La importancia de la conmutación por error
La conmutación por error es una de las prácticas de bases de datos más importantes para el gobierno de bases de datos. Es útil no solo cuando se administran grandes bases de datos en producción, sino también si desea asegurarse de que su sistema esté siempre disponible cada vez que acceda a él, especialmente en el nivel de la aplicación.
Antes de que se produzca una conmutación por error, las instancias de su base de datos deben cumplir ciertos requisitos. Estos requisitos son, de hecho, muy importantes para la alta disponibilidad. Uno de los requisitos que deben cumplir las instancias de su base de datos es la redundancia. La redundancia permite que continúe la conmutación por error, en la que la redundancia se configura para tener un candidato de conmutación por error que puede ser un nodo de réplica (secundario) o de un grupo de réplicas que actúan como nodos de espera o de espera activa. El candidato se selecciona de forma manual o automática en función del nodo más avanzado o actualizado. Por lo general, querrá una réplica en espera activa, ya que puede evitar que su base de datos extraiga índices del disco, ya que una espera activa a menudo llena los índices en el grupo de búfer de la base de datos.
Failover es el término utilizado para describir que se ha producido un proceso de recuperación. Antes del proceso de recuperación, esto ocurre cuando un nodo de la base de datos primaria (o maestra) falla después de un bloqueo, después de un desastre natural, después de una falla de hardware o puede haber sufrido una partición de la red; estos son los casos más comunes por los que se puede producir una conmutación por error. El proceso de recuperación generalmente procede automáticamente y luego busca la secundaria (réplica) más deseada y actualizada como se indicó anteriormente.
Conmutación por error avanzada
Aunque el proceso de recuperación durante una conmutación por error es automático, hay ciertas ocasiones en las que no es necesario automatizar el proceso y debe hacerse cargo un proceso manual. La complejidad suele ser la consideración principal asociada con las tecnologías que componen toda la pila de su base de datos:la conmutación por error automática también se puede combinar con la conmutación por error manual.
En la mayoría de las consideraciones cotidianas con la administración de bases de datos, la mayoría de las preocupaciones en torno a la conmutación por error automática no son triviales. A menudo resulta útil implementar y configurar una conmutación por error automática en caso de que surjan problemas. Aunque eso suena prometedor ya que cubre complejidades, vienen los mecanismos avanzados de conmutación por error y eso involucra eventos "previos" y eventos "posteriores" que están vinculados como ganchos en un software o tecnología de conmutación por error.
Estos eventos previos y posteriores generan comprobaciones o ciertas acciones para realizar antes de que finalmente pueda continuar con la conmutación por error, y después de que se realiza una conmutación por error, algunas limpiezas para asegurarse de que la conmutación por error finalmente sea exitosa uno. Afortunadamente, hay herramientas disponibles que permiten, no solo la conmutación por error automática, sino también la capacidad de aplicar enlaces previos y posteriores a la secuencia de comandos.
En este blog, usaremos la conmutación por error automática de ClusterControl (CC) y explicaremos cómo usar los enlaces previos y posteriores a la secuencia de comandos y a qué clúster se aplican.
Conmutación por error de replicación de ClusterControl
El mecanismo de conmutación por error de ClusterControl se aplica de manera eficiente sobre la replicación asincrónica que se aplica a las variantes de MySQL (MySQL/Percona Server/MariaDB). También es aplicable a los clústeres de PostgreSQL/TimescaleDB:ClusterControl admite la replicación de transmisión. Los clústeres de MongoDB y Galera tienen su propio mecanismo de conmutación por error automático integrado en su propia tecnología de base de datos. Obtenga más información sobre cómo ClusterControl realiza la recuperación automática de la base de datos y la conmutación por error.
La conmutación por error de ClusterControl no funciona a menos que la recuperación del nodo y del clúster (recuperación automática estén habilitadas). Eso significa que estos botones deben ser verdes.

La documentación establece que estas opciones de configuración también se pueden usar para habilitar / deshabilite lo siguiente:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Para este blog, nos estamos enfocando principalmente en cómo usar los ganchos de secuencias de comandos previas y posteriores, lo que es esencialmente una gran ventaja para la conmutación por error de replicación avanzada.
Replicación de conmutación por error del clúster compatibilidad con secuencias de comandos previas y posteriores
Como se mencionó anteriormente, las variantes de MySQL que utilizan la replicación asincrónica (incluida la semisincrónica) y la replicación de transmisión para PostgreSQL/TimescaleDB admiten este mecanismo. ClusterControl tiene las siguientes opciones de configuración que se pueden usar para enlaces previos y posteriores al script. Básicamente, estas opciones de configuración se pueden configurar a través de sus archivos de configuración o se pueden configurar a través de la interfaz de usuario web (nos ocuparemos de esto más adelante).
