SCUMM (Severalnines ClusterControl Unified Monitoring &Management) es una solución basada en agentes con agentes instalados en los nodos de la base de datos. Proporciona un conjunto de paneles de control que tienen a Prometheus como almacén de datos con su lenguaje de consulta elástico y su modelo de datos multidimensional. Prometheus extrae datos de métricas de los exportadores que se ejecutan en los hosts de la base de datos.
La arquitectura ClusterControl SCUMM se introdujo con la versión 1.7.0 que amplía la funcionalidad de monitoreo para MySQL, Galera Cluster, PostgreSQL y ProxySQL.
El nuevo ClusterControl 1.7.1 agrega monitoreo de alta resolución para sistemas MongoDB.
 Lista del panel de control de ClusterControl MongoDB
Lista del panel de control de ClusterControl MongoDB En este artículo, describiremos los dos paneles principales para entornos MongoDB. MongoDB Server y MongoDB Replicaset.
Panel de control y lista de métricas
La lista de paneles y sus métricas:
| Servidor MongoDB | |
|---|---|
| Name ReplSet Name Server Uptime OpsCounters Connections WT - Tickets simultáneos (lectura) WT - Tickets simultáneos (escritura) WT - Caché Bloqueo global Afirmaciones |
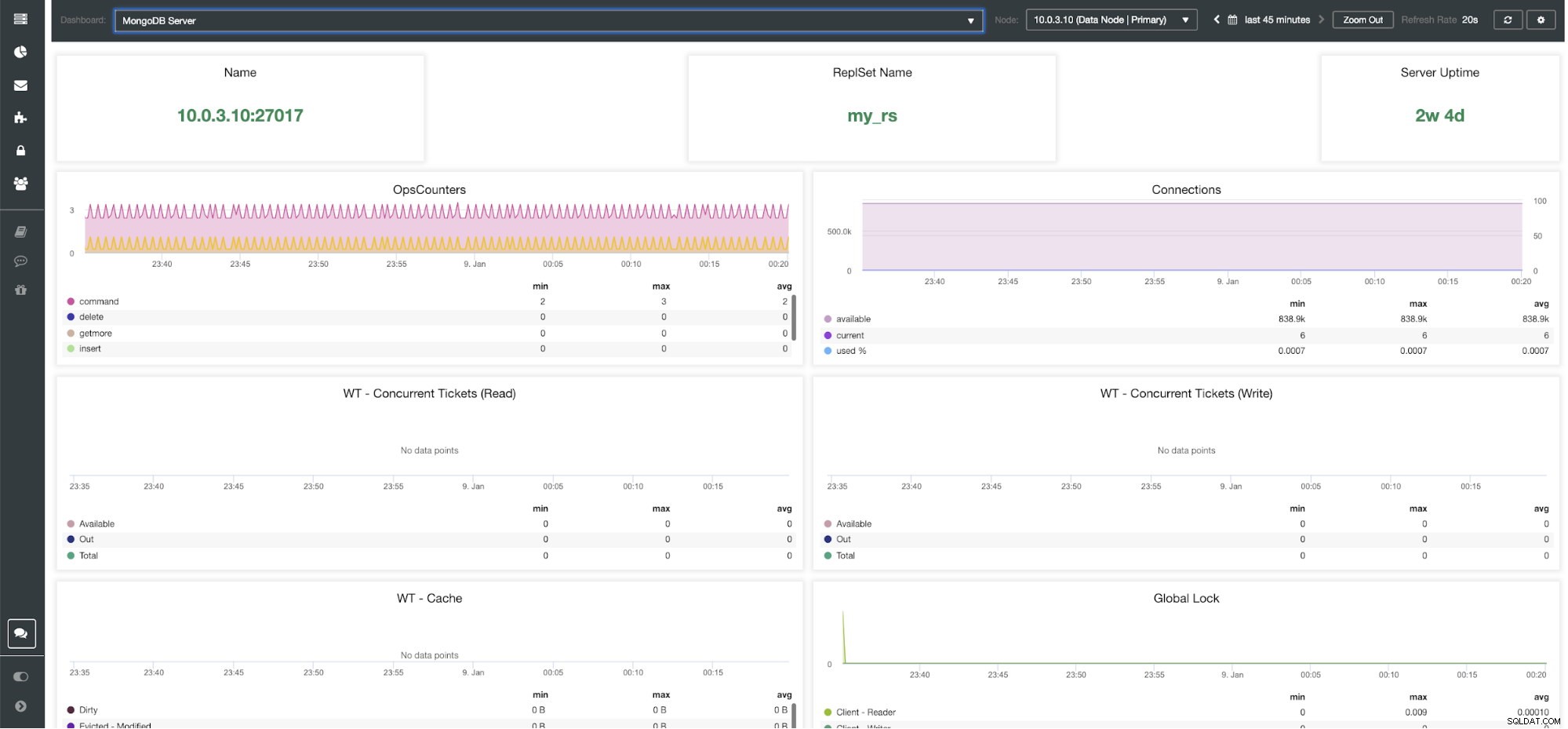 Panel de control del servidor MongoDB de ClusterControl
Panel de control del servidor MongoDB de ClusterControl| MongoDB ReplicaSet | |
|---|---|
| Tamaño de ReplSet Nombre de ReplSet PRIMARIO Versión del servidor Conjuntos de réplicas y miembros Ventana de Oplog por ReplSet Espacio de replicación Total de PRIMARIO/SECUNDARIO en línea por ReplSet Cursores abiertos por ReplSet ReplSet - Cursores con tiempo de espera agotado por conjunto Retraso máximo de replicación por ReplSet Tamaño de Oplog OpsCounters Tiempo de ping para replicar miembros del conjunto desde PRIMARY(s) |
 Panel de control ClusterControl MongoDB ReplicaSet
Panel de control ClusterControl MongoDB ReplicaSet Los sistemas de bases de datos dependen en gran medida de los recursos del sistema operativo, por lo que también puede encontrar dos paneles adicionales para la Descripción general del sistema y la Descripción general del clúster de su entorno MongoDB.
| Descripción general del sistema | |
|---|---|
