Esta es la versión escrita de mi nuevo video de youtube ✍️ 🙂
En este tutorial de Redis, aprenderá sobre Redis y cómo se puede usar Redis como base de datos principal para aplicaciones complejas que necesitan almacenar datos en múltiples formatos.
Resumen 📝
- Qué es Redis y sus usos así como por qué es adecuado para aplicaciones modernas de microservicios complejos?
- Cómo admite Redis el almacenamiento de múltiples formatos de datos para diferentes propósitos a través de sus módulos ?
- Cómo Redis como base de datos en memoria puede mantener los datos y recuperarse de la pérdida de datos ?
- Cómo escalar y replicar Redis ?
- Por último, dado que una de las plataformas más populares para ejecutar microservicios es Kubernetes y que ejecutar aplicaciones con estado en Kubernetes es un poco complicado, veremos cómo puede ejecutar Redis en Kubernetes fácilmente.
¿Qué es Redis?
Redis significa re mote dic s cionarios nunca
Redis es una base de datos en memoria . Así que muchas personas lo han usado como un caché encima de otras bases de datos para mejorar el rendimiento de la aplicación. 🤓
Sin embargo, lo que mucha gente no sabe es que Redis es una base de datos primaria completa. que se puede utilizar para almacenar y conservar múltiples formatos de datos para aplicaciones complejas. 😎
Así que veamos los casos de uso para eso.
¿Por qué una base de datos multimodelo?
Veamos una configuración común para una aplicación de microservicios.
Digamos que tenemos una aplicación de redes sociales compleja con millones de usuarios. Para esto, es posible que necesitemos almacenar diferentes formatos de datos en diferentes bases de datos:
- Base de datos relacional , como Mysql, para almacenar nuestros datos
- Búsqueda elástica para búsqueda y filtrado rápidos
- Base de datos de gráficos para representar las conexiones de los usuarios
- Base de datos de documentos , como MongoDB para almacenar contenido multimedia compartido por nuestros usuarios diariamente
- Servicio de caché para un mejor rendimiento de la aplicación
Es obvio que esta es una configuración bastante compleja.
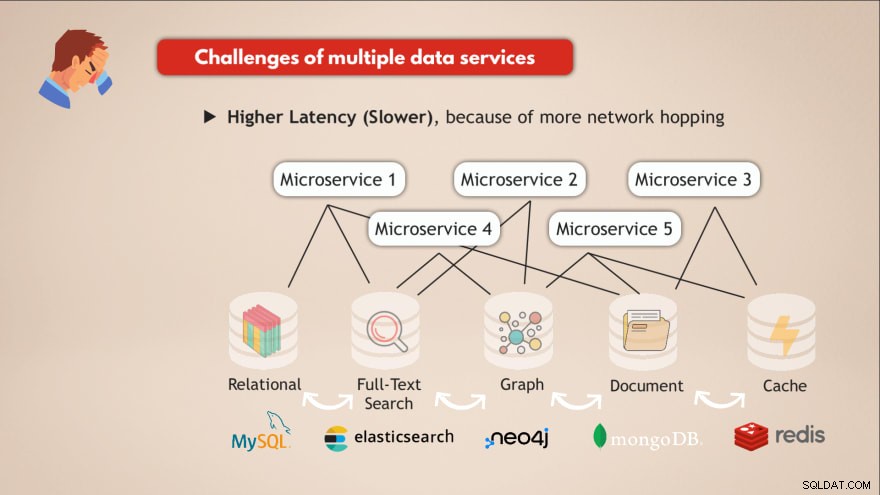
Desafíos de tener múltiples servicios de datos
- ❌ Cada servicio de datos debe implementarse y mantenerse
- ❌ Know-How necesario para cada servicio de datos
- ❌ Diferentes requisitos de escala e infraestructura
- ❌ Código de aplicación más complejo para interactuar con todas estas bases de datos diferentes
- ❌ Latencia más alta (más lenta), debido a más saltos de red
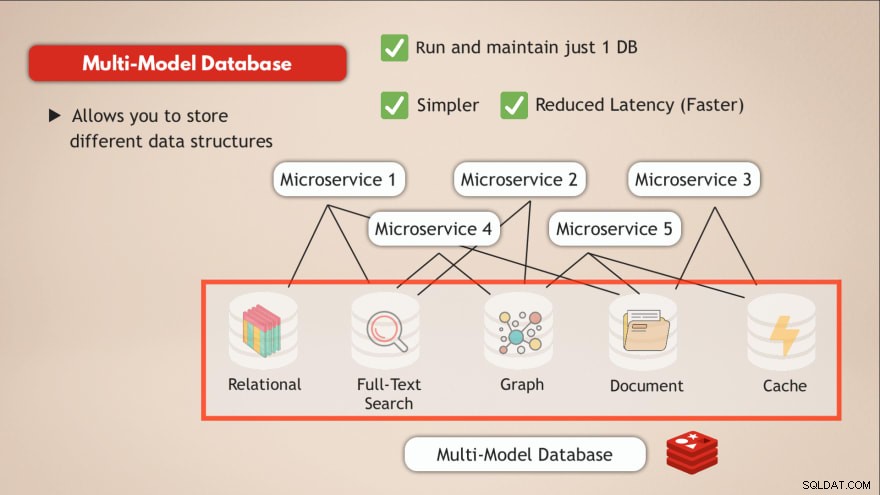
