Este artículo explora algunas características y limitaciones del optimizador de consultas menos conocidas, y explica las razones del rendimiento extremadamente bajo de la unión hash en un caso específico.
Datos de muestra
El script de creación de datos de muestra que sigue se basa en una tabla de números existente. Si aún no tiene uno de estos, puede usar el siguiente script para crear uno de manera eficiente. La tabla resultante contendrá una sola columna de enteros con números del uno al millón:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
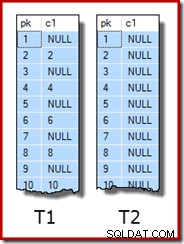
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Los datos de muestra en sí consisten en dos tablas, T1 y T2. Ambos tienen una columna de clave primaria entera secuencial denominada pk y una segunda columna que acepta valores NULL denominada c1. La tabla T1 tiene 600 000 filas donde las filas pares tienen el mismo valor para c1 que la columna pk y las filas impares son nulas. La tabla c2 tiene 32 000 filas donde la columna c1 es NULL en cada fila. El siguiente script crea y completa estas tablas:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Las primeras diez filas de datos de muestra en cada tabla se ven así:
Unir las dos mesas
Esta primera prueba implica unir las dos tablas en la columna c1 (no la columna pk) y devolver el valor pk de la tabla T1 para las filas que se unen:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
La consulta en realidad no devolverá filas porque la columna c1 es NULL en todas las filas de la tabla T2, por lo que ninguna fila puede coincidir con el predicado de combinación de igualdad. Esto puede sonar extraño, pero estoy seguro de que se basa en una consulta de producción real (muy simplificada para facilitar la discusión).
Tenga en cuenta que este resultado vacío no depende de la configuración de ANSI_NULLS, porque eso solo controla cómo se manejan las comparaciones con una variable o un literal nulo. Para comparaciones de columnas, un predicado de igualdad siempre rechaza valores nulos.
El plan de ejecución de esta consulta de combinación simple tiene algunas características interesantes. Primero veremos el plan de ejecución previa ("estimado") en SQL Sentry Plan Explorer:
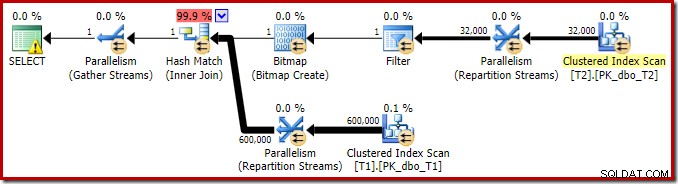
La advertencia en el icono SELECCIONAR solo se queja de que falta un índice en la tabla T1 para la columna c1 (con pk como columna incluida). La sugerencia de índice es irrelevante aquí.
El primer elemento real de interés en este plan es el Filtro:
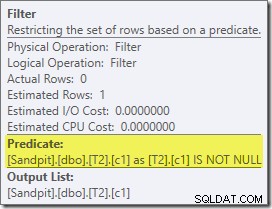
Este predicado NO ES NULO no aparece en la consulta de origen, aunque está implícito en el predicado de unión como se mencionó anteriormente. Es interesante que se haya desglosado como un operador adicional explícito y se haya colocado antes de la operación de unión. Tenga en cuenta que incluso sin el filtro, la consulta aún produciría resultados correctos:la unión en sí misma aún rechazaría los valores nulos.
El filtro también es curioso por otras razones. Tiene un costo estimado de exactamente cero (aunque se espera que opere en 32 000 filas) y no se ha incluido en el Análisis de índice agrupado como un predicado residual. El optimizador normalmente está muy interesado en hacer esto.
Ambas cosas se explican por el hecho de que este filtro se introduce en una reescritura posterior a la optimización. Una vez que el optimizador de consultas completa su procesamiento basado en costos, hay una cantidad relativamente pequeña de reescrituras de planes fijos que se consideran. Uno de estos es el encargado de introducir el Filtro.