| Tiempo de actividad del servidor Núcleos de CPU RAM total Promedio de carga Uso de CPU Uso de RAM Uso de espacio en disco Uso de red IOPS de disco % de utilidad de E/S de disco Rendimiento del disco |
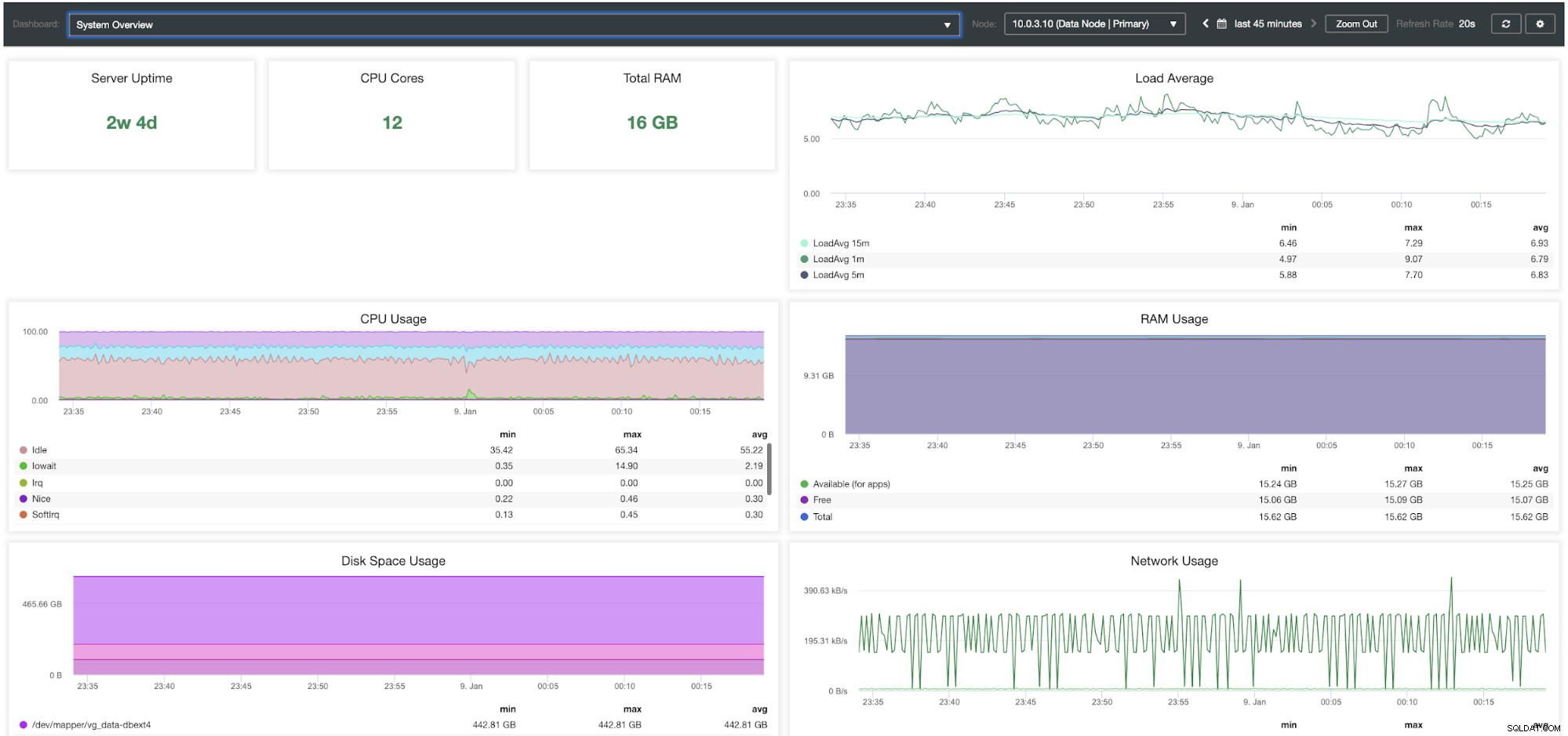 Panel de información general del sistema ClusterControl
Panel de información general del sistema ClusterControl| Información general del clúster | |
|---|---|
| Promedio de carga de 1 m Promedio de carga de 5 m Promedio de carga de 15 m Memoria disponible para aplicaciones TX de red RX de red IOPS de lectura de disco Escritura en disco IOPS Escritura en disco + IOPS de lectura |
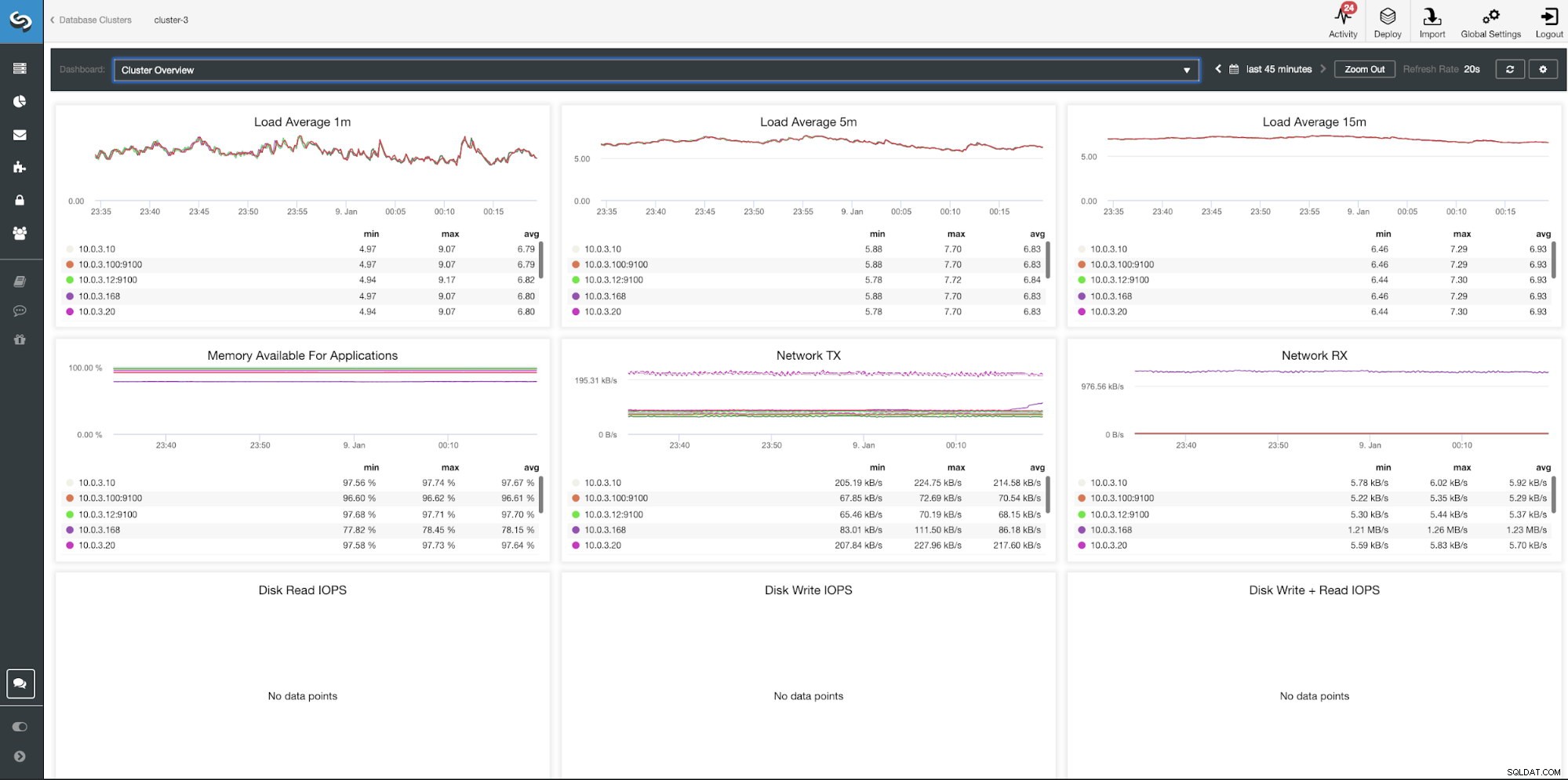 Panel de información general del clúster de ClusterControl
Panel de información general del clúster de ClusterControl Panel de control del servidor MongoDB
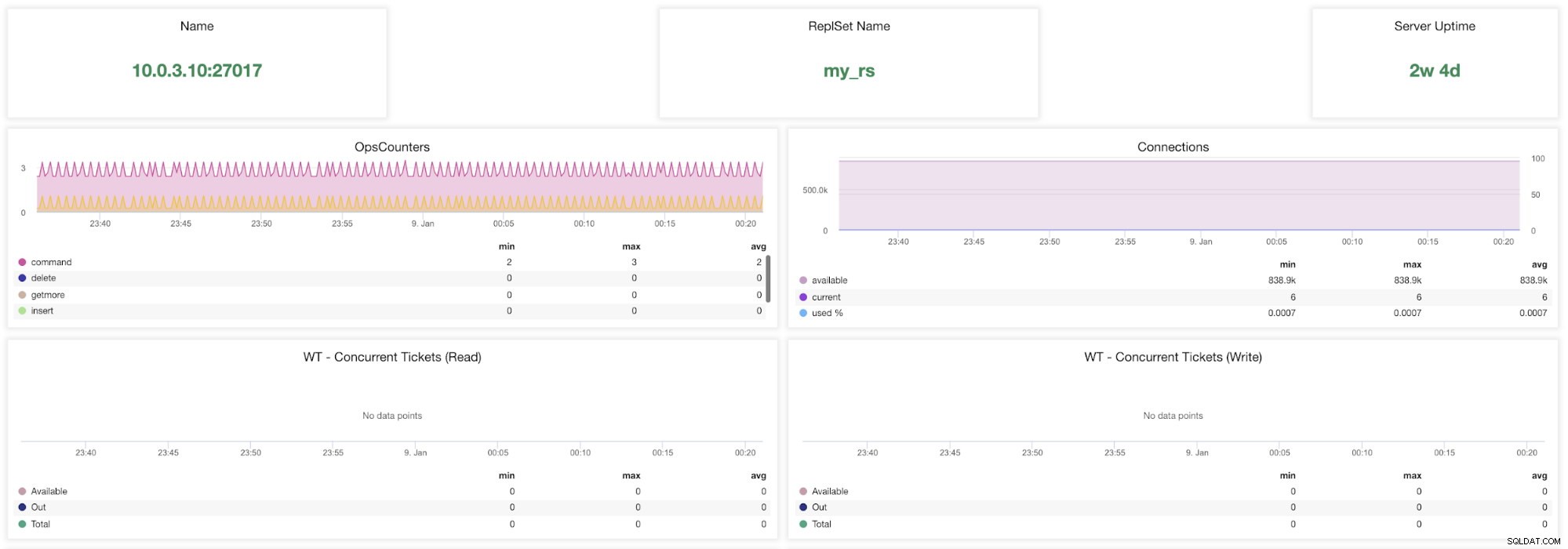 Métricas de ClusterControl MongoDB
Métricas de ClusterControl MongoDB Nombre - Dirección del servidor y el puerto.
Nombre del conjunto de respuestas - Presenta el nombre del conjunto de réplicas al que pertenece el servidor.
