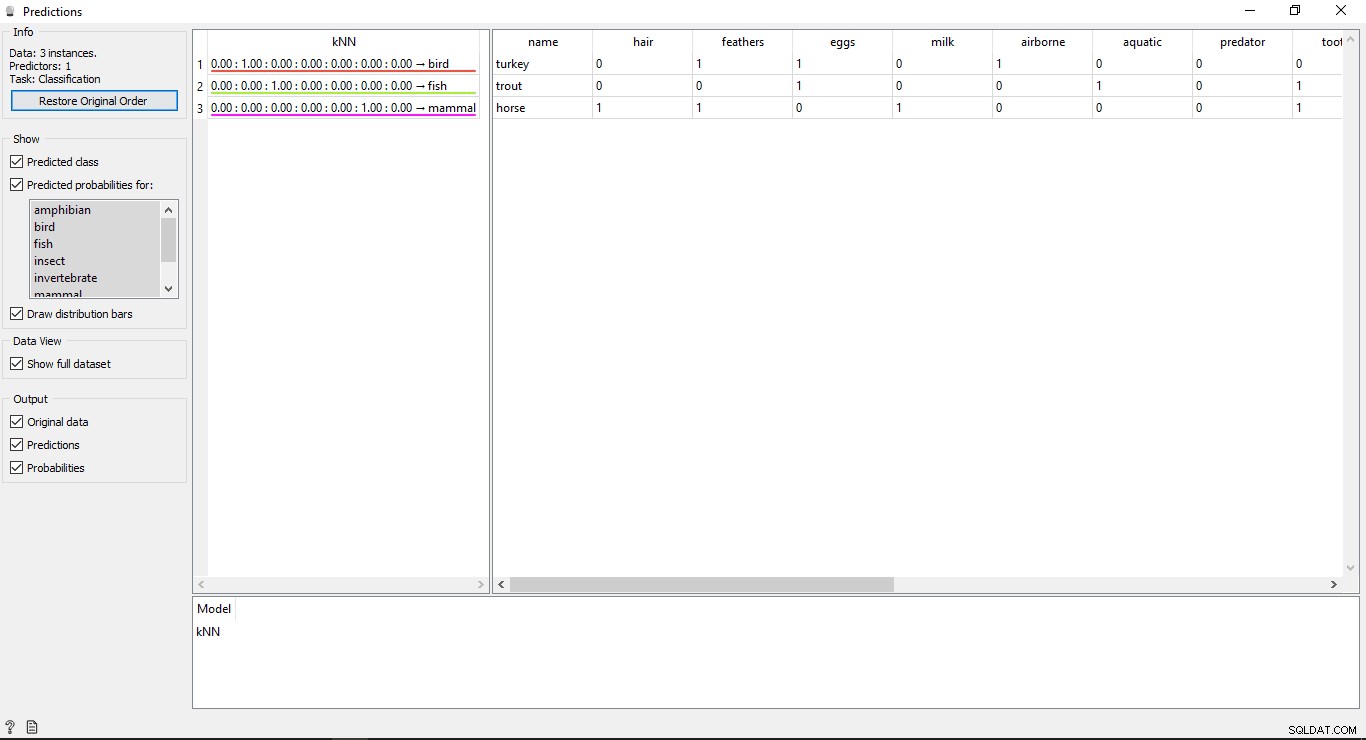
Haga doble clic en Predicción widget para ver los resultados.
Comprender los resultados
Verá 2 tablas principales en la ventana de predicción. La tabla del lado izquierdo muestra los resultados pronosticados, mientras que la tabla de la derecha muestra los datos de prueba originales, que se proporcionaron para las predicciones.
Desde la KNN el modelo se usó para entrenar los datos, por lo que verá una columna llamada KNN que enumera los resultados.
Como sabemos:
- Caballo es un mamífero
- Trucha es un pez
- Turquía es un pájaro
Entonces KNN puede determinar todos los tipos correctamente.
Precisión de las predicciones
Si ve la tabla en el lado izquierdo en la salida del widget de predicción, tiene algunos números antes del tipo de predicción, es decir, 1.00. 0.00 Estos números muestran la precisión del tipo predicho.
Hemos utilizado 7 tipos de animales en el conjunto de datos de entrenamiento, por lo que muestra un número total de 7 columnas con valores de precisión, cada columna representará 1 tipo de animal. Puede verificar qué columna representa qué tipo de animal mirando la lista disponible en el lado izquierdo de su pantalla en Probabilidades pronosticadas para etiqueta. Si observa la primera fila que dice Turquía es un pájaro . Podemos ver Su precisión es 1.00 (100% de la 2ª columna). Lo mismo ocurre con otros ejemplos Trucha es un pez y su precisión es 1.00 (100 % de la 3.ª columna).
En este artículo, hemos utilizado el algoritmo de k vecinos más cercanos (KNN) para implementar el modelo de aprendizaje automático. En el próximo blog, usaremos la Máquina de vectores de soporte (SVM) modelo.
Para cualquier pregunta o comentario, póngase en contacto utilizando el formulario de contacto aquí.