Un punto único de falla (SPOF) es una razón común por la cual las organizaciones están trabajando para distribuir la presencia de sus entornos de base de datos a otra ubicación geográfica. Forma parte de los planes estratégicos Disaster Recovery y Business Continuity.
La planificación de recuperación ante desastres (DR) incorpora procedimientos técnicos que cubren la preparación para problemas imprevistos como desastres naturales, accidentes (como errores humanos) o incidentes (como actos delictivos).
Durante la última década, la distribución de su entorno de base de datos en varias ubicaciones geográficas ha sido una configuración bastante común, ya que las nubes públicas ofrecen muchas formas de lidiar con esto. El desafío surge al configurar entornos de base de datos. Crea desafíos cuando intenta administrar las bases de datos, mover sus datos a otra ubicación geográfica o aplicar seguridad con un alto nivel de observabilidad.
En este blog, mostraremos cómo puede hacer esto usando la replicación de MySQL. Cubriremos cómo puede copiar sus datos a otro nodo de base de datos ubicado en un país diferente distante de la geografía actual del clúster de MySQL. Para este ejemplo, nuestra región de destino se basa en el este de EE. UU., mientras que mi región local se encuentra en Asia, ubicada en Filipinas.
¿Por qué necesito un clúster de base de datos de ubicación geográfica?
Incluso Amazon AWS, el principal proveedor de nube pública, afirma que sufre tiempos de inactividad o interrupciones no deseadas (como la que ocurrió en 2017). Supongamos que está utilizando AWS como su centro de datos secundario aparte de su local. No puede tener ningún acceso interno a su hardware subyacente o a esas redes internas que administran sus nodos de cómputo. Estos son servicios completamente administrados por los que pagó, pero no puede evitar el hecho de que puede sufrir una interrupción en cualquier momento. Si una ubicación geográfica de este tipo sufre una interrupción, puede tener un tiempo de inactividad prolongado.
Este tipo de problema debe preverse durante la planificación de la continuidad del negocio. Debe haber sido analizado e implementado en base a lo definido. La continuidad del negocio para sus bases de datos MySQL debe incluir un alto tiempo de actividad. Algunos entornos están realizando pruebas comparativas y establecen un estándar alto de pruebas rigurosas, incluido el lado débil para exponer cualquier vulnerabilidad, qué tan resistente puede ser y qué tan escalable es su arquitectura tecnológica, incluida su infraestructura de base de datos. Para las empresas, especialmente aquellas que manejan grandes transacciones, es imperativo asegurarse de que las bases de datos de producción estén disponibles para las aplicaciones en todo momento, incluso cuando ocurre una catástrofe. De lo contrario, se puede experimentar un tiempo de inactividad que podría costarle una gran cantidad de dinero.
Con estos escenarios identificados, las organizaciones comienzan a extender su infraestructura a diferentes proveedores de nube y colocan nodos en diferentes ubicaciones geográficas para tener un tiempo de actividad más alto (si es posible en 99.99999999999), menor RPO y sin SPOF.
Para garantizar que las bases de datos de producción sobrevivan a un desastre, se debe configurar un sitio de recuperación ante desastres (DR). Los sitios de producción y DR deben ser parte de dos centros de datos geográficamente distantes. Esto significa que se debe configurar una base de datos en espera en el sitio de DR para cada base de datos de producción, de modo que los cambios de datos que se produzcan en la base de datos de producción se sincronicen inmediatamente con la base de datos en espera a través de los registros de transacciones. Algunas configuraciones también usan sus nodos de recuperación ante desastres para manejar las lecturas a fin de proporcionar equilibrio de carga entre la aplicación y la capa de datos.
La configuración arquitectónica deseada
En este blog, la configuración deseada es simple y, sin embargo, una implementación muy común hoy en día. Consulte a continuación la configuración arquitectónica deseada para este blog:
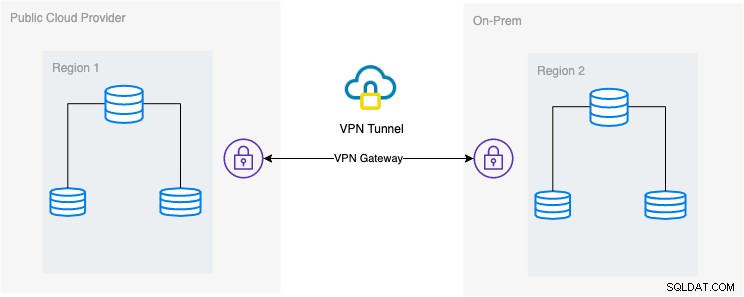
En este blog, elijo Google Cloud Platform (GCP) como público proveedor de la nube y usando mi red local como mi entorno de base de datos local.
Es imprescindible que al usar este tipo de diseño, siempre necesite tanto el entorno como la plataforma para comunicarse de una manera muy segura. Usando VPN o usando alternativas como AWS Direct Connect. Aunque estas nubes públicas hoy en día ofrecen servicios VPN administrados que puede usar. Pero para esta configuración, usaremos OpenVPN ya que no necesito un hardware o servicio sofisticado para este blog.
La mejor y más eficiente forma
Para entornos de bases de datos MySQL/Percona/MariaDB, la mejor y más eficiente forma es realizar una copia de seguridad de su base de datos y enviarla al nodo de destino para implementarla o instanciarla. Hay diferentes formas de usar este enfoque, ya sea que pueda usar mysqldump, mydumper, rsync o usar Percona XtraBackup/Mariabackup y transmitir los datos que van a su nodo de destino.
Uso de mysqldump
mysqldump crea una copia de seguridad lógica de toda su base de datos o puede elegir selectivamente una lista de bases de datos, tablas o incluso registros específicos que desea volcar.