Tiempo de actividad del servidor - Tiempo desde el último reinicio del servidor.
Contadores de operaciones - Número de solicitudes recibidas durante el periodo de tiempo seleccionado desglosado por el tipo de operación. Estos recuentos incluyen todas las operaciones recibidas, incluidas las que no tuvieron éxito.
Conexiones - Este gráfico muestra una de las métricas más importantes para observar:la cantidad de conexiones recibidas durante el período de tiempo seleccionado, incluidas las solicitudes fallidas. Las cargas de tráfico anormales pueden provocar problemas de rendimiento. Si MongoDB se queda sin conexiones, es posible que no pueda manejar las solicitudes entrantes de manera oportuna.
WT:entradas simultáneas (lectura) / WT:entradas simultáneas (escritura) Estos dos gráficos muestran tickets de lectura y escritura que controlan la concurrencia en WiredTiger (WT). Los tickets WT controlan cuántas operaciones de lectura y escritura se pueden ejecutar en el motor de almacenamiento al mismo tiempo. Cuando los tickets de lectura y escritura disponibles caen a cero, el número de operaciones simultáneas en ejecución es igual a los valores de lectura/escritura configurados. Esto significa que cualquier otra operación debe esperar hasta que uno de los subprocesos en ejecución finalice su trabajo en el motor de almacenamiento antes de ejecutarse.
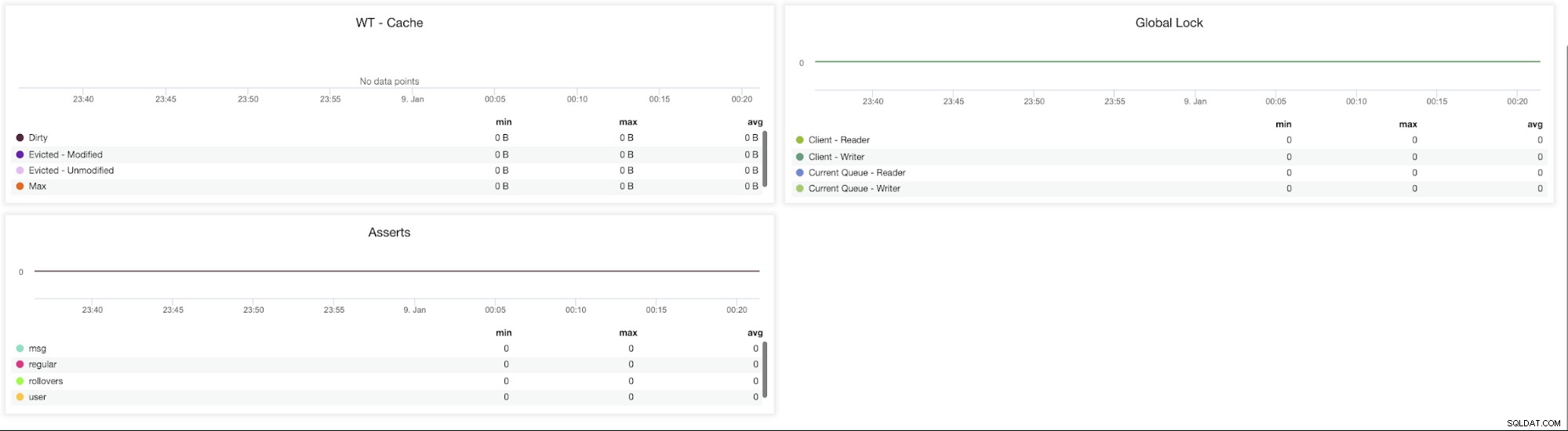 Métricas de ClusterControl MongoDB
Métricas de ClusterControl MongoDB WT - Caché (Sucio, Desalojado - Modificado, Desalojado - No modificado, Máx.):el tamaño de la memoria caché es el botón más importante para WiredTiger. Por defecto, MongoDB 3.x reserva el 50 % (60 % en 3.2) de la memoria disponible para su caché de datos.
Bloqueo global (Cliente-Lectura, Cliente - Escritura, Cola actual - Lector, Cola actual - Escritor) - Los patrones de diseño de esquema deficientes o las solicitudes de lectura y escritura pesadas de muchos clientes pueden causar bloqueos extensos. Cuando esto ocurre, es necesario mantener la coherencia y evitar conflictos de escritura.
Para lograr esto, MongoDB utiliza el bloqueo de granularidad múltiple que permite que las operaciones de bloqueo se realicen en diferentes niveles, como un nivel global, de base de datos o de colección. .
