ClusterControl 1.6 viene con una integración más estrecha con AWS, Azure y Google Cloud, por lo que ahora es posible lanzar nuevas instancias e implementar MySQL, MariaDB, MongoDB y PostgreSQL directamente desde la interfaz de usuario de ClusterControl. En este blog, le mostraremos cómo implementar un clúster en Amazon Web Services.
Tenga en cuenta que esta nueva característica requiere dos módulos llamados clustercontrol-cloud y clustercontrol-clud . El primero es un demonio auxiliar que amplía la capacidad de CMON de comunicación en la nube, mientras que el segundo es un cliente administrador de archivos para cargar y descargar archivos en instancias de la nube. Ambos paquetes son dependencias del paquete de interfaz de usuario de clustercontrol, que se instalará automáticamente si no existen. Consulte la página de documentación de componentes para obtener más información.
Credenciales en la nube
ClusterControl le permite almacenar y administrar sus credenciales de nube en Integraciones (menú lateral) -> Proveedores de nube:
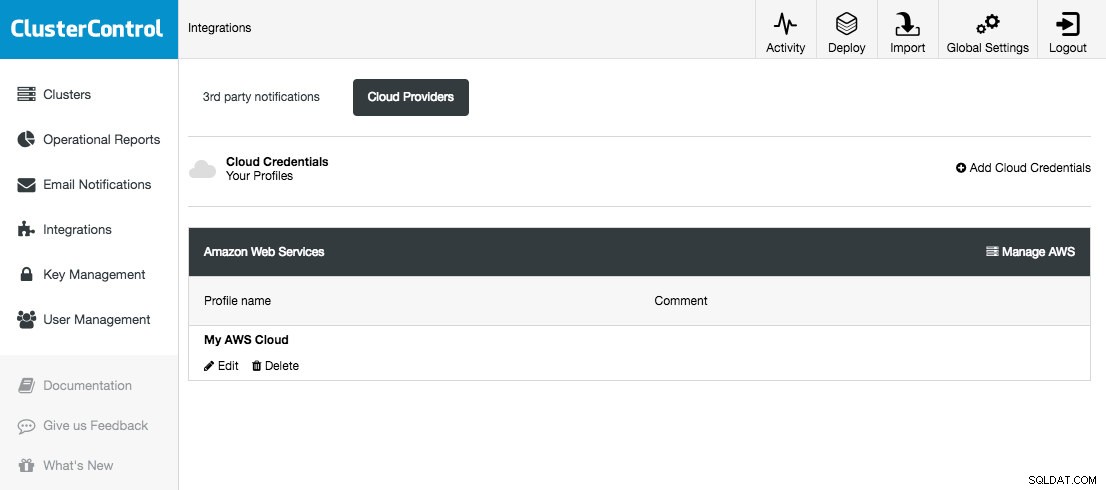
Las plataformas en la nube admitidas en esta versión son Amazon Web Services, Google Cloud Platform y Microsoft Azure. En esta página, puede agregar nuevas credenciales en la nube, administrar las existentes y también conectarse a su plataforma en la nube para administrar recursos.
