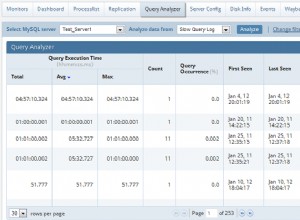
Su consulta lenta está eliminando TOAST los datos jsonb grandes para las 44255 filas y luego lleva los valores analizados a través de la ordenación para seleccionar las 20 filas principales. (No sé por qué hace el DESTOSTADO tan ansiosamente). Así que 44235 JSONB fueron deTOASTADOS solo para tirarlos.
Su consulta rápida (presumiblemente) está devolviendo punteros TOAST de la unión hash, ordenando las filas con esos pequeños punteros y luego eliminando TOAST solo los 20 sobrevivientes. En el caso de EXPLAIN ANALYZE, ni siquiera elimina el TOSTADO de los sobrevivientes, simplemente descarta los indicadores.
Ese es el "por qué", en cuanto a qué hacer al respecto, si realmente no puede modificar ninguna de las consultas debajo de la parte superior, dudo que haya algo que pueda hacer al respecto en el lado del servidor.
Si puede modificar la consulta de manera más sustancial, entonces puede mejorar el tiempo de ejecución con un CTE. Haga que el CTE seleccione todo el jsonb, y luego la selección en el CTE extrae el valor de él.
WITH T as (select cfiles.property_values as "1907", <rest of query>)
SELECT "1907"->>'name1', "1907"->>'name2', <rest of select list> from T;