La replicación de Galera es relativamente nueva si se compara con la replicación de MySQL, que es compatible de forma nativa desde MySQL v3.23. Aunque la replicación MySQL está diseñada para la replicación unidireccional maestro-esclavo, se puede configurar como una configuración activa maestro-maestro con replicación bidireccional. Si bien es fácil de configurar y algunos casos de uso podrían beneficiarse de este "truco", hay una serie de advertencias. Por otro lado, el clúster de Galera es un tipo diferente de tecnología para aprender y administrar. ¿Vale la pena?
En esta entrada de blog, vamos a comparar la replicación maestro-maestro con el clúster de Galera.
Conceptos de replicación
Antes de saltar a la comparación, expliquemos los conceptos básicos detrás de estos dos mecanismos de replicación.
Generalmente, cualquier modificación a la base de datos MySQL genera un evento en formato binario. Este evento se transporta a los otros nodos según el método de replicación elegido:replicación MySQL (nativa) o replicación Galera (parcheada con API wsrep).
Replicación MySQL
Los siguientes diagramas ilustran el flujo de datos de una transacción exitosa de un nodo a otro cuando se usa la replicación de MySQL:
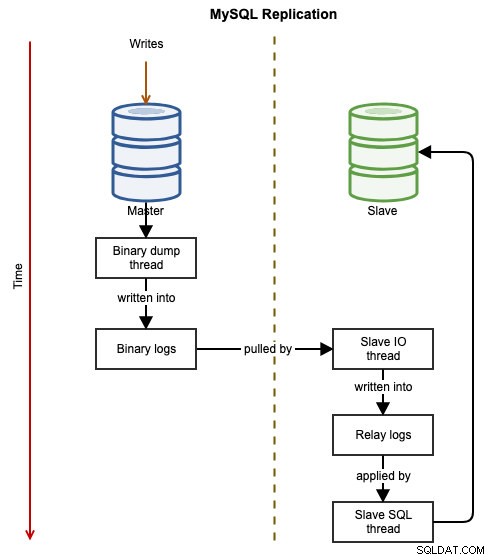
El evento binario se escribe en el registro binario del maestro. Los esclavos a través de slave_IO_thread extraerá los eventos binarios del registro binario del maestro y los replicará en su registro de retransmisión. El esclavo_SQL_thread luego aplicará el evento del registro de retransmisión de forma asíncrona. Debido a la naturaleza asíncrona de la replicación, no se garantiza que el servidor esclavo tenga los datos cuando el maestro realice el cambio.
Idealmente, la replicación de MySQL tendrá el esclavo configurado como un servidor de solo lectura configurando read_only=ON o super_read_only=ON. Esta es una precaución para proteger al esclavo de escrituras accidentales que pueden provocar inconsistencias en los datos o fallas durante la conmutación por error del maestro (por ejemplo, transacciones erráticas). Sin embargo, en una configuración de replicación activo-activo maestro-maestro, solo lectura debe estar deshabilitada en el otro maestro para permitir que las escrituras se procesen simultáneamente. El maestro principal debe configurarse para replicar desde el maestro secundario mediante la instrucción CHANGE MASTER para habilitar la replicación circular.
Replicación de Galera
Los siguientes diagramas ilustran el flujo de replicación de datos de una transacción exitosa de un nodo a otro para Galera Cluster:
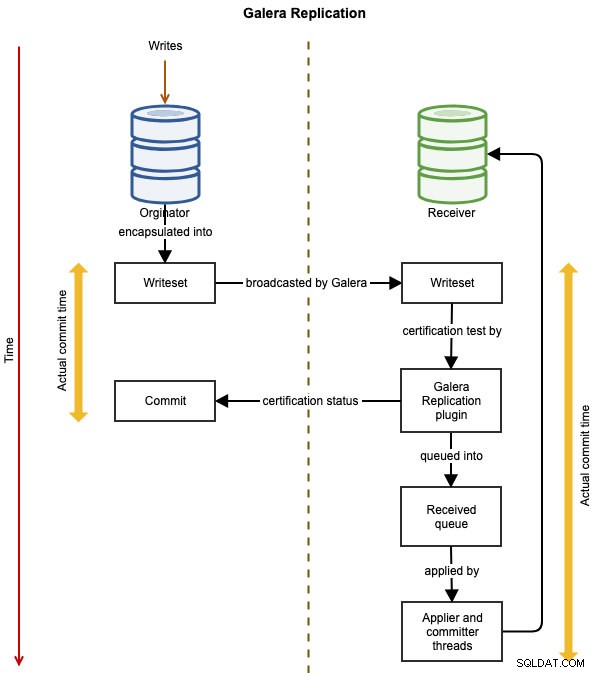
El evento se encapsula en un conjunto de escritura y se transmite desde el nodo de origen a los demás nodos del clúster mediante la replicación de Galera. El conjunto de escritura se somete a certificación en cada nodo de Galera y, si pasa, los subprocesos del aplicador aplicarán el conjunto de escritura de forma asíncrona. Esto significa que el servidor esclavo eventualmente se volverá consistente, luego del acuerdo de todos los nodos participantes en el pedido total global. Es lógicamente síncrono, pero la escritura y confirmación reales en el tablespace ocurren de forma independiente y, por lo tanto, de forma asíncrona en cada nodo con la garantía de que el cambio se propagará en todos los nodos.
Evitar la colisión de clave principal
Para implementar la replicación de MySQL en la configuración maestro-maestro, se debe ajustar el valor de incremento automático para evitar la colisión de la clave principal para INSERTAR entre dos o más maestros replicantes. Esto permite que el valor de la clave principal en los maestros se intercale entre sí y evita que el mismo número de incremento automático se use dos veces en cualquiera de los nodos. Este comportamiento debe configurarse manualmente, según la cantidad de maestros en la configuración de la replicación. El valor de auto_increment_increment es igual al número de maestros replicantes y el auto_increment_offset debe ser único entre ellos. Por ejemplo, las siguientes líneas deberían existir dentro del my.cnf correspondiente:
Maestro1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Maestro2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Del mismo modo, Galera Cluster usa este mismo truco para evitar colisiones de claves primarias al controlar el valor de incremento automático y compensar automáticamente con wsrep_auto_increment_control variable. Si se establece en 1 (el valor predeterminado), se ajustará automáticamente el auto_increment_increment y auto_increment_offset variables según el tamaño del conglomerado y cuando cambia el tamaño del conglomerado. Esto evita conflictos de replicación debido a auto_increment. En un entorno maestro-esclavo, esta variable se puede configurar en APAGADO.
La consecuencia de esta configuración es que el valor de incremento automático no estará en orden secuencial, como se muestra en la siguiente tabla de un clúster Galera de tres nodos:
| Nodo | auto_incremento_incremento | auto_incremento_desplazamiento | Valor de incremento automático |
|---|---|---|---|
| Nodo 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Nodo 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Nodo 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Si una aplicación realiza operaciones de inserción en los siguientes nodos en el siguiente orden:
- Nodo1, Nodo3, Nodo2, Nodo3, Nodo3, Nodo1, Nodo3 ..
Entonces, el valor de la clave principal que se almacenará en la tabla será:
- 1, 6, 8, 9, 12, 13, 15 ..
En pocas palabras, al usar la replicación maestro-maestro (replicación MySQL o Galera), su aplicación debe ser capaz de tolerar valores de incremento automático no secuenciales en su conjunto de datos.
Para los usuarios de ClusterControl, tenga en cuenta que admite la implementación de la replicación maestro-maestro de MySQL con un límite de dos maestros por clúster de replicación, solo para la configuración activa-pasiva. Por lo tanto, ClusterControl no configura deliberadamente los maestros con auto_increment_increment y auto_increment_offset variables.
Coherencia de datos
Galera Cluster viene con su mecanismo de control de flujo, en el que cada nodo del clúster debe mantenerse al día durante la replicación o, de lo contrario, todos los demás nodos tendrán que reducir la velocidad para permitir que el nodo más lento se ponga al día. Básicamente, esto minimiza la probabilidad de retraso del esclavo, aunque aún podría ocurrir, pero no tan significativo como en la replicación de MySQL. De forma predeterminada, Galera permite que los nodos tengan al menos 16 transacciones atrasadas en la aplicación a través de la variable gcs.fc_limit . Si desea realizar lecturas críticas (una SELECCIÓN que debe devolver la información más actualizada), probablemente desee utilizar la variable de sesión, wsrep_sync_wait .
