La clasificación de datos de fecha y hora implica organizar los datos en grupos que representan intervalos fijos de tiempo con fines analíticos. A menudo, la entrada son datos de series de tiempo almacenados en una tabla donde las filas representan mediciones tomadas a intervalos de tiempo regulares. Por ejemplo, las mediciones podrían ser lecturas de temperatura y humedad tomadas cada 5 minutos, y desea agrupar los datos utilizando cubos por hora y calcular agregados como el promedio por hora. Aunque los datos de series temporales son una fuente común para el análisis basado en cubos, el concepto es igualmente relevante para cualquier dato que involucre atributos de fecha y hora y medidas asociadas. Por ejemplo, es posible que desee organizar los datos de ventas en cubos de año fiscal y calcular agregados como el valor total de ventas por año fiscal. En este artículo, cubro dos métodos para agrupar datos de fecha y hora. Uno usa una función llamada DATE_BUCKET, que en el momento de escribir este artículo solo está disponible en Azure SQL Edge. Otro es usar un cálculo personalizado que emula la función DATE_BUCKET, que puede usar en cualquier versión, edición y tipo de SQL Server y Azure SQL Database.
En mis ejemplos, usaré la base de datos de muestra TSQLV5. Puede encontrar el script que crea y completa TSQLV5 aquí y su diagrama ER aquí.
DATE_BUCKET
Como se mencionó, la función DATE_BUCKET actualmente solo está disponible en Azure SQL Edge. SQL Server Management Studio ya es compatible con IntelliSense, como se muestra en la Figura 1:
 Figura 1:soporte de inteligencia para DATE_BUCKET en SSMS
Figura 1:soporte de inteligencia para DATE_BUCKET en SSMS
La sintaxis de la función es la siguiente:
DATE_BUCKET (La entrada origen representa un punto de anclaje en la flecha del tiempo. Puede ser de cualquiera de los tipos de datos de fecha y hora admitidos. Si no se especifica, el valor predeterminado es 1900, 1 de enero, medianoche. Luego, puede imaginar que la línea de tiempo se divide en intervalos discretos que comienzan con el punto de origen, donde la duración de cada intervalo se basa en las entradas ancho del cubo y parte de la fecha . El primero es la cantidad y el segundo la unidad. Por ejemplo, para organizar la escala de tiempo en unidades de 2 meses, especificaría 2 como el ancho del cubo entrada y mes como la parte de la fecha entrada.
La marca de tiempo de entrada es un punto arbitrario en el tiempo que debe asociarse con su depósito contenedor. Su tipo de datos debe coincidir con el tipo de datos del origen de entrada . La marca de tiempo de entrada es el valor de fecha y hora asociado con las medidas que está capturando.
La salida de la función es entonces el punto de partida del cubo contenedor. El tipo de datos de la salida es el de la entrada timestamp .
Si aún no era obvio, generalmente usaría la función DATE_BUCKET como un elemento de conjunto de agrupación en la cláusula GROUP BY de la consulta y, naturalmente, también lo devolvería en la lista SELECT, junto con las medidas agregadas.
¿Todavía está un poco confundido acerca de la función, sus entradas y su salida? Tal vez ayudaría un ejemplo específico con una representación visual de la lógica de la función. Comenzaré con un ejemplo que usa variables de entrada y más adelante en el artículo demostraré la forma más típica en que lo usaría como parte de una consulta en una tabla de entrada.
Considere el siguiente ejemplo:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Puede encontrar una representación visual de la lógica de la función en la Figura 2.