Un comando simple que puede usar para realizar una copia de seguridad completa puede ser,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsCon este comando simple, ejecutará directamente las declaraciones de MySQL en el nodo de la base de datos de destino, por ejemplo, su nodo de la base de datos de destino en Google Compute Engine. Esto puede ser eficiente cuando los datos son más pequeños o tiene un ancho de banda rápido. De lo contrario, empaquetar su base de datos en un archivo y luego enviarlo al nodo de destino puede ser su opción.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathLuego ejecute mysqldump en el nodo de la base de datos de destino como tal,
zcat mydata.db | mysqlLa desventaja de usar respaldo lógico usando mysqldump es que es más lento y consume espacio en disco. También utiliza un único subproceso, por lo que no puede ejecutarlo en paralelo. Opcionalmente, puede usar mydumper, especialmente cuando sus datos son demasiado grandes. mydumper se puede ejecutar en paralelo, pero no es tan flexible en comparación con mysqldump.
Usando xtrabackup
xtrabackup es una copia de seguridad física donde puede enviar los flujos o el binario al nodo de destino. Esto es muy eficiente y se usa principalmente cuando se transmite una copia de seguridad a través de la red, especialmente cuando el nodo de destino es de una geografía diferente o una región diferente. ClusterControl usa xtrabackup cuando aprovisiona o instancia un nuevo esclavo, independientemente de dónde se encuentre, siempre que el acceso y el permiso se hayan configurado antes de la acción.
Si está utilizando xtrabackup para ejecutarlo manualmente, puede ejecutar el comando como tal,
## Nodo de destino
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Nodo de origen
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Para elaborar esos dos comandos, el primer comando debe ejecutarse o ejecutarse primero en el nodo de destino. El comando del nodo de destino escucha en el puerto 9999 y escribirá cualquier transmisión que se reciba desde el puerto 9999 en el nodo de destino. Depende de los comandos socat y xbstream, lo que significa que debe asegurarse de tener estos paquetes instalados.
En el nodo de origen, ejecuta el script perl innobackupex que invoca xtrabackup en segundo plano y usa xbstream para transmitir los datos que se enviarán a través de la red. El comando socat abre el puerto 9999 y envía sus datos al host deseado, que es 192.168.10.70 en este ejemplo. Aún así, asegúrese de tener instalados socat y xbstream cuando use este comando. La forma alternativa de usar socat es nc, pero socat ofrece funciones más avanzadas en comparación con nc, como la serialización, ya que varios clientes pueden escuchar en un puerto.
ClusterControl usa este comando cuando se reconstruye un esclavo o se construye uno nuevo. Es rápido y garantiza que la copia exacta de sus datos de origen se copiará en su nodo de destino. Al aprovisionar una nueva base de datos en una ubicación geográfica separada, usar este enfoque ofrece más eficiencia y le ofrece más velocidad para terminar el trabajo. Aunque puede haber ventajas y desventajas cuando se utiliza una copia de seguridad binaria o lógica cuando se transmite a través del cable. El uso de este método es un enfoque muy común al configurar un nuevo clúster de base de datos de ubicación geográfica en una región diferente y crear una copia exacta de su entorno de base de datos.
Eficiencia, observabilidad y velocidad
Las preguntas dejadas por la mayoría de las personas que no están familiarizadas con este enfoque siempre cubren los problemas de "CÓMO, QUÉ, DÓNDE". En esta sección, cubriremos cómo puede configurar de manera eficiente su base de datos de ubicación geográfica con menos trabajo y con la observabilidad por qué falla. Usar ClusterControl es muy eficiente. En esta configuración actual, tengo el siguiente entorno como se implementó inicialmente:
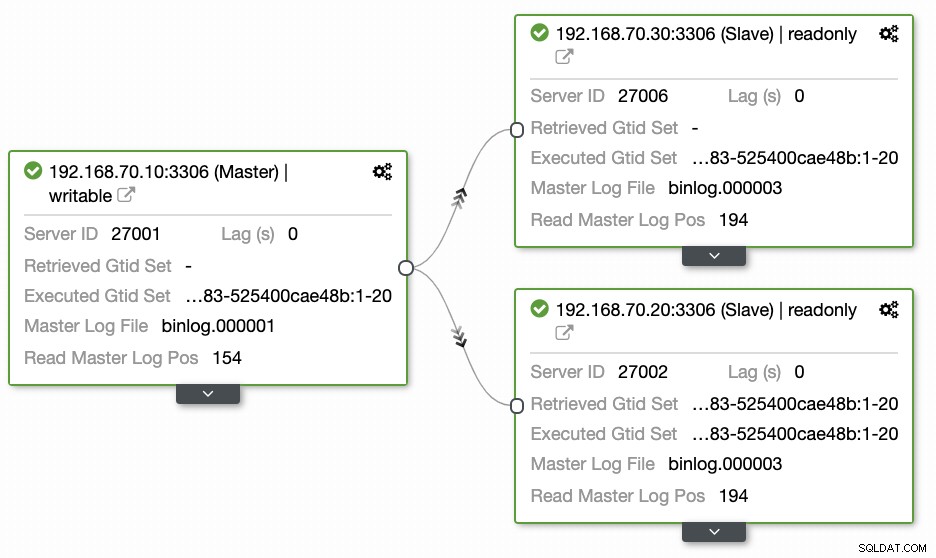
Nodo extendido a GCP
Comenzando a configurar su clúster de base de datos de ubicación geográfica, para ampliar su clúster y crear una copia instantánea de su clúster, puede agregar un nuevo esclavo. Como se mencionó anteriormente, ClusterControl usará xtrabackup (mariabackup para MariaDB 10.2 en adelante) e implementará un nuevo nodo dentro de su clúster. Antes de que pueda registrar sus nodos de cómputo de GCP como sus nodos de destino, primero debe configurar el usuario del sistema apropiado, igual que el usuario del sistema que registró en ClusterControl. Puede verificar esto en su /etc/cmon.d/cmon_X.cnf, donde X es el cluster_id. Por ejemplo, vea a continuación:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (en este ejemplo) debe estar presente en sus nodos de cómputo de GCP. El usuario en sus nodos de GCP debe tener los privilegios sudo o superadministrador. También debe configurarse con un acceso SSH sin contraseña. Lea nuestra documentación para obtener más información sobre el usuario del sistema y sus privilegios necesarios.
