Evaluar qué patrón de arquitectura de transmisión se adapta mejor a su caso de uso es una condición previa para una implementación de producción exitosa.
El ecosistema Apache Hadoop se ha convertido en una plataforma preferida para las empresas que buscan procesar y comprender datos a gran escala en tiempo real. Tecnologías como Apache Kafka, Apache Flume, Apache Spark, Apache Storm y Apache Samza están ampliando cada vez más los límites de lo que es posible. A menudo es tentador agrupar casos de uso de transmisión a gran escala, pero en realidad tienden a dividirse en algunos patrones arquitectónicos diferentes, con diferentes componentes del ecosistema más adecuados para diferentes problemas.
En esta publicación, describiré los cuatro principales patrones de transmisión que hemos encontrado con clientes que ejecutan centros de datos empresariales en producción y explicaré cómo implementar esos patrones arquitectónicamente en Hadoop.
Patrones de transmisión
Los cuatro patrones básicos de transmisión (a menudo usados en conjunto) son:
- Ingesta de transmisiones: Implica la persistencia de baja latencia de eventos en HDFS, Apache HBase y Apache Solr.
- Procesamiento de eventos en tiempo casi real (NRT) con contexto externo: Realiza acciones como alertar, marcar, transformar y filtrar eventos a medida que llegan. Se pueden tomar acciones basadas en criterios sofisticados, como modelos de detección de anomalías. Los casos de uso común, como la detección y recomendación de fraude de NRT, a menudo exigen latencias bajas de menos de 100 milisegundos.
- Procesamiento particionado de eventos NRT: Similar al procesamiento de eventos NRT, pero se beneficia de la partición de los datos, como almacenar información externa más relevante en la memoria. Este patrón también requiere latencias de procesamiento inferiores a 100 milisegundos.
- Topología compleja para agregaciones o ML: El santo grial del procesamiento de transmisiones:obtiene respuestas en tiempo real de los datos con un conjunto de operaciones complejo y flexible. Aquí, debido a que los resultados a menudo dependen de cálculos en ventana y requieren datos más activos, el enfoque cambia de latencia ultrabaja a funcionalidad y precisión.
En las siguientes secciones, veremos las formas recomendadas para implementar dichos patrones de una manera comprobada, comprobada y mantenible.
Ingestión de transmisión
Tradicionalmente, Flume ha sido el sistema recomendado para la ingesta de streaming. Su gran biblioteca de fuentes y sumideros cubre todas las bases de qué consumir y dónde escribir. (Para obtener detalles sobre cómo configurar y administrar Flume, Uso de Flume , el libro O'Reilly Media del ingeniero de software de Cloudera/miembro de Flume PMC, Hari Shreedharan, es un gran recurso).
En el último año, Kafka también se ha vuelto popular debido a sus potentes funciones, como la reproducción y la replicación. Debido a la superposición de los objetivos de Flume y Kafka, su relación suele ser confusa. ¿Cómo encajan? La respuesta es simple:Kafka es una canalización similar a la abstracción del Canal de Flume, aunque es una canalización mejor debido a su compatibilidad con las funciones mencionadas anteriormente. Un enfoque común es usar Flume para la fuente y el sumidero, y Kafka para la tubería entre ellos.
El siguiente diagrama ilustra cómo Kafka puede servir como fuente de datos UpStream para Flume, el destino DownStream de Flume o el canal Flume.
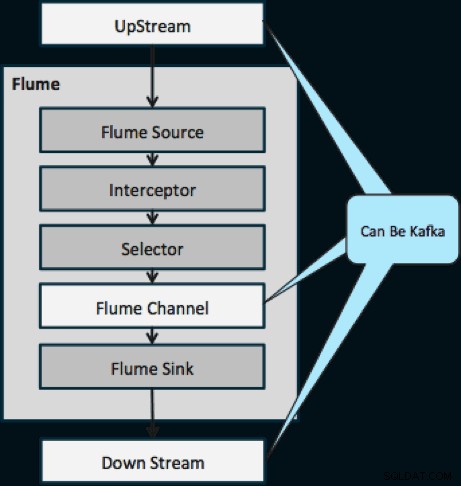
El diseño que se ilustra a continuación es enormemente escalable, reforzado para la batalla, monitoreado de forma centralizada a través de Cloudera Manager, tolerante a fallas y compatible con la reproducción.
