Es bastante común ver bases de datos distribuidas en varias ubicaciones geográficas. Un escenario para realizar este tipo de configuración es para la recuperación ante desastres, donde su centro de datos en espera está ubicado en una ubicación separada de su centro de datos principal. También podría ser necesario para que las bases de datos estén ubicadas más cerca de los usuarios.
El principal desafío para lograr esta configuración es diseñar la base de datos de manera que reduzca la posibilidad de problemas relacionados con la partición de la red. Una de las soluciones podría ser usar Galera Cluster en lugar de la replicación asíncrona (o semi-síncrona) normal. En este blog discutiremos los pros y los contras de este enfoque. Esta es la primera parte de una serie de dos blogs. En la segunda parte, diseñaremos el Galera Cluster geodistribuido y veremos cómo ClusterControl puede ayudarnos a implementar dicho entorno.
¿Por qué Galera Cluster en lugar de la replicación asincrónica para clústeres distribuidos geográficamente?
Veamos las principales diferencias entre Galera y la replicación normal. La replicación regular le proporciona un solo nodo en el que escribir, lo que significa que cada escritura desde el centro de datos remoto tendría que enviarse a través de la red de área amplia (WAN) para llegar al maestro. También significa que todos los proxies ubicados en el centro de datos remoto deberán poder monitorear toda la topología, abarcando todos los centros de datos involucrados, ya que deben poder saber qué nodo es actualmente el maestro.
Esto lleva a la cantidad de problemas. En primer lugar, se deben establecer múltiples conexiones a través de la WAN, esto agrega latencia y ralentiza las comprobaciones que el proxy pueda estar ejecutando. Además, esto agrega una sobrecarga innecesaria en los proxies y las bases de datos. La mayoría de las veces, solo le interesa enrutar el tráfico a los nodos de la base de datos local. La única excepción es el maestro y solo debido a esto, los proxies se ven obligados a vigilar toda la infraestructura en lugar de solo la parte ubicada en el centro de datos local. Por supuesto, puede intentar superar esto usando proxies para enrutar solo SELECT, mientras usa algún otro método (nombre de host dedicado para maestro administrado por DNS) para apuntar la aplicación al maestro, pero esto agrega niveles innecesarios de complejidad y partes móviles, que podría afectar seriamente su capacidad para manejar múltiples fallas de nodos y redes sin perder la consistencia de los datos.
Galera Cluster puede admitir múltiples escritores. La latencia también es un factor, ya que todos los nodos en el clúster de Galera tienen que coordinarse y comunicarse para certificar conjuntos de escritura, incluso puede ser la razón por la que puede decidir no usar Galera cuando la latencia es demasiado alta. También es un problema en los clústeres de replicación:en los clústeres de replicación, la latencia afecta solo a las escrituras desde los centros de datos remotos, mientras que las conexiones desde el centro de datos donde se encuentra el maestro se beneficiarían de confirmaciones de baja latencia.
En MySQL Replication también debe tener en cuenta el peor de los casos y asegurarse de que la aplicación esté bien con escrituras retrasadas. El maestro siempre puede cambiar y no puede estar seguro de que todo el tiempo estará escribiendo en un nodo local.
Otra diferencia entre la replicación y Galera Cluster es el manejo del retraso de la replicación. Los clústeres distribuidos geográficamente pueden verse seriamente afectados por el retraso:latencia, rendimiento limitado de la conexión WAN, todo esto afectará la capacidad de un clúster replicado para mantenerse al día con la replicación. Tenga en cuenta que la replicación genera uno para todo el tráfico.