Veamos una lista de servidores de ejemplo a continuación (desde la consola de GCP:panel de Compute Engine):
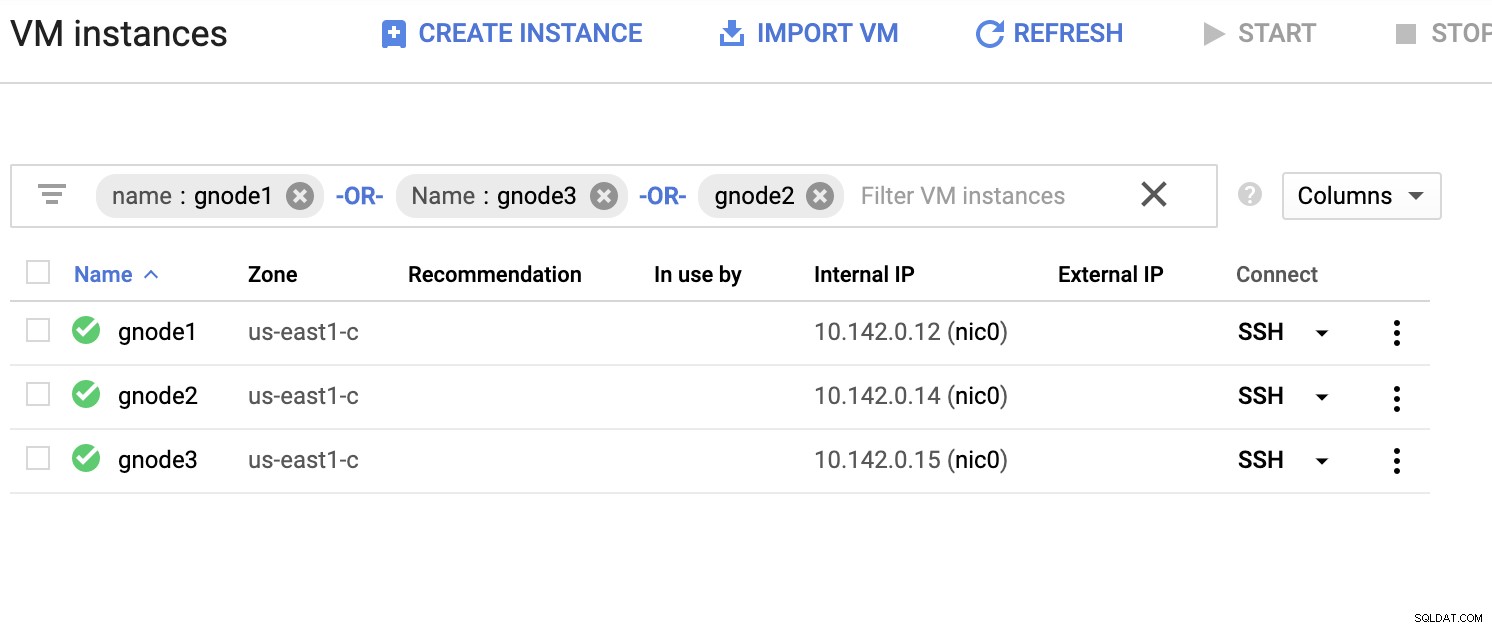
En la captura de pantalla anterior, nuestra región objetivo se basa en EE.UU. Este región. Como se señaló anteriormente, mi red local está configurada sobre una capa segura que pasa por GCP (viceversa) usando OpenVPN. Por lo tanto, la comunicación de GCP que va a mi red local también se encapsula a través del túnel VPN.