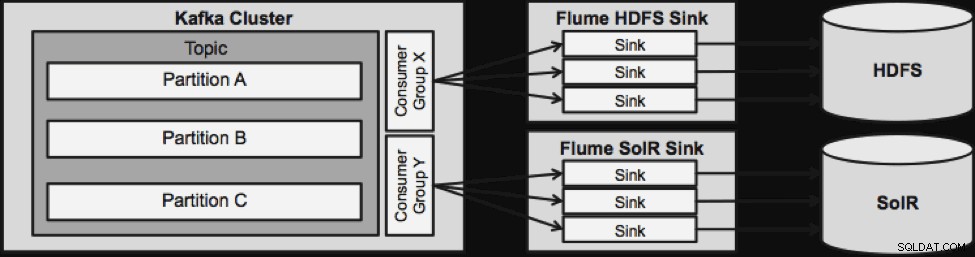
Una cosa a tener en cuenta antes de pasar a la siguiente arquitectura de transmisión es cómo este diseño maneja las fallas con gracia. Flume Sinks proviene de Kafka Consumer Group. El grupo de consumidores realiza un seguimiento de la compensación del tema con la ayuda de Apache ZooKeeper. Si se pierde un Flume Sink, Kafka Consumer redistribuirá la carga a los demás sumideros. Cuando Flume Sink vuelva a subir, el grupo Consumer redistribuirá nuevamente.
Procesamiento de eventos NRT con contexto externo
Para reiterar, un caso de uso común para este patrón es observar los eventos que se transmiten y tomar decisiones inmediatas, ya sea para transformar los datos o para realizar algún tipo de acción externa. La lógica de decisión a menudo depende de perfiles o metadatos externos. Una manera fácil y escalable de implementar este enfoque es agregar un interceptor de canal de fuente o sumidero a su arquitectura Kafka/Flume. Con un ajuste modesto, no es difícil lograr latencias de milisegundos.
Los Flume Interceptors toman eventos o lotes de eventos y permiten que el código de usuario los modifique o realice acciones en función de ellos. El código de usuario puede interactuar con la memoria local o un sistema de almacenamiento externo como HBase para obtener la información de perfil necesaria para tomar decisiones. HBase generalmente puede brindarnos nuestra información en alrededor de 4 a 25 milisegundos, según la red, el diseño del esquema y la configuración. También puede configurar HBase de manera que nunca esté inactivo o interrumpido, incluso en caso de falla.
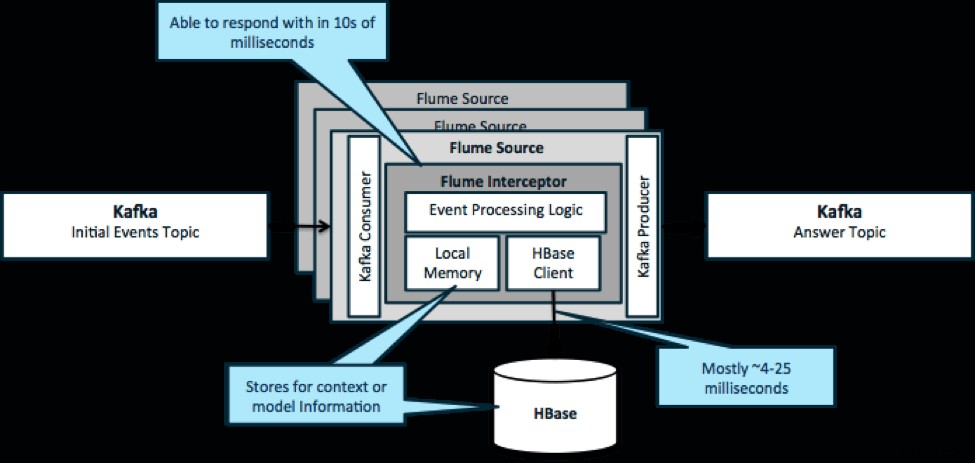
La implementación casi no requiere codificación más allá de la lógica específica de la aplicación en el interceptor. Cloudera Manager ofrece una interfaz de usuario intuitiva para implementar esta lógica a través de paquetes, así como para conectar, configurar y monitorear los servicios.
Procesamiento de eventos particionados NRT con contexto externo
En la arquitectura que se ilustra a continuación (solución sin particiones), necesitaría llamar con frecuencia a HBase porque el contexto externo relevante para eventos particulares no cabe en la memoria local de los interceptores Flume.
