Bueno, analizar la propagación del coronavirus SARS-CoV-2 no era el caso de uso de mis sueños . Pero basándome en las respuestas al artículo Seguimiento del coronavirus COVID-19 casi en tiempo real con SAP HANA XSA de Ferry Djaja, decidí agregar mis dos groszy también.
[Actualizado el 20-03-30 con los enlaces modificados a los datos de origen; y la nueva salida del mapa basada en la nueva granularidad de los datos. ¡Gracias Douglas Maltby por tu comentario!]
En su publicación de blog, Ferry usó JavaScript en SAP HANA XSA para extraer los datos de los archivos CSV actualizados diariamente por la Universidad Johns Hopkins.
Me gustaría mostrarle cómo puede extraer y cargar estos archivos en SAP HANA usando solo unas pocas líneas de código gracias a SAP HANA Python Client API for Machine Learning (hana_ml paquete).
Algunas personas estaban confundidas con la visualización en el mapa al final; tenga en cuenta que este artículo se enfoca en el caso de uso técnico que conecta diferentes componentes, no en hacer un análisis profundo de datos de coronavirus.
Obtener el entorno de Python, p. ej. Jupyter
Usaré Jupyter en el contenedor Docker para eso. Eche un vistazo a mi publicación anterior Comprender los contenedores (parte 05):archivos compartidos entre el host y los contenedores si no está familiarizado con cómo iniciarlo. También puede realizar los mismos pasos a continuación desde cualquier otro entorno de Python.
Entonces, tengo mi contenedor myjupyter01 corriendo. Estoy conectado a la interfaz de usuario de Jupyter como se describe en el blog anterior.
Instalar hana_ml
La imagen de Jupyter que usé del registro de Docker Hub fue jupyter/minimal-notebook . Ya contiene algunos paquetes de procesamiento de datos populares, como pandas .
Pero además, necesito instalar hana_ml , que, en su versión actual 1.0.8, está disponible en el repositorio de PyPI:https://pypi.org/project/hana-ml/.
El comando para ejecutar la instalación es python -m pip install hana_ml , pero debido a que lo estoy ejecutando desde Jupyter Notebook con kernel Python3, necesito ejecutarlo con ! al principio:
!python -m pip install hana_ml
Obviamente, este paso de instalación debe realizarse una sola vez. No es necesario volver a ejecutarlo en el mismo contenedor, p. al recargar los archivos más nuevos.
Usar pandas para importar archivos con datos