Tener una base de datos multimodelo
En comparación con una base de datos multimodelo, usted resuelve la mayoría de estos desafíos. En primer lugar, ejecuta y mantiene solo 1 servicio de datos . Por lo tanto, su aplicación también necesita hablar con un solo almacén de datos y eso requiere solo una interfaz programática para ese servicio de datos.
Además, la latencia se reducirá al ir a un solo punto final de datos y eliminar varios centros de red internos.
Entonces, tener una base de datos, como Redis, que le permite almacenar diferentes tipos de datos o básicamente le permite tener varios tipos de bases de datos en una sola, además de actuar como un caché, resuelve estos desafíos.
- ✅ Ejecute y mantenga solo 1 base de datos
- ✅ Más sencillo
- ✅ Latencia reducida (más rápido)
¿Cómo funciona Redis?
Módulos Redis 📦
La forma en que funciona es que tiene Redis Core, que es un almacén de valor clave que ya admite el almacenamiento de múltiples tipos de datos y luego puede ampliar ese núcleo con lo que se llama módulos para diferentes tipos de datos , que su aplicación necesita para diferentes propósitos. Entonces, por ejemplo, RediSearch para la funcionalidad de búsqueda como ElasticSearch o Redis Graph para el almacenamiento de datos de gráficos, etc.:

Y lo bueno de esto es que es modular . Por lo tanto, estos diferentes tipos de funcionalidades de base de datos no están estrechamente integrados en una sola base de datos, sino que puede elegir exactamente qué funcionalidad de servicio de datos necesita para su aplicación y luego, básicamente, agregar ese módulo.
Caché listo para usar ⚡️
Por supuesto, cuando usa Redis como base de datos principal, no necesita un caché adicional, porque lo tiene automáticamente listo para usar con Redis. Eso significa nuevamente menos complejidad en su aplicación, porque no necesita implementar la lógica para administrar el llenado y la invalidación de la memoria caché.
Redis es rápido 🚀
Como una base de datos en memoria (los datos se almacenan en RAM), Redis es súper rápido y eficaz, lo que por supuesto hace que la aplicación sea más rápida.
Pero llegados a este punto te estarás preguntando:
¿Cómo puede una base de datos en memoria conservar los datos? 🤔
¿Cómo puede Redis conservar los datos y recuperarse de la pérdida de datos? 🧐
Si falla el proceso de Redis o el servidor en el que se ejecuta Redis, todos los datos en la memoria desaparecerán, ¿verdad? Entonces, ¿cómo se conservan los datos y, básicamente, cómo puedo estar seguro de que mis datos están seguros? 👀
¿Replicando Redis?