Nuestra documentación establece que estas son las siguientes opciones de configuración que pueden alterar el mecanismo de conmutación por error mediante el uso de ganchos de script previos y posteriores:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Técnicamente, una vez que establezca las siguientes opciones de configuración en su archivo de configuración /etc/cmon.d/cmon_
$ systemctl restart cmonComo alternativa, también puede establecer las opciones de configuración yendo a
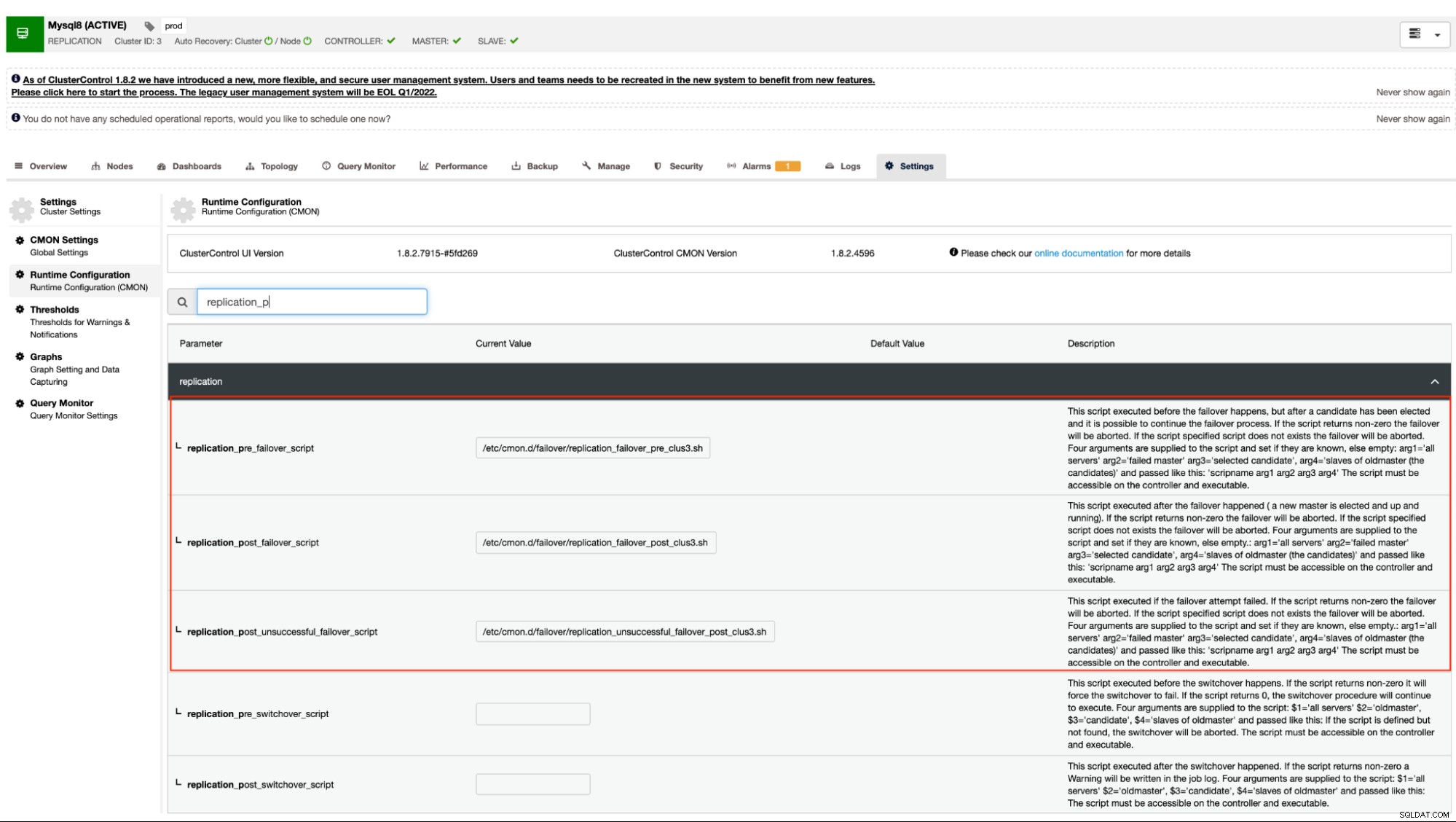
Este enfoque aún requeriría reiniciar el servicio cmon antes de que pueda reflejar el cambios realizados para estas opciones de configuración para enlaces previos y posteriores al script.