Afirmaciones (msg, regular, rollovers, user):este gráfico muestra la cantidad de afirmaciones que se generan cada segundo. Se deben revisar los valores altos y las desviaciones de las tendencias.
Panel de MongoDB ReplicaSet
Las métricas que se muestran en este panel son importantes solo si usa un conjunto de réplicas.
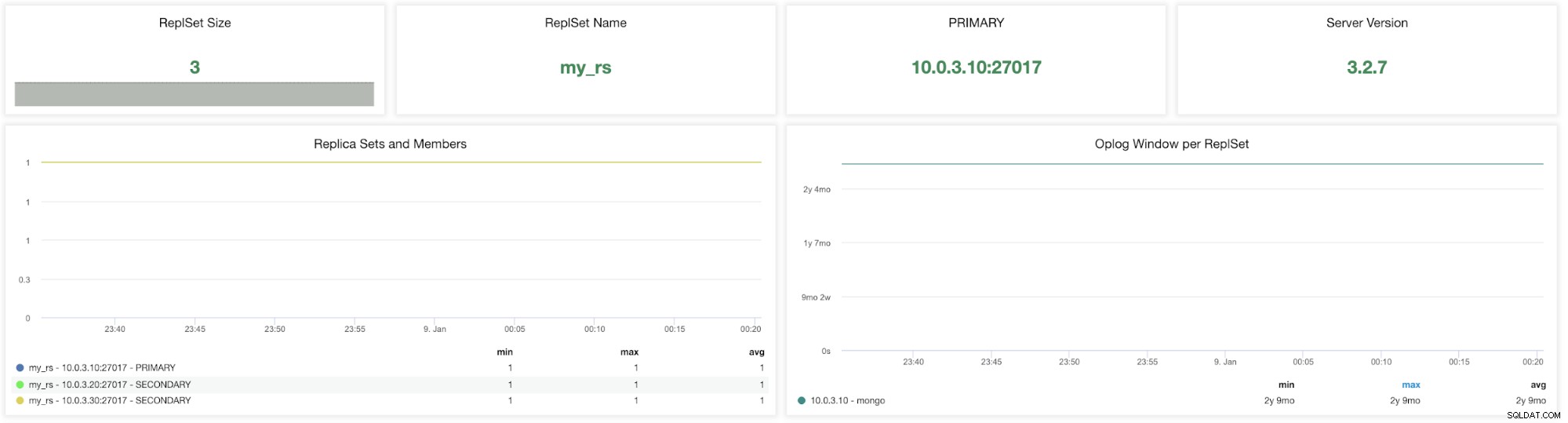 Métricas de ClusterControl MongoDB ReplicaSet
Métricas de ClusterControl MongoDB ReplicaSet Tamaño del conjunto de réplicas - El número de miembros en el conjunto de réplicas. La implementación del conjunto de réplicas estándar para el sistema de producción es un conjunto de réplicas de tres miembros. En términos generales, se recomienda que un conjunto de réplicas tenga un número impar de miembros con derecho a voto. La tolerancia a fallas para un conjunto de réplicas es la cantidad de miembros que pueden dejar de estar disponibles y aún así dejar suficientes miembros en el conjunto para elegir un principal. La tolerancia a fallos para tres miembros es uno, para cinco es dos, etc.