Las credenciales que se han configurado aquí se pueden utilizar para:
- Administrar recursos en la nube
- Implementar bases de datos en la nube
- Subir copia de seguridad al almacenamiento en la nube
Lo siguiente es lo que vería si hiciera clic en el botón "Administrar AWS":
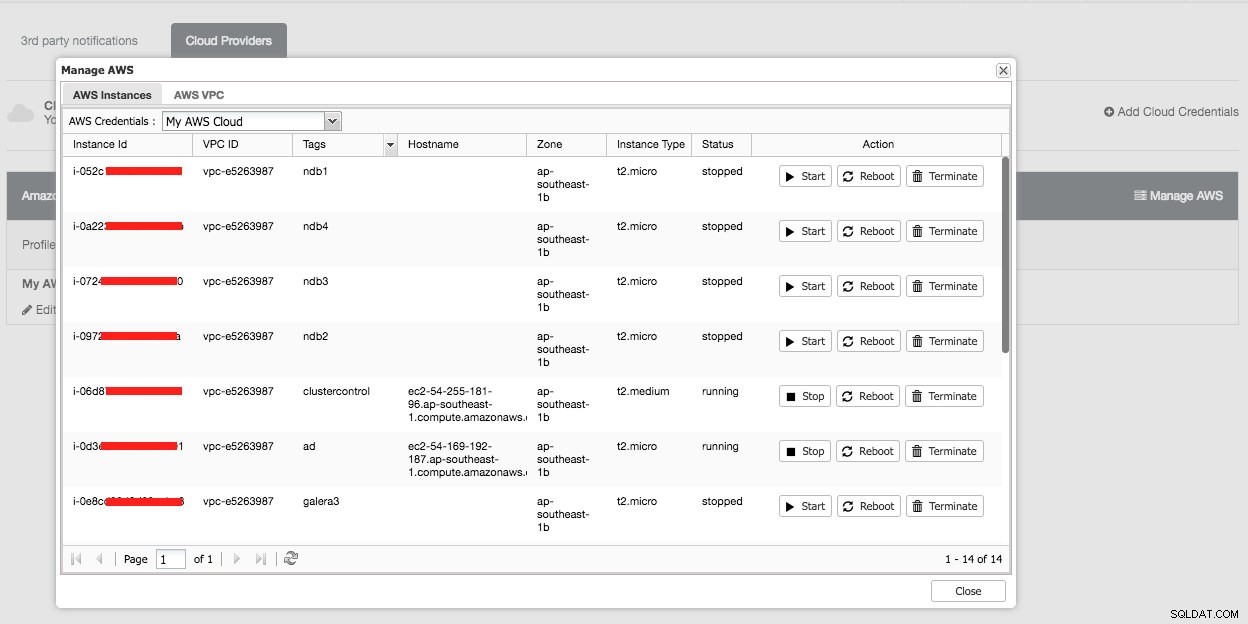
Puede realizar tareas de administración simples en sus instancias en la nube. También puede verificar la configuración de VPC en la pestaña "AWS VPC", como se muestra en la siguiente captura de pantalla:
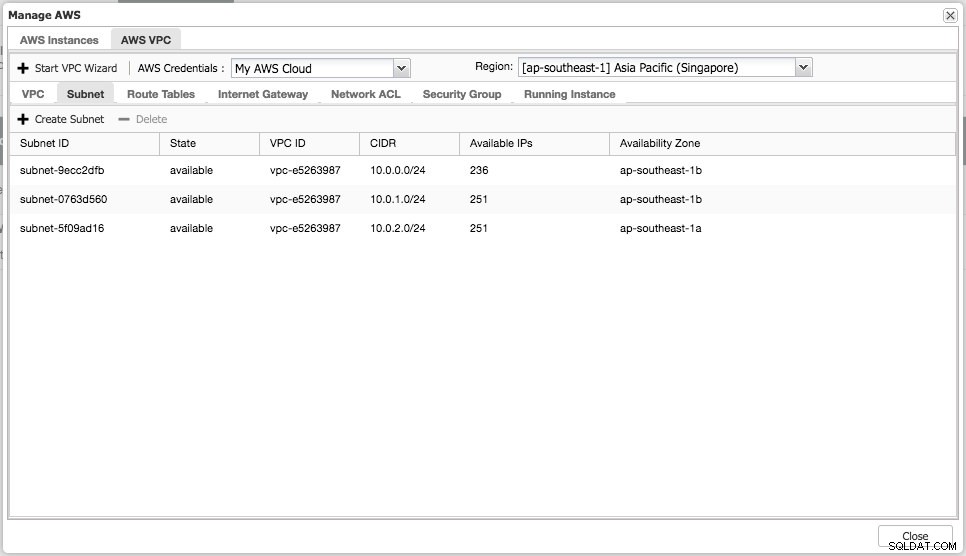
Las funciones anteriores son útiles como referencia, especialmente al preparar sus instancias en la nube antes de iniciar las implementaciones de la base de datos.
Despliegue de base de datos en la nube
En versiones anteriores de ClusterControl, la implementación de la base de datos en la nube se trataba de manera similar a la implementación en hosts estándar, donde tenía que crear las instancias de la nube de antemano y luego proporcionar los detalles y las credenciales de la instancia en el asistente "Implementar clúster de base de datos". El procedimiento de implementación desconocía cualquier funcionalidad adicional y flexibilidad en el entorno de la nube, como IP dinámica y asignación de nombre de host, dirección IP pública NAT-ed, elasticidad de almacenamiento, configuración de red de nube privada virtual, etc.