Bueno, la forma más sencilla de tener copias de seguridad de datos es replicando Redis . Entonces, si la instancia maestra de Redis deja de funcionar, las réplicas seguirán ejecutándose y tendrán todos los datos. Entonces, si tiene un Redis replicado, las réplicas tendrán los datos.
Pero, por supuesto, si todas las instancias de Redis se caen, perderá los datos, porque no quedará ninguna réplica. 🤯Así que necesitamos persistencia real .
Instantáneas y AOF
Redis tiene múltiples mecanismos para conservar los datos y mantenerlos seguros.
Instantáneas
Primero:las instantáneas, que puede configurar en función del tiempo, la cantidad de solicitudes, etc. De modo que las instantáneas de sus datos se almacenarán en un disco , que puede usar para recuperar sus datos si toda la base de datos de Redis desaparece.
Pero tenga en cuenta que perderá los últimos minutos de datos , porque generalmente realiza instantáneas cada cinco minutos o una hora, según sus necesidades. 😐
AOF
Entonces, como alternativa, Redis usa algo llamado AOF , que significa A Añadir O solo F archivo.
En este caso cada cambio se guarda en el disco para persistencia continua . Y cuando se reinicie Redis o después de una interrupción, Redis reproducirá los registros de Solo archivo adjunto para reconstruir el estado.
Entonces AOF es más duradero , pero puede ser más lento que tomar instantáneas.
La mejor opción 💡:use una combinación de AOF e instantáneas, donde AOF persiste los datos de la memoria al disco de forma continua, además tiene instantáneas regulares en el medio para guardar el estado de los datos en caso de que necesite recuperarlos:

¿Cómo escalar una base de datos Redis?
Digamos que mi primera instancia de Redis se queda sin memoria, por lo que los datos se vuelven demasiado grandes para almacenarlos en la memoria o Redis se convierte en un cuello de botella y no puede manejar más solicitudes. En tal caso, ¿cómo aumento la capacidad y el tamaño de la memoria? para mi base de datos Redis? 🤔
Tenemos varias opciones para eso:
1. Agrupación
En primer lugar, Redis admite la agrupación en clústeres . Esto significa que puede tener una instancia principal o maestra de Redis, que se puede usar para leer y escribir datos y puede tener varias réplicas de esa instancia principal para leer los datos :
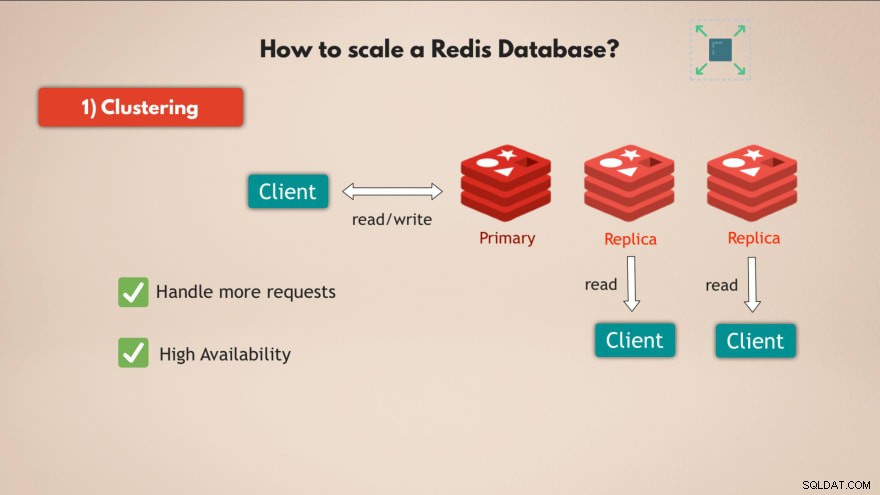
De esta forma, puede escalar Redis para gestionar más solicitudes y, además, aumentar la alta disponibilidad. de su base de datos, porque si el maestro falla, 1 de las réplicas puede hacerse cargo y su base de datos Redis básicamente puede continuar funcionando sin ningún problema.
