El tema del almacenamiento en caché apareció en PostgreSQL hace 22 años, y en ese momento el enfoque estaba en la confiabilidad de la base de datos.
Avanzando rápidamente hasta 2020, los platos de disco están ocultos aún más profundamente en entornos virtualizados, hipervisores y dispositivos de almacenamiento asociados. Además, las aplicaciones distribuidas e interconectadas que operan a escala global piden a gritos conexiones de baja latencia y, de repente, ajustan las memorias caché del servidor y las consultas SQL compiten para garantizar que los resultados se devuelvan a los clientes en milisegundos. Nacen los cachés de nivel de aplicación y en memoria, y las consultas de lectura ahora se guardan cerca de los servidores de aplicaciones. Como resultado, las operaciones de E/S se reducen a solo escrituras y la latencia de la red mejora drásticamente. Con una captura. Las implementaciones son responsables de su propia gestión de caché, lo que a veces conduce a una degradación del rendimiento.
El almacenamiento en caché de escrituras es un asunto mucho más complicado, como se explica en el wiki de PostgreSQL.
Este blog es una descripción general de las cachés de consultas en memoria y los balanceadores de carga que se utilizan con PostgreSQL.
Equilibrio de carga de PostgreSQL
La idea del equilibrio de carga surgió al mismo tiempo que el almacenamiento en caché, en 1999, cuando Bruce Momjiam escribió:
[...] es posible que seamos _muy_ populares en un futuro cercano.
La base para implementar el equilibrio de carga en PostgreSQL la proporciona la función Hot Standby integrada. El único requisito es que la aplicación maneje la conmutación por error y aquí es donde entran las soluciones de terceros. Veremos algunas de esas soluciones en las siguientes secciones.
Las consultas con equilibrio de carga solo pueden arrojar resultados coherentes siempre que el retraso de la replicación síncrona se mantenga bajo. En la práctica, incluso la infraestructura de red más avanzada, como AWS, puede presentar retrasos de decenas de milisegundos:
Por lo general, observamos tiempos de retraso de decenas de milisegundos. [...] Sin embargo, en condiciones típicas, es común un retraso de replicación de menos de un minuto. [...]
Las réplicas entre regiones que utilizan la replicación lógica se verán afectadas por la tasa de cambio/aplicación y los retrasos en la comunicación de red entre las regiones específicas seleccionadas. Las réplicas entre regiones que usan Aurora Global Database tendrán un retraso típico de menos de un segundo.
Como se indicó anteriormente, las soluciones de terceros se basan en las características principales de PostgreSQL. Por ejemplo, el equilibrio de carga de las consultas de lectura se logra utilizando múltiples modos de espera sincrónicos.
Soluciones
pgpool-II
pgpool-II es un producto rico en funciones que proporciona equilibrio de carga y almacenamiento en memoria caché de consultas. Es un reemplazo directo, no se requieren cambios en el lado de la aplicación.
Como equilibrador de carga, pgpool-II examina cada consulta SQL; para equilibrar la carga, las consultas SELECT deben cumplir varias condiciones.
La configuración puede ser tan simple como un nodo, a continuación se muestra un clúster de dos nodos:
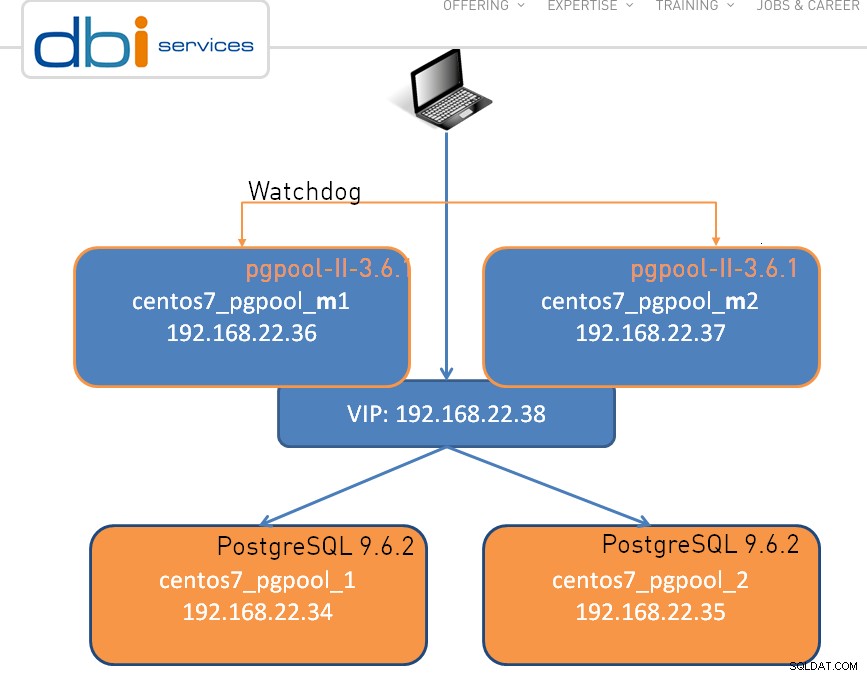
Como es el caso con cualquier gran pieza de software, hay ciertas limitaciones , y pgpool-II no hace ninguna excepción:
- No maneja consultas de declaraciones múltiples.