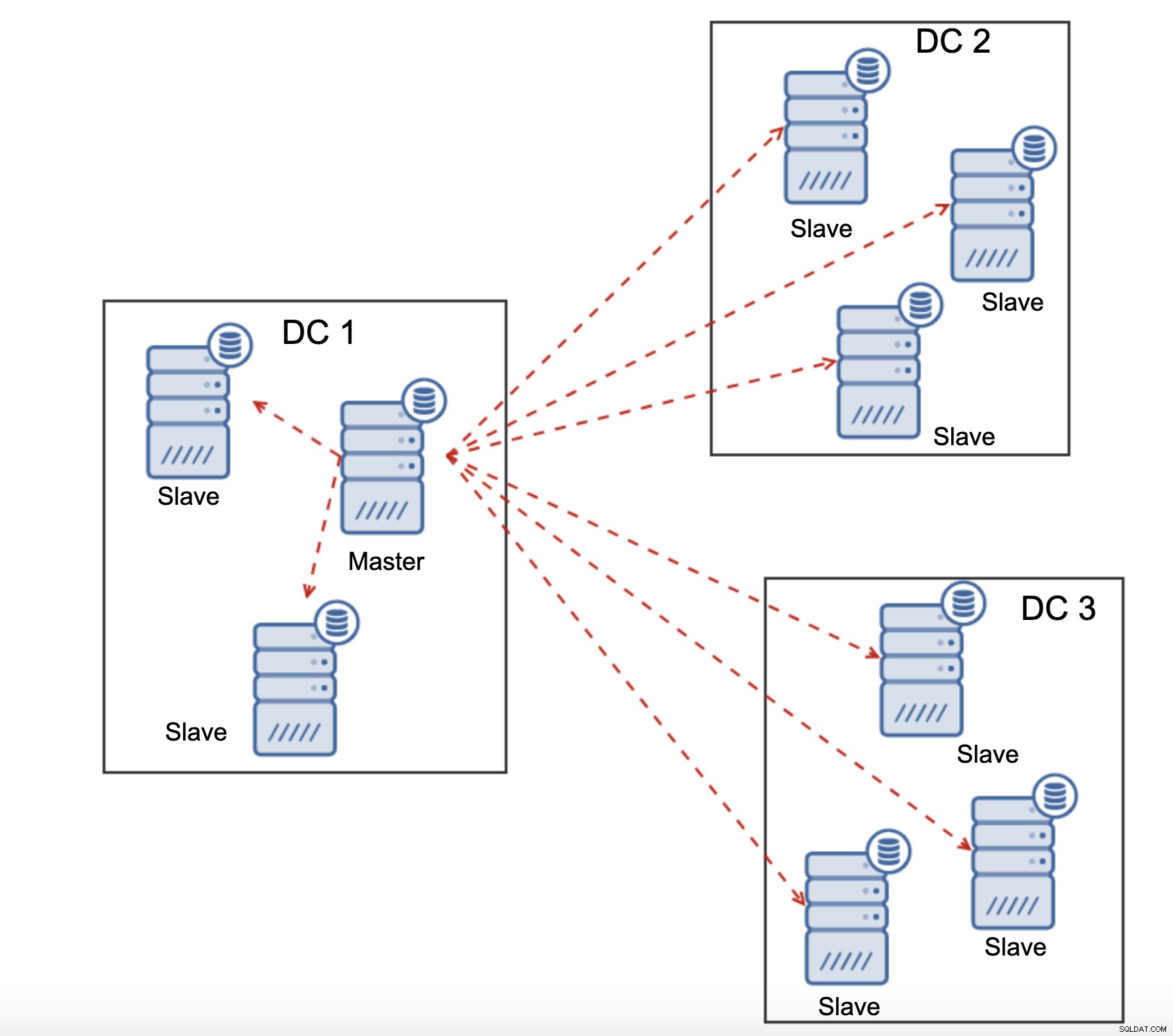
Todos los esclavos deben recibir todo el tráfico de replicación:la cantidad de datos que tiene para enviar a esclavos remotos a través de WAN aumenta con cada esclavo remoto que agregue. Esto puede resultar fácilmente en la saturación del enlace WAN, especialmente si realiza muchas modificaciones y el enlace WAN no tiene un buen rendimiento. Como puede ver en el diagrama anterior, con tres centros de datos y tres nodos en cada uno de ellos, el maestro tiene que enviar 6 veces el tráfico de replicación a través de la conexión WAN.
Con el clúster de Galera, las cosas son ligeramente diferentes. Para empezar, Galera utiliza el control de flujo para mantener los nodos sincronizados. Si uno de los nodos comienza a retrasarse, tiene la capacidad de pedirle al resto del clúster que reduzca la velocidad y deje que lo alcance. Claro, esto reduce el rendimiento de todo el clúster, pero aún es mejor que cuando realmente no puede usar esclavos para SELECT, ya que tienden a retrasarse de vez en cuando; en tales casos, los resultados que obtendrá pueden estar desactualizados e incorrectos.
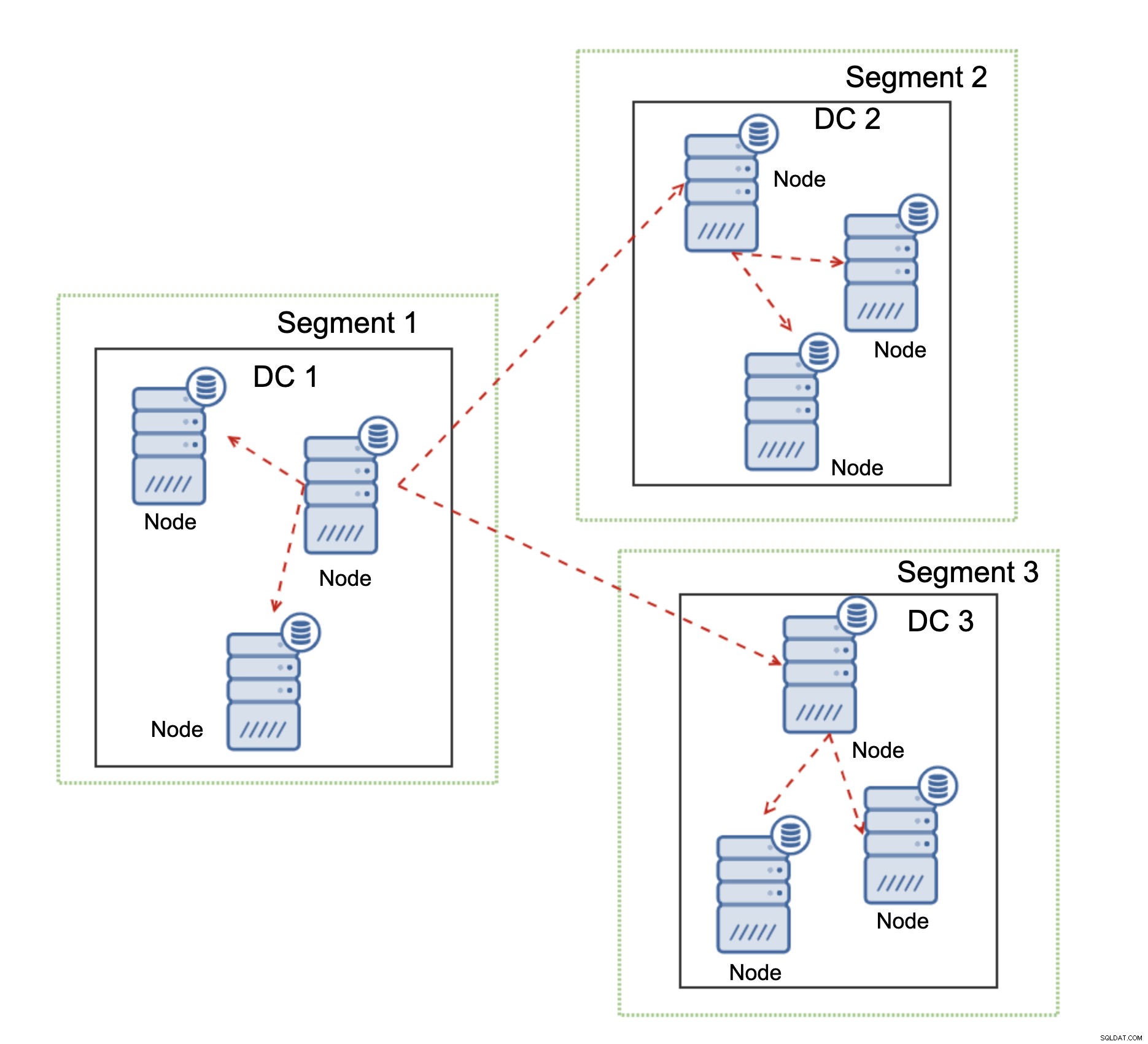
Otra característica de Galera Cluster, que puede mejorar significativamente su rendimiento cuando se utiliza WAN, son segmentos. De forma predeterminada, Galera utiliza la comunicación de todos a todos y el nodo envía cada conjunto de escritura a todos los demás nodos del clúster. Este comportamiento se puede cambiar usando segmentos. Los segmentos permiten a los usuarios dividir el clúster de Galera en varias partes. Cada segmento puede contener varios nodos y elige uno de ellos como nodo de