Importemos los mismos tres archivos (confirmed , deaths , recovered ) de https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series como Ferry usó en su ejemplo.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
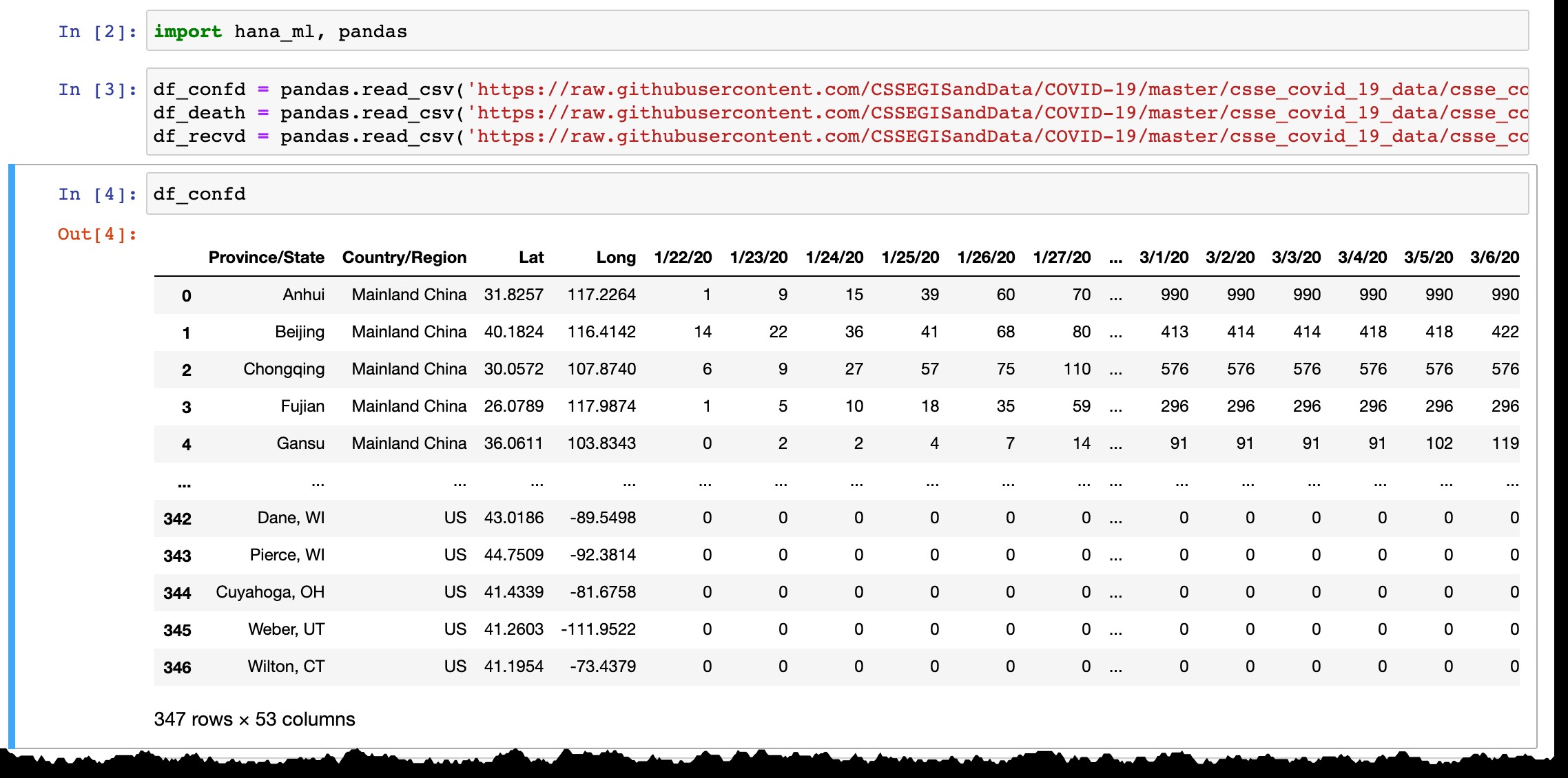
Como puede ver en la vista previa del marco de datos de Pandas, enumera solo países o provincias con casos confirmados, y todos los días se agrega una nueva columna con los últimos datos del día anterior. Las líneas se agregan cuando se confirman los primeros casos en la nueva región.
Usar pandas para volver a formatear el marco de datos
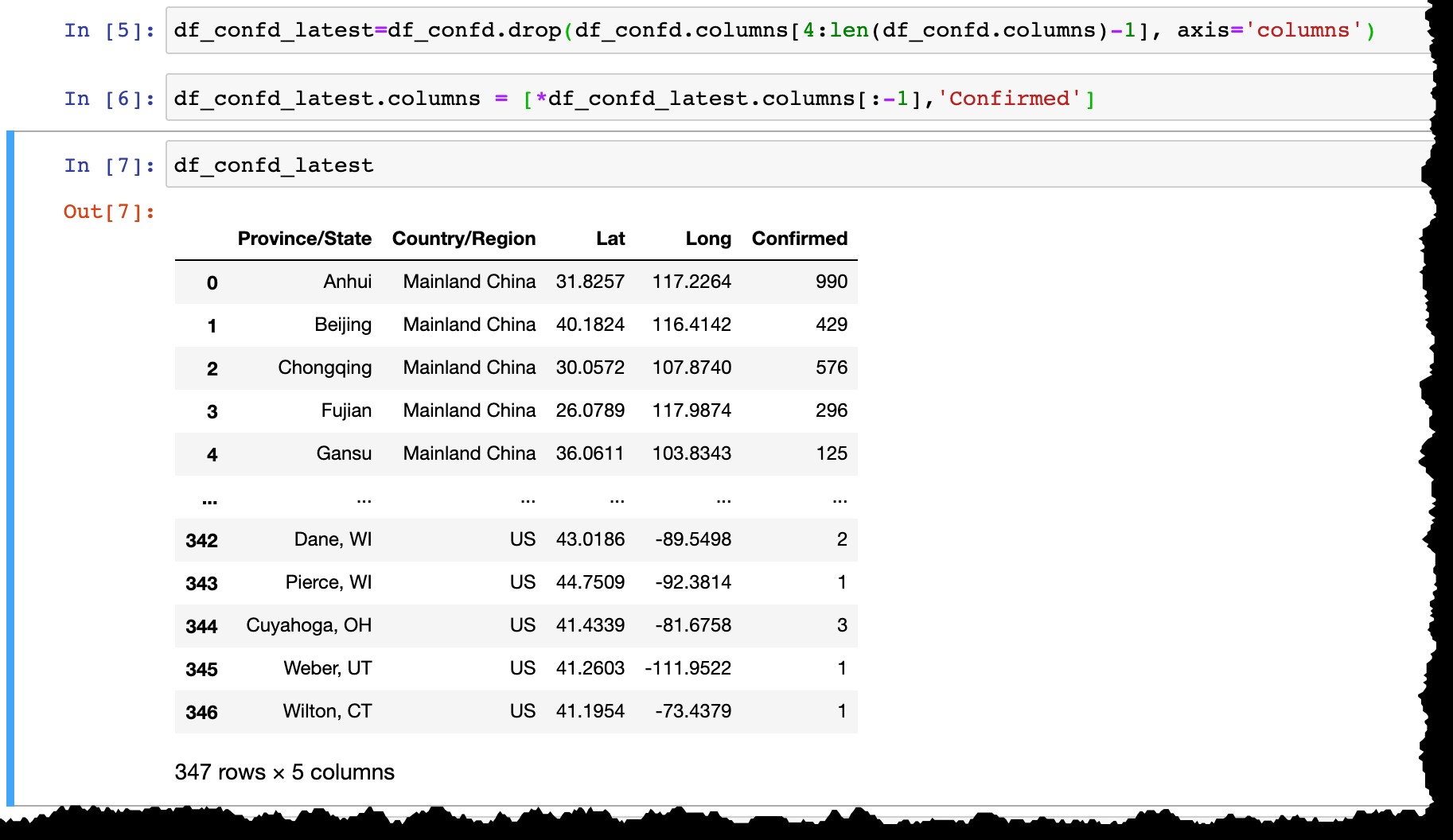
Antes de persistir los datos en SAP HANA, hagamos lo siguiente:
- Eliminar todas las columnas de fecha excepto la última,
- Cambie el nombre de la última columna de la fecha real (como el
3/10/20de hoy aConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Usar hana_ml para conservar los datos en la tabla de SAP HANA
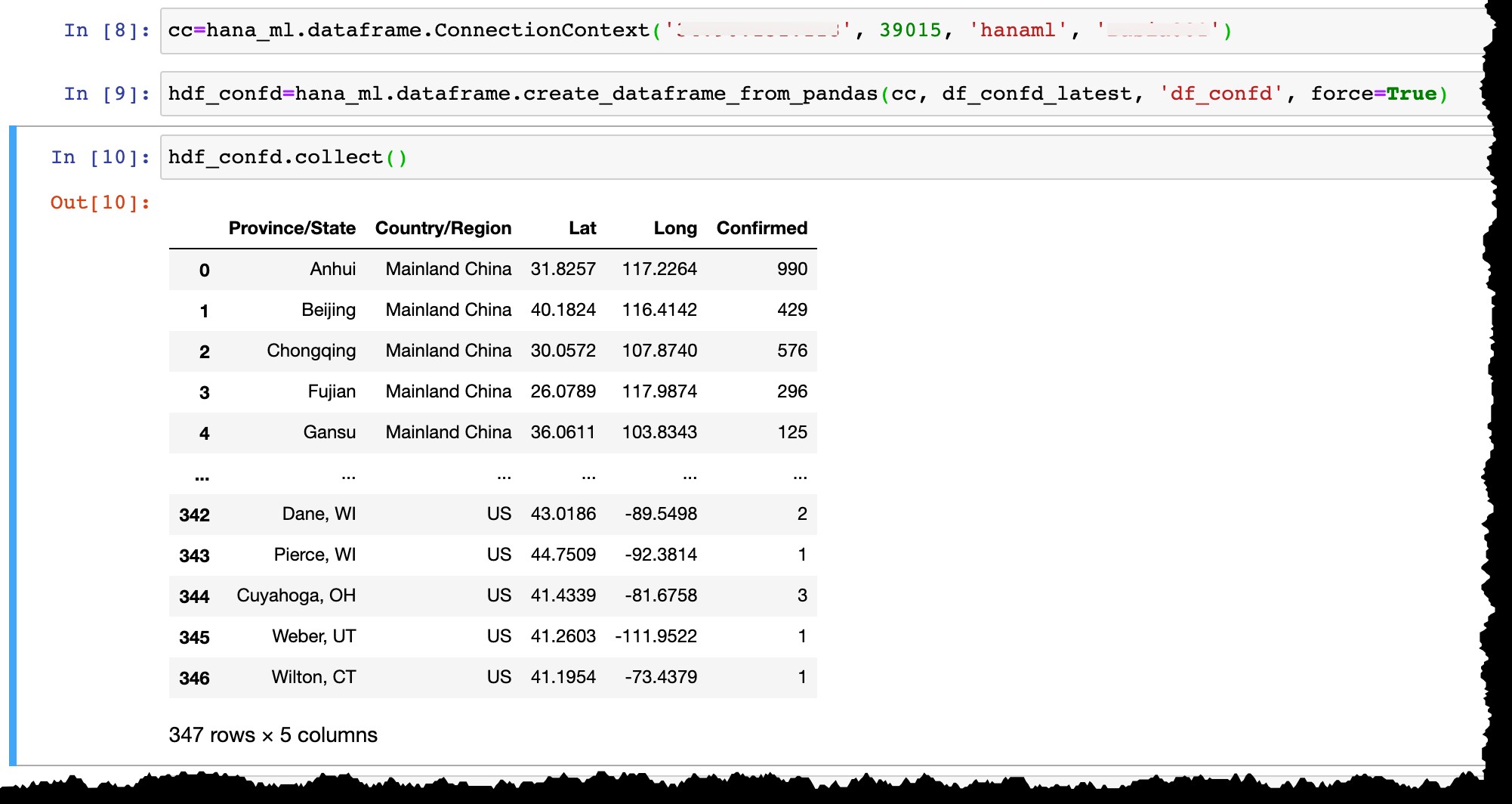
Ahora déjame conectarme a mi instancia de SAP HANA Express con el usuario hanaml eso ya existe ahí…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…y convertir el dataframe de Pandas df_confd_latest en un marco de datos HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Una vez que se crea el marco de datos de HANA:
- Se crea una tabla de columnas físicas en HANA y allí se insertan los datos del marco de datos de Pandas,
- Marco de datos HANA
hdf_confden Python no almacena ningún dato en su computadora portátil, sino que solo apunta a una tablaHANAML.df_confden la memoria del servidor de SAP HANA, y todas las operaciones de Python en el marco de datos de HANA se ejecutan físicamente en la base de datos de HANA sin mover datos entre el servidor y un cliente, - Para mostrar el resultado de cualquier operación, necesitamos aplicar
collect()método para convertir el marco de datos de HANA a Pandas (y, como resultado, traer datos del servidor de base de datos de HANA al cliente local).
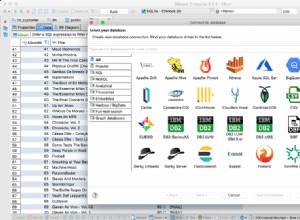
Utilice DBeaver para verificar datos en SAP HANA...
Es posible que me recuerde usando DBeaver, la herramienta de base de datos gratuita compatible con SAP HANA, en mi publicación anterior "GeoArt con SAP HANA y DBeaver".
Lo estoy usando ahora de nuevo y, de hecho, puedo encontrar la tabla df_confd en el esquema HANAML con todos los datos del marco de datos de Pandas de origen.
