En esta publicación de blog, analizaremos 6 escenarios de falla diferentes en los sistemas de bases de datos de producción, que van desde problemas de un solo servidor hasta planes de conmutación por error de múltiples centros de datos. Lo guiaremos a través de los procedimientos de recuperación y conmutación por error para el escenario respectivo. Con suerte, esto le dará una buena comprensión de los riesgos que podría enfrentar y las cosas que debe considerar al diseñar su infraestructura.
Esquema de base de datos dañado
Comencemos con la instalación de un solo nodo:una configuración de base de datos en la forma más simple. Fácil de implementar, al menor costo. En este escenario, ejecuta varias aplicaciones en un solo servidor donde cada uno de los esquemas de la base de datos pertenece a la aplicación diferente. El enfoque para la recuperación de un solo esquema dependería de varios factores.
- ¿Tengo alguna copia de seguridad?
- ¿Tengo una copia de seguridad y qué tan rápido puedo restaurarla?
- ¿Qué tipo de motor de almacenamiento está en uso?
- ¿Tengo una copia de seguridad compatible con PITR (recuperación de un punto en el tiempo)?
mysqlcheck puede identificar la corrupción de datos.
mysqlcheck -uroot -p <DATABASE>Reemplace BASE DE DATOS con el nombre de la base de datos y reemplace TABLA con el nombre de la tabla que desea verificar:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck comprueba la base de datos y las tablas especificadas. Si una tabla pasa la verificación, mysqlcheck muestra OK para la tabla. En el siguiente ejemplo, podemos ver que la tabla salarios requiere recuperación.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKPara una instalación de un solo nodo sin servidores DR adicionales, el enfoque principal sería restaurar los datos desde la copia de seguridad. Pero esto no es lo único que debes tener en cuenta. Tener varios esquemas de base de datos bajo la misma instancia causa un problema cuando tiene que apagar su servidor para restaurar los datos. Otra pregunta es si puede darse el lujo de revertir todas sus bases de datos a la última copia de seguridad. En la mayoría de los casos, eso no sería posible.
Hay algunas excepciones aquí. Es posible restaurar una sola tabla o base de datos desde la última copia de seguridad cuando no se necesita la recuperación de un momento dado. Tal proceso es más complicado. Si tiene mysqldump, puede extraer su base de datos de él. Si ejecuta copias de seguridad binarias con xtradbackup o mariabackup y ha habilitado la tabla por archivo, entonces es posible.
Aquí se explica cómo verificar si tiene habilitada una opción de tabla por archivo.
mysql> SET GLOBAL innodb_file_per_table=1; Con innodb_file_per_table habilitado, puede almacenar tablas de InnoDB en un archivo tbl_name .ibd. A diferencia del motor de almacenamiento MyISAM, con sus archivos tbl_name .MYD y tbl_name .MYI separados para índices y datos, InnoDB almacena los datos y los índices juntos en un solo archivo .ibd. Para verificar su motor de almacenamiento, debe ejecutar:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';o directamente desde la consola:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Para restaurar tablas desde xtradbackup, debe pasar por un proceso de exportación. La copia de seguridad debe prepararse antes de poder restaurarla. La exportación se realiza en la etapa de preparación. Una vez que se crea una copia de seguridad completa, ejecute el procedimiento de preparación estándar con el indicador adicional --export :
innobackupex --apply-log --export /u01/backupEsto creará archivos de exportación adicionales que utilizará más adelante en la fase de importación. Para importar una tabla a otro servidor, primero cree una nueva tabla con la misma estructura que la que se importará en ese servidor:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;descartar el espacio de tablas:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Luego copie los archivos mytable.ibd y mytable.exp en el hogar de la base de datos e importe su tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Sin embargo, para hacer esto de una manera más controlada, la recomendación sería restaurar una copia de seguridad de la base de datos en otra instancia/servidor y copiar lo que se necesita al sistema principal. Para hacerlo, debe ejecutar la instalación de la instancia de mysql. Esto podría hacerse en la misma máquina, pero requiere más esfuerzo para configurar de manera que ambas instancias puedan ejecutarse en la misma máquina; por ejemplo, eso requeriría diferentes configuraciones de comunicación.
Puede combinar la restauración y la instalación de tareas mediante ClusterControl.
ClusterControl lo guiará a través de las copias de seguridad disponibles en las instalaciones o en la nube, le permitirá elegir la hora exacta para una restauración o la posición precisa del registro e instalar una nueva instancia de base de datos si es necesario.
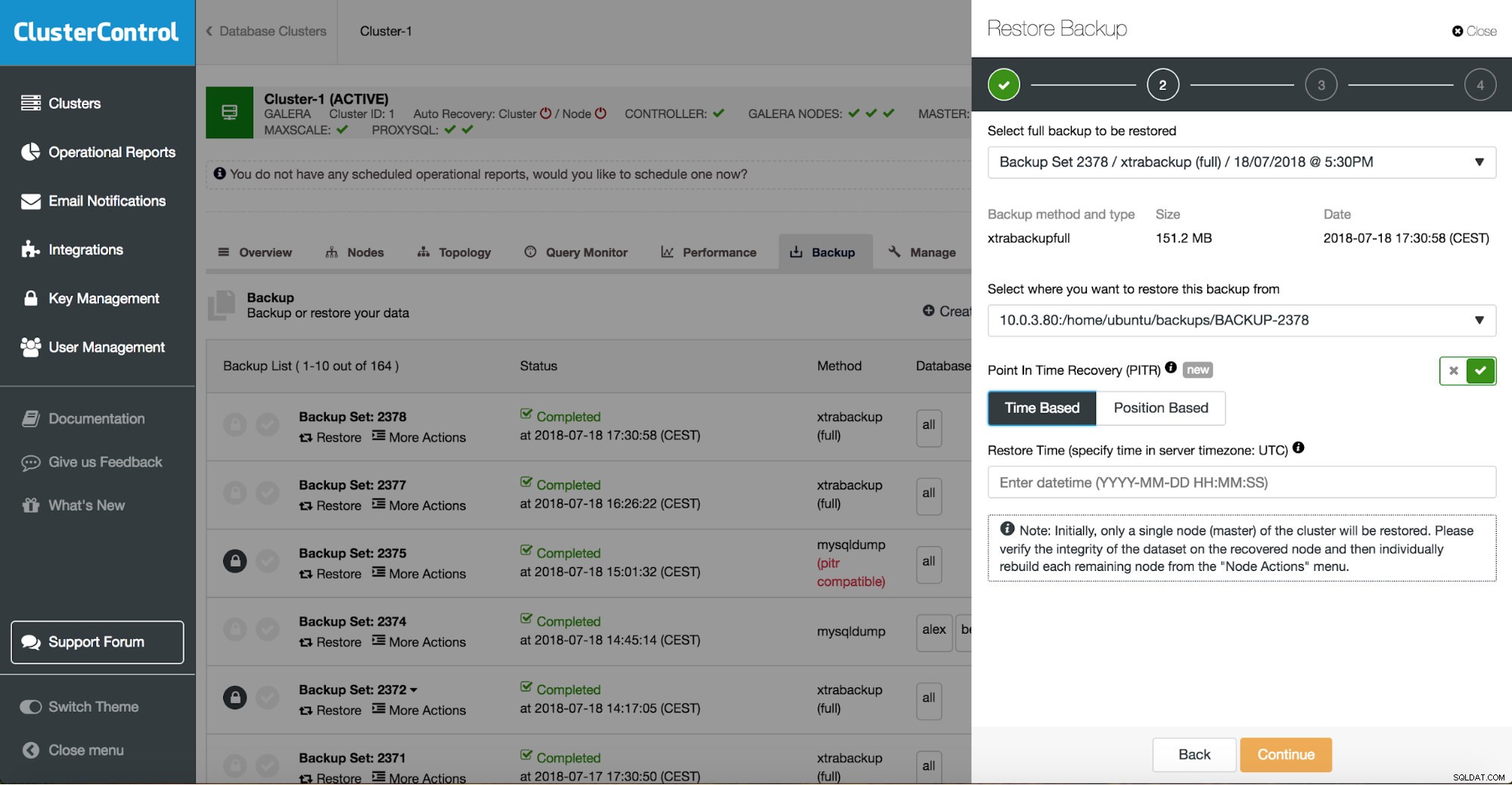 Recuperación puntual de ClusterControl
Recuperación puntual de ClusterControl 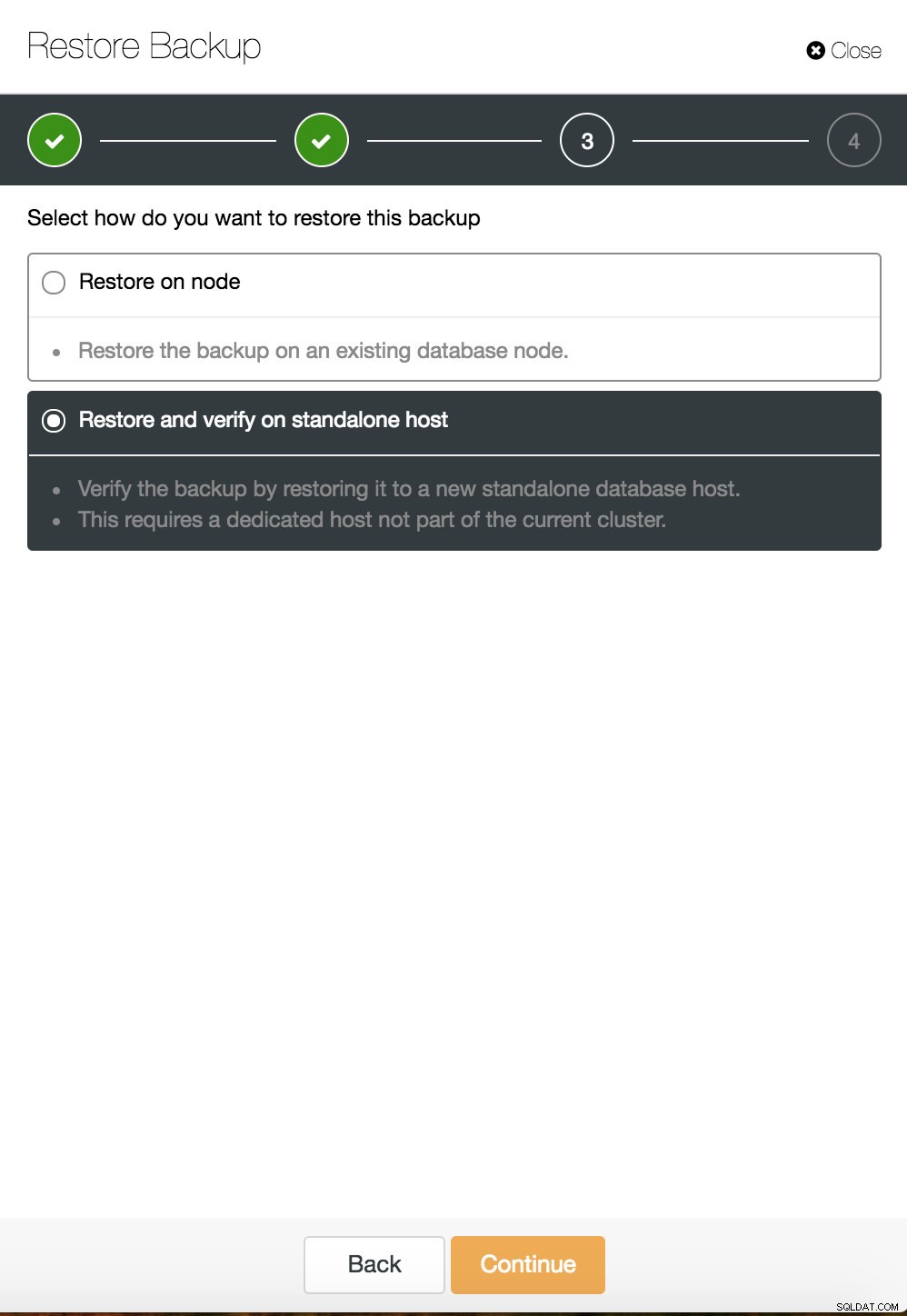 Restauración y verificación de ClusterControl en un host independiente
Restauración y verificación de ClusterControl en un host independiente 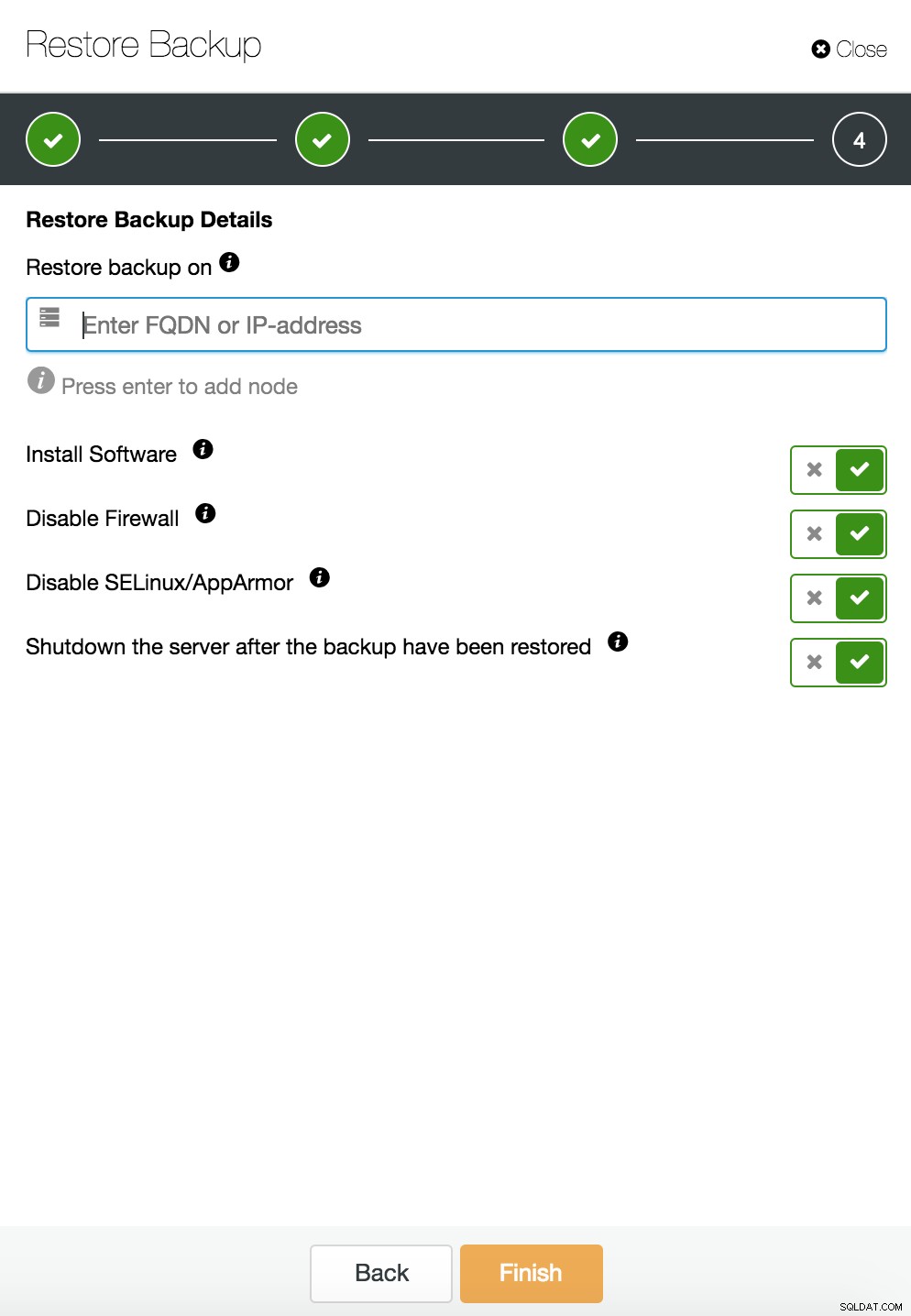 Restauración y verificación de CusterControl en un host independiente. Opciones de instalación.
Restauración y verificación de CusterControl en un host independiente. Opciones de instalación. Puede encontrar más información sobre la recuperación de datos en el blog Mi base de datos MySQL está dañada... ¿Qué hago ahora?
Instancia de base de datos dañada en el servidor dedicado
Los defectos en la plataforma subyacente son a menudo la causa de la corrupción de la base de datos. Su instancia de MySQL se basa en varias cosas para almacenar y recuperar datos:subsistema de disco, controladores, canales de comunicación, controladores y firmware. Un bloqueo puede afectar partes de sus datos, archivos binarios mysql o incluso archivos de copia de seguridad que almacena en el sistema. Para separar diferentes aplicaciones, puede ubicarlas en servidores dedicados.
Diferentes esquemas de aplicación en sistemas separados son una buena idea si puede permitírselos. Se puede decir que esto es un desperdicio de recursos, pero existe la posibilidad de que el impacto comercial sea menor si solo uno de ellos falla. Pero incluso entonces, necesita proteger su base de datos de la pérdida de datos. Almacenar la copia de seguridad en el mismo servidor no es una mala idea siempre que tenga una copia en otro lugar. Actualmente, el almacenamiento en la nube es una excelente alternativa a la copia de seguridad en cinta.
ClusterControl le permite mantener una copia de su copia de seguridad en la nube. Admite la carga a los 3 principales proveedores de la nube:Amazon AWS, Google Cloud y Microsoft Azure.
Cuando haya restaurado su copia de seguridad completa, es posible que desee restaurarla a un momento determinado. La recuperación de un punto en el tiempo actualizará el servidor a un momento más reciente que cuando se realizó la copia de seguridad completa. Para hacerlo, debe tener habilitados los registros binarios. Puede consultar los registros binarios disponibles con:
mysql> SHOW BINARY LOGS;Y el archivo de registro actual con:
SHOW MASTER STATUS;Luego puede capturar datos incrementales pasando registros binarios al archivo sql. Las operaciones que faltan se pueden volver a ejecutar.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outLo mismo se puede hacer en ClusterControl.
 Copia de seguridad en la nube de ClusterControl
Copia de seguridad en la nube de ClusterControl  Copia de seguridad en la nube de ClusterControl
Copia de seguridad en la nube de ClusterControl El esclavo de la base de datos se cae
Ok, entonces tienes tu base de datos ejecutándose en un servidor dedicado. Creó un programa de copia de seguridad sofisticado con una combinación de copias de seguridad completas e incrementales, cárguelas en la nube y almacene la copia de seguridad más reciente en discos locales para una recuperación rápida. Tiene diferentes políticas de retención de copias de seguridad:más cortas para las copias de seguridad almacenadas en controladores de disco locales y más amplias para las copias de seguridad en la nube.
Parece que estás bien preparado para un escenario de desastre. Pero cuando se trata del tiempo de restauración, es posible que no satisfaga sus necesidades comerciales.
Necesita una función de conmutación por error rápida. Un servidor que estará en funcionamiento aplicando registros binarios del maestro donde ocurren las escrituras. La replicación maestro/esclavo inicia un nuevo capítulo en el escenario de conmutación por error. Es un método rápido para que su aplicación vuelva a la vida si su maestro deja de funcionar.
Pero hay algunas cosas a considerar en el escenario de conmutación por error. Una es configurar un esclavo de replicación retrasada, para que pueda reaccionar a los comandos fat finger que se activaron en el servidor maestro. Un servidor esclavo puede retrasarse con respecto al maestro al menos una cantidad de tiempo específica. El retraso predeterminado es de 0 segundos. Use la opción MASTER_DELAY para CHANGE MASTER TO para establecer el retraso en N segundos:
CHANGE MASTER TO MASTER_DELAY = N;El segundo es habilitar la conmutación por error automatizada. Hay muchas soluciones automatizadas de conmutación por error en el mercado. Puede configurar la conmutación por error automática con herramientas de línea de comandos como MHA, MRM, mysqlfailover o GUI Orchestrator y ClusterControl. Cuando está configurado correctamente, puede reducir significativamente su interrupción.
ClusterControl admite la conmutación por error automatizada para las replicaciones de MySQL, PostgreSQL y MongoDB, así como las soluciones de clúster multimaestro Galera y NDB.
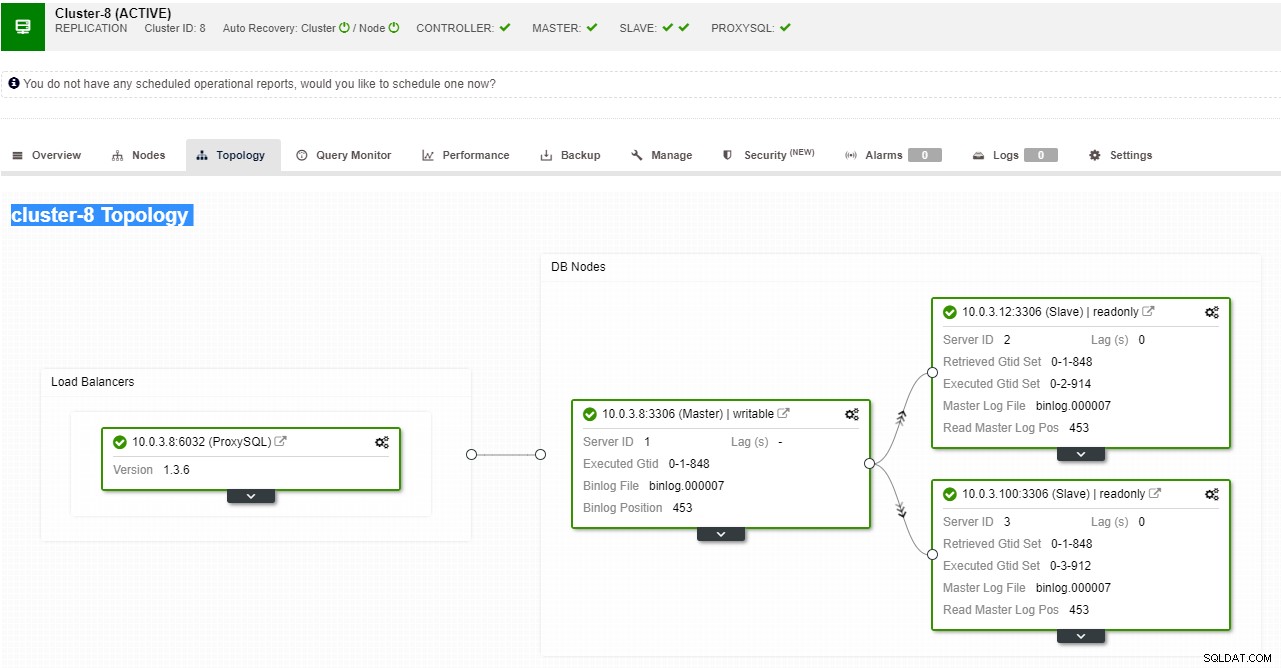 Vista de topología de replicación de ClusterControl
Vista de topología de replicación de ClusterControl Cuando un nodo esclavo falla y el servidor se está retrasando mucho, es posible que desee reconstruir su servidor esclavo. El proceso de reconstrucción del esclavo es similar a la restauración desde una copia de seguridad.
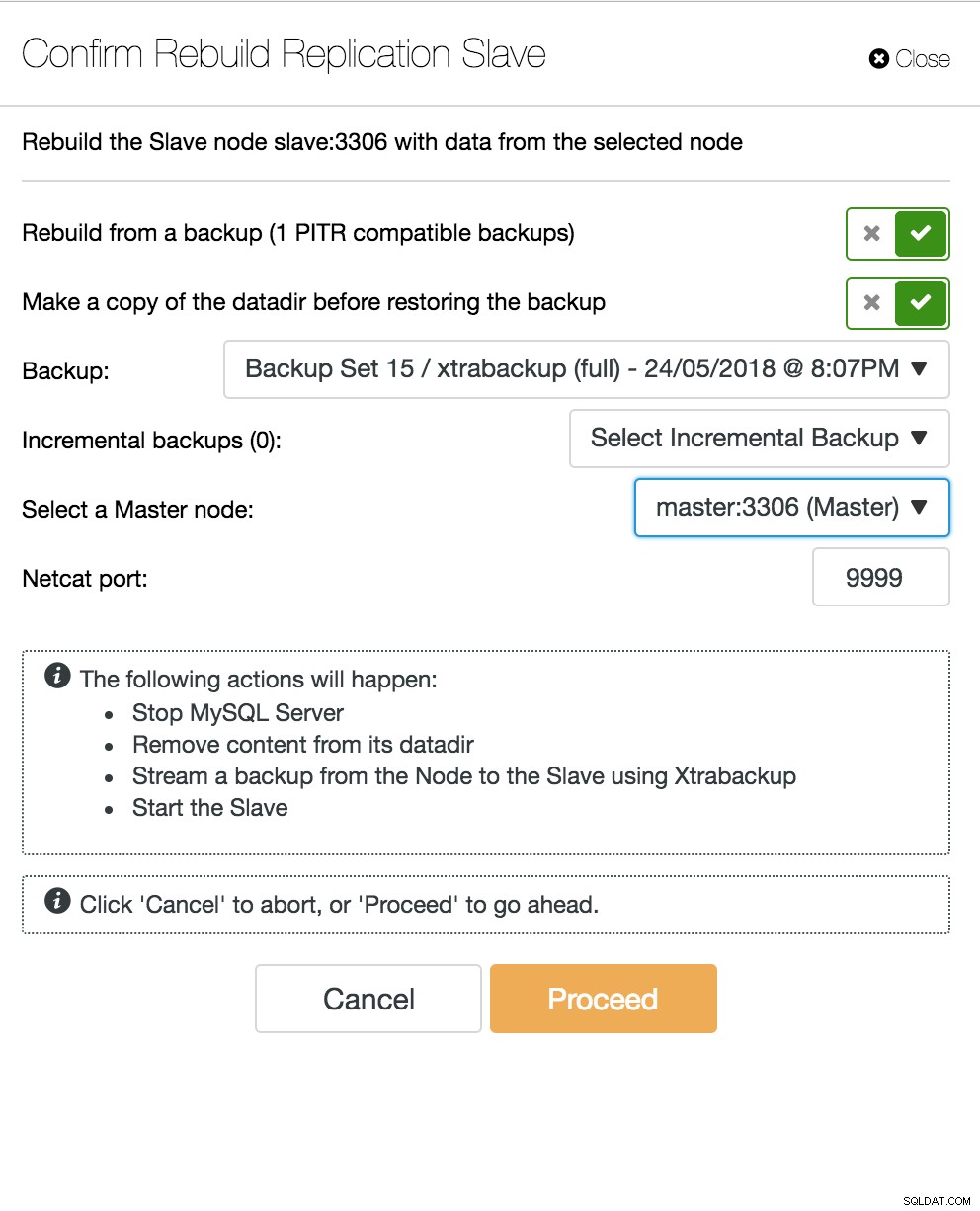 Esclavo de reconstrucción de ClusterControl
Esclavo de reconstrucción de ClusterControl El servidor multimaestro de la base de datos se cae
Ahora, cuando tiene un servidor esclavo que actúa como un nodo DR y su proceso de conmutación por error está bien automatizado y probado, su vida como DBA se vuelve más cómoda. Eso es cierto, pero hay algunos acertijos más para resolver. El poder de cómputo no es gratis, y su equipo comercial puede pedirle que utilice mejor su hardware, es posible que desee usar su servidor esclavo no solo como servidor pasivo, sino también para servir operaciones de escritura.
Es posible que desee investigar una solución de replicación multimaestro. Galera Cluster se ha convertido en una opción principal para MySQL y MariaDB de alta disponibilidad. Y aunque ahora se conoce como un reemplazo creíble para las arquitecturas maestro-esclavo tradicionales de MySQL, no es un reemplazo directo.
El clúster de Galera tiene una arquitectura de nada compartido. En lugar de discos compartidos, Galera utiliza la replicación basada en certificación con comunicación grupal y ordenación de transacciones para lograr la replicación síncrona. Un clúster de base de datos debería poder sobrevivir a la pérdida de un nodo, aunque se logra de diferentes maneras. En el caso de Galera, el aspecto crítico es el número de nodos. Galera requiere quórum para mantenerse operativa. Un clúster de tres nodos puede sobrevivir al bloqueo de un nodo. Con más nodos en su clúster, puede sobrevivir a más fallas.
El proceso de recuperación está automatizado, por lo que no necesita realizar ninguna operación de conmutación por error. Sin embargo, la buena práctica sería matar nodos y ver qué tan rápido puede recuperarlos. Para que esta operación sea más eficiente, puede modificar el tamaño de caché de galera. Si el tamaño de la memoria caché de galera no se planifica correctamente, su próximo nodo de arranque deberá realizar una copia de seguridad completa en lugar de solo perder conjuntos de escritura en la memoria caché.
El escenario de conmutación por error es tan simple como iniciar la instancia. En función de los datos en la caché de galera, el nodo de arranque realizará SST (restauración desde una copia de seguridad completa) o IST (aplicación de conjuntos de escritura faltantes). Sin embargo, esto a menudo está relacionado con la intervención humana. Si desea automatizar todo el proceso de conmutación por error, puede utilizar la funcionalidad de recuperación automática de ClusterControl (nivel de nodo y clúster).