Con la versión 1.6, solo necesita proporcionar las credenciales de la nube, que se pueden administrar a través de la interfaz "Proveedores de la nube" y seguir el asistente de implementación "Implementar en la nube". Desde la interfaz de usuario de ClusterControl, haga clic en Implementar y se le presentarán las siguientes opciones:
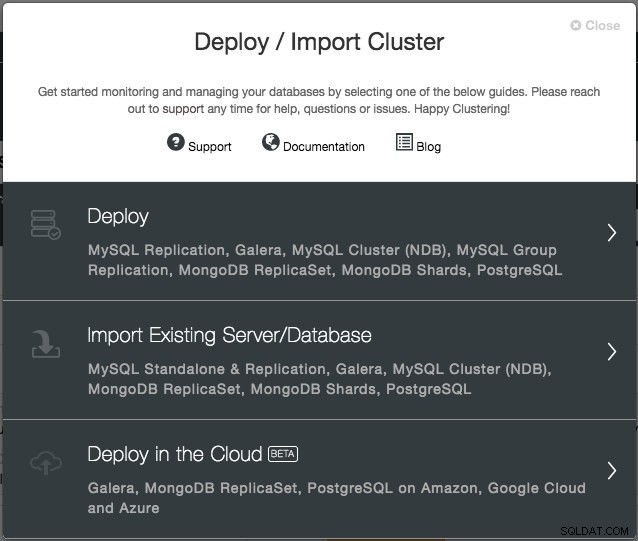
Por el momento, los proveedores de nube admitidos son los tres grandes:Amazon Web Service (AWS), Google Cloud y Microsoft Azure. Vamos a integrar más proveedores en la versión futura.
En la primera página, se le presentarán las opciones de Detalles del clúster:
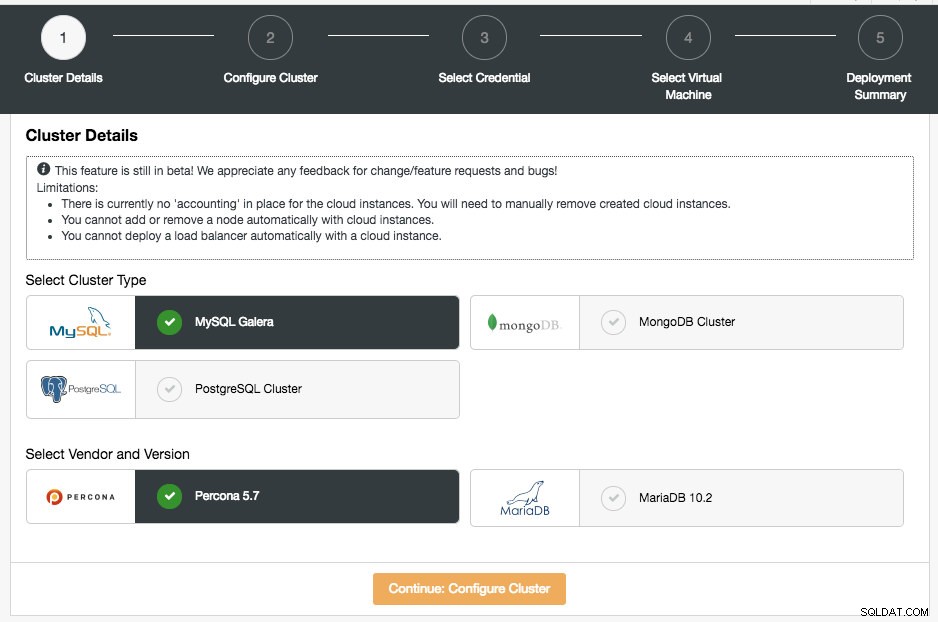
En esta sección, deberá seleccionar el tipo de clúster compatible, MySQL Galera Cluster, MongoDB Replica Set o PostgreSQL Streaming Replication. El siguiente paso es elegir el proveedor admitido para el tipo de clúster seleccionado. Por el momento, se admiten los siguientes proveedores y versiones:
- Clúster MySQL Galera - Clúster Percona XtraDB 5.7, MariaDB 10.2
- MongoDB Cluster:MongoDB 3.4 de MongoDB, Inc y Percona Server para MongoDB 3.4 de Percona (solo conjunto de réplicas).