Ejemplo de enlaces previos y posteriores al script
Idealmente, los enlaces previos y posteriores al script están dedicados cuando necesita una conmutación por error avanzada para la cual ClusterControl no pudo administrar la complejidad de la configuración de su base de datos. Por ejemplo, si está ejecutando diferentes centros de datos con seguridad estricta y desea determinar si la alerta de que la red es inalcanzable no es una alarma de falso positivo. Tiene que verificar si el primario y el esclavo pueden comunicarse entre sí y viceversa y también puede comunicarse desde los nodos de la base de datos que van al host de ClusterControl.
Hagamos eso en nuestro ejemplo y demostremos cómo puede beneficiarse de él.
Detalles del servidor y scripts
En este ejemplo, estoy usando un clúster de replicación de MariaDB con solo un primario y una réplica. Administrado por ClusterControl para administrar la conmutación por error.
ClusterControl =192.168.40.110
primario (debnode5) =192.168.30.50
réplica (debnode9) =192.168.30.90
En el nodo principal, cree el script como se indica a continuación,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Asegúrese de que /opt/pre_failover.sh sea ejecutable, es decir,
$ chmod +x /opt/pre_failover.shEntonces use este script para participar a través de cron. En este ejemplo, creé un archivo /etc/cron.d/ccfailover y tengo el siguiente contenido:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shEn su réplica, solo use los siguientes pasos que hicimos para el principal, excepto cambiar el nombre de host. Vea lo siguiente de lo que tengo a continuación en mi réplica:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"y asegúrese de que el script invocado en nuestro cron sea ejecutable,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shScripts previos y posteriores de ClusterControl
En esta demostración, mi cluster_id es 3. Como se indicó anteriormente en nuestra documentación, requiere que estas secuencias de comandos residan en nuestro host controlador CC. Así que en mi /etc/cmon.d/cmon_3.cnf, tengo lo siguiente:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shMientras que la siguiente secuencia de comandos "previa" a la conmutación por error determina si ambos nodos pudieron llegar al host del controlador CC. Ver lo siguiente:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demostración de conmutación por error
Ahora, intentemos simular una interrupción de la red en el nodo principal y veamos cómo reacciona. En mi nodo principal, elimino la interfaz de red que se usa para comunicarme con la réplica y el controlador CC.
example@sqldat.com:~# ip link set enp0s8 downDurante el primer intento de conmutación por error, CC pudo ejecutar mi script previo que se encuentra en /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Vea a continuación cómo funciona:
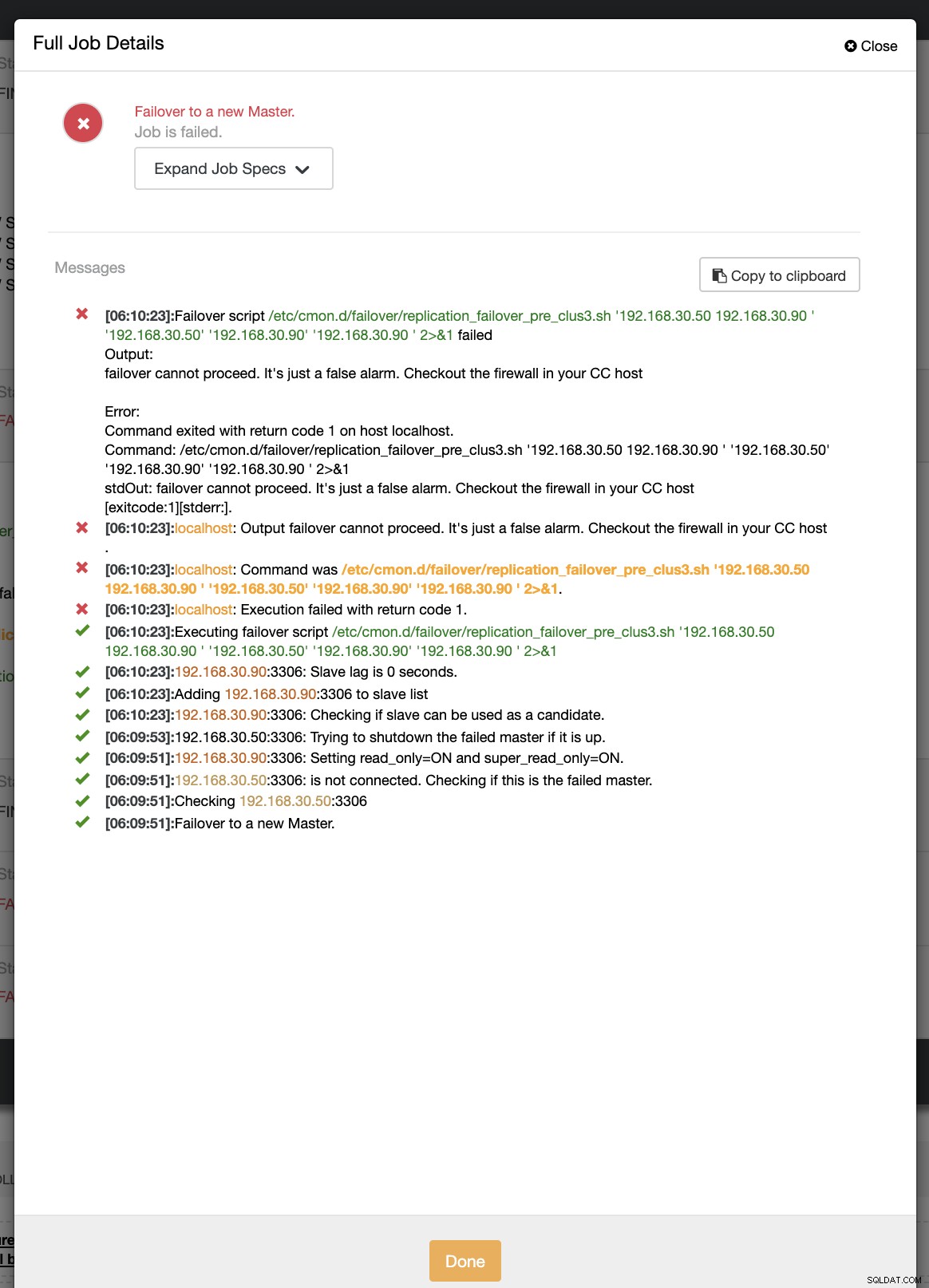
Obviamente, falla porque la marca de tiempo que se ha registrado aún no tiene más de un minuto o fue hace solo unos segundos que el controlador principal aún podía conectarse con el controlador CC. Obviamente, ese no es el enfoque perfecto cuando se trata de un escenario real. Sin embargo, ClusterControl pudo invocar y ejecutar el script perfectamente como se esperaba. Ahora, ¿qué tal si realmente alcanza más de un minuto (es decir,> 60 segundos)?