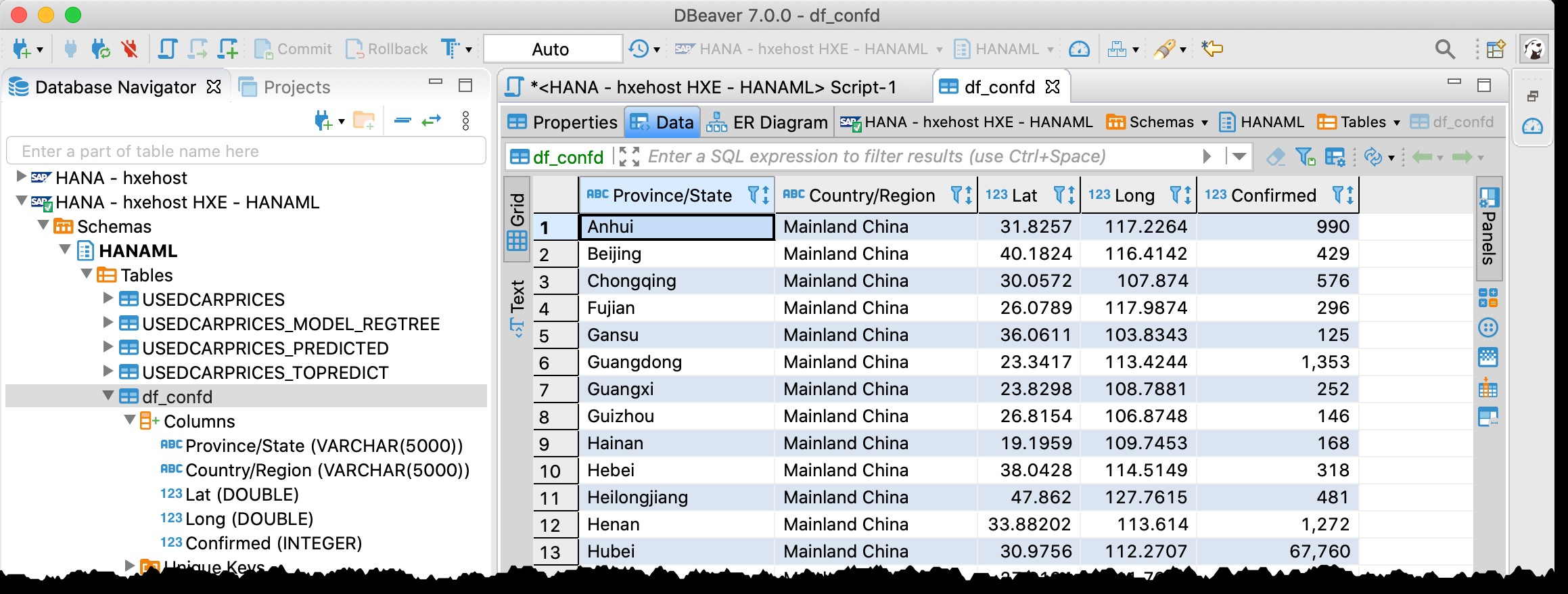
... y haz una vista previa espacial
Como la tabla contiene columnas de latitud y longitud, puedo visualizar los países/estados afectados directamente desde DBeaver con el siguiente SQL usando la vista previa de datos espaciales.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Necesitaba cambiar la proyección del mapa a EPSG:4326 para obtener estos puntos en el mapa. Y DBeaver me muestra el resto de los datos del registro cuando hago clic en cualquier punto.