- Las consultas SELECT en tablas temporales requieren el comentario SQL /*SIN SALDO DE CARGA*/.
Las aplicaciones que se ejecutan en entornos de alto rendimiento se beneficiarán de una configuración mixta donde pgBouncer es el agrupador de conexiones y pgpool-II maneja el equilibrio de carga y el almacenamiento en caché. El resultado es un aumento de rendimiento impresionante de 4 veces y una reducción de latencia del 40 por ciento:
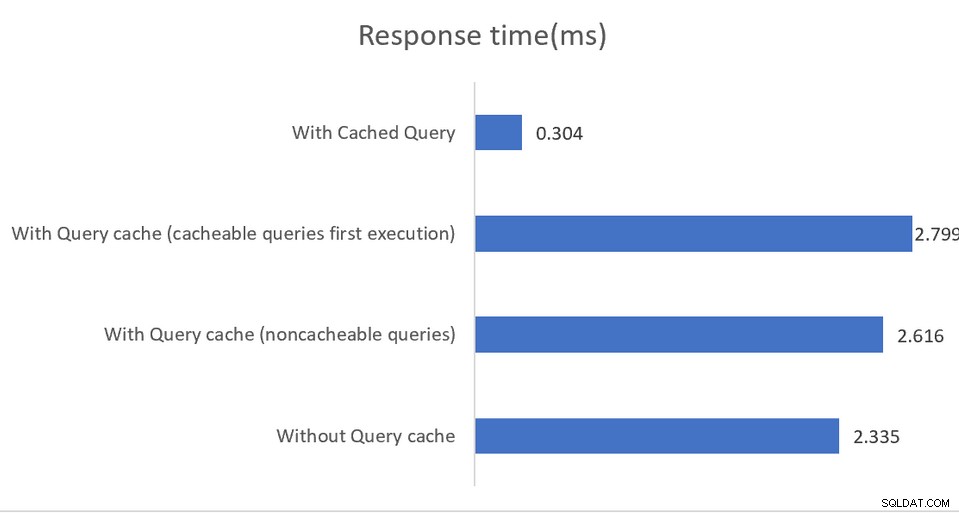
El almacenamiento en caché en memoria funciona, nuevamente, solo en consultas de lectura, con caché los datos se guardan en la memoria compartida o en una instalación Memcached externa. Si bien la documentación es bastante buena para explicar las diversas opciones de configuración, sugiere indirectamente que las implementaciones deben monitorear la salida de SHOW POOL CACHE para alertar sobre las tasas de aciertos que caen por debajo de la marca del 70 %, momento en el que se pierde la ganancia de rendimiento proporcionada por el almacenamiento en caché.
Bucardo
Bucardo es una herramienta de replicación de PostgreSQL escrita en Perl y PL/Perl.
He mencionado a Bucardo, porque el equilibrio de carga es una de sus características, según el wiki de PostgreSQL, sin embargo, una búsqueda en Internet no arroja resultados relevantes. Para aclarar, me dirigí a la documentación oficial que detalla cómo funciona realmente el software:

Eso deja bastante claro que Bucardo no es un equilibrador de carga, al igual que fue señalado por la gente de Database Soup.
HAProxy
HAProxy es un equilibrador de carga de uso general que funciona a nivel de TCP (para las conexiones de la base de datos). Las comprobaciones de estado garantizan que las consultas solo se envíen a nodos activos.
En comparación con pgpool-II, las aplicaciones que utilizan HAProxy como equilibrador de carga deben ser conscientes de las solicitudes de envío de puntos finales a los nodos lectores.
Ignición de Apache
Apache Ignite es un caché de segundo nivel que comprende ANSI-99 SQL y brinda soporte para transacciones ACID. Apache Ignite no comprende el protocolo Frontend/Backend de PostgreSQL y, por lo tanto, las aplicaciones deben usar una capa de persistencia como Hibernate ORM. Como alternativa a la modificación de aplicaciones, Apache Ignite proporciona `integración de memcached`_ que requiere la extensión PostgreSQL de memcached. Desafortunadamente, esta última opción no es compatible con las versiones recientes de PostgreSQL, ya que la extensión pgmemcache se actualizó por última vez en 2017.
Datos de Heimdall
Como producto comercial, Heimdall Data marca ambas casillas:equilibrio de carga y almacenamiento en caché. Es un producto maduro que se presentó en conferencias de PostgreSQL desde la PGCon 2017:

Puede encontrar más detalles y una demostración del producto en el blog de Azure para PostgreSQL .
Conclusión
En la informática distribuida actual, el almacenamiento en caché de consultas y el equilibrio de carga son tan importantes para el ajuste del rendimiento de PostgreSQL como los conocidos GUC, el kernel del sistema operativo, el almacenamiento y la optimización de consultas. Si bien pgpool-II y Heimdall Data son el código abierto y, respectivamente, las soluciones comerciales preferidas, hay casos en los que se pueden usar herramientas creadas a propósito como componentes básicos para lograr resultados similares.