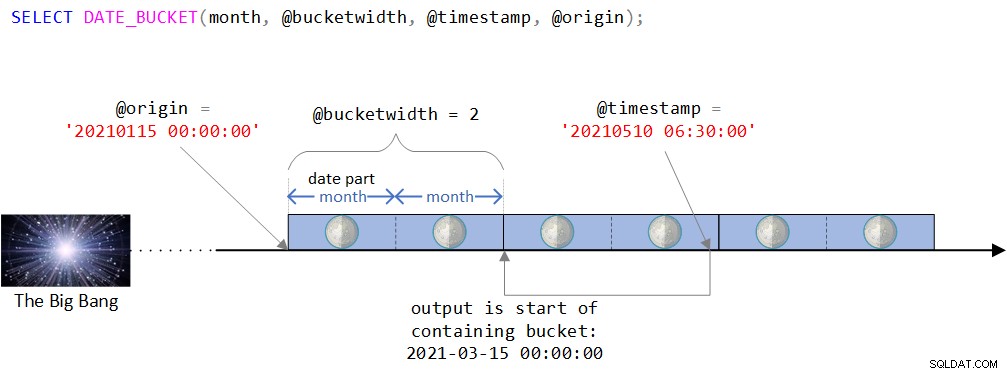 Figura 2:Representación visual de la lógica de la función DATE_BUCKET
Figura 2:Representación visual de la lógica de la función DATE_BUCKET
Como puede ver en la Figura 2, el punto de origen es el valor DATETIME2 del 15 de enero de 2021 a la medianoche. Si este punto de origen parece un poco extraño, estaría en lo correcto al sentir intuitivamente que normalmente usaría uno más natural como el comienzo de algún año o el comienzo de algún día. De hecho, a menudo estaría satisfecho con el valor predeterminado, que, como recordará, es el 1 de enero de 1900 a la medianoche. Intencionalmente quería usar un punto de origen menos trivial para poder discutir ciertas complejidades que podrían no ser relevantes cuando se usa uno más natural. Más sobre esto en breve.
Luego, la línea de tiempo se divide en intervalos discretos de 2 meses a partir del punto de origen. La marca de tiempo de entrada es el valor DATETIME2 del 10 de mayo de 2021 a las 6:30 a. m.
Observe que la marca de tiempo de entrada es parte del depósito que comienza el 15 de marzo de 2021 a medianoche. De hecho, la función devuelve este valor como un valor de tipo DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Emular DATE_BUCKET
A menos que esté usando Azure SQL Edge, si desea dividir en cubos los datos de fecha y hora, por el momento necesitará crear su propia solución personalizada para emular lo que hace la función DATE_BUCKET. Hacerlo no es demasiado complejo, pero tampoco demasiado simple. Tratar con datos de fecha y hora a menudo implica una lógica complicada y trampas con las que debe tener cuidado.
Construiré el cálculo en pasos y usaré las mismas entradas que usé con el ejemplo DATE_BUCKET que mostré anteriormente:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Asegúrese de incluir esta parte antes de cada uno de los ejemplos de código que mostraré si realmente desea ejecutar el código.
En el Paso 1, utiliza la función DATEDIFF para calcular la diferencia en parte de la fecha unidades entre origen y marca de tiempo . Me referiré a esta diferencia como diff1 . Esto se hace con el siguiente código:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Con nuestras entradas de muestra, esta expresión devuelve 4.
La parte complicada aquí es que necesitas calcular cuántas unidades enteras de parte de la fecha existen entre origen y marca de tiempo . Con nuestras entradas de muestra, hay 3 meses completos entre los dos y no 4. La razón por la que la función DATEDIFF informa 4 es que, cuando calcula la diferencia, solo observa la parte solicitada de las entradas y las partes superiores, pero no las inferiores. . Entonces, cuando solicita la diferencia en meses, la función solo se preocupa por las partes de año y mes de las entradas y no por las partes debajo del mes (día, hora, minuto, segundo, etc.). De hecho, hay 4 meses entre enero de 2021 y mayo de 2021, pero solo 3 meses completos entre las entradas completas.
Entonces, el propósito del Paso 2 es calcular cuántas unidades enteras de parte de la fecha existen entre origen y marca de tiempo . Me referiré a esta diferencia como diff2 . Para lograr esto, puede agregar diff1 unidades de parte de la fecha al origen . Si el resultado es mayor que timestamp , restas 1 de diff1 para calcular diff2 , de lo contrario, reste 0 y, por lo tanto, use diff1 como diff2 . Esto se puede hacer usando una expresión CASE, así:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Esta expresión devuelve 3, que es el número de meses completos entre las dos entradas.