Nombre del conjunto de respuestas - Es el nombre asignado en el archivo de configuración de MongoDB. El nombre se refiere al valor /etc/mongod.conf replSet.
PRIMARIO - El nodo principal recibe todas las operaciones de escritura y registra todos los demás cambios en su conjunto de datos en su registro de operaciones. El valor es identificar la IP y el puerto de su nodo principal en el clúster del conjunto de réplicas de MongoDB.
Versión del servidor - Identificar la versión del servidor. La versión 1.7.1 de ClusterControl es compatible con las versiones 3.2/3.4/3.6/4.0 de MongoDB.
Conjuntos de réplicas y miembros (mín., máx., promedio):este gráfico puede ayudarlo a identificar a los miembros activos durante el período de tiempo. Puede rastrear los números mínimo, máximo y promedio de nodos primarios y secundarios y cómo estos números cambiaron con el tiempo. Cualquier desviación puede afectar la tolerancia a fallas y la disponibilidad del clúster.
Ventana de Oplog por ReplSet - La ventana de replicación es una métrica esencial para observar. El registro de operaciones de MongoDB es una colección única que se ha limitado en un tamaño (preestablecido). Se puede describir como la diferencia entre la primera y la última marca de tiempo en oplog.rs. Es la cantidad de tiempo que un secundario puede estar sin conexión antes de que se necesite la sincronización inicial para sincronizar la instancia. Estas métricas le informan cuánto tiempo le queda antes de que nuestra próxima transacción se elimine del registro de operaciones.
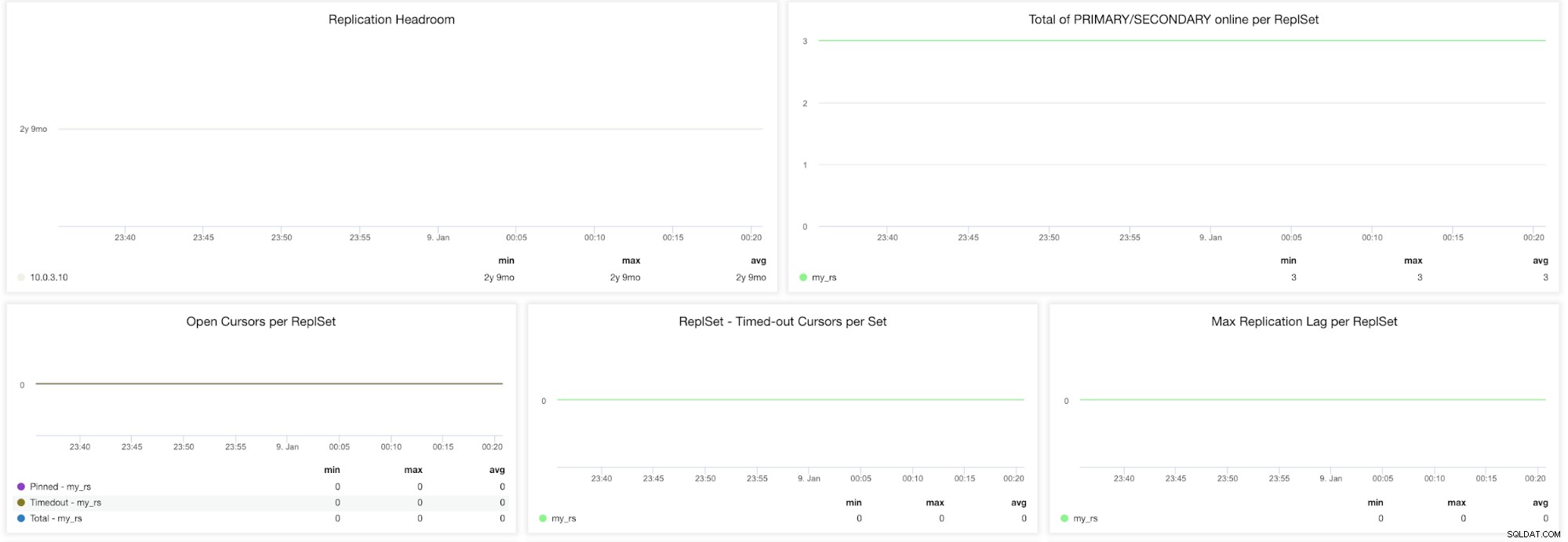 Métricas de ClusterControl MongoDB ReplicaSet
Métricas de ClusterControl MongoDB ReplicaSet Espacio de replicación - Este gráfico presenta la diferencia entre la ventana de oplog del primario y el retraso de replicación de los nodos secundarios. El registro de operaciones de MongoDB tiene un tamaño limitado y si el nodo se retrasa demasiado, no podrá ponerse al día. Si esto sucede, se emitirá una sincronización completa y esta es una operación costosa que debe evitarse en todo momento.
Total de PRIMARIO/SECUNDARIO en línea por ReplSet - Número total de nodos de clúster durante el período de tiempo.
