El clúster de Galera impone una sólida consistencia de datos, donde todos los nodos del clúster están estrechamente acoplados. Aunque se admite la segmentación de la red, el rendimiento de la replicación sigue estando limitado por dos factores:
-
El tiempo de ida y vuelta (RTT) al nodo más alejado del clúster desde el nodo de origen.
-
El tamaño de un conjunto de escritura que se transferirá y certificará en caso de conflicto en el nodo receptor.
Si bien hay formas de mejorar el rendimiento de Galera, no es posible evitar estos dos factores limitantes.
Afortunadamente, Galera Cluster se construyó sobre MySQL, que también viene con una función de replicación incorporada (¡duh!). Tanto la replicación de Galera como la replicación de MySQL existen en el mismo software de servidor de forma independiente. Podemos hacer uso de estas tecnologías para trabajar juntos, donde toda la replicación dentro de un centro de datos estará en Galera, mientras que la replicación entre centros de datos estará en la replicación MySQL estándar. El sitio esclavo puede actuar como un sitio en espera activo, listo para servir datos una vez que las aplicaciones se redirigen al sitio de respaldo. Cubrimos esto en un blog anterior sobre arquitecturas MySQL para recuperación ante desastres.
La replicación de clúster a clúster se introdujo en ClusterControl en la versión 1.7.4. En esta publicación de blog, mostraremos lo sencillo que es configurar la replicación entre dos clústeres de Galera (PXC 8.0). Luego, veremos la parte más desafiante:manejar fallas tanto a nivel de nodo como de clúster con la ayuda de ClusterControl; Las operaciones de conmutación por error y conmutación por recuperación son cruciales para preservar la integridad de los datos en todo el sistema.
Despliegue de clúster
Por el bien de nuestro ejemplo, necesitaremos al menos dos clústeres y dos sitios:uno para el principal y otro para el secundario. Funciona de manera similar a la replicación maestro-esclavo tradicional de MySQL, pero a mayor escala con tres nodos de base de datos en cada sitio. Con ClusterControl, lograría esto mediante la implementación de un clúster principal, seguido de la implementación del clúster secundario en el sitio de recuperación ante desastres como un clúster de réplica, replicado por una replicación asíncrona bidireccional.
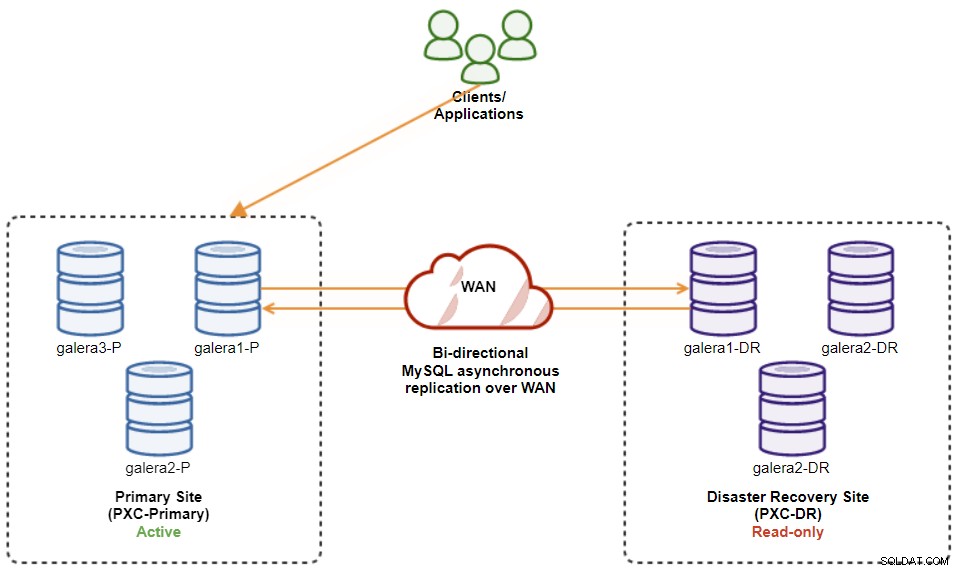
El siguiente diagrama ilustra nuestra arquitectura final:

Tenemos seis nodos de base de datos en total, tres en el sitio principal y otro tres en el sitio de recuperación de desastres. Para simplificar la representación de los nodos, utilizaremos las siguientes notaciones:
-
Sitio principal:
-
galera1-P - 192.168.11.171 (maestro)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Sitio de recuperación ante desastres:
-
galera1-DR - 192.168.11.181 (esclavo)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Primero, simplemente implemente el primer clúster y lo llamaremos PXC-Primary. Abra la interfaz de usuario de ClusterControl → Implementar → MySQL Galera e ingrese todos los detalles requeridos:
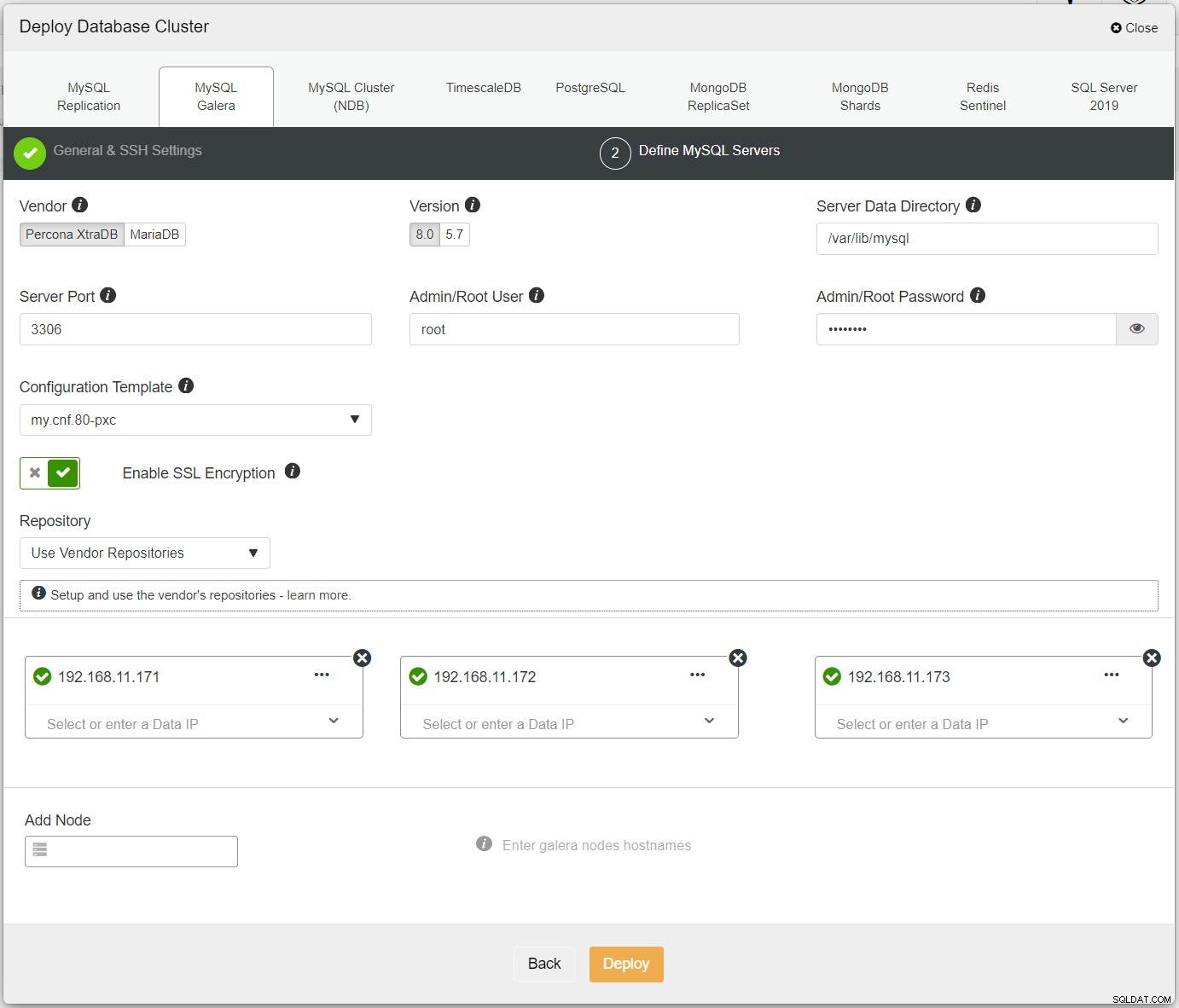
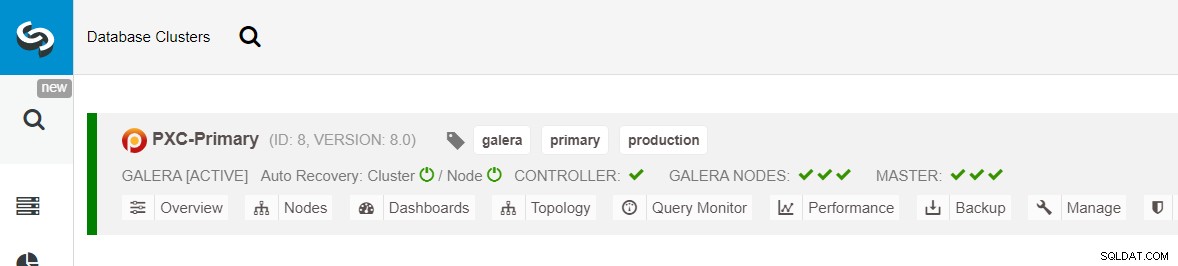
Asegúrese de que cada nodo especificado tenga una marca verde junto a él, lo que indica que ClusterControl puede conectarse al host a través de SSH sin contraseña. Haga clic en Implementar y espere a que se complete la implementación. Una vez hecho esto, debería ver el siguiente grupo en la página del panel del grupo:
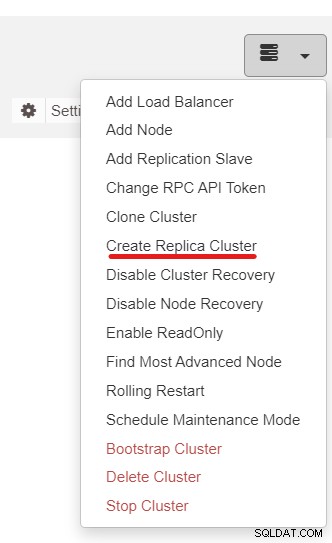
A continuación, usaremos la función ClusterControl llamada Create Replica Cluster, accesible desde el menú desplegable Acción de clúster:
Aparecerá la siguiente ventana emergente en la barra lateral:
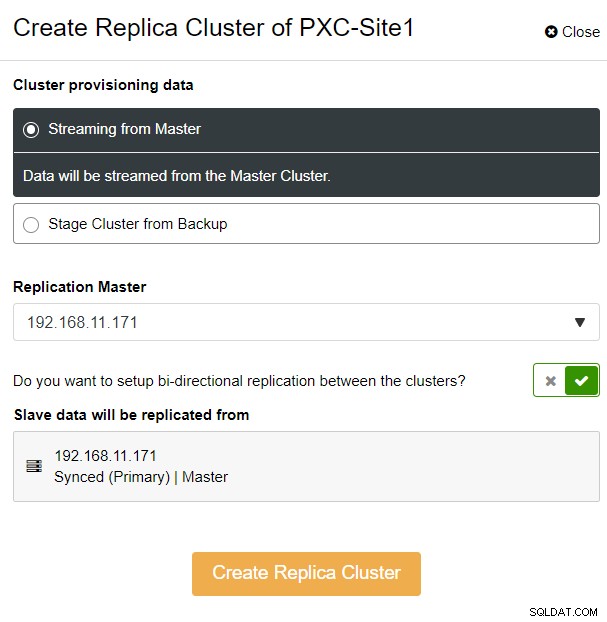
Elegimos la opción "Streaming from Master", donde ClusterControl usará el maestro elegido para sincronizar el clúster de réplica y configurar la replicación. Preste atención a la opción de replicación bidireccional. Si está habilitado, ClusterControl configurará una replicación bidireccional entre ambos sitios (replicación circular). El maestro elegido se replicará desde el primer maestro definido para el clúster de réplica y viceversa. Esta configuración minimizará el tiempo de preparación requerido cuando se recupera después de una conmutación por error o conmutación por recuperación. Haga clic en "Crear clúster de réplica", donde ClusterControl abre un nuevo asistente de implementación para el clúster de réplica, como se muestra a continuación:
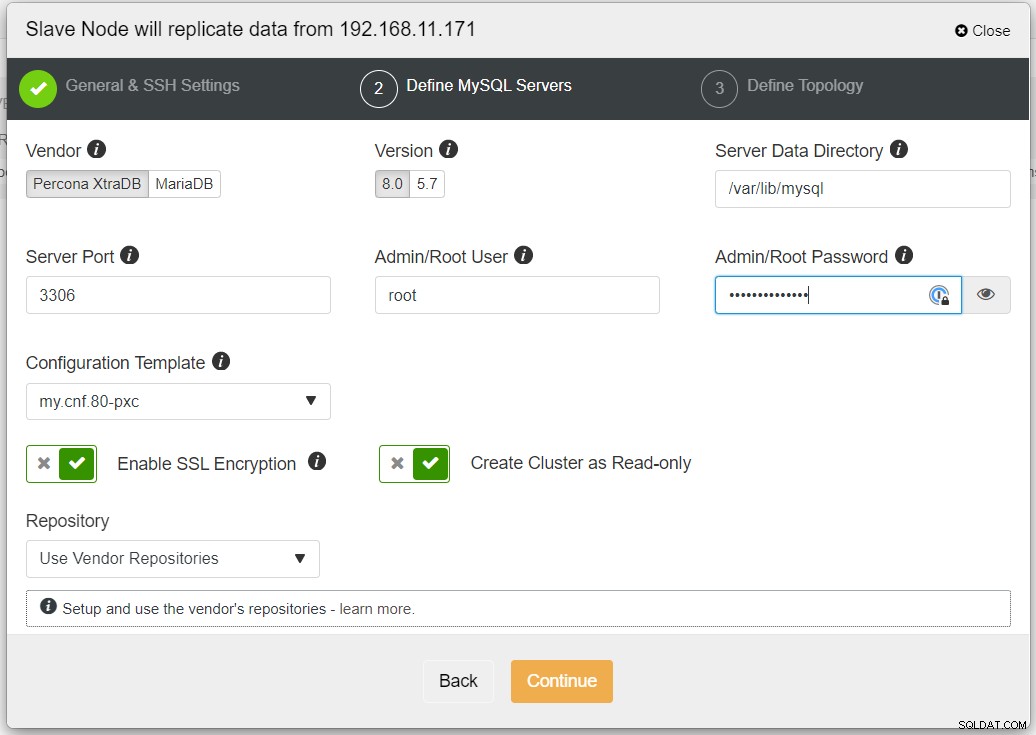
Se recomienda habilitar el cifrado SSL si la replicación involucra redes no confiables como WAN, redes sin túnel o Internet. Además, asegúrese de que esté activado "Crear clúster como de solo lectura"; esta es la protección contra escrituras accidentales y un buen indicador para distinguir fácilmente entre el clúster activo (lectura-escritura) y el clúster pasivo (solo lectura).
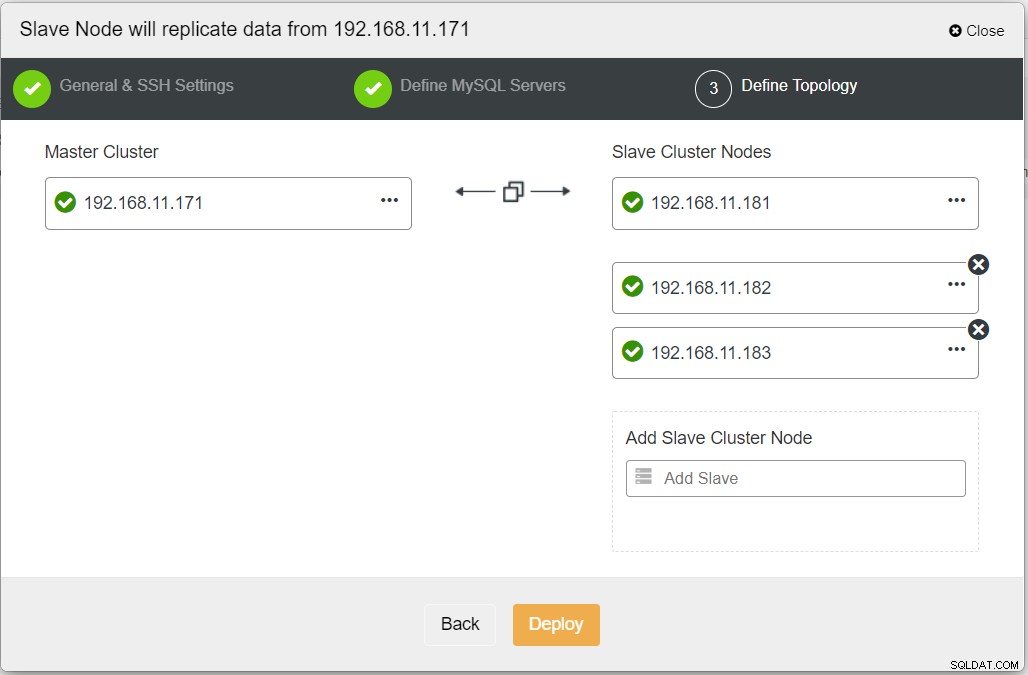
Al completar toda la información necesaria, debe llegar a la siguiente etapa para definir la topología del clúster de réplica:
Desde el panel de control de ClusterControl, una vez completada la implementación, debería ver el El sitio DR tiene una flecha bidireccional conectada con el sitio principal:
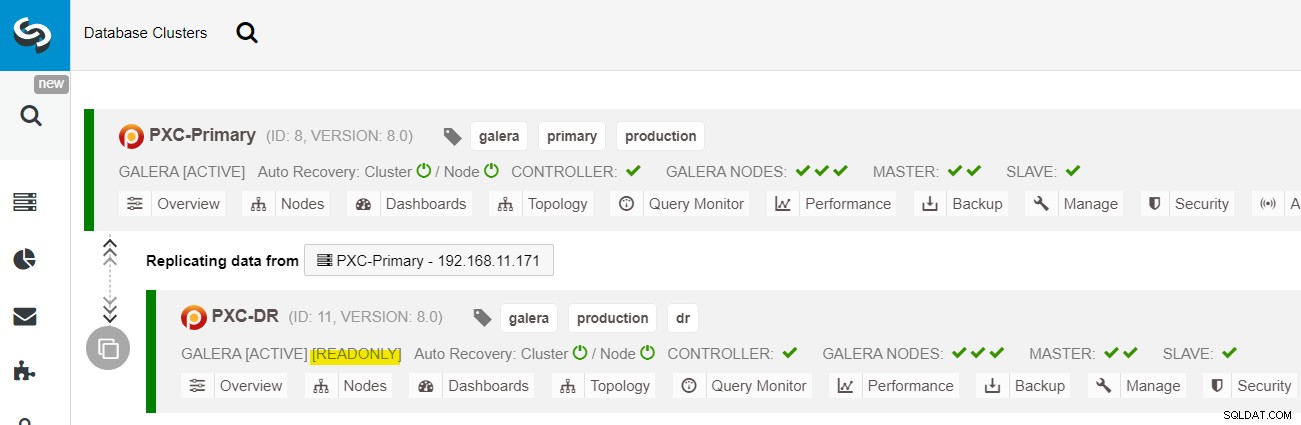
La implementación ahora está completa. Las aplicaciones deben enviar escrituras al sitio principal solo, ya que este es el sitio activo y el sitio DR está configurado para solo lectura (resaltado en amarillo). Las lecturas se pueden enviar a ambos sitios, aunque el sitio DR corre el riesgo de quedarse atrás debido a la naturaleza de replicación asíncrona. Esta configuración hará que los sitios principal y de recuperación ante desastres sean independientes entre sí, conectados libremente con la replicación asíncrona. Uno de los nodos de Galera en el sitio de DR será un esclavo que replica desde uno de los nodos de Galera (maestro) en el sitio principal.
Ahora tenemos un sistema en el que una falla de clúster en el sitio principal no afectará al sitio de respaldo. En cuanto al rendimiento, la latencia de la WAN no afectará las actualizaciones en el clúster activo. Estos se envían de forma asíncrona al sitio de copia de seguridad.
Como nota al margen, también es posible tener una instancia esclava dedicada como relé de replicación en lugar de usar uno de los nodos de Galera como esclavo.
Procedimiento de conmutación por error del nodo de Galera
En caso de que el maestro actual (galera1-P) falle y los nodos restantes en el sitio principal aún estén activos, el esclavo en el sitio de recuperación de desastres (galera1-DR) debe dirigirse a cualquier maestro disponible en el sitio principal, como se muestra en el siguiente diagrama:
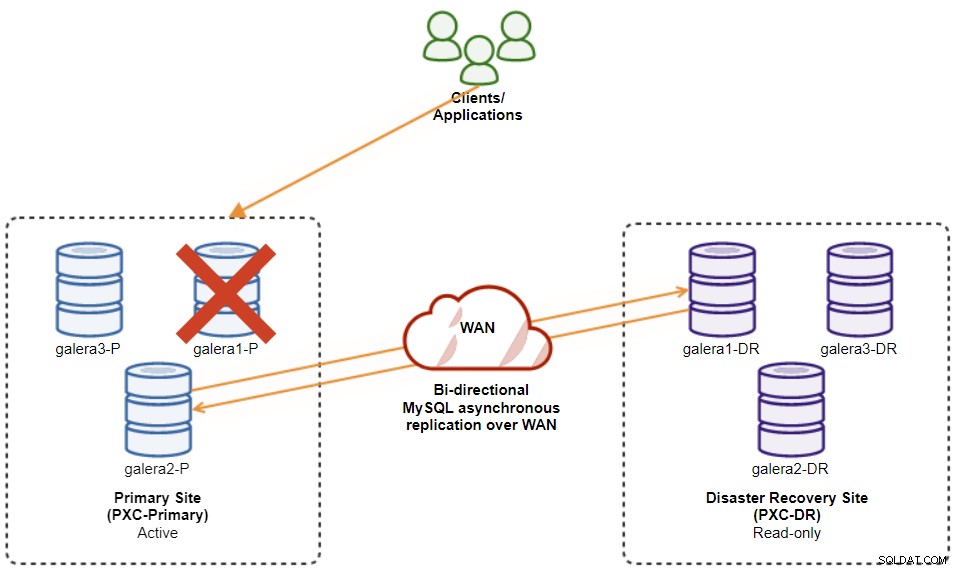
Desde la lista de clústeres de ClusterControl, puede ver que el estado del clúster está degradado , y si pasa el mouse sobre el ícono de signo de exclamación, puede ver el error para ese nodo en particular (galera1-P):
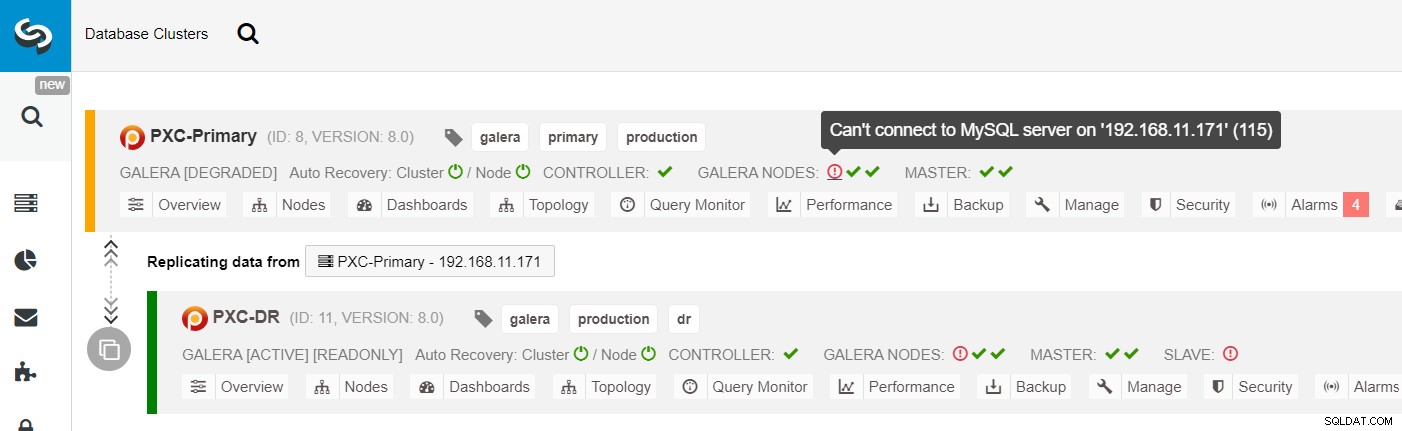
Con ClusterControl, simplemente puede ir al clúster PXC-DR → Nodos → elegir galera1-DR → Acciones de nodo → Reconstruir esclavo de replicación y aparecerá el siguiente cuadro de diálogo de configuración:
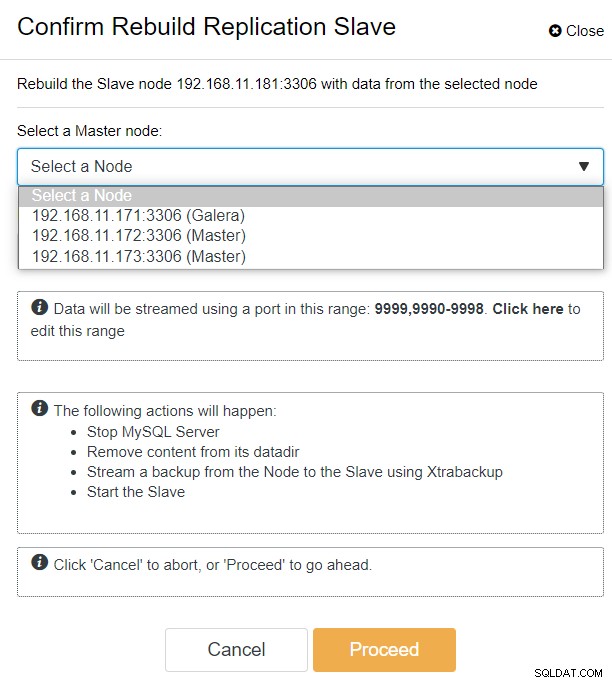
Podemos ver todos los nodos de Galera en el sitio principal (192.168.11.17x ) de la lista desplegable. Elija el nodo secundario, 192.168.11.172 (galera2-P), y haga clic en Continuar. Luego, ClusterControl configurará la topología de replicación como debe ser, configurando la replicación bidireccional de galera2-P a galera1-DR. Puede confirmar esto desde la página del panel de control del clúster (resaltado en amarillo):
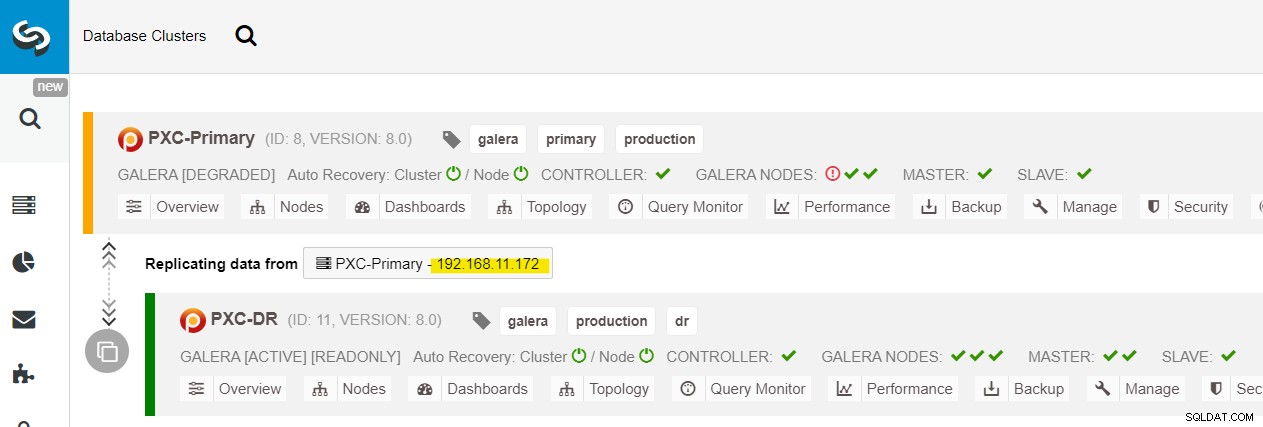
En este punto, el clúster primario (PXC-Primary) todavía está sirviendo como clúster activo para esta topología. No debería afectar el tiempo de actividad del servicio de la base de datos del clúster principal.
Procedimiento de conmutación por error del clúster de Galera
Si el clúster principal deja de funcionar, falla o simplemente pierde la conectividad desde el punto de vista de la aplicación, la aplicación se puede dirigir al sitio de recuperación ante desastres casi al instante. El SysAdmin simplemente necesita deshabilitar el modo de solo lectura en todos los nodos de Galera en el sitio de recuperación ante desastres usando la siguiente declaración:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRPara los usuarios de ClusterControl, puede usar la interfaz de usuario de ClusterControl → Nodos → elegir el nodo DB → Acciones de nodo → Deshabilitar solo lectura. La CLI de ClusterControl también está disponible ejecutando los siguientes comandos en el nodo de ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeLa conmutación por error al sitio DR ahora está completa y las aplicaciones pueden comenzar a enviar escrituras al clúster PXC-DR. Desde la interfaz de usuario de ClusterControl, debería ver algo como esto:
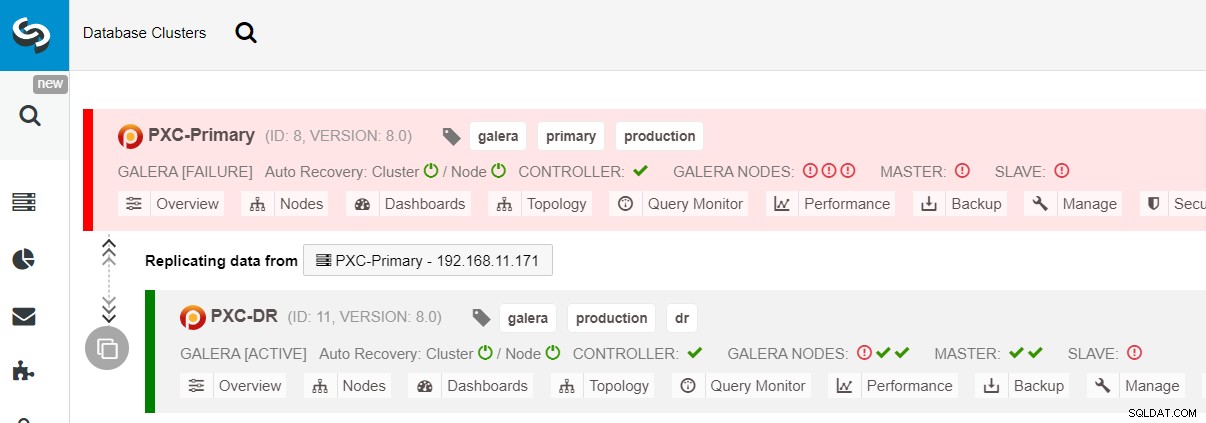
El siguiente diagrama muestra nuestra arquitectura después de que la aplicación fallara en el sitio DR :
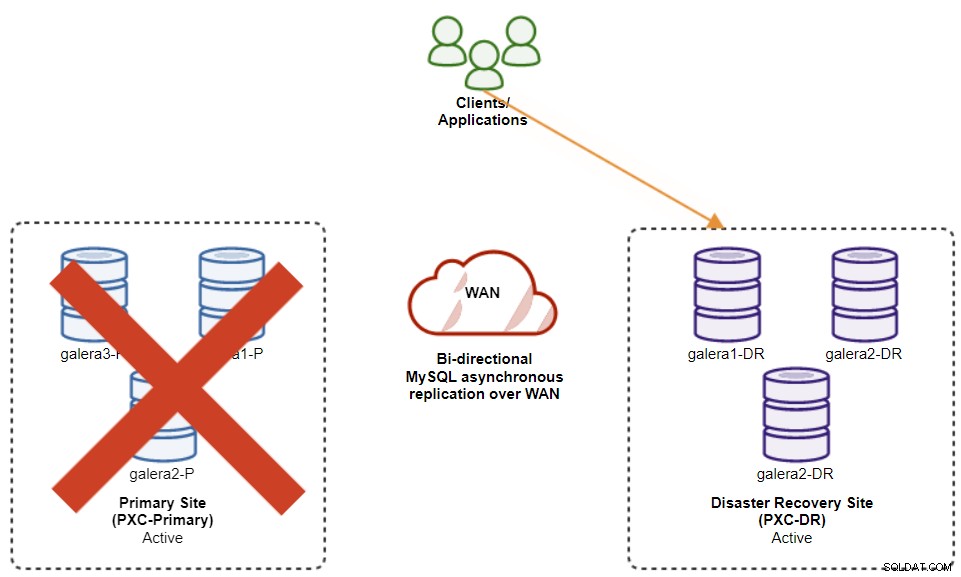
Suponiendo que el sitio principal todavía esté inactivo, en este momento no hay replicación entre sitios hasta que el sitio principal vuelva a funcionar.
Procedimiento de conmutación por recuperación del clúster de Galera
Después de que aparece el sitio principal, es importante tener en cuenta que el clúster principal debe configurarse como de solo lectura, para que sepamos que el clúster activo es el que se encuentra en el sitio de recuperación ante desastres. Desde ClusterControl, vaya al menú desplegable del clúster y elija "Habilitar solo lectura", lo que habilitará el solo lectura en todos los nodos del clúster principal y resumirá la topología actual de la siguiente manera:
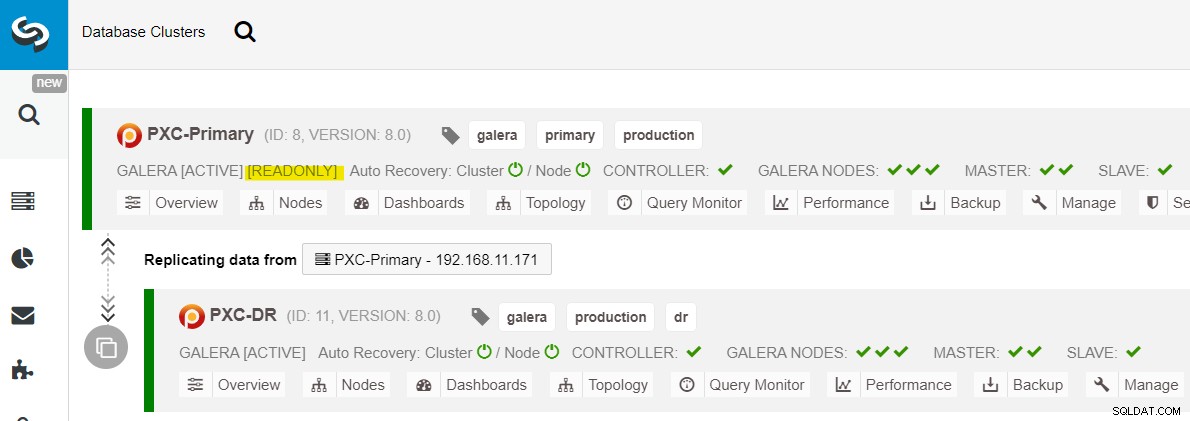
Asegúrese de que todo esté verde antes de planificar el inicio del procedimiento de conmutación por recuperación del clúster (verde significa que todos los nodos están activos y sincronizados entre sí). Si hay un nodo en estado de degradación, por ejemplo, el nodo de replicación todavía está retrasado o solo se pudo acceder a algunos de los nodos en el clúster principal, espere hasta que el clúster se recupere por completo, ya sea esperando los procedimientos de recuperación automática de ClusterControl. para completar, o intervención manual.
En este punto, el clúster activo sigue siendo el clúster de DR y el clúster principal actúa como un clúster secundario. El siguiente diagrama ilustra la arquitectura actual:
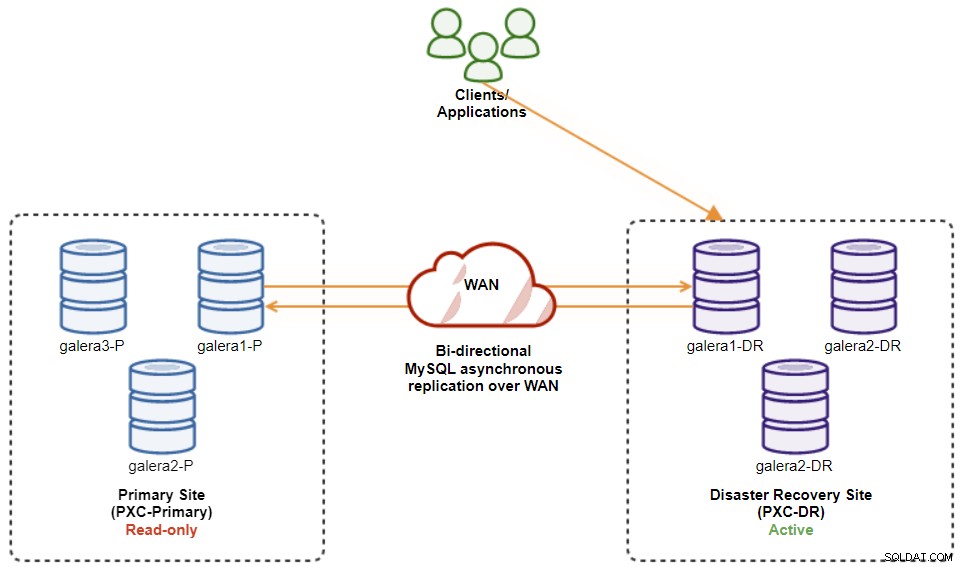
La forma más segura de conmutación por recuperación al sitio principal es configurar solo lectura en el clúster de DR, seguido de la desactivación de solo lectura en el sitio principal. Vaya a la interfaz de usuario de ClusterControl → PXC-DR (menú desplegable) → Habilitar solo lectura. Esto activará un trabajo para configurar el modo de solo lectura en todos los nodos del clúster de DR. Luego, vaya a Interfaz de usuario de ClusterControl → PXC-Primary → Nodes, y deshabilite el modo de solo lectura en todos los nodos de la base de datos en el clúster principal.
También puede simplificar los procedimientos anteriores con ClusterControl CLI. Como alternativa, ejecute los siguientes comandos en el host de ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeUna vez hecho esto, la dirección de replicación ha vuelto a su configuración original, donde PXC-Primary es el clúster activo y PXC-DR es el clúster en espera. El siguiente diagrama ilustra la arquitectura final después de la operación de conmutación por recuperación del clúster:
En este punto, ahora es seguro redirigir las aplicaciones para escribir el sitio principal.
Ventajas de la replicación asincrónica de clúster a clúster
Cluster-to-cluster con replicación asíncrona viene con una serie de ventajas:
-
Tiempo de inactividad mínimo durante una operación de conmutación por error de la base de datos. Básicamente, puede redirigir la escritura casi instantáneamente al sitio esclavo, solo si puede proteger las escrituras para que no lleguen al sitio maestro (ya que estas escrituras no se replicarían y probablemente se sobrescribirán cuando se vuelvan a sincronizar desde el sitio DR).
-
No hay impacto en el rendimiento del sitio principal, ya que es independiente del sitio de respaldo (DR). La replicación de maestro a esclavo se realiza de forma asíncrona. El sitio maestro genera registros binarios, el sitio esclavo replica los eventos y los aplica en algún momento posterior.
-
Los sitios de recuperación ante desastres se pueden usar para otros fines, por ejemplo, respaldo de bases de datos, respaldo de registros binarios e informes, o consultas analíticas pesadas (OLAP). Ambos sitios se pueden usar simultáneamente, excepto por el retraso de la replicación y las operaciones de solo lectura en el lado esclavo.
-
El clúster de recuperación ante desastres podría ejecutarse potencialmente en instancias más pequeñas en un entorno de nube pública, siempre que puedan mantenerse al día con el grupo primario. Puede actualizar las instancias si es necesario. En ciertos escenarios, puede ahorrarle algunos costos.
-
Solo necesita un sitio adicional para la recuperación ante desastres en comparación con la configuración de replicación multisitio activo-activo de Galera, que requiere al menos tres sitios activos para funcionar correctamente.
Desventajas de la replicación asincrónica de clúster a clúster
También existen inconvenientes en esta configuración, dependiendo de si está utilizando replicación bidireccional o unidireccional:
-
Existe la posibilidad de perder algunos datos durante la conmutación por error si el esclavo estaba retrasado, ya que la replicación es asíncrona. Esto podría mejorarse con la replicación de esclavos semisincrónicos y de subprocesos múltiples, aunque habrá otro conjunto de desafíos esperando (sobrecarga de la red, brecha de replicación, etc.).
-
En la replicación unidireccional, a pesar de que los procedimientos de conmutación por error son bastante simples, los procedimientos de conmutación por recuperación pueden ser complicados y propensos a errores humanos. error. Requiere algo de experiencia en cambiar el rol maestro/esclavo de regreso al sitio principal. Se recomienda mantener los procedimientos documentados, ensayar la operación de conmutación por error/recuperación con regularidad y utilizar herramientas precisas de supervisión e informes.
-
Puede ser bastante costoso, ya que debe configurar una cantidad similar de nodos en el sitio de recuperación ante desastres . Esto no es blanco y negro, ya que la justificación del costo generalmente proviene de los requisitos de su negocio. Con algo de planificación, es posible maximizar el uso de los recursos de la base de datos en ambos sitios, independientemente de las funciones de la base de datos.
Conclusión
Configurar la replicación asíncrona para sus MySQL Galera Clusters puede ser un proceso relativamente sencillo, siempre y cuando comprenda cómo manejar correctamente las fallas tanto a nivel de nodo como de clúster. En última instancia, las operaciones de conmutación por error y conmutación por recuperación son fundamentales para garantizar la integridad de los datos.
Para obtener más sugerencias sobre cómo diseñar sus clústeres de Galera teniendo en cuenta las estrategias de conmutación por error y conmutación por recuperación, consulte esta publicación sobre arquitecturas MySQL para recuperación ante desastres. Si está buscando ayuda para automatizar estas operaciones, evalúe ClusterControl gratis durante 30 días y siga los pasos de esta publicación.
No olvide seguirnos en Twitter o LinkedIn y suscríbase a nuestro boletín para mantenerse actualizado sobre las últimas noticias y las mejores prácticas para administrar sus infraestructuras de bases de datos de código abierto.