Recuerde que anteriormente mencioné que en mi ejemplo usé intencionalmente un punto de origen que no es uno natural, como un comienzo redondo de un período, para poder discutir ciertas complejidades que luego podrían ser relevantes. Por ejemplo, si usa mes como parte de la fecha y el comienzo exacto de algún mes (1 de algún mes a la medianoche) como origen, puede omitir el paso 2 y usar diff1 como diff2 . Eso es porque origen + diferencia1 nunca puede ser> marca de tiempo En ese caso. Sin embargo, mi objetivo es proporcionar una alternativa lógicamente equivalente a la función DATE_BUCKET que funcione correctamente para cualquier punto de origen, común o no. Por lo tanto, incluiré la lógica para el Paso 2 en mis ejemplos, pero recuerde que cuando identifique casos en los que este paso no sea relevante, puede eliminar con seguridad la parte en la que resta la salida de la expresión CASE.
En el Paso 3, identifica cuántas unidades de parte de la fecha hay en cubos enteros que existen entre origen y marca de tiempo . Me referiré a este valor como diff3 . Esto se puede hacer con la siguiente fórmula:
diff3 = diff2 / <bucket width> * <bucket width>
El truco aquí es que cuando se usa el operador de división / en T-SQL con operandos enteros, se obtiene una división entera. Por ejemplo, 3/2 en T-SQL es 1 y no 1.5. La expresión diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Esta expresión devuelve 2, que es el número de meses en los cubos completos de 2 meses que existen entre las dos entradas.
En el Paso 4, que es el paso final, agrega diff3 unidades de parte de la fecha al origen para calcular el inicio del depósito contenedor. Aquí está el código para lograr esto:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código genera el siguiente resultado:
--------------------------- 2021-03-15 00:00:00.0000000
Como recordará, esta es la misma salida producida por la función DATE_BUCKET para las mismas entradas.
Le sugiero que pruebe esta expresión con varias entradas y partes. Mostraré algunos ejemplos aquí, pero siéntete libre de probar el tuyo propio.
Aquí hay un ejemplo donde origen está ligeramente por delante de timestamp en el mes:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código genera el siguiente resultado:
--------------------------- 2021-03-10 06:30:01.0000000
Tenga en cuenta que el inicio de la cubeta contenedora es en marzo.
Aquí hay un ejemplo donde origen está en el mismo punto dentro del mes que timestamp :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código genera el siguiente resultado:
--------------------------- 2021-05-10 06:30:00.0000000
Tenga en cuenta que esta vez el inicio de la cubeta contenedora es en mayo.
Aquí hay un ejemplo con cubos de 4 semanas:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Observe que el código usa la semana parte esta vez.
Este código genera el siguiente resultado:
--------------------------- 2021-02-12 00:00:00.0000000
Aquí hay un ejemplo con cubos de 15 minutos:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Este código genera el siguiente resultado:
--------------------------- 2021-02-03 21:15:00.0000000
Observe que la parte es minuto . En este ejemplo, desea utilizar cubos de 15 minutos que comiencen en la parte inferior de la hora, por lo que funcionaría un punto de origen que sea la parte inferior de cualquier hora. De hecho, un punto de origen que tenga una unidad de minutos de 00, 15, 30 o 45 con ceros en las partes inferiores, con cualquier fecha y hora funcionaría. Entonces, el valor predeterminado que usa la función DATE_BUCKET para la entrada origen trabajaría. Por supuesto, al usar la expresión personalizada, debe ser explícito sobre el punto de origen. Entonces, para simpatizar con la función DATE_BUCKET, podrías usar la fecha base a la medianoche como lo hago en el ejemplo anterior.
Por cierto, ¿puede ver por qué este sería un buen ejemplo en el que es perfectamente seguro omitir el Paso 2 en la solución? Si de hecho elige omitir el Paso 2, obtendrá el siguiente código:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Claramente, el código se vuelve significativamente más simple cuando no se necesita el Paso 2.
Agrupación y agregación de datos por intervalos de fecha y hora
Hay casos en los que necesita dividir en cubos los datos de fecha y hora que no requieren funciones sofisticadas ni expresiones difíciles de manejar. Por ejemplo, suponga que desea consultar la vista Sales.OrderValues en la base de datos TSQLV5, agrupar los datos anualmente y calcular los recuentos y valores totales de pedidos por año. