Publicado por Dan Holmes, que tiene un blog en sql.dnhlms.com.
SQL Server Books Online (BOL), documentos técnicos y muchas otras fuentes le mostrarán cómo y por qué es posible que desee actualizar las estadísticas en una tabla o índice. Sin embargo, solo tienes una forma de dar forma a esos valores. Le mostraré cómo puede crear las estadísticas exactamente de la manera que desee dentro de los límites de los 200 pasos disponibles.
Descargo de responsabilidad :Esto funciona para mí porque conozco mi aplicación, mi base de datos y el flujo de trabajo regular y los patrones de uso de la aplicación de mi usuario. Sin embargo, utiliza comandos no documentados y, si se usa incorrectamente, podría hacer que su aplicación funcione significativamente peor.En nuestra aplicación, el usuario de Programación lee y escribe regularmente datos que representan eventos para mañana y los próximos días. El Programador no utiliza los datos de hoy y anteriores. A primera hora de la mañana, el conjunto de datos para mañana comienza en un par de cientos de filas y para el mediodía puede ser de 1400 o más. El siguiente gráfico ilustrará los recuentos de filas. Estos datos se recopilaron en la mañana del miércoles 18 de noviembre de 2015. Históricamente, puede ver que el recuento de filas normal es de aproximadamente 1400, excepto los días de fin de semana y el día siguiente.
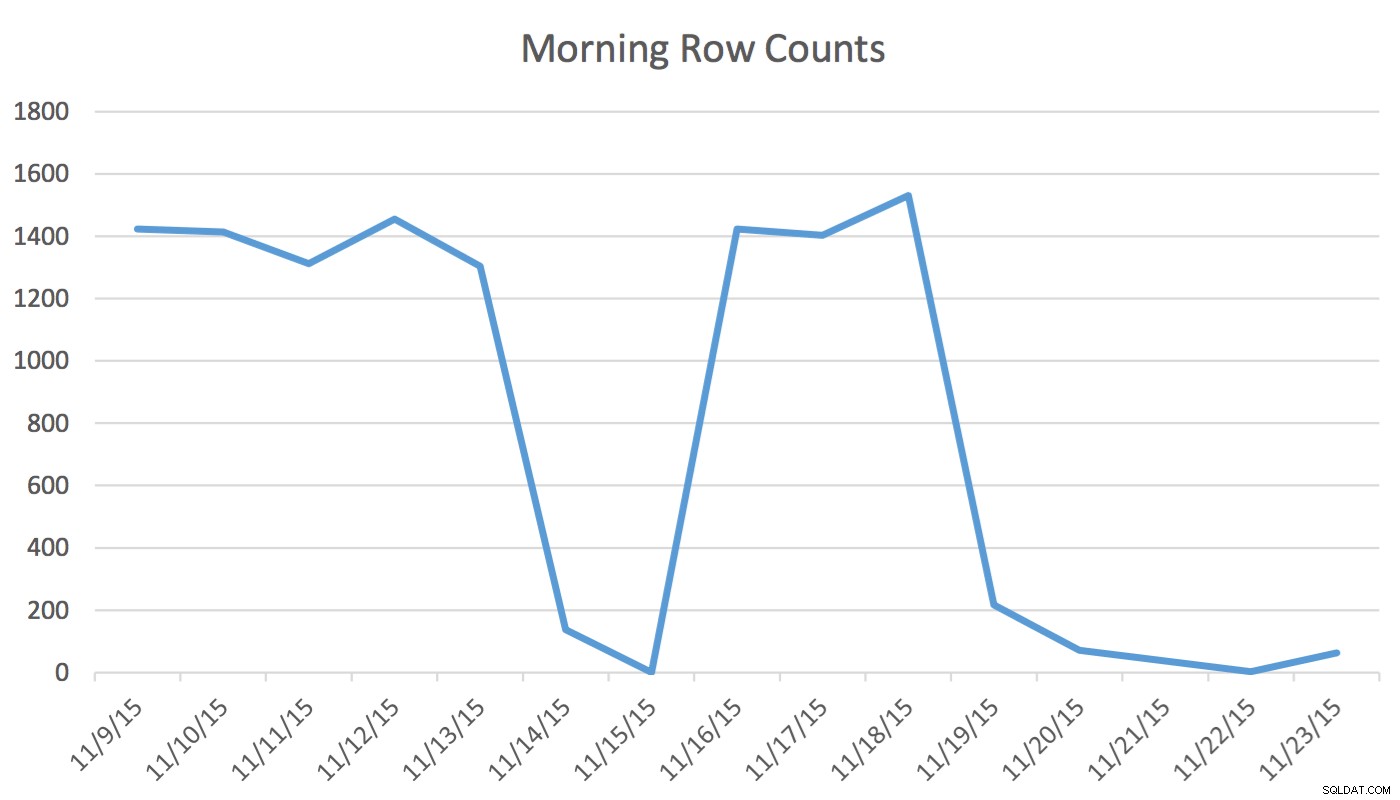
Para el Programador, los únicos datos pertinentes son los próximos días. Lo que está sucediendo hoy y lo que sucedió ayer no es relevante para su actividad. Entonces, ¿cómo causa esto un problema? Esta tabla tiene 2 259 205 filas, lo que significa que el cambio en el recuento de filas de la mañana al mediodía no será suficiente para desencadenar una actualización de estadísticas iniciada por SQL Server. Además, un trabajo programado manualmente que genera estadísticas utilizando UPDATE STATISTICS rellena el histograma con una muestra de todos los datos de la tabla, pero es posible que no incluya la información relevante. Este delta de recuento de filas es suficiente para cambiar el plan. Sin embargo, sin una actualización de estadísticas y un histograma preciso, el plan no mejorará a medida que cambien los datos.
Una selección relevante del histograma para esta tabla de una copia de seguridad fechada el 4/11/2015 podría verse así:
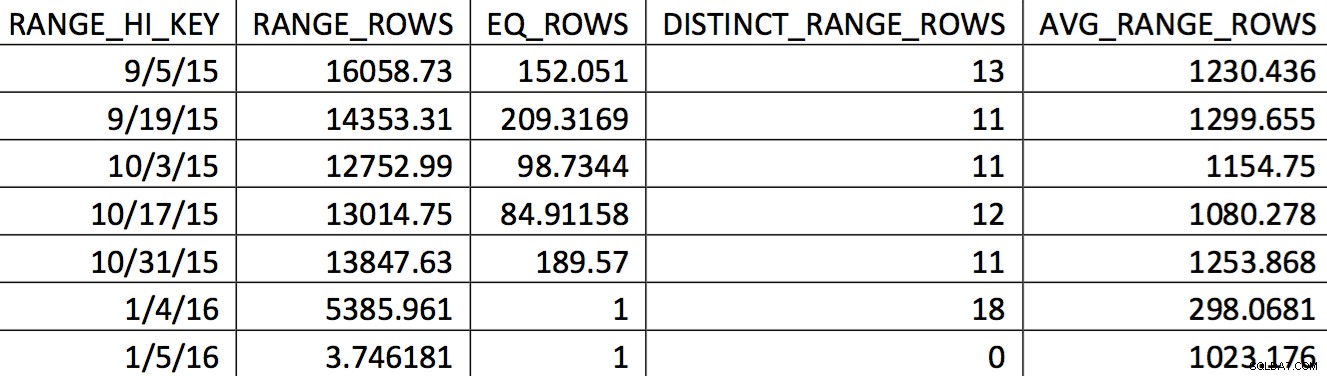
Los valores de interés no se reflejan con precisión en el histograma. Lo que se usaría para la fecha 5/11/2015 sería el valor alto 4/1/2016. Según el gráfico, este histograma claramente no es una buena fuente de información para el optimizador para la fecha de interés. Forzar los valores de uso en el histograma no es confiable, entonces, ¿cómo puedes hacer eso? Mi primer intento fue usar repetidamente el WITH SAMPLE opción de UPDATE STATISTICS y consultar el histograma hasta que los valores que necesitaba estuvieran en el histograma (un esfuerzo detallado aquí). En última instancia, ese enfoque resultó ser poco confiable.
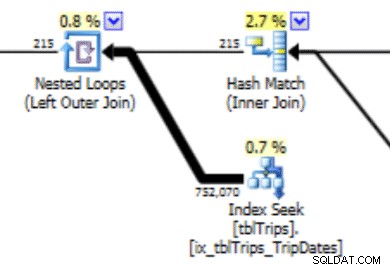
Este histograma puede conducir a un plan con este tipo de comportamiento. La subestimación de las filas produce una combinación de bucle anidado y una búsqueda de índice. Las lecturas son posteriormente más altas de lo que deberían ser debido a esta elección de plan. Esto también afectará la duración del estado de cuenta.
Lo que funcionaría mucho mejor es crear los datos exactamente como los quiere, y así es como se hace.
Hay una opción no admitida de UPDATE STATISTICS :STATS_STREAM . El soporte al cliente de Microsoft lo usa para exportar e importar estadísticas para que puedan volver a crear un optimizador sin tener todos los datos en la tabla. Podemos usar esa característica. La idea es crear una tabla que imite el DDL de la estadística que queremos personalizar. Los datos relevantes se agregan a la tabla. Las estadísticas se exportan e importan a la tabla original.
En este caso, es una tabla con 200 filas de fechas no NULL y 1 fila que incluye los valores NULL. Además, hay un índice en esa tabla que coincide con el índice que tiene los valores de histograma incorrectos.
El nombre de la tabla es tblTripsScheduled . Tiene un índice no agrupado en (id, TheTripDate) y un índice agrupado en TheTripDate . Hay un puñado de otras columnas, pero solo las involucradas en el índice son importantes.
Cree una tabla (tabla temporal si lo desea) que imite la tabla y el índice. La tabla y el índice se ven así:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
A continuación, la tabla debe completarse con 200 filas de datos en los que se deben basar las estadísticas. Para mi situación, es el día de hasta los próximos sesenta días. Los últimos 60 días y posteriores se rellenan con una selección "aleatoria" de cada 10 días. (El cnt El valor en el CTE es un valor de depuración. No juega un papel en los resultados finales). El orden descendente para el rn columna asegura que se incluyan los 60 días y luego la mayor cantidad posible del pasado.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Nuestra tabla ahora se completa con cada fila que es valiosa para el usuario hoy y una selección de filas históricas. Si la columna TheTripdate era anulable, la inserción también habría incluido lo siguiente:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
A continuación, actualizamos las estadísticas en el índice de nuestra tabla temporal.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Ahora, exporte esas estadísticas a una tabla temporal. Esa mesa se parece a esto. Coincide con la salida de DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS tiene una opción para exportar las estadísticas como un flujo. Es esa corriente la que queremos. Esa transmisión también es la misma transmisión que UPDATE STATISTICS usos de la opción de flujo. Para hacer eso:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); El paso final es crear el SQL que actualiza las estadísticas de nuestra tabla de destino y luego ejecutarlo.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); En este punto, hemos reemplazado el histograma con uno personalizado. Puede verificar revisando el histograma:
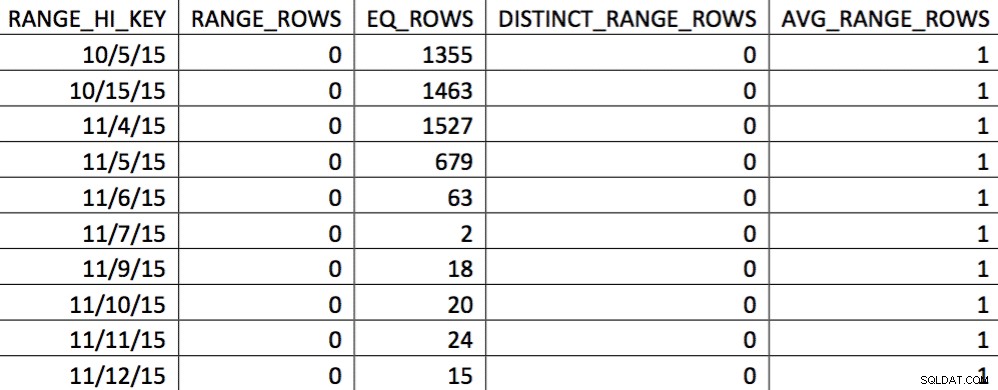
En esta selección de los datos del 4/11, se representan todos los días desde el 4/11 en adelante, y los datos históricos se representan y son precisos. Al revisar la parte del plan de consulta que se mostró anteriormente, puede ver que el optimizador hizo una mejor elección según las estadísticas corregidas:
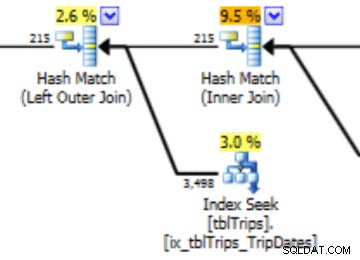
Hay un beneficio de rendimiento para las estadísticas importadas. El costo de calcular las estadísticas está en una tabla "fuera de línea". El único tiempo de inactividad de la mesa de producción es la duración de la importación de secuencias.
Este proceso utiliza funciones no documentadas y parece que podría ser peligroso, pero recuerde que hay una manera fácil de deshacerlo:la declaración de estadísticas de actualización. Si algo sale mal, las estadísticas siempre se pueden actualizar usando T-SQL estándar.
Programar este código para que se ejecute regularmente puede ayudar mucho al optimizador a producir mejores planes dado un conjunto de datos que cambia sobre el punto de inflexión pero no lo suficiente como para desencadenar una actualización de estadísticas.
Cuando terminé el primer borrador de este artículo, el recuento de filas en la tabla del primer gráfico cambió de 217 a 717. Eso es un cambio del 300 %. Eso es suficiente para cambiar el comportamiento del optimizador, pero no para activar una actualización de estadísticas. Este cambio de datos habría dejado un mal plan en marcha. Es con el proceso descrito aquí que este problema se resuelve.
Referencias:
- ACTUALIZAR ESTADÍSTICAS (Libros en línea)
- Informe sobre estadísticas de SQL 2008
- Búsqueda de puntos de inflexión