Agregar un nodo esclavo a GCP
La siguiente captura de pantalla muestra cómo puede hacerlo. Vea las imágenes a continuación:
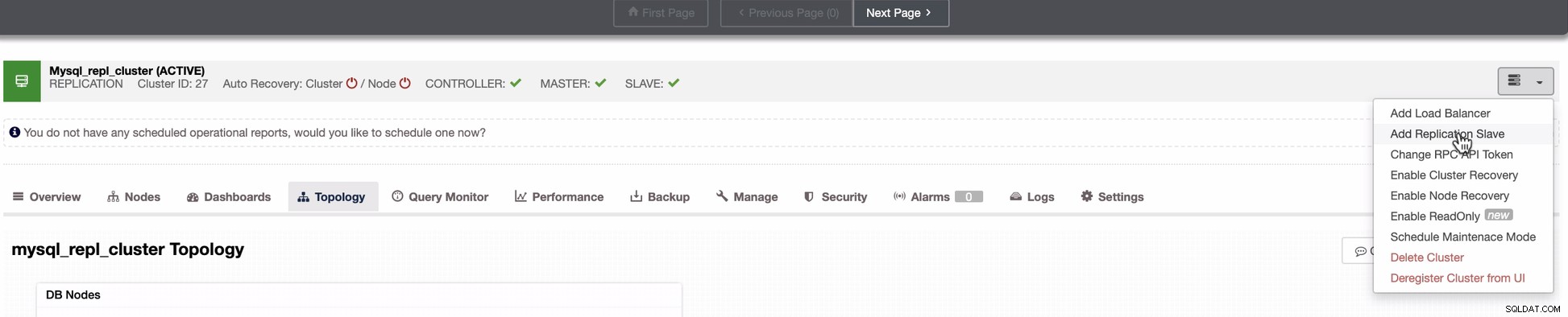
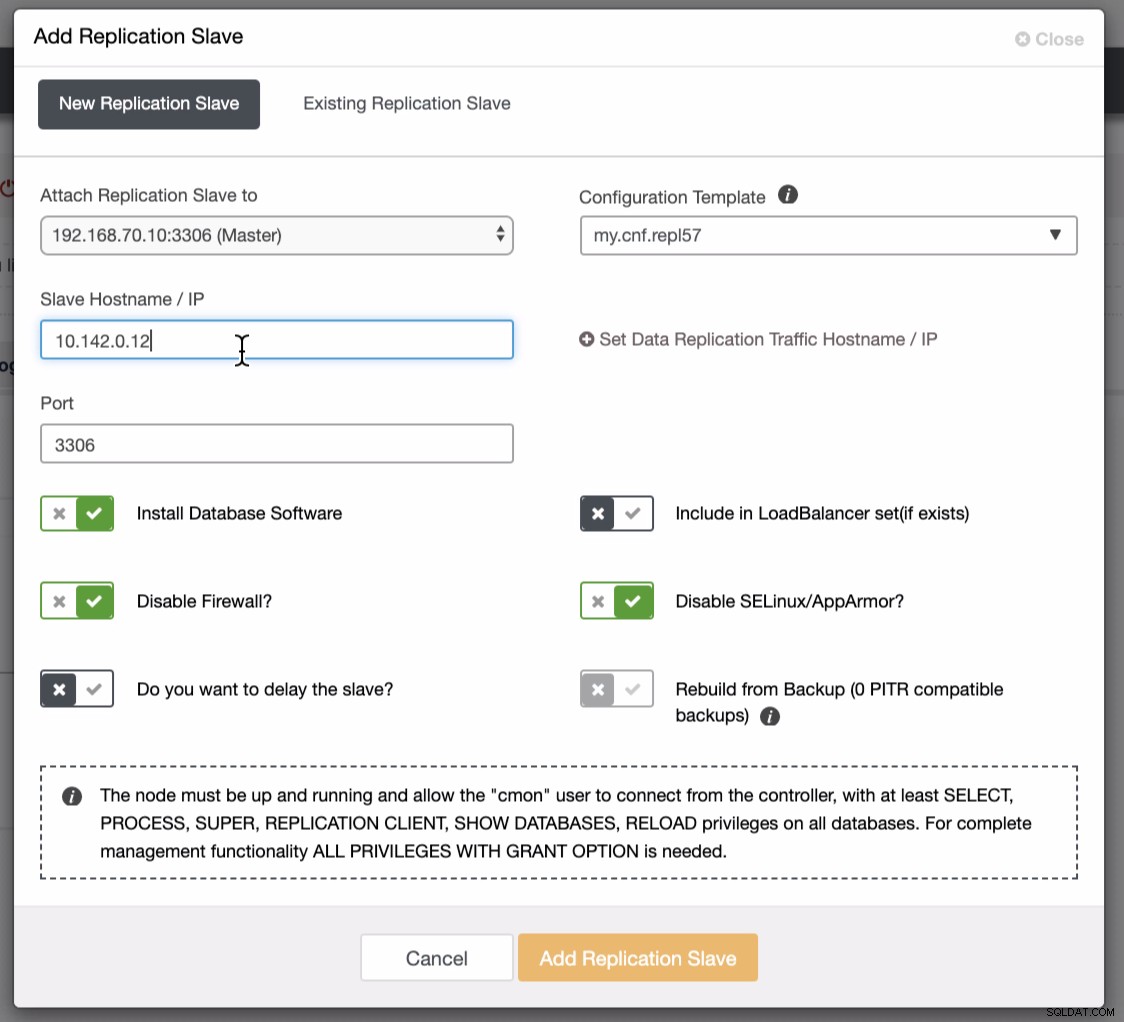
Como se ve en la segunda captura de pantalla, apuntamos al nodo 10.142.0.12 y su maestro de origen es 192.168.70.10. ClusterControl es lo suficientemente inteligente como para determinar los cortafuegos, los módulos de seguridad, los paquetes, la configuración y la instalación que debe realizarse. Vea a continuación un ejemplo de registro de actividad laboral:
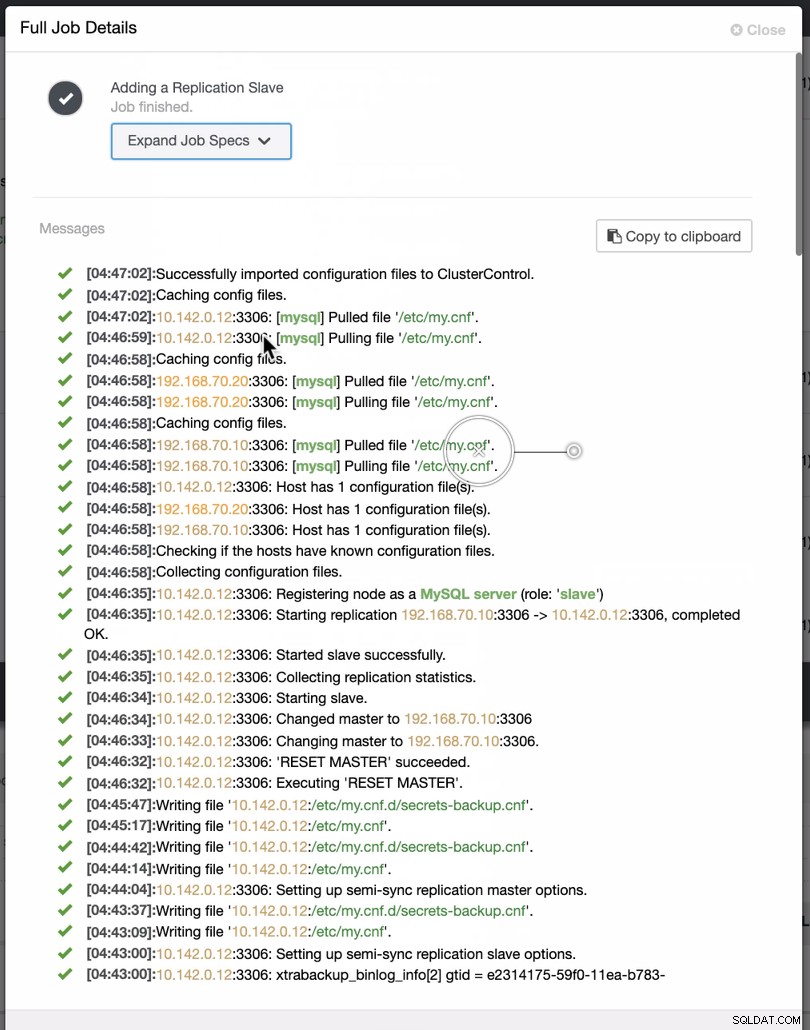
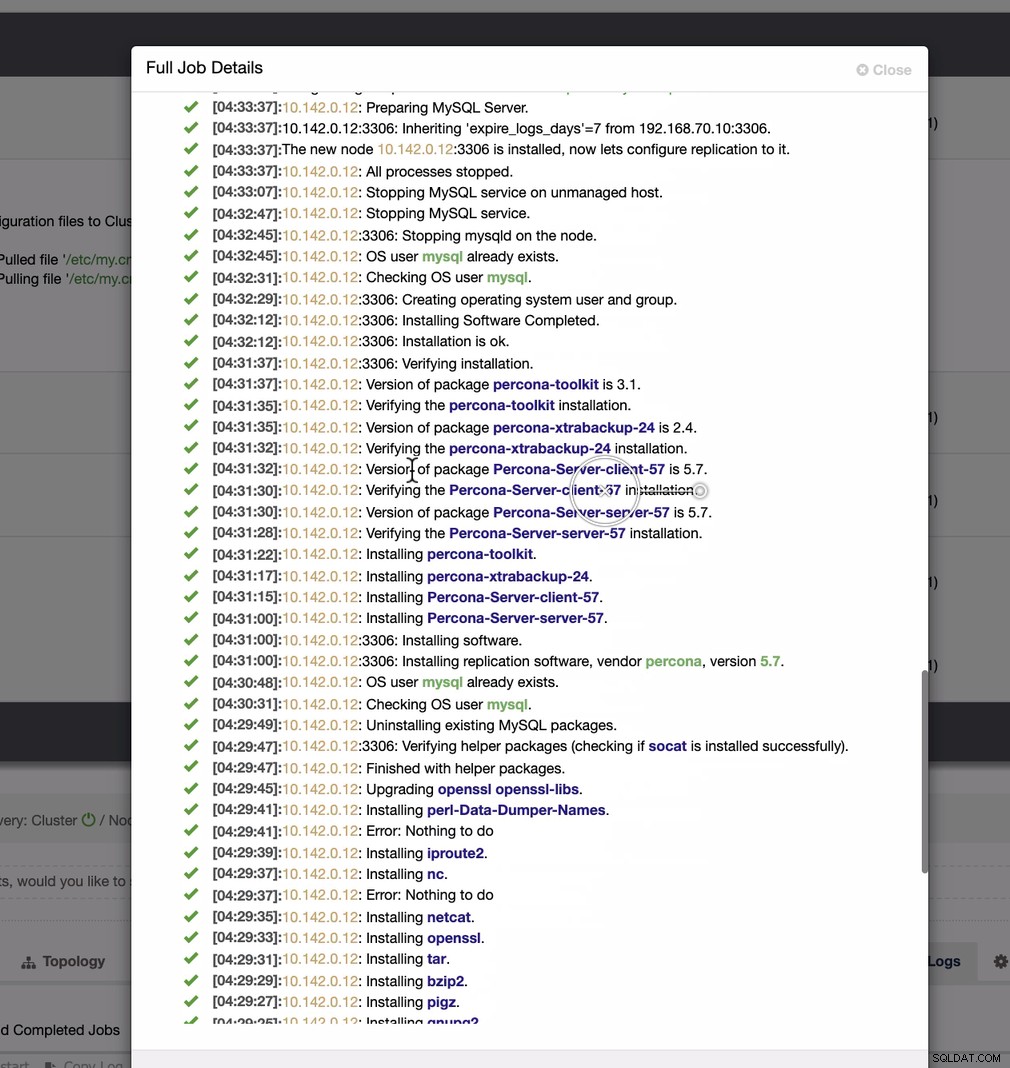
Una tarea bastante sencilla, ¿no?
Complete el clúster MySQL de GCP
Necesitamos agregar dos nodos más al clúster de GCP para tener una topología equilibrada como la que teníamos en la red local. Para el segundo y tercer nodo, asegúrese de que el maestro debe apuntar a su nodo GCP. En este ejemplo, el maestro es 10.142.0.12. Vea a continuación cómo hacer esto,
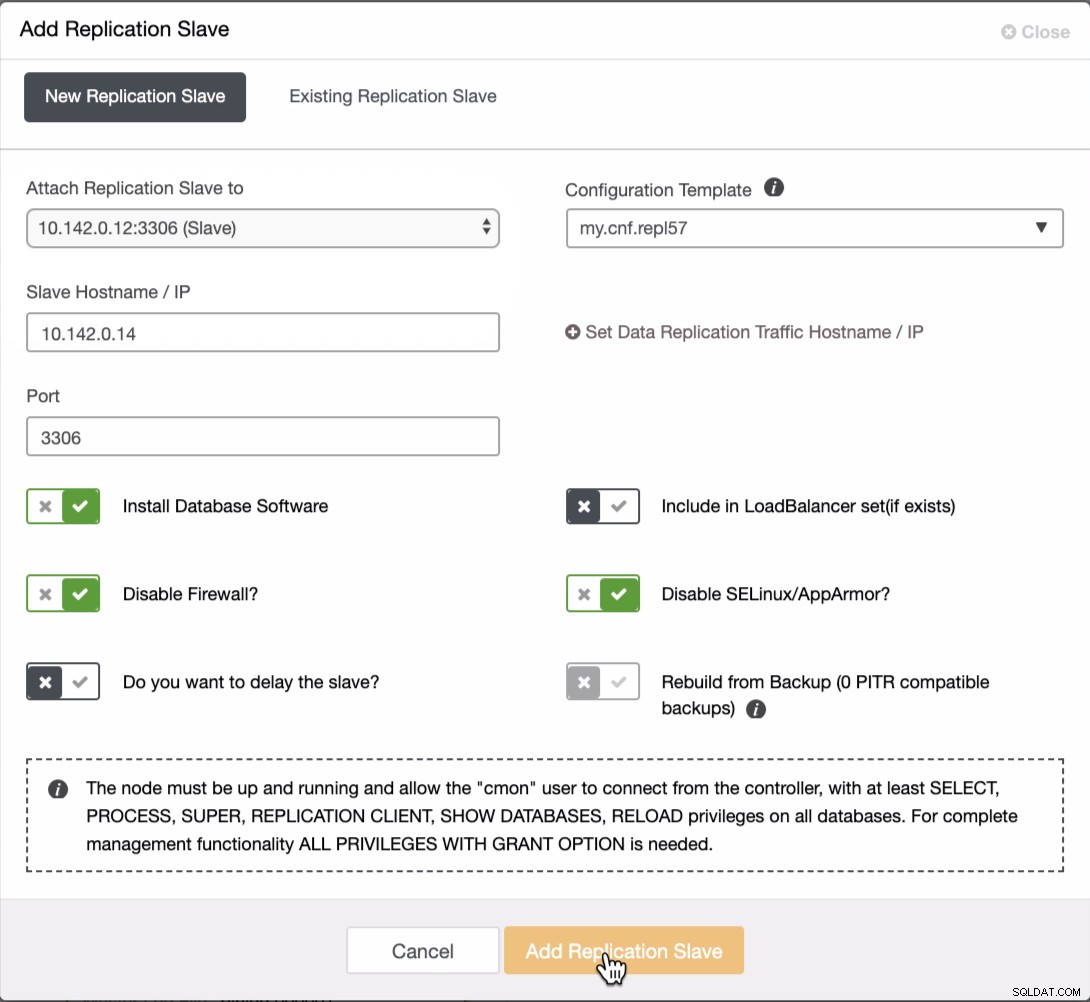
Como se ve en la captura de pantalla anterior, seleccioné el 10.142.0.12 (esclavo ), que es el primer nodo que hemos agregado al clúster. El resultado completo muestra lo siguiente,
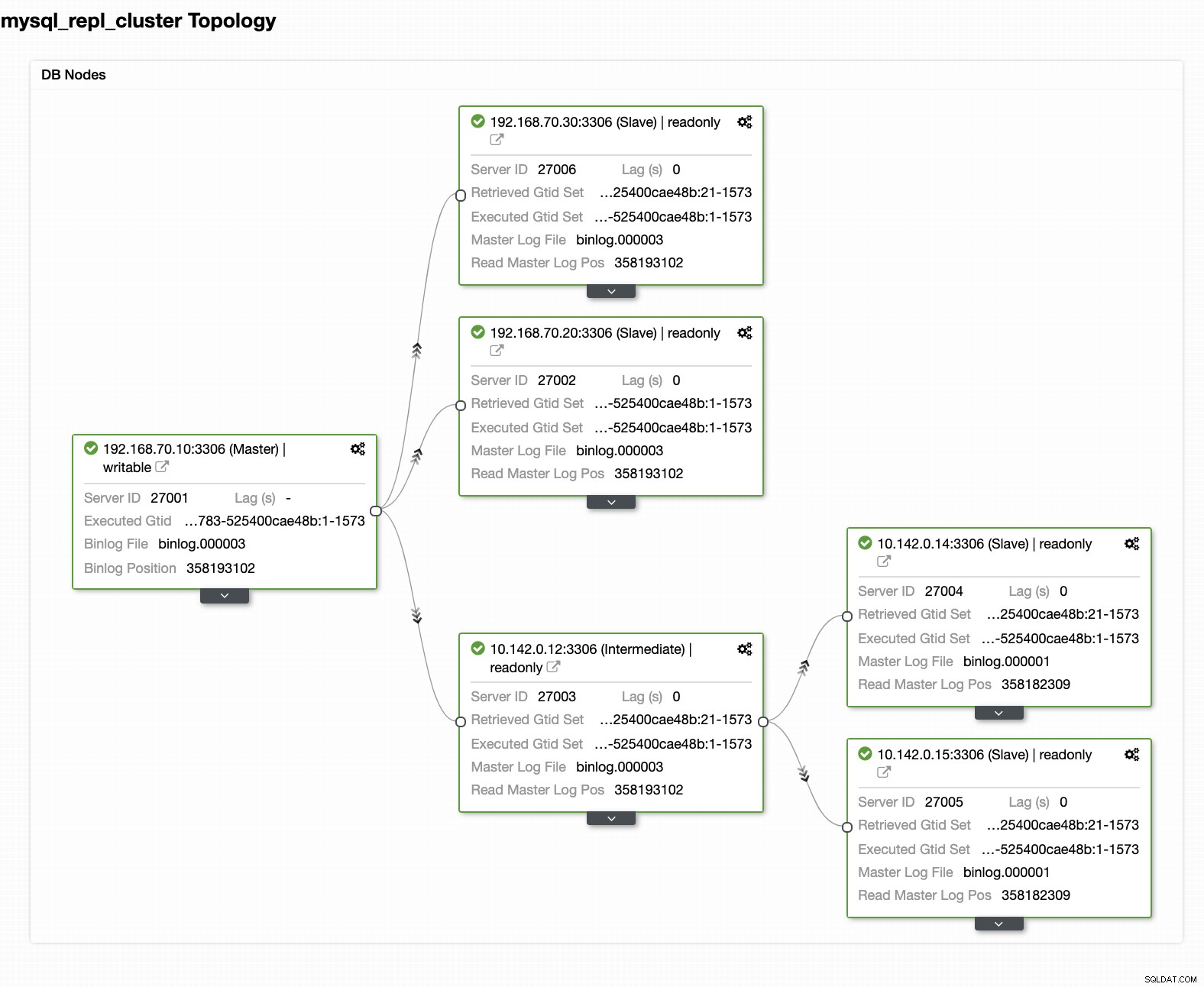
Su configuración final del clúster de la base de datos de ubicación geográfica
Desde la última captura de pantalla, este tipo de topología podría no ser su configuración ideal. En su mayoría, tiene que ser una configuración multimaestro, donde su clúster DR sirve como el clúster en espera, mientras que su local sirve como el clúster activo principal. Para hacer esto, es bastante simple en ClusterControl. Vea las siguientes capturas de pantalla para lograr este objetivo.
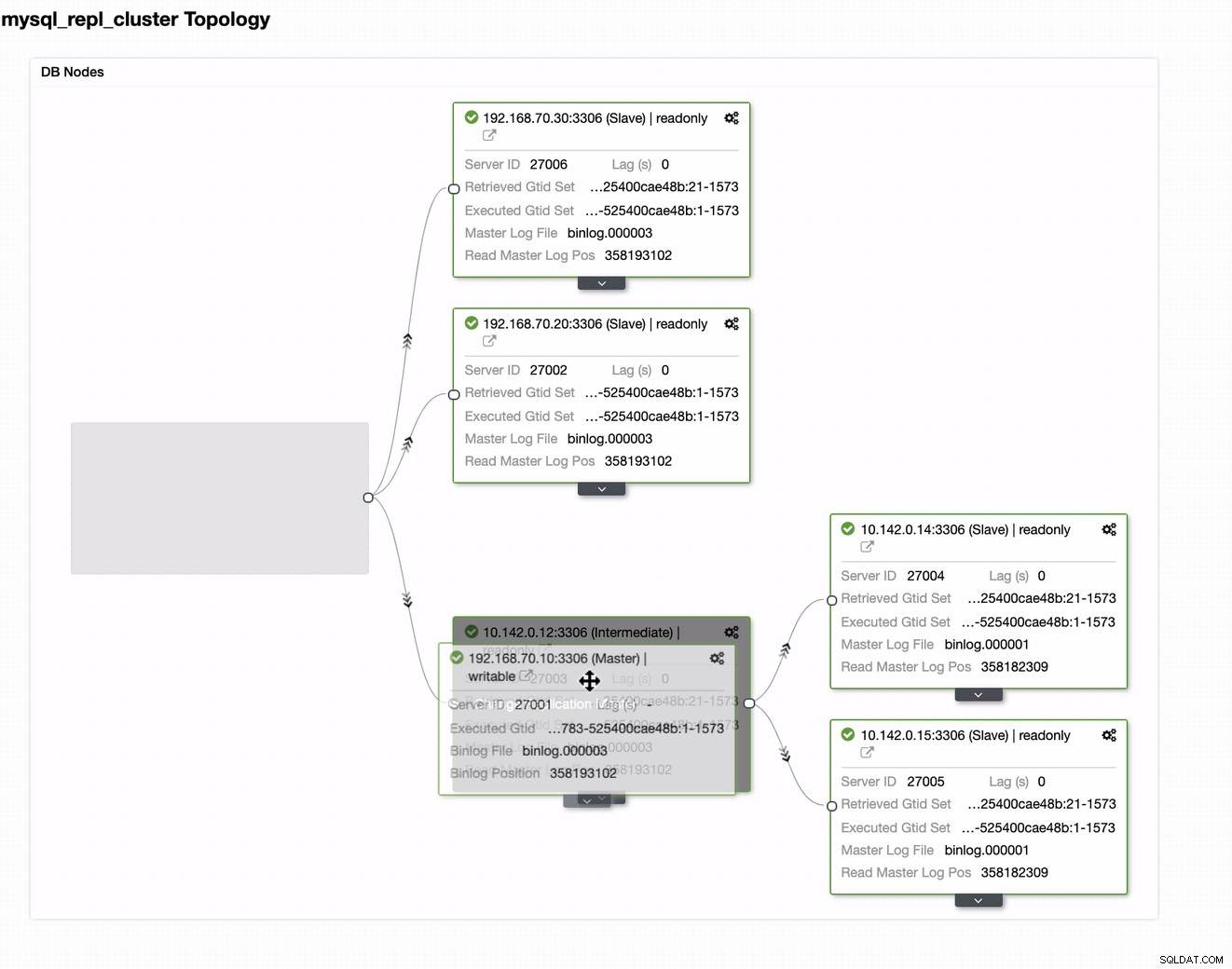
Puede simplemente arrastrar su maestro actual al maestro de destino que debe ser configúrelo como un escritor principal en espera en caso de que su local esté en peligro. En este ejemplo, arrastramos el host de destino 10.142.0.12 (nodo de cómputo de GCP). El resultado final se muestra a continuación:
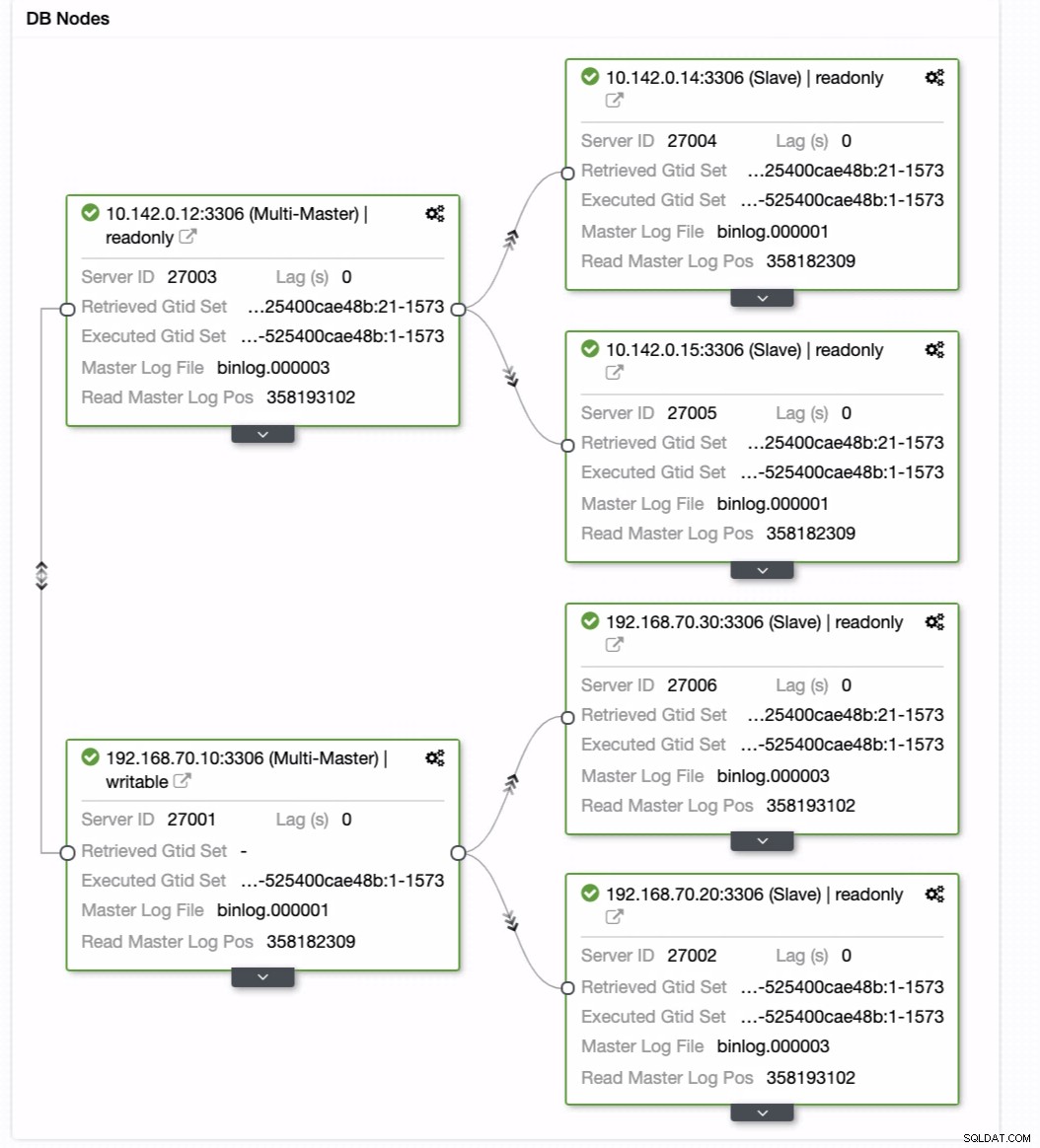
Luego logra el resultado deseado. Fácil y muy rápido de generar su clúster de base de datos de ubicación geográfica mediante la replicación de MySQL.
Conclusión
Tener un clúster de base de datos de ubicación geográfica no es nuevo. Ha sido una configuración deseada para las empresas y organizaciones que evitan SPOF que desean resiliencia y un RPO más bajo.
Los puntos principales de esta configuración son la seguridad, la redundancia y la resiliencia. También cubre qué tan factible y eficiente puede implementar su nuevo clúster en una región geográfica diferente. Si bien ClusterControl puede ofrecer esto, espere que podamos tener más mejoras en esto antes donde puede crear de manera eficiente a partir de una copia de seguridad y generar su nuevo clúster diferente en ClusterControl, así que permanezca atento.