- Clúster de PostgreSQL:PostgreSQL 10.0 (solo replicación de transmisión).
En el siguiente paso, se le presentará el siguiente cuadro de diálogo:
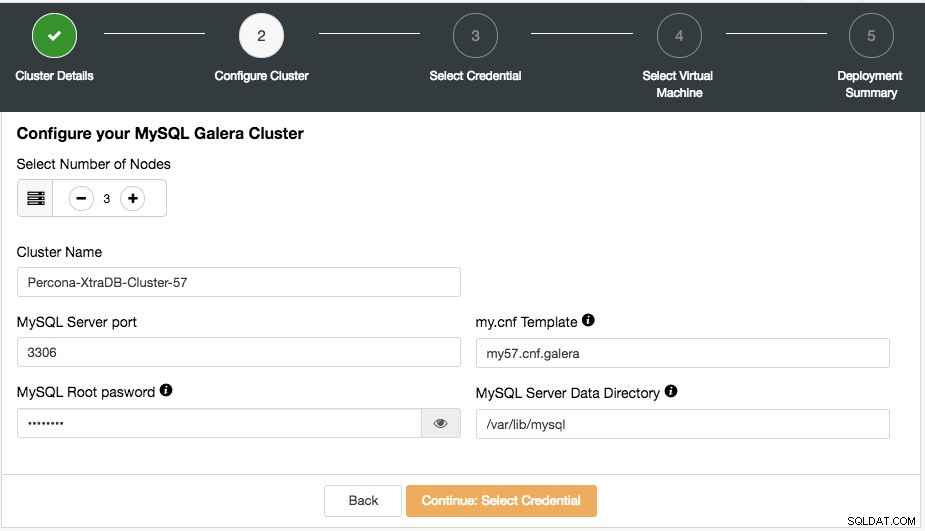
Aquí puede configurar el tipo de clúster seleccionado en consecuencia. Elija el número de nodos. El nombre del clúster se usará como la etiqueta de la instancia, por lo que puede reconocer fácilmente esta implementación en el panel de control de su proveedor de nube. No se permiten espacios en el nombre del clúster. My.cnf Template es el archivo de configuración de la plantilla que utilizará ClusterControl para implementar el clúster. Debe estar ubicado en /usr/share/cmon/templates en el host de ClusterControl. El resto de los campos se explican por sí mismos.
El siguiente cuadro de diálogo es para seleccionar las credenciales de la nube:
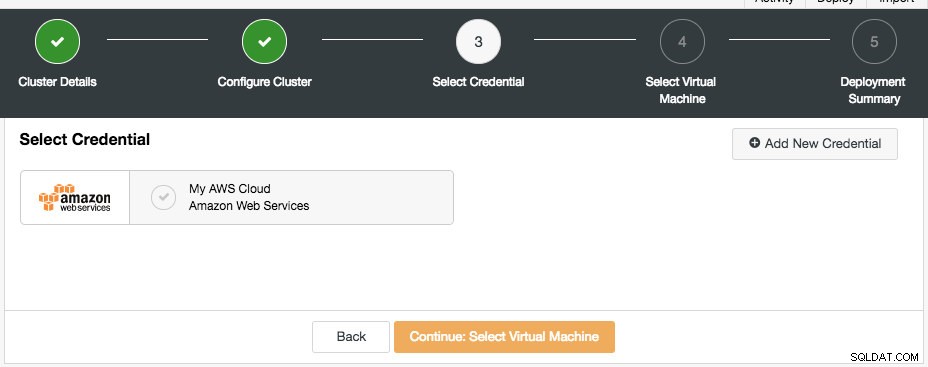
Puede elegir las credenciales de nube existentes o crear una nueva haciendo clic en el botón "Agregar nueva credencial". El siguiente paso es elegir la configuración de la máquina virtual:
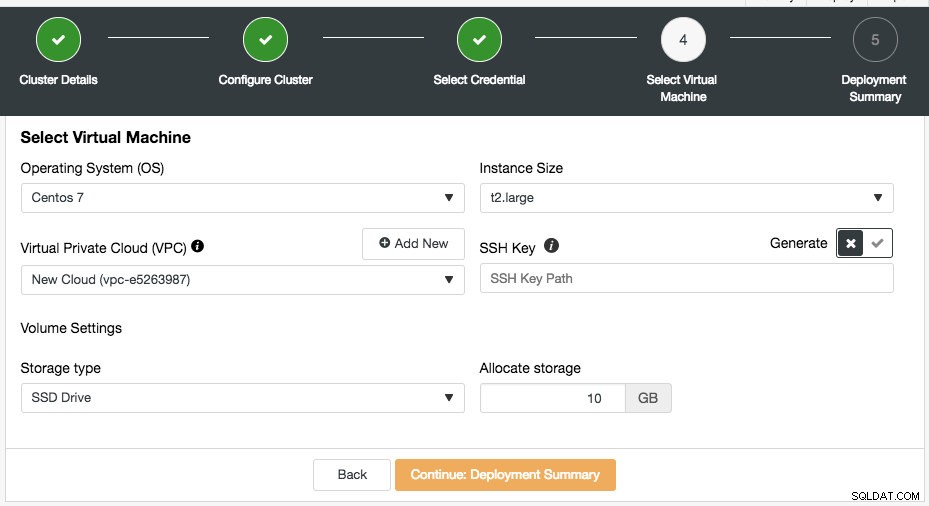