Podemos ver el resultado de la selección del plan basado en costos (antes de la reescritura) usando marcas de seguimiento no documentadas 8607 y el conocido 3604 para dirigir el resultado textual a la consola (pestaña de mensajes en SSMS):
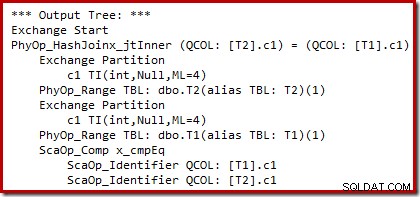
El árbol de salida muestra una unión hash, dos escaneos y algunos operadores de paralelismo (intercambio). No hay filtro de rechazo nulo en la columna c1 de la tabla T2.
La reescritura particular posterior a la optimización analiza exclusivamente la entrada de compilación de una unión hash. Dependiendo de su evaluación de la situación, puede agregar un filtro explícito para rechazar las filas que son nulas en la clave de unión. El efecto del filtro en los recuentos de filas estimados también se escribe en el plan de ejecución, pero debido a que la optimización basada en costos ya se completó, no se calcula un costo para el filtro. En caso de que no sea obvio, calcular los costos es una pérdida de esfuerzo si ya se han tomado todas las decisiones basadas en costos.
El filtro permanece directamente en la entrada de compilación en lugar de ser empujado hacia abajo en el escaneo de índice agrupado porque la actividad de optimización principal se ha completado. Las reescrituras posteriores a la optimización son, de hecho, ajustes de última hora a un plan de ejecución completo.
Una segunda reescritura posterior a la optimización, bastante separada, es responsable del operador de mapa de bits en el plan final (puede que haya notado que también faltaba en la salida 8607):
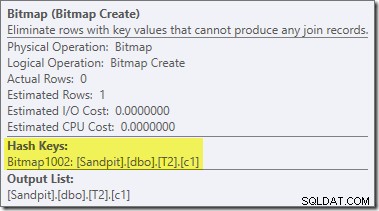
Este operador también tiene un costo estimado cero para E/S y CPU. La otra cosa que lo identifica como un operador introducido por un ajuste tardío (en lugar de durante la optimización basada en costos) es que su nombre es Mapa de bits seguido de un número. Hay otros tipos de mapas de bits introducidos durante la optimización basada en costos, como veremos más adelante.
Por ahora, lo importante de este mapa de bits es que registra los valores de c1 vistos durante la fase de construcción de la unión hash. El mapa de bits completo se envía al lado de sondeo de la unión cuando el hash pasa de la fase de creación a la fase de sondeo. El mapa de bits se usa para realizar una reducción temprana de semiunión, eliminando filas del lado de la sonda que posiblemente no puedan unirse. si necesita más detalles sobre esto, consulte mi artículo anterior sobre el tema.
El segundo efecto del mapa de bits se puede ver en el escaneo de índice agrupado del lado de la sonda:
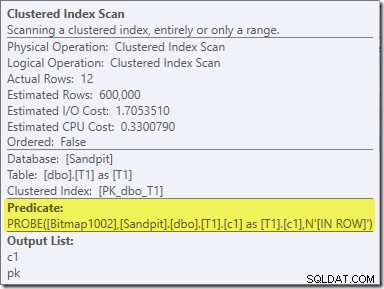
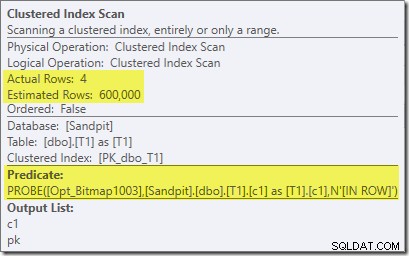
La captura de pantalla anterior muestra el mapa de bits completo que se verifica como parte del escaneo de índice agrupado en la tabla T1. Dado que la columna de origen es un número entero (un bigint también funcionaría), la verificación del mapa de bits se envía completamente al motor de almacenamiento (como lo indica el calificador 'INROW') en lugar de que la verifique el procesador de consultas. Más generalmente, el mapa de bits se puede aplicar a cualquier operador en el lado de la sonda, desde el intercambio hacia abajo. Hasta dónde puede empujar el procesador de consultas el mapa de bits depende del tipo de columna y la versión de SQL Server.