Galera Cluster, por otro lado, viene con una protección contra la inconsistencia de datos mediante la cual un nodo será desalojado del clúster si no aplica ningún conjunto de escritura por cualquier motivo. Por ejemplo, cuando un nodo de Galera no puede aplicar el conjunto de escritura debido a un error interno del motor de almacenamiento subyacente (MySQL/MariaDB), el nodo se extraerá del clúster con el siguiente error:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..Para corregir la consistencia de los datos, el nodo infractor debe volver a sincronizarse antes de que se le permita unirse al clúster. Esto se puede hacer manualmente o borrando el directorio de datos para activar la transferencia de estado de instantánea (sincronización completa de un donante).
La replicación maestro-maestro de MySQL no aplica la protección de coherencia de datos y se permite que un esclavo diverja, por ejemplo, replicar un subconjunto de datos o retrasarse, lo que hace que el esclavo sea inconsistente con el maestro. Está diseñado para replicar datos en un flujo, desde el maestro hasta los esclavos. Las comprobaciones de coherencia de datos deben realizarse manualmente o mediante herramientas externas como Percona Toolkit pt-table-checksum o mysql-replication-check.
Resolución de Conflictos
Por lo general, la replicación maestro-maestro (o multimaestro o bidireccional) permite que más de un miembro en el clúster procese escrituras. Con la replicación de MySQL, en caso de conflicto de replicación, el subproceso SQL del esclavo simplemente deja de aplicar la siguiente consulta hasta que se resuelva el conflicto, ya sea omitiendo manualmente el evento de replicación, arreglando las filas infractoras o resincronizando el esclavo. En pocas palabras, no hay soporte de resolución automática de conflictos para la replicación de MySQL.
Galera Cluster ofrece una mejor alternativa al volver a intentar la transacción infractora durante la replicación. Mediante el uso de wsrep_retry_autocommit variable, se puede indicar a Galera que vuelva a intentar automáticamente una transacción fallida debido a conflictos en todo el clúster, antes de devolver un error al cliente. Si se establece en 0, no se intentarán reintentos, mientras que un valor de 1 (predeterminado) o más especifica el número de reintentos. Esto puede ser útil para ayudar a las aplicaciones que utilizan la confirmación automática para evitar interbloqueos.
Consenso de nodos y conmutación por error
Galera utiliza el Sistema de comunicación grupal (GCS) para verificar el consenso y la disponibilidad de los nodos entre los miembros del clúster. Si un nodo no está en buen estado, se expulsará automáticamente del clúster después de gmcast.peer_timeout. valor, por defecto a 3 segundos. Un nodo de Galera en buen estado en estado "Sincronizado" se considera un nodo confiable para servir lecturas y escrituras, mientras que otros no lo son. Este diseño simplifica enormemente los procedimientos de verificación de estado desde los niveles superiores (equilibrador de carga o aplicación).
En la replicación de MySQL, un maestro no se preocupa por sus esclavos, mientras que un esclavo solo tiene consenso con su único maestro a través de slave_IO_thread proceso al replicar los eventos binarios del registro binario del maestro. Si un maestro falla, se interrumpirá la replicación y se intentará restablecer el enlace cada slave_net_timeout (predeterminado a 60 segundos). Desde la perspectiva de la aplicación o del balanceador de carga, los procedimientos de verificación de estado para el esclavo de replicación deben implicar al menos verificar el siguiente estado:
- Segundos_detrás_del_maestro
- Esclavo_IO_Corriendo
- Slave_SQL_Ejecutándose
- variable de solo lectura
- variable super_read_only (MySQL 5.7.8 y posterior)
En términos de conmutación por error, generalmente, la replicación maestro-maestro y los nodos Galera son iguales. Tienen el mismo conjunto de datos (aunque puede replicar un subconjunto de datos en la replicación de MySQL, pero eso es poco común para maestro-maestro) y comparten el mismo rol que los maestros, capaces de manejar lecturas y escrituras simultáneamente. Por lo tanto, en realidad no hay conmutación por error desde el punto de vista de la base de datos debido a este equilibrio. Solo desde el lado de la aplicación que requeriría conmutación por error para omitir los nodos no operativos. Tenga en cuenta que debido a que la replicación de MySQL es asíncrona, es posible que no todos los cambios realizados en el maestro se hayan propagado al otro maestro.