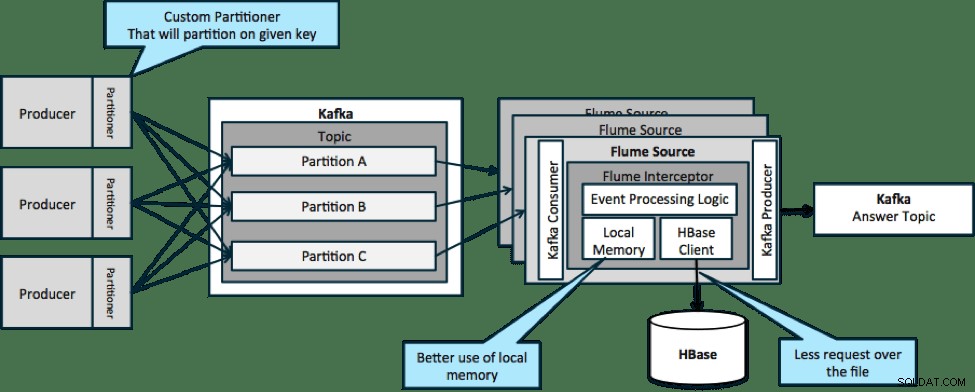
Sin embargo, si define una clave para particionar sus datos, puede hacer coincidir los datos entrantes con el subconjunto de los datos de contexto que son relevantes para ellos. Si particiona los datos 10 veces, solo necesita mantener 1/10 de los perfiles en la memoria. HBase es rápido, pero la memoria local es más rápida. Kafka le permite definir un particionador personalizado que utiliza para dividir sus datos.
Tenga en cuenta que Flume no es estrictamente necesario aquí; la solución raíz aquí es solo un consumidor de Kafka. Por lo tanto, podría usar solo un consumidor en YARN o una aplicación MapReduce solo de mapas.
Topología compleja para agregaciones o ML
Hasta este punto, hemos estado explorando las operaciones a nivel de eventos. Sin embargo, a veces necesita operaciones más complejas como recuentos, promedios, creación de sesiones o creación de modelos de aprendizaje automático que operan en lotes de datos. En este caso, Spark Streaming es la herramienta ideal por varias razones:
- Es fácil de desarrollar en comparación con otras herramientas. Las API completas y concisas de Spark facilitan la creación de topologías complejas.
- Código similar para transmisión y procesamiento por lotes. Con unos pocos cambios, el código para lotes pequeños en tiempo real se puede usar para lotes enormes fuera de línea. Además de reducir el tamaño del código, este enfoque reduce el tiempo necesario para la prueba y la integración.
- Hay un motor que debe conocer. Hay un costo que se destina a capacitar al personal sobre las peculiaridades y los aspectos internos de los motores de procesamiento distribuido. La estandarización en Spark consolida este costo tanto para la transmisión como para el procesamiento por lotes.
- Los microlotes lo ayudan a escalar de manera confiable. El reconocimiento a nivel de lote permite un mayor rendimiento y permite soluciones sin temor a un doble envío. Los microlotes también ayudan a enviar cambios a HDFS o HBase en términos de rendimiento a escala.
- La integración del ecosistema Hadoop está integrada. Spark tiene una integración profunda con HDFS, HBase y Kafka.
- Sin riesgo de pérdida de datos. Gracias a WAL y Kafka, Spark Streaming evita la pérdida de datos en caso de falla.
- Es fácil de depurar y ejecutar. Puede depurar y recorrer paso a paso su código Spark Streaming en un IDE local sin un clúster. Además, el código se parece a un código de programación funcional normal, por lo que un desarrollador de Java o Scala no necesita mucho tiempo para dar el salto. (Python también es compatible).
- La transmisión tiene estado de forma nativa. En Spark Streaming, el estado es un ciudadano de primera clase, lo que significa que es fácil escribir aplicaciones de transmisión con estado que sean resistentes a las fallas de los nodos.
- Como estándar de facto, Spark está recibiendo inversiones a largo plazo de todo el ecosistema.
En el momento de escribir este artículo, hubo aproximadamente 700 confirmaciones en Spark en su conjunto en los últimos 30 días, en comparación con otros marcos de transmisión como Storm, con 15 confirmaciones durante el mismo tiempo. - Tienes acceso a las bibliotecas de ML.
MLlib de Spark se está volviendo muy popular y su funcionalidad seguirá aumentando. - Puede usar SQL cuando sea necesario.
Con Spark SQL, puede agregar lógica SQL a su aplicación de transmisión para reducir la complejidad del código.
Conclusión
Hay mucho poder en la transmisión y varios patrones posibles, pero como ha aprendido en esta publicación, puede hacer cosas realmente poderosas con una codificación mínima si sabe qué patrón se adapta mejor a su caso de uso.
Ted Malaska es arquitecto de soluciones en Cloudera, colaborador de Spark, Flume y HBase, y coautor del libro de O'Reilly, Arquitectura de aplicaciones de Hadoop.