La mayoría de las configuraciones en este paso se completan dinámicamente desde el proveedor de la nube mediante las credenciales elegidas. Puede configurar el sistema operativo, el tamaño de la instancia, la configuración de VPC, el tipo y el tamaño de almacenamiento y también especificar la ubicación de la clave SSH en el host de ClusterControl. También puede dejar que ClusterControl genere una nueva clave específicamente para estas instancias. Al hacer clic en el botón "Agregar nuevo" junto a Virtual Private Cloud, se le presentará un formulario para crear una nueva VPC:
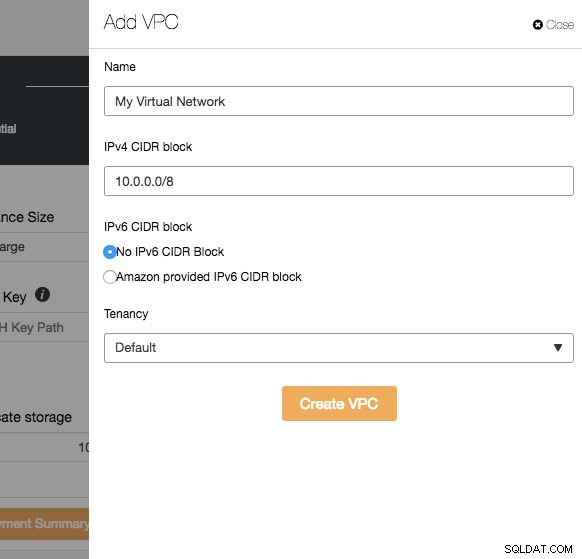
VPC es una infraestructura de red lógica que tiene dentro de su plataforma en la nube. Puede configurar su VPC modificando su rango de direcciones IP, crear subredes, configurar tablas de rutas, puertas de enlace de red y configuraciones de seguridad. Se recomienda implementar la infraestructura de su base de datos en esta red para el aislamiento, la seguridad y el control de enrutamiento.
Al crear una nueva VPC, especifique el nombre de la VPC y el bloque de direcciones IPv4 con la subred. Luego, elija si IPv6 debe ser parte de la red y la opción de tenencia. Luego puede usar esta red virtual para su infraestructura de base de datos.