En nuestro segundo intento de conmutación por error, dado que la marca de tiempo alcanza más de 60 segundos, se considera que es un verdadero positivo, y eso significa que tenemos que realizar la conmutación por error según lo previsto. CC ha podido ejecutarlo perfectamente e incluso ejecutar el script posterior como se esperaba. Esto se puede ver en el registro de trabajo. Vea la captura de pantalla a continuación:
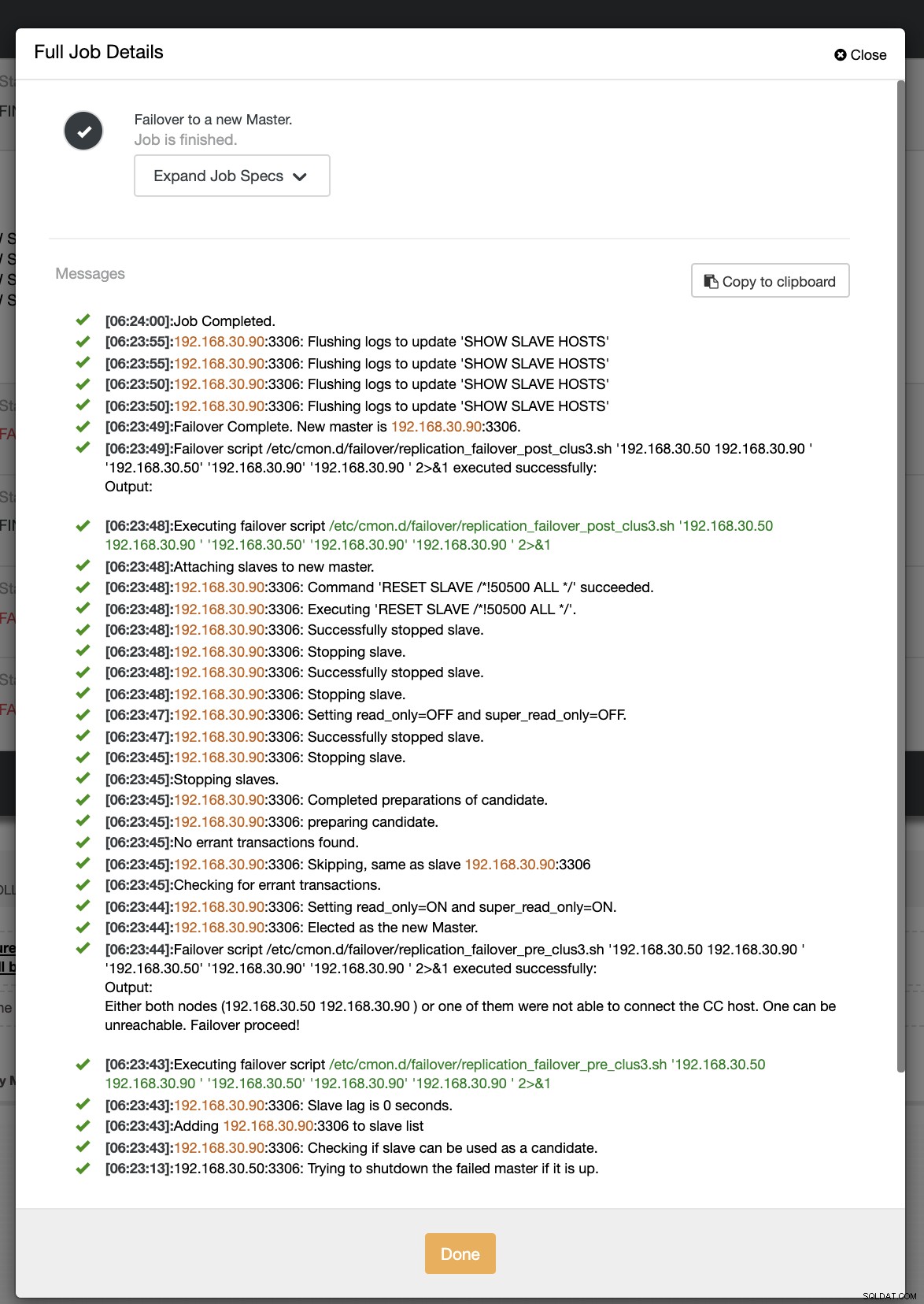
Verificando si se ejecutó mi secuencia de comandos posterior, fue capaz de crear el registro archivo en el directorio CC /tmp como se esperaba,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtpublicar secuencia de comandos de conmutación por error en el clúster 3 con argumentos:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
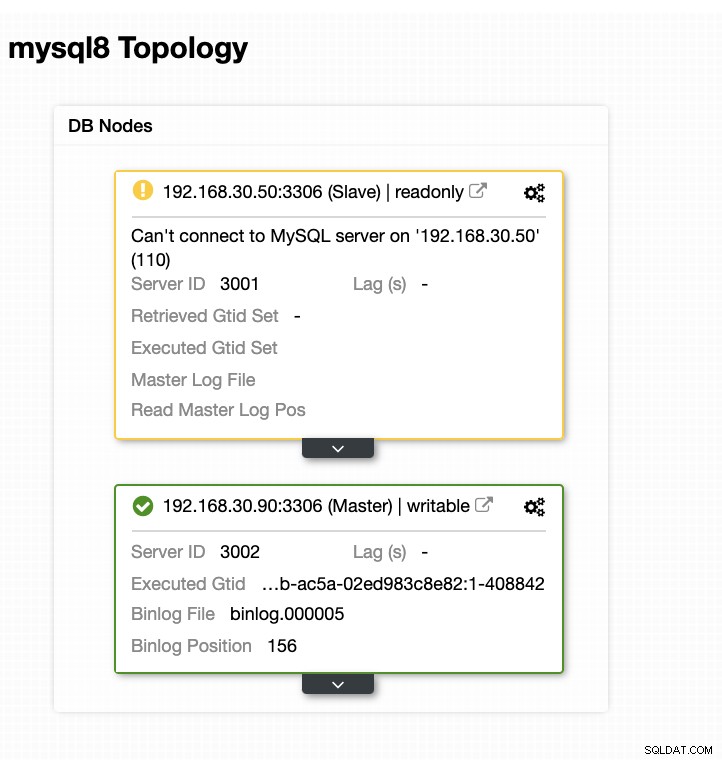
Ahora, mi topología ha cambiado y la conmutación por error fue exitosa.
Conclusión
Para cualquier configuración de base de datos complicada que pueda tener, cuando se requiere una conmutación por error avanzada, las secuencias de comandos previas y posteriores pueden ser muy útiles para lograrlo. Dado que ClusterControl es compatible con estas funciones, hemos demostrado lo poderoso y útil que es. Incluso con sus limitaciones, siempre hay formas de hacer que las cosas sean factibles y útiles, especialmente en entornos de producción.