El equilibrio de carga de la base de datos distribuye solicitudes de clientes simultáneas a varios servidores de bases de datos para reducir la cantidad de carga en un solo servidor. Esto puede mejorar drásticamente el rendimiento de su base de datos. Afortunadamente, MongoDB puede manejar múltiples solicitudes de clientes para leer y escribir los mismos datos simultáneamente de forma predeterminada. Utiliza algunos mecanismos de control de concurrencia y protocolos de bloqueo para garantizar la consistencia de los datos en todo momento.
De esta manera, MongoDB también asegura que todos los clientes obtengan una vista consistente de los datos en cualquier momento. Debido a esta característica integrada de manejar solicitudes de múltiples clientes, no tiene que preocuparse por agregar un balanceador de carga externo encima de sus servidores MongoDB. Aunque, si aún desea mejorar el rendimiento de su base de datos mediante el equilibrio de carga, aquí hay algunas formas de lograrlo.
Escalado vertical de MongoDB
En términos simples, el escalado vertical significa agregar más recursos a su servidor para manejar la carga. Como todos los sistemas de bases de datos, MongoDB prefiere más RAM y capacidad de E/S. Esta es la forma más sencilla de aumentar el rendimiento de MongoDB sin distribuir la carga entre varios servidores. El escalado vertical de la base de datos MongoDB generalmente incluye aumentar la capacidad de la CPU o del disco y aumentar el rendimiento (operaciones de E/S). Al agregar más recursos, su servidor mongo se vuelve más capaz de manejar las solicitudes de múltiples clientes. Por lo tanto, mejor equilibrio de carga para su base de datos.
La desventaja de usar este enfoque es la limitación técnica de agregar recursos a un solo sistema. Además, todos los proveedores de la nube tienen limitaciones para agregar nuevas configuraciones de hardware. La otra desventaja de este enfoque es un único punto de falla. En este enfoque, todos sus datos se almacenan en un solo sistema, lo que puede provocar la pérdida permanente de sus datos.
Escalado horizontal de MongoDB
La escala horizontal se refiere a dividir su base de datos en fragmentos y almacenarlos en varios servidores. La principal ventaja de este enfoque es que puede agregar servidores adicionales sobre la marcha para aumentar el rendimiento de su base de datos sin tiempo de inactividad. MongoDB proporciona escalado horizontal mediante fragmentación. La fragmentación de MongoDB brinda capacidad adicional para distribuir la carga de escritura en varios servidores (fragmentos). Aquí, cada fragmento se puede ver como una base de datos independiente y la colección de todos los fragmentos se puede ver como una gran base de datos lógica. La fragmentación permite que su MongoDB distribuya los datos entre varios servidores para manejar las solicitudes simultáneas de los clientes de manera eficiente. Por lo tanto, aumenta el rendimiento de lectura y escritura de su base de datos.
fragmentación MongoDB
Un fragmento puede ser una única instancia de mongod o un conjunto de réplicas que contenga el subconjunto de la base de datos fragmentada de mongo. Puede convertir fragmentos en conjuntos de réplicas para garantizar una alta disponibilidad de datos y redundancia.
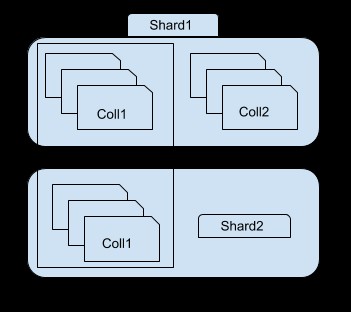
Como puede ver en la imagen anterior, el fragmento 1 contiene un subconjunto de la colección 1 y toda la colección2, mientras que el fragmento 2 contiene solo otro subconjunto de la colección1. Puede acceder a cada fragmento utilizando la instancia de mongos. Por ejemplo, si se conecta a la instancia shard1, podrá ver/acceder solo a un subconjunto de la colección 1.
Mongos
Mongos es el enrutador de consultas que brinda acceso al clúster fragmentado para aplicaciones cliente. Puede tener varias instancias de mongos para un mejor equilibrio de carga. Por ejemplo, en su clúster de producción, puede tener una instancia de mongos para cada servidor de aplicaciones. Ahora aquí puede usar un balanceador de carga externo, que redirigirá la solicitud de su servidor de aplicaciones a la instancia de mongos adecuada. Al agregar tales configuraciones a su servidor de producción, asegúrese de que la conexión de cualquier cliente siempre se conecte a la misma instancia de mongos cada vez, ya que algunos recursos de mongo, como los cursores, son específicos de la instancia de mongos.