retransmisión. Dicho nodo recibe conjuntos de escritura de otros segmentos y los redistribuye a través de los nodos Galera locales al segmento. Como resultado, como puede ver en el diagrama anterior, es posible reducir tres veces el tráfico de replicación que pasa por la WAN:solo se envían dos "réplicas" del flujo de replicación a través de la WAN:una por centro de datos en comparación con una por esclavo en la replicación de MySQL.
Manejo de particiones de red de clúster de Galera
Donde brilla Galera Cluster es en el manejo de la partición de la red. Galera Cluster monitorea constantemente el estado de los nodos en el clúster. Cada nodo intenta conectarse con sus pares e intercambiar el estado del clúster. Si no se puede acceder a un subconjunto de nodos, Galera intenta retransmitir la comunicación para que, si hay una forma de llegar a esos nodos, se llegue a ellos.

Se puede ver un ejemplo en el diagrama anterior:DC 1 perdió la conectividad con DC2 pero DC2 y DC3 pueden conectarse. En este caso, uno de los nodos en DC3 se utilizará para transmitir datos de DC1 a DC2, lo que garantiza que se pueda mantener la comunicación dentro del clúster.
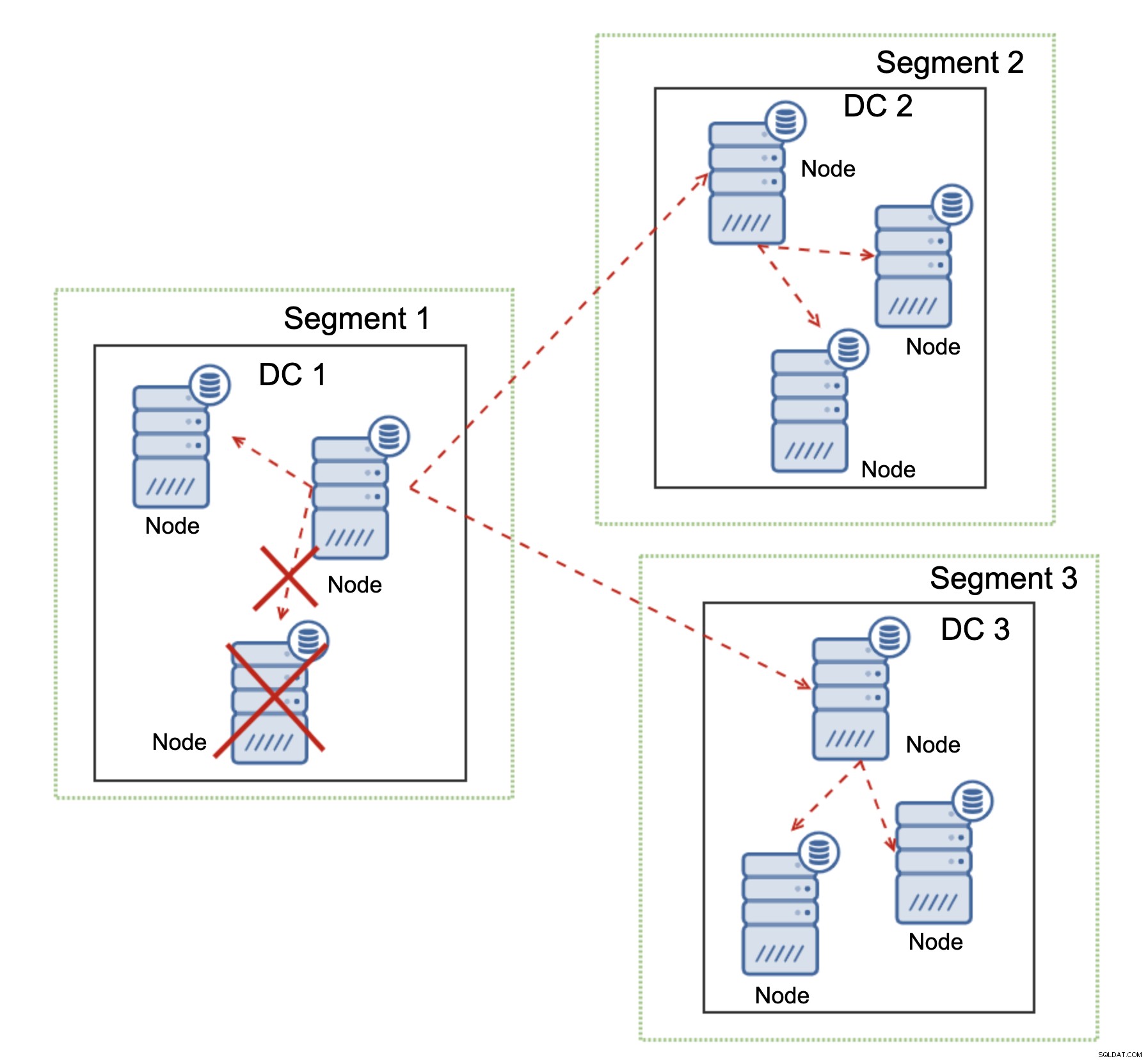
Galera Cluster puede realizar acciones en función del estado del clúster. Implementa el quórum:la mayoría de los nodos deben estar disponibles para que el clúster pueda operar. Si el nodo se desconecta del clúster y no puede llegar a ningún otro nodo, dejará de funcionar.
Como se puede ver en el diagrama anterior, hay una pérdida parcial de la comunicación de red en DC1 y el nodo afectado se elimina del clúster, lo que garantiza que la aplicación no accederá a datos obsoletos.
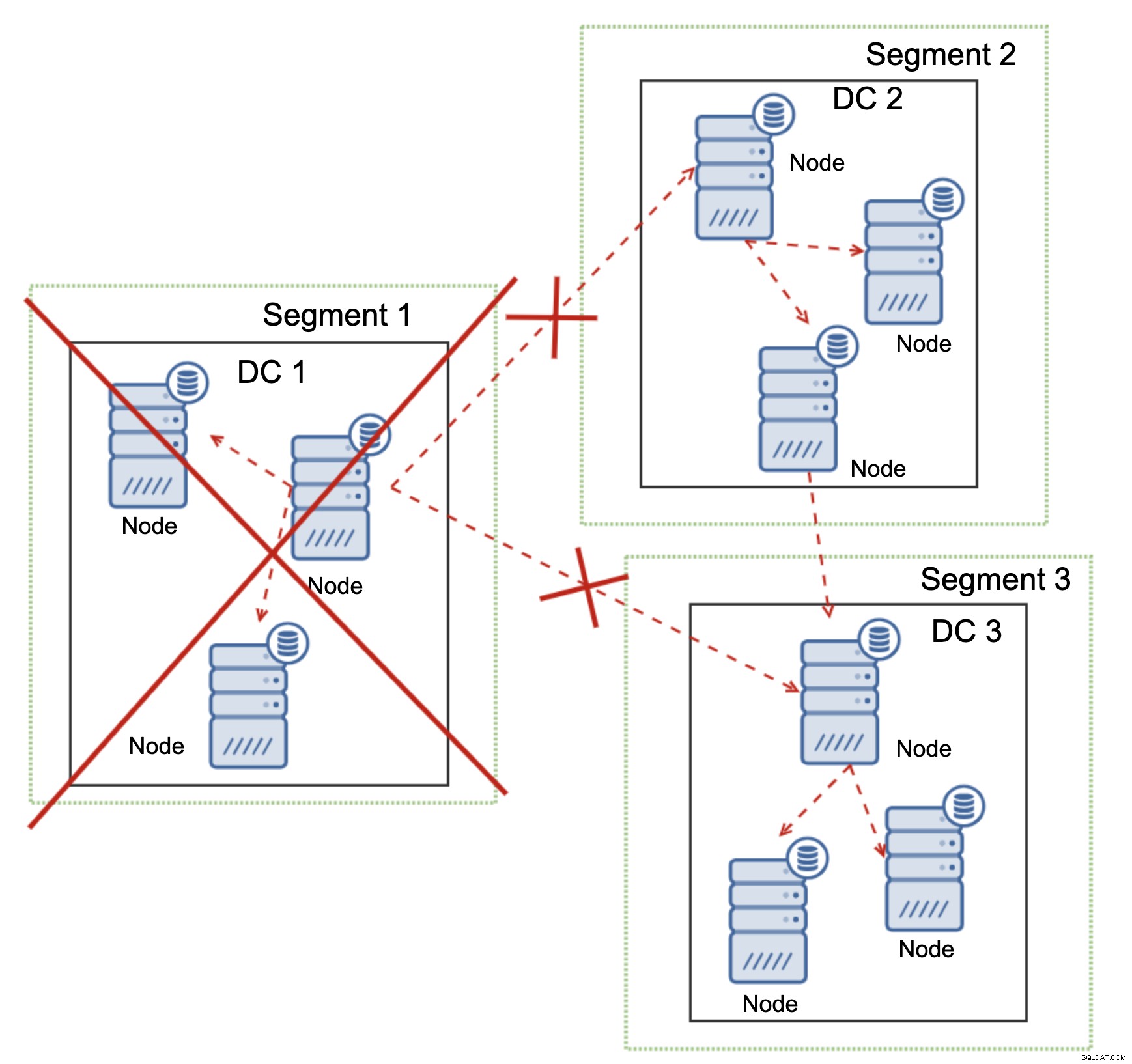
Esto también es cierto a mayor escala. El DC1 cortó todas sus comunicaciones. Como resultado, todo el centro de datos se eliminó del clúster y ninguno de sus nodos atenderá el tráfico. El resto del clúster mantuvo la mayoría (6 de 9 nodos están disponibles) y se reconfiguró para mantener la conexión entre DC 2 y DC3. En el diagrama anterior, asumimos que la escritura llega al nodo en DC2, pero tenga en cuenta que Galera es capaz de ejecutarse con varios escritores.
La replicación de MySQL no tiene ningún tipo de reconocimiento de clústeres, lo que dificulta el manejo de problemas de red. No puede apagarse al perder la conexión con otros nodos. No hay una manera fácil de evitar que el maestro antiguo aparezca después de la división de la red.
Las únicas posibilidades se limitan a la capa de proxy o incluso superior. Debe diseñar un sistema que intente comprender el estado del clúster y tomar las medidas necesarias. Una forma posible es usar herramientas para clústeres como Orchestrator y luego ejecutar secuencias de comandos que verifiquen el estado del clúster RAFT de Orchestrator y, en función de este estado, tomar las medidas necesarias en la capa de la base de datos. Esto está lejos de ser ideal porque cualquier acción realizada en una capa más alta que la base de datos agrega latencia adicional:hace posible que el problema aparezca y la coherencia de los datos se vea comprometida antes de que se pueda tomar la acción correcta. Galera, por otro lado, toma acciones a nivel de base de datos, asegurando la reacción más rápida posible.