Cursores abiertos por ReplSet (fijado, tiempo de espera, total) - Una solicitud de lectura viene con un cursor que es un puntero al conjunto de datos del resultado. Permanecerá abierto en el servidor y, por lo tanto, consumirá memoria a menos que se termine con la configuración predeterminada de MongoDB. Debería identificar los cursores no activos y cortarlos para guardarlos en la memoria.
ConjuntoRep - Cursores de tiempo de espera por SetsMax Retraso de replicación por ReplSet - Es muy importante vigilar el retraso de replicación si está ampliando las lecturas mediante la adición de más secundarios. MongoDB solo usará estos secundarios si no se quedan demasiado atrás. Si el secundario tiene un retraso en la replicación, corre el riesgo de entregar datos obsoletos que ya se sobrescribieron en el principal.
Tamaño de Oplog - Ciertas cargas de trabajo pueden requerir un tamaño de registro de operaciones mayor. Actualizaciones de varios documentos a la vez, las eliminaciones equivalen a la misma cantidad de datos que una inserción o la cantidad significativa de actualizaciones en el lugar.
OpsConters - Este gráfico muestra el número de ejecuciones de consultas.
Ping Time to Replica Set Member from Primary - Esto le permite descubrir miembros del conjunto de réplicas que están inactivos o que no se pueden alcanzar desde el nodo principal.
Palabras de cierre
La nueva función del panel de control de ClusterControl 1.7.1 MongoDB está disponible en la Community Edition de forma gratuita. Los equipos de operaciones de bases de datos pueden beneficiarse mediante el uso de gráficos de alta resolución, especialmente cuando realizan sus rutinas diarias como análisis de causa raíz y planificación de capacidad.
Es solo cuestión de un clic para implementar nuevos agentes de monitoreo. ClusterControl instala los agentes de Prometheus, configura las métricas y mantiene el acceso a la configuración de los exportadores de Prometheus a través de su GUI, para que pueda administrar mejor la configuración de los parámetros, como indicadores de recopiladores para los exportadores (Prometheus).
Al monitorear adecuadamente la cantidad de solicitudes de lectura y escritura, puede evitar la sobrecarga de recursos, encontrar rápidamente el origen de posibles sobrecargas y saber cuándo escalar.