Servidores de configuración
Los servidores de configuración almacenan los ajustes de configuración y los metadatos sobre su clúster. A partir de MongoDB versión 3.4, debe implementar servidores de configuración como un conjunto de réplicas. Si está habilitando la fragmentación en un entorno de producción, entonces es obligatorio usar tres servidores de configuración separados, cada uno en diferentes máquinas.
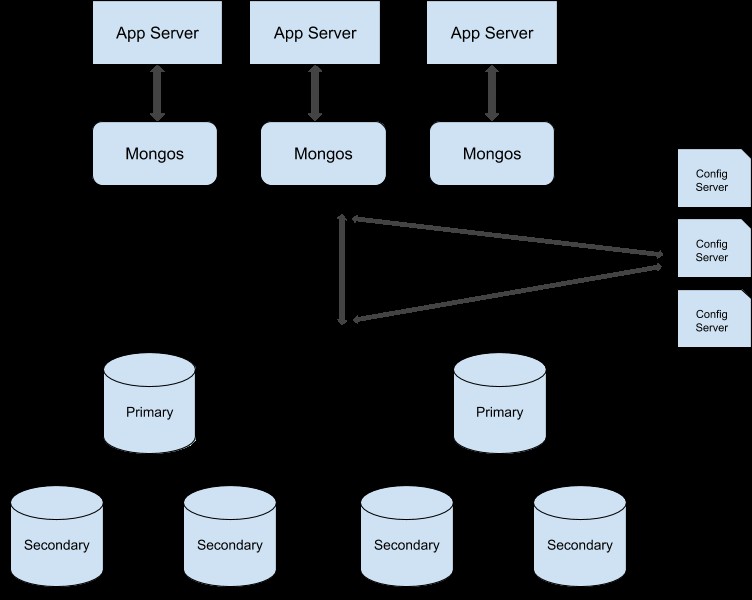
Puede seguir esta guía para convertir su conjunto de réplicas en un clúster fragmentado. Esta es la ilustración de muestra del clúster de producción fragmentado:
Equilibrio de carga de MongoDB mediante replicación
A veces, la replicación de MongoDB se puede usar para manejar más tráfico de clientes y reducir la carga en el servidor principal. Para hacerlo, puede indicar a los clientes que lean desde servidores secundarios en lugar del servidor principal. Esto puede reducir la cantidad de carga en el servidor principal, ya que todas las solicitudes de lectura provenientes de los clientes serán manejadas por servidores secundarios, y el servidor principal solo se ocupará de las solicitudes de escritura.
El siguiente es el comando para establecer la preferencia de lectura en secundaria:
db.getMongo().setReadPref('secondary')También puede especificar algunas etiquetas para apuntar a secundarios específicos mientras maneja las consultas de lectura.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Aquí, MongoDB intentará encontrar el nodo secundario con el valor de la etiqueta del centro de datos como APAC. Si se encuentra, Mongo atenderá las solicitudes de lectura de todos los secundarios con el centro de datos de la etiqueta:"APAC". Si no se encuentra, Mongo intentará encontrar secundarias con la etiqueta región:"Este". Si aún no se encuentran secundarios, entonces {} funcionará como el caso predeterminado y Mongo atenderá las solicitudes de cualquier secundario elegible.
Sin embargo, no se recomienda utilizar este enfoque para el equilibrio de carga para aumentar el rendimiento de lectura. Porque cualquier modo de preferencia de lectura que no sea el principal puede devolver datos antiguos en caso de actualizaciones de escritura recientes en el servidor principal. Por lo general, el servidor principal tardará algún tiempo en manejar las solicitudes de escritura y propagar los cambios a los servidores secundarios. Durante este tiempo, si alguien solicita una operación de lectura en los mismos datos, el servidor secundario devolverá datos obsoletos ya que no está sincronizado con el servidor principal. Puede usar este enfoque si su aplicación tiene muchas operaciones de lectura en comparación con las operaciones de escritura.
Conclusión
Como MongoDB puede manejar solicitudes simultáneas por sí mismo, no es necesario agregar un balanceador de carga en su clúster de MongoDB. Para equilibrar la carga de las solicitudes de los clientes, puede elegir el escalado vertical o el escalado horizontal, ya que no es recomendable utilizar secundarios para escalar sus operaciones de lectura y escritura. La escala vertical puede alcanzar los límites técnicos, como se discutió anteriormente. Por lo tanto, es adecuado para aplicaciones de pequeña escala. Para aplicaciones grandes, el escalado horizontal mediante fragmentación es el mejor enfoque para equilibrar la carga de las operaciones de lectura y escritura.