 Recuperación automática de clústeres de ClusterControl
Recuperación automática de clústeres de ClusterControl Estimar tamaño de caché de galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Para que la conmutación por error sea más uniforme, debe habilitar gcache.recover=yes en mycnf. Esta opción reactivará la caché de galera al reiniciar. Esto significa que el nodo puede actuar como DONANTE y dar servicio a los conjuntos de escritura faltantes (facilitando IST, en lugar de usar SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3El nodo de proxy SQL se cae
Si tiene una configuración de IP virtual, todo lo que tiene que hacer es apuntar su aplicación a la dirección IP virtual y todo debería ser correcto en cuanto a la conexión. No basta con que las instancias de su base de datos abarquen varios centros de datos, aún necesita sus aplicaciones para acceder a ellas. Supongamos que ha escalado el número de réplicas de lectura, es posible que desee implementar IP virtuales para cada una de esas réplicas de lectura también por motivos de mantenimiento o disponibilidad. Podría convertirse en un grupo engorroso de direcciones IP virtuales que debe administrar. Si una de esas réplicas de lectura se bloquea, debe reasignar la IP virtual al host diferente o, de lo contrario, su aplicación se conectará a un host que está inactivo o, en el peor de los casos, a un servidor retrasado con datos obsoletos.
 Vista de topología de balanceadores de carga HA de ClusterControl
Vista de topología de balanceadores de carga HA de ClusterControl Los bloqueos no son frecuentes, pero son más probables que los servidores se caigan. Si por alguna razón, un esclavo falla, algo como ProxySQL redirigirá todo el tráfico al maestro, con el riesgo de sobrecargarlo. Cuando el esclavo se recupere, el tráfico se redirigirá a él. Por lo general, dicho tiempo de inactividad no debería durar más de un par de minutos, por lo que la gravedad general es media, aunque la probabilidad también es media.
Para que los componentes de su balanceador de carga sean redundantes, puede usar keepalived.
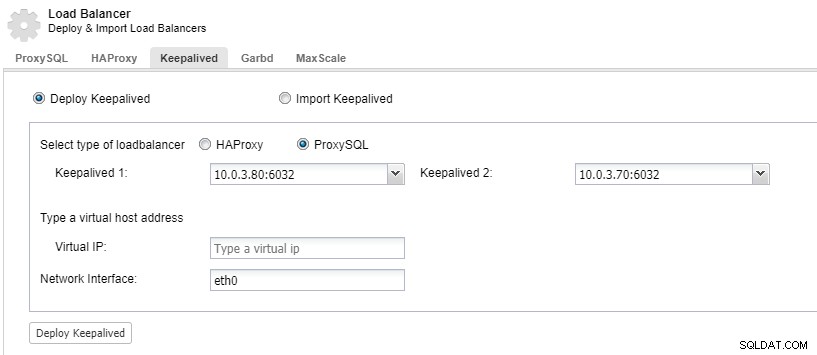 ClusterControl:implemente keepalived para el balanceador de carga de ProxySQL
ClusterControl:implemente keepalived para el balanceador de carga de ProxySQL El centro de datos se cae
El principal problema con la replicación es que no existe un mecanismo mayoritario para detectar una falla en el centro de datos y servir a un nuevo maestro. Una de las resoluciones es usar Orchestrator/Raft. Orchestrator es un supervisor de topología que puede controlar las conmutaciones por error. Cuando se usa junto con Raft, Orchestrator se volverá consciente del quórum. Una de las instancias de Orchestrator se elige como líder y ejecuta las tareas de recuperación. La conexión entre el nodo del orquestador no se correlaciona con las confirmaciones de bases de datos transaccionales y es escasa.
Orchestrator/Raft puede usar instancias adicionales que realizan el monitoreo de la topología. En el caso de la partición de la red, las instancias de Orchestrator particionadas no realizarán ninguna acción. La parte del clúster de Orchestrator que tenga el quórum elegirá un nuevo maestro y realizará los cambios de topología necesarios.
ClusterControl se utiliza para la administración, el escalado y, lo que es más importante, la recuperación de nodos:Orchestrator manejaría las conmutaciones por error, pero si un esclavo fallara, ClusterControl se asegurará de que se recupere. Orchestrator y ClusterControl estarían ubicados en la misma zona de disponibilidad, separados de los nodos de MySQL, para garantizar que su actividad no se vea afectada por divisiones de red entre zonas de disponibilidad en el centro de datos.