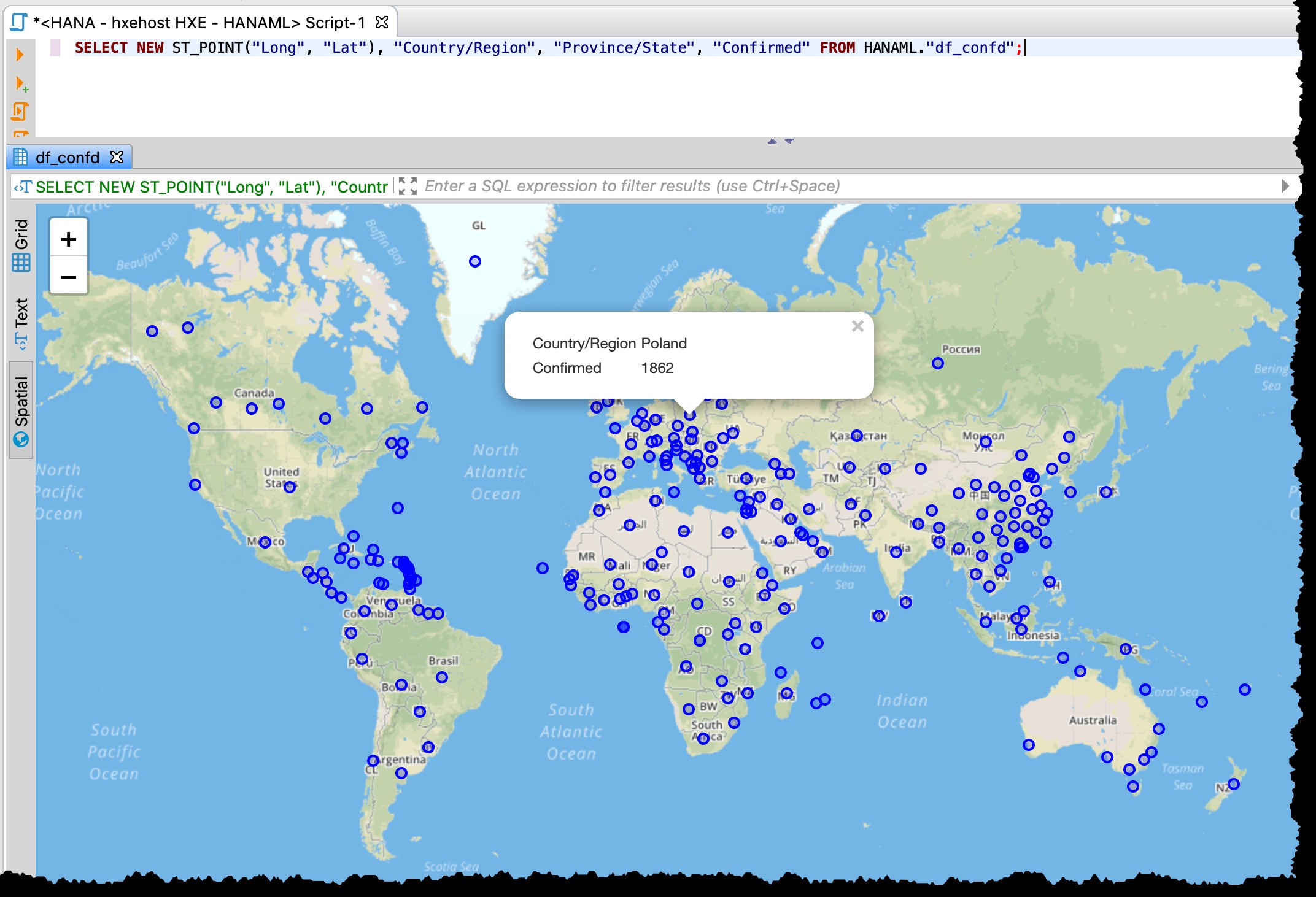
[Abajo es la captura de pantalla anterior del 11 de marzo de 2020, que también demuestra la granularidad diferente de, p. Datos de EE. UU. utilizados en ese momento]
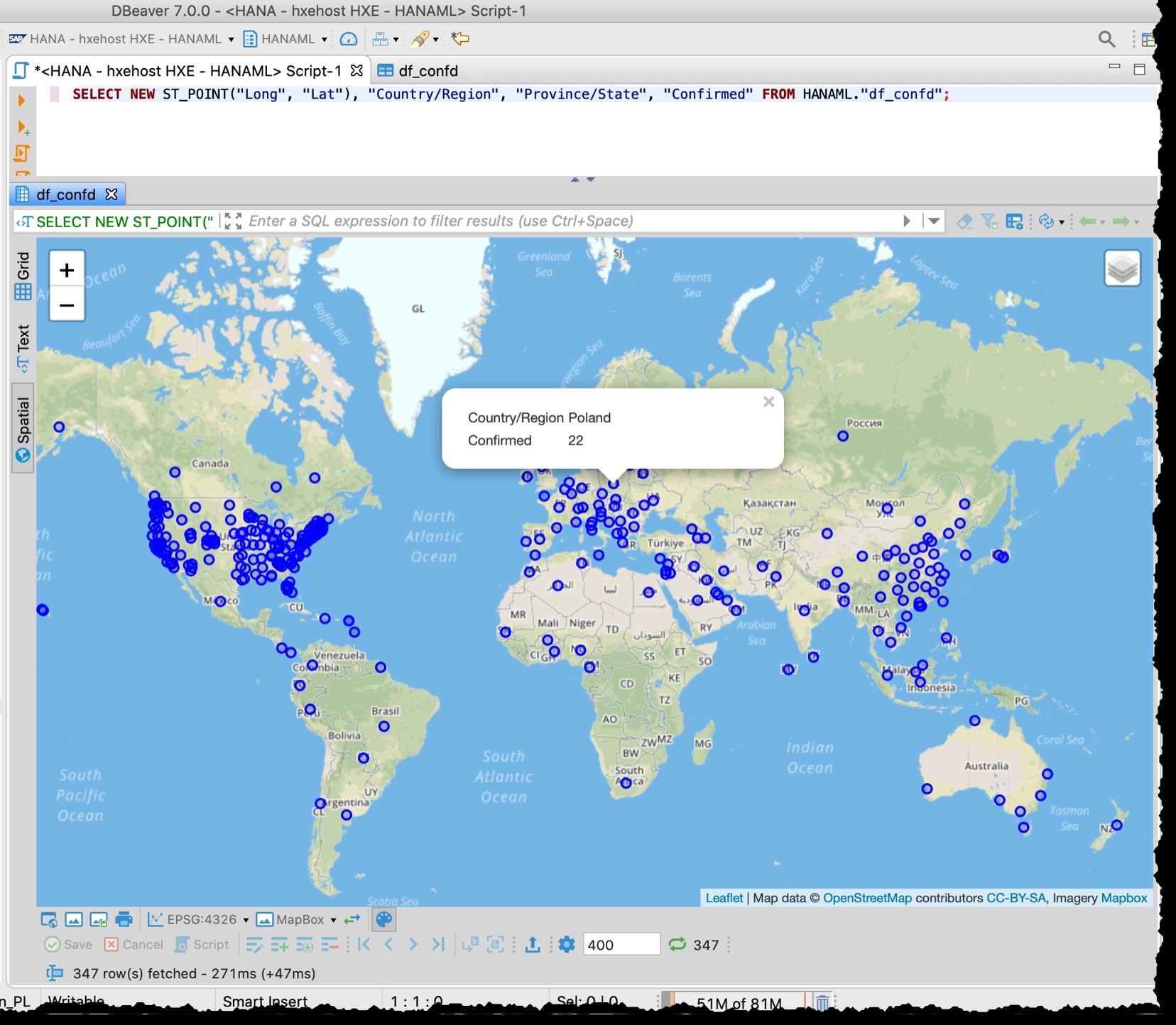
La vista previa espacial de DBeaver no es una herramienta de exploración visual geoespacial completa. Sin embargo, es lo suficientemente bueno para ver los países/regiones afectados (según la granularidad de los archivos de origen).
Si le interesa obtener más información sobre hana_ml …
… entonces definitivamente recomendaría consultar el Tutorial práctico:Aplicación de aprendizaje automático a SAP HANA con Python de Andreas Forster.
HANA ML es parte del nuevo tema "Análisis avanzado con SAP HANA" para eventos de CodeJam. Desafortunadamente, debido a la situación del coronavirus, tuvimos que cancelar el primero organizado por Jakob Flaman en Berna este mes. Otro está organizado por Ewelina Pękała el 27 de mayo en Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Con suerte, la situación se normalizará para entonces, y no tendremos que cancelar este también.