Aprovisionamiento de nodos
El proceso de sincronizar un nodo con el clúster antes de que comience la replicación se conoce como aprovisionamiento. En la replicación de MySQL, el aprovisionamiento de un nuevo nodo es un proceso manual. Uno tiene que hacer una copia de seguridad del maestro y restaurarlo en el nuevo nodo antes de configurar el enlace de replicación. Para un nodo de replicación existente, si los registros binarios del maestro se han rotado (basado en expire_logs_days , el valor predeterminado es 0 significa que no se elimina automáticamente), es posible que deba volver a aprovisionar el nodo mediante este procedimiento. También hay herramientas externas como Percona Toolkit pt-table-sync y ClusterControl para ayudarte con esto. ClusterControl admite la resincronización de un esclavo con solo dos clics. Tiene opciones para resincronizar haciendo una copia de seguridad del maestro activo o una copia de seguridad existente.
En Galera, hay dos formas de hacerlo:transferencia de estado incremental (IST) o transferencia de instantánea de estado (SST). El proceso IST es el método preferido donde solo las transacciones que faltan se transfieren desde el caché de un donante. El proceso SST es similar a tomar una copia de seguridad completa del donante, por lo general requiere muchos recursos. Galera determinará automáticamente qué proceso de sincronización activar en función del estado del usuario. En la mayoría de los casos, si un nodo no se une a un clúster, simplemente borre el directorio de datos MySQL del nodo problemático e inicie el servicio MySQL. El proceso de aprovisionamiento de Galera es mucho más simple, resulta muy útil al escalar su clúster o volver a introducir un nodo problemático en el clúster.
Laxamente acoplado frente a estrechamente acoplado
La replicación de MySQL funciona muy bien incluso en conexiones más lentas y con conexiones que no son continuas. También se puede utilizar en diferentes hardware, entornos y sistemas operativos. La mayoría de los motores de almacenamiento lo admiten, incluidos MyISAM, Aria, MEMORY y ARCHIVE. Esta configuración débilmente acoplada permite que la replicación maestro-maestro de MySQL funcione bien en un entorno mixto con menos restricciones.
Los nodos de Galera están estrechamente acoplados, donde el rendimiento de replicación es tan rápido como el nodo más lento. Galera utiliza un mecanismo de control de flujo para controlar el flujo de replicación entre los miembros y eliminar cualquier retraso del esclavo. La replicación puede ser rápida o lenta en cada nodo y Galera la ajusta automáticamente. Por lo tanto, se recomienda utilizar especificaciones de hardware uniformes para todos los nodos de Galera, especialmente con respecto a la CPU, la RAM, el subsistema de disco, la tarjeta de interfaz de red y la latencia de red entre los nodos del clúster.
Conclusiones
En resumen, Galera Cluster es superior si se compara con la replicación maestro-maestro de MySQL debido a su soporte de replicación síncrona con gran consistencia, además de características más avanzadas como el control automático de membresía, el aprovisionamiento automático de nodos y esclavos de subprocesos múltiples. En última instancia, esto depende de cómo interactúa la aplicación con el servidor de la base de datos. Es posible que algunas aplicaciones heredadas creadas para un servidor de base de datos independiente no funcionen bien en una configuración en clúster.
Para simplificar nuestros puntos anteriores, las siguientes razones justifican cuándo usar la replicación maestro-maestro de MySQL:
- Cosas que no son compatibles con Galera:
- Replicación para tablas que no son InnoDB/XtraDB como MyISAM, Aria, MEMORY o ARCHIVE.
- Transacciones XA.
- Replicación basada en sentencias entre maestros (p. ej., cuando el ancho de banda es muy caro).
- Confiar en un bloqueo explícito como la instrucción LOCK TABLES.
- El registro de consultas generales y el registro de consultas lentas deben dirigirse a una tabla, en lugar de a un archivo.
- Configuración débilmente acoplada donde las especificaciones de hardware, la versión de software y la velocidad de conexión son significativamente diferentes en cada maestro.
- Cuando ya tiene una cadena de replicación de MySQL y desea agregar otro maestro activo/de respaldo para redundancia para acelerar el tiempo de recuperación y recuperación en caso de que uno de los maestros no esté disponible.
- Si su aplicación no se puede modificar para solucionar las limitaciones de Galera Cluster y tener un balanceador de carga compatible con MySQL como ProxySQL o MaxScale no es una opción.
Razones para elegir Galera Cluster en lugar de la replicación maestro-maestro de MySQL:
- Capacidad de escribir de forma segura en múltiples maestros.
- Coherencia de datos gestionada (y garantizada) automáticamente en todas las bases de datos.
- Nuevos nodos de base de datos fácilmente introducidos y sincronizados.
- Fallas o inconsistencias detectadas automáticamente.
- En general, funciones de alta disponibilidad más avanzadas y sólidas.