El último paso es el resumen de implementación:
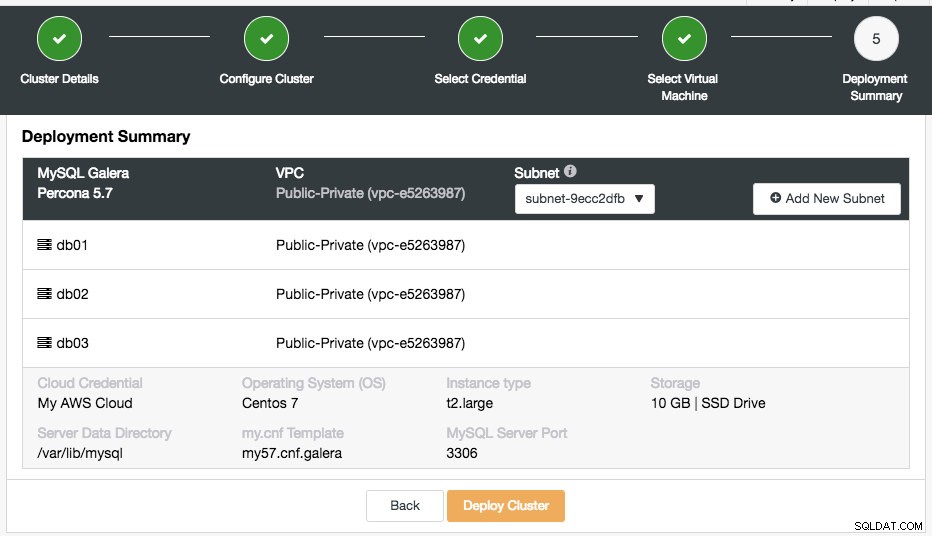
En esta etapa, debe elegir en qué subred de la red virtual elegida desea que se ejecute la base de datos. Tenga en cuenta que la subred elegida DEBE tener habilitada la dirección IPv4 pública de asignación automática. También puede crear una nueva subred en esta VPC haciendo clic en el botón "Agregar nueva subred". Verifique si todo es correcto y presione el botón "Implementar clúster" para iniciar la implementación.
Luego puede monitorear el progreso haciendo clic en Actividad -> Trabajos -> Crear grupo -> Detalles completos del trabajo:
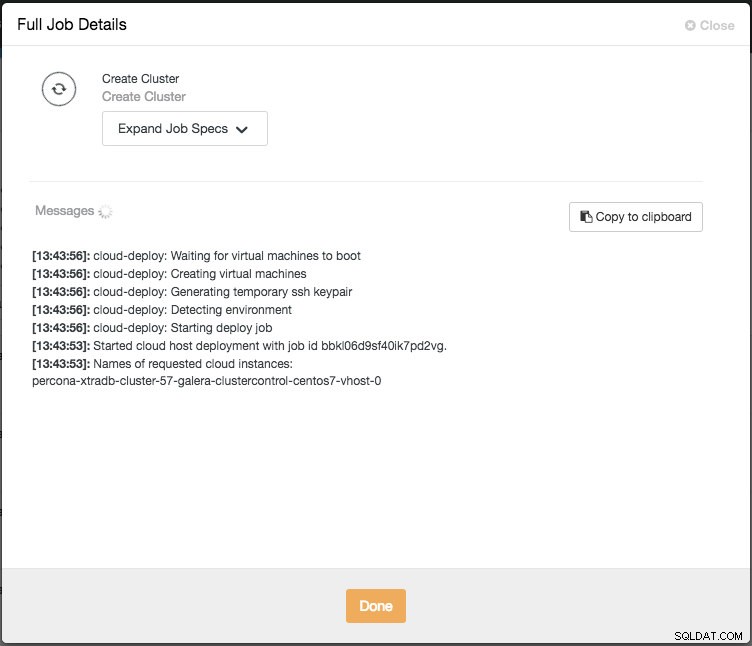
Según las conexiones, puede tardar de 10 a 20 minutos en completarse. Una vez hecho esto, verá un nuevo clúster de base de datos en el panel de control de ClusterControl. Para el clúster de replicación de transmisión de PostgreSQL, es posible que necesite conocer las direcciones IP maestra y esclava una vez que se complete la implementación. Simplemente vaya a la pestaña Nodos y verá las direcciones IP públicas y privadas en la lista de nodos a la izquierda:
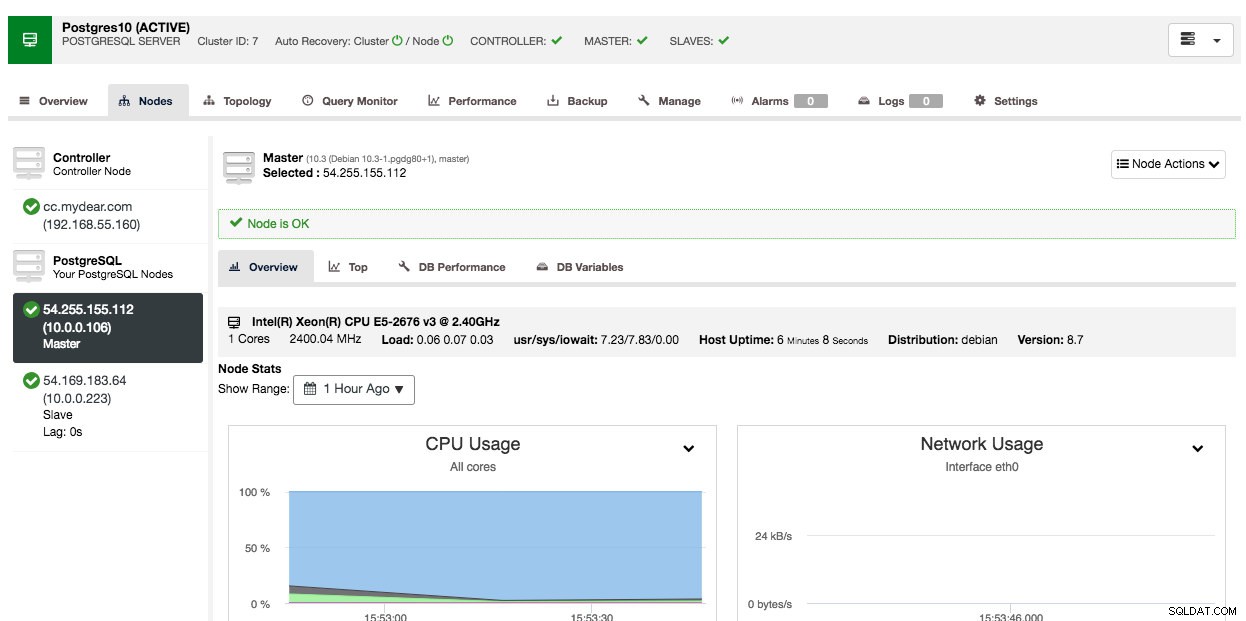
Su clúster de base de datos ahora está implementado y ejecutándose en AWS.
Por el momento, la ampliación funciona de manera similar al host estándar, donde debe crear una instancia de nube manualmente de antemano y especificar el host en ClusterControl -> seleccione el clúster -> Agregar nodo.
Debajo del capó, el proceso de implementación hace lo siguiente:
- Crear instancias en la nube
- Configurar grupos de seguridad y redes
- Verificar la conectividad SSH desde ClusterControl a todas las instancias creadas
- Implementar base de datos en cada instancia
- Configurar los enlaces de agrupación o replicación
- Registre la implementación en ClusterControl
Tenga en cuenta que esta función aún está en versión beta. No obstante, puede utilizar esta característica para acelerar su entorno de desarrollo y pruebas al controlar y administrar el clúster de la base de datos en diferentes proveedores de la nube desde una única interfaz de usuario.
Copia de seguridad de la base de datos en la nube
Esta función existe desde ClusterControl 1.5.0 y ahora agregamos soporte para Azure Cloud Storage. Esto significa que ahora puede cargar y descargar la copia de seguridad creada en los tres principales proveedores de nube (AWS, GCP y Azure). El proceso de carga ocurre justo después de que se crea correctamente la copia de seguridad (si activa "Cargar copia de seguridad en la nube") o puede hacer clic manualmente en el botón del icono de la nube de la lista de copias de seguridad:
A continuación, puede descargar y restaurar copias de seguridad desde la nube, en caso de que haya perdido su almacenamiento de copia de seguridad local o si necesita reducir el uso de espacio en disco local para sus copias de seguridad.
Limitaciones de corriente
Existen algunas limitaciones conocidas para la función de implementación en la nube, como se indica a continuación:
- Actualmente no existe una 'contabilidad' para las instancias en la nube. Deberá eliminar manualmente las instancias de la nube si elimina un clúster de base de datos.
- No puede agregar o eliminar un nodo automáticamente con instancias en la nube.
- No puede implementar un balanceador de carga automáticamente con una instancia en la nube.
Hemos probado exhaustivamente la función en muchos entornos y configuraciones, pero siempre hay casos de esquina que podríamos haber pasado por alto. Para obtener más información, consulte el registro de cambios.
¡Feliz agrupamiento en la nube!