2. Fragmentación
Bueno, eso parece lo suficientemente bueno, pero ¿y si
- su conjunto de datos crece demasiado para caber en la memoria de un solo servidor .
- Además, hemos escalado las lecturas en la base de datos, por lo que todas las solicitudes que básicamente solo consultan los datos. Pero nuestra instancia maestra todavía está sola y todavía tiene que manejar todas las escrituras .
Entonces, ¿cuál es la solución aquí? 🤔
Para eso usamos el concepto de sharding , que es un concepto general en las bases de datos y que Redis también admite.
Así que fragmentación básicamente significa que toma su conjunto de datos completo y lo divide en partes o subconjuntos de datos más pequeños , donde cada fragmento es responsable de su propio subconjunto de datos.
Eso significa que en lugar de tener una instancia maestra que maneje todas las escrituras en el conjunto de datos completo, puede dividirlo en, digamos, 4 fragmentos, cada uno de ellos responsable de las lecturas y escrituras en un subconjunto de los datos . 💡
Y cada fragmento también necesita menos capacidad de memoria , porque solo tienen una cuarta parte de los datos. Esto significa que puede distribuir y ejecutar fragmentos en nodos más pequeños y básicamente escalar su clúster horizontalmente:
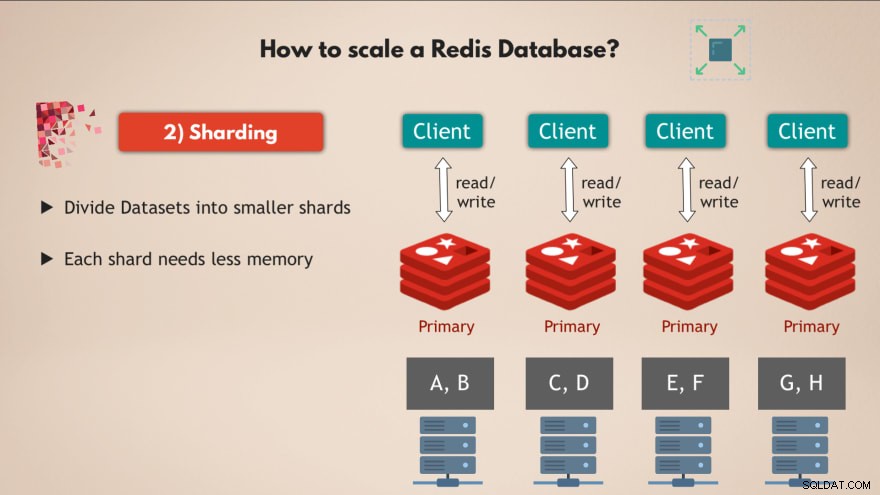
Entonces, tener múltiples nodos , que ejecutan múltiples réplicas de Redis que están todas fragmentadas le brinda una base de datos Redis de gran rendimiento y alta disponibilidad que puede manejar muchas más solicitudes sin crear cuellos de botella 👍
Más temas...
Mire mi video a continuación para ver los últimos 2 temas y escenarios:
- Aplicaciones que necesitan una disponibilidad y un rendimiento aún mayores en varias ubicaciones geográficas
- El nuevo estándar para ejecutar microservicios es la plataforma Kubernetes, por lo que ejecutar Redis en Kubernetes es un caso de uso muy interesante y común
El video completo está disponible aquí:🤓
¡Espero que esto haya sido útil e interesante para algunos de ustedes! 😊
Me gusta, compartir y seguirme 😍 para más contenido:
- Instagram:publica muchas cosas detrás de escena
- Grupo privado de FB