Para completar el análisis de las características principales de este plan de ejecución, debemos observar el plan posterior a la ejecución ("real"):
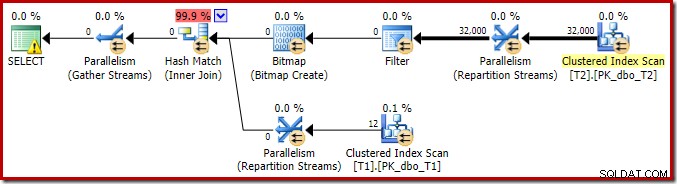
Lo primero que se debe notar es la distribución de filas a través de subprocesos entre el escaneo T2 y el intercambio Repartition Streams inmediatamente superior. En una ejecución de prueba, vi la siguiente distribución en un sistema con cuatro procesadores lógicos:
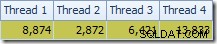
La distribución no es particularmente uniforme, como suele ser el caso de un escaneo paralelo en un número relativamente pequeño de filas, pero al menos todos los subprocesos recibieron algo de trabajo. La distribución de subprocesos entre el mismo intercambio Repartition Streams y el filtro es muy diferente:
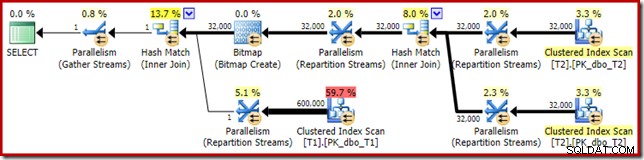
Esto muestra que las 32 000 filas de la tabla T2 fueron procesadas por un solo subproceso. Para ver por qué, necesitamos ver las propiedades de intercambio:

Este intercambio, como el del lado de la sonda de la combinación hash, debe garantizar que las filas con los mismos valores de clave de combinación terminen en la misma instancia de la combinación hash. En DOP 4, hay cuatro combinaciones hash, cada una con su propia tabla hash. Para obtener resultados correctos, las filas del lado de la compilación y las filas del lado de la sonda con las mismas claves de combinación deben llegar a la misma combinación hash; de lo contrario, podríamos comparar una fila del lado de la sonda con la tabla hash incorrecta.
En un plan paralelo en modo fila, SQL Server logra esto al volver a particionar ambas entradas usando la misma función hash en las columnas de unión. En el presente caso, la combinación está en la columna c1, por lo que las entradas se distribuyen entre subprocesos aplicando una función hash (tipo de partición:hash) a la columna clave de combinación (c1). El problema aquí es que la columna c1 contiene solo un valor único, nulo, en la tabla T2, por lo que a las 32 000 filas se les asigna el mismo valor hash, por lo que todas terminan en el mismo subproceso.
La buena noticia es que nada de esto realmente importa para esta consulta. El filtro de reescritura posterior a la optimización elimina todas las filas antes de que se realice mucho trabajo. En mi computadora portátil, la consulta anterior se ejecuta (no produce resultados, como se esperaba) en alrededor de 70 ms .
Unir tres mesas
Para la segunda prueba, agregamos una combinación adicional de la tabla T2 a sí misma en su clave principal:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Esto no cambia los resultados lógicos de la consulta, pero cambia el plan de ejecución:
Como era de esperar, la autocombinación de la tabla T2 en su clave principal no tiene efecto en la cantidad de filas que califican de esa tabla:
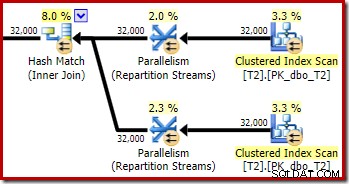
La distribución de filas a través de subprocesos también es buena en esta sección del plan. Para los escaneos, es similar al anterior porque el escaneo en paralelo distribuye filas a subprocesos a pedido. La partición de los intercambios se basa en un hash de la clave de unión, que esta vez es la columna pk. Dado el rango de diferentes valores de pk, la distribución de subprocesos resultante también es muy uniforme:
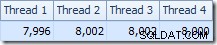
Pasando a la sección más interesante del plan estimado, hay algunas diferencias con la prueba de dos tablas:

Una vez más, el intercambio del lado de la compilación termina enrutando todas las filas al mismo subproceso porque c1 es la clave de combinación y, por lo tanto, la columna de partición para los intercambios de Repartition Streams (recuerde, c1 es nulo para todas las filas en la tabla T2).
Hay otras dos diferencias importantes en esta sección del plan en comparación con la prueba anterior. Primero, no hay un filtro para eliminar las filas null-c1 del lado de compilación de la unión hash. La explicación de eso está ligada a la segunda diferencia:el mapa de bits ha cambiado, aunque no es obvio en la imagen de arriba:
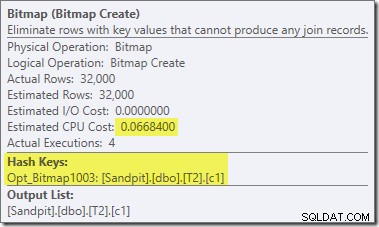
Este es un Opt_Bitmap, no un Bitmap. La diferencia es que este mapa de bits se introdujo durante la optimización basada en costos, no por una reescritura de último minuto. El mecanismo que considera mapas de bits optimizados está asociado con el procesamiento de consultas de unión en estrella. La lógica de unión en estrella requiere al menos tres tablas unidas, por lo que esto explica por qué un optimizado el mapa de bits no se consideró en el ejemplo de combinación de dos tablas.
Este mapa de bits optimizado tiene un costo de CPU estimado distinto de cero y afecta directamente el plan general elegido por el optimizador. Su efecto en la estimación de cardinalidad del lado de la sonda se puede ver en el operador Repartition Streams:
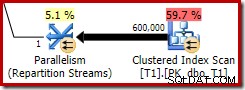
Tenga en cuenta que el efecto de cardinalidad se ve en el intercambio, aunque el mapa de bits finalmente se empuja hacia abajo en el motor de almacenamiento ('INROW') tal como vimos en la primera prueba (pero tenga en cuenta la referencia Opt_Bitmap ahora):
El plan posterior a la ejecución ("real") es el siguiente:
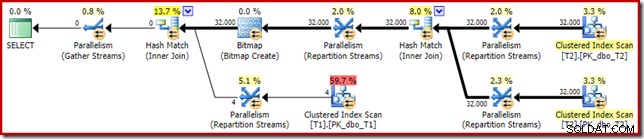
La eficacia prevista del mapa de bits optimizado significa que no se aplica la reescritura posterior a la optimización por separado para el filtro nulo. Personalmente, creo que esto es desafortunado porque la eliminación temprana de los nulos con un filtro anularía la necesidad de construir el mapa de bits, llenar las tablas hash y realizar el escaneo mejorado de mapa de bits de la tabla T1. Sin embargo, el optimizador decide lo contrario y simplemente no hay discusión en este caso.
A pesar de la unión automática adicional de la tabla T2 y el trabajo adicional asociado con el filtro faltante, este plan de ejecución todavía produce el resultado esperado (sin filas) en poco tiempo. Una ejecución típica en mi portátil tarda unos 200 ms .
Cambiar el tipo de datos
Para esta tercera prueba, cambiaremos el tipo de datos de la columna c1 en ambas tablas de entero a decimal. No hay nada particularmente especial en esta elección; el mismo efecto se puede ver con cualquier tipo numérico que no sea entero o bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Reutilización de la consulta de combinación de tres combinaciones:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
El plan de ejecución estimado parece muy familiar:
Aparte del hecho de que el motor de almacenamiento ya no puede aplicar el mapa de bits optimizado 'INROW' debido al cambio de tipo de datos, el plan de ejecución es esencialmente idéntico. La siguiente captura muestra el cambio en las propiedades de escaneo:
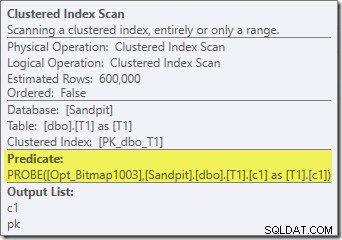
Desafortunadamente, el rendimiento se ve bastante afectado dramáticamente. Esta consulta no se ejecuta en 70 ms o 200 ms, sino en alrededor de 20 minutos . En la prueba que generó el siguiente plan posterior a la ejecución, el tiempo de ejecución fue en realidad de 22 minutos y 29 segundos:

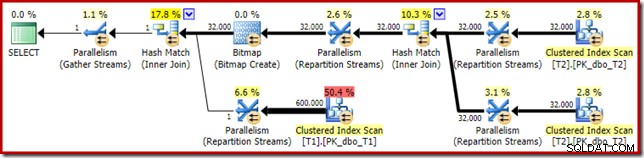
La diferencia más obvia es que el escaneo de índice agrupado en la tabla T1 devuelve 300 000 filas incluso después de aplicar el filtro de mapa de bits optimizado. Esto tiene sentido, ya que el mapa de bits se basa en filas que solo contienen valores nulos en la columna c1. El mapa de bits elimina las filas no nulas del escaneo T1, dejando solo las 300 000 filas con valores nulos para c1. Recuerde, la mitad de las filas en T1 son nulas.
Aun así, parece extraño que unir 32.000 filas con 300.000 filas deba llevar más de 20 minutos. En caso de que se lo pregunte, un núcleo de la CPU se fijó al 100 % para toda la ejecución. La explicación de este rendimiento deficiente y el uso extremo de recursos se basa en algunas ideas que exploramos anteriormente:
Ya sabemos, por ejemplo, que a pesar de los íconos de ejecución en paralelo, todas las filas de T2 terminan en el mismo hilo. Como recordatorio, la unión hash paralela en modo fila requiere volver a particionar en las columnas de unión (c1). Todas las filas de T2 tienen el mismo valor, nulo, en la columna c1, por lo que todas las filas terminan en el mismo subproceso. De manera similar, todas las filas de T1 que pasan el filtro de mapa de bits también tienen un valor nulo en la columna c1, por lo que también se reparten en el mismo subproceso. Esto explica por qué un solo núcleo hace todo el trabajo.
Todavía puede parecer irrazonable que el hash que une 32 000 filas con 300 000 filas tome 20 minutos, especialmente porque las columnas de unión en ambos lados son nulas y no se unirán de todos modos. Para entender esto, debemos pensar en cómo funciona esta unión hash.
La entrada de compilación (las 32 000 filas) crea una tabla hash usando la columna de unión, c1. Dado que cada fila del lado de la compilación contiene el mismo valor (nulo) para la columna de unión c1, esto significa que las 32 000 filas terminan en el mismo cubo hash. Cuando la unión hash cambia a buscar coincidencias, cada fila del lado de la sonda con una columna c1 nula también genera un hash en el mismo depósito. Luego, la unión hash debe verificar las 32 000 entradas en ese depósito para ver si hay una coincidencia.
Al comprobar las 300 000 filas de sonda, se realizan 32 000 comparaciones 300 000 veces. Este es el peor caso para una unión hash:todas las filas laterales compilan hash en el mismo depósito, lo que da como resultado lo que es esencialmente un producto cartesiano. Esto explica el largo tiempo de ejecución y la utilización constante del 100 % del procesador, ya que el hash sigue la larga cadena de cubos de hash.
Este rendimiento deficiente ayuda a explicar por qué existe la reescritura posterior a la optimización para eliminar los valores nulos en la entrada de compilación para una unión hash. Es lamentable que el Filtro no se haya aplicado en este caso.
Soluciones alternativas
El optimizador elige esta forma de plan porque estima incorrectamente que el mapa de bits optimizado filtrará todas las filas de la tabla T1. Aunque esta estimación se muestra en Repartition Streams en lugar de Clustered Index Scan, esta sigue siendo la base de la decisión. Como recordatorio, aquí está nuevamente la sección relevante del plan de ejecución previa:
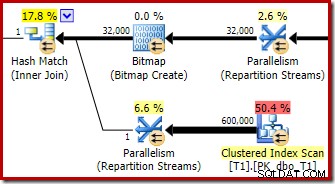
Si esta fuera una estimación correcta, no llevaría nada de tiempo procesar la unión hash. Es lamentable que la estimación de selectividad para el mapa de bits optimizado sea tan incorrecta cuando el tipo de datos no es un entero simple o un bigint. Parece que un mapa de bits creado en una clave entera o bigint también puede filtrar filas nulas que no pueden unirse. Si este es realmente el caso, esta es una razón importante para preferir columnas de unión de enteros o bigint.
Las soluciones alternativas que siguen se basan en gran medida en la idea de eliminar los mapas de bits optimizados problemáticos.
Ejecución en serie
Una forma de evitar que se consideren mapas de bits optimizados es requerir un plan no paralelo. Los operadores de mapas de bits en modo fila (optimizados o no) solo se ven en planes paralelos:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Esa consulta se expresa usando una sintaxis ligeramente diferente con una sugerencia de FORCE ORDER para generar una forma de plan que sea más fácil de comparar con los planes paralelos anteriores. La característica esencial es la pista MAXDOP 1.
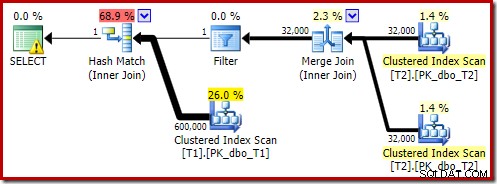
Ese plan estimado muestra que se restablece el filtro de reescritura posterior a la optimización:
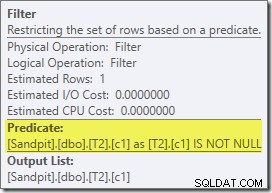
La versión posterior a la ejecución del plan muestra que filtra todas las filas de la entrada de compilación, lo que significa que la exploración del lado de la sonda se puede omitir por completo:
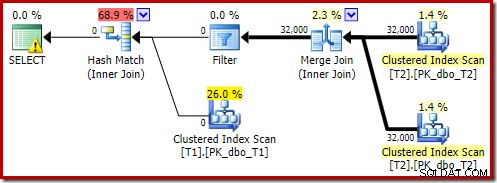
Como era de esperar, esta versión de la consulta se ejecuta muy rápido, alrededor de 20 ms en promedio para mí. Podemos lograr un efecto similar sin la sugerencia FORCE ORDER y la reescritura de consulta:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
El optimizador elige una forma de plan diferente en este caso, con el Filtro colocado directamente sobre el escaneo de T2:
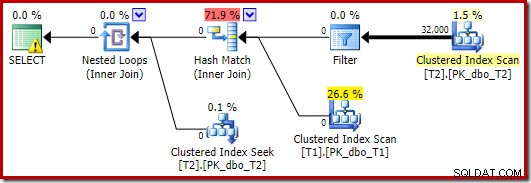
Esto se ejecuta aún más rápido, en aproximadamente 10 ms, como era de esperar. Naturalmente, esta no sería una buena opción si el número de filas presentes (y combinables) fuera mucho mayor.
Desactivar mapas de bits optimizados
No hay una sugerencia de consulta para desactivar los mapas de bits optimizados, pero podemos lograr el mismo efecto usando un par de marcas de seguimiento no documentadas. Como siempre, esto es solo por valor de interés; no querrías volver a usarlos en un sistema o aplicación real:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
El plan de ejecución resultante es:
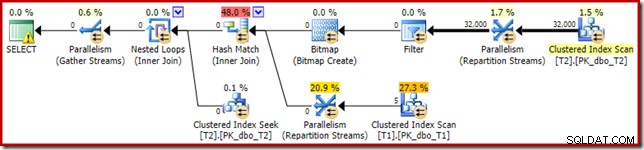
El mapa de bits allí es un mapa de bits de reescritura posterior a la optimización, no un mapa de bits optimizado:
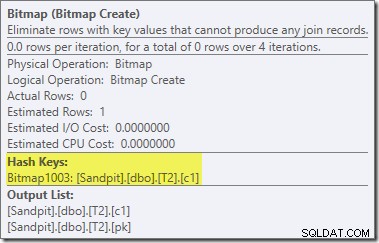
Tenga en cuenta las estimaciones de costo cero y el nombre de mapa de bits (en lugar de Opt_Bitmap). sin un mapa de bits optimizado para sesgar las estimaciones de costos, se activa la reescritura posterior a la optimización para incluir un filtro de rechazo nulo. Este plan de ejecución se ejecuta en alrededor de 70 ms .
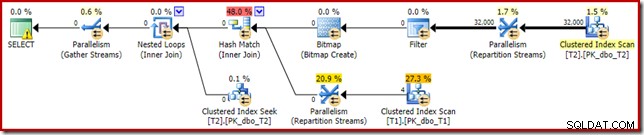
El mismo plan de ejecución (con filtro y mapa de bits no optimizado) también se puede producir desactivando la regla del optimizador responsable de generar planes de mapas de bits de unión en estrella (nuevamente, estrictamente sin documentar y no para uso en el mundo real):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Incluyendo un filtro explícito
Esta es la opción más simple, pero uno solo pensaría en hacerlo si es consciente de los problemas discutidos hasta ahora. Ahora que sabemos que necesitamos eliminar los nulos de T2.c1, podemos agregar esto a la consulta directamente:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! El plan de ejecución estimado resultante quizás no sea exactamente lo que podría esperar:
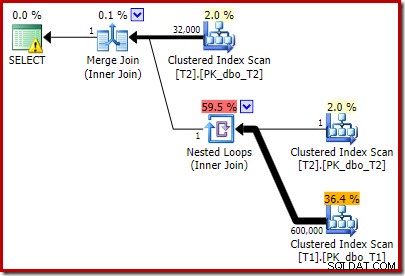
El predicado adicional que agregamos se ha insertado en el escaneo de índice agrupado medio de T2:
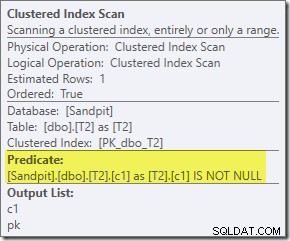
El plan posterior a la ejecución es:
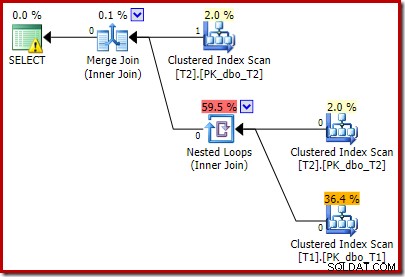
Observe que Merge Join se cierra después de leer una fila de su entrada superior y luego no encuentra una fila en su entrada inferior, debido al efecto del predicado que agregamos. El escaneo de índice agrupado de la tabla T1 nunca se ejecuta en absoluto, porque la combinación de bucles anidados nunca obtiene una fila en su entrada de control. Este formulario de consulta final se ejecuta en uno o dos milisegundos.
Reflexiones finales
Este artículo ha cubierto una buena cantidad de terreno para explorar algunos comportamientos menos conocidos del optimizador de consultas y explicar las razones del rendimiento extremadamente bajo de la unión hash en un caso específico.
Puede ser tentador preguntar por qué el optimizador no agrega de forma rutinaria filtros de rechazo de valores nulos antes de las uniones de igualdad. Uno solo puede suponer que esto no sería beneficioso en suficientes casos comunes. No se espera que la mayoría de las uniones encuentren muchos rechazos nulo =nulo, y agregar predicados de forma rutinaria podría convertirse rápidamente en contraproducente, especialmente si hay muchas columnas de unión presentes. Para la mayoría de las combinaciones, rechazar valores nulos dentro del operador de combinación es probablemente una mejor opción (desde la perspectiva del modelo de costos) que introducir un filtro explícito.
Parece que hay un esfuerzo para evitar que se manifiesten los peores casos a través de la reescritura posterior a la optimización diseñada para rechazar filas de unión nula antes de que alcancen la entrada de compilación de una unión hash. Parece que existe una interacción desafortunada entre el efecto de los filtros de mapa de bits optimizados y la aplicación de esta reescritura. También es desafortunado que cuando ocurre este problema de rendimiento, es muy difícil de diagnosticar solo a partir del plan de ejecución.
Por ahora, la mejor opción parece ser consciente de este posible problema de rendimiento con combinaciones hash en columnas anulables y agregar predicados explícitos de rechazo nulo (¡con un comentario!) para garantizar que se produzca un plan de ejecución eficiente, si es necesario. El uso de una pista MAXDOP 1 también puede revelar un plan alternativo con el filtro revelador presente.
Como regla general, las consultas que se unen en columnas de tipo entero y buscan datos que existen tienden a ajustarse al modelo del optimizador y las capacidades del motor de ejecución bastante mejor que las alternativas.
Agradecimientos
Quiero agradecer a SQL_Sasquatch (@sqL_handLe) por su permiso para responder a su artículo original con un análisis técnico. Los datos de muestra utilizados aquí se basan en gran medida en ese artículo.
También quiero agradecer a Rob Farley (blog | twitter) por nuestras discusiones técnicas a lo largo de los años, y especialmente una en enero de 2015 donde discutimos las implicaciones de los predicados de rechazo nulo adicionales para las uniones equitativas. Rob ha escrito sobre temas relacionados varias veces, incluso en Predicados inversos:mire a ambos lados antes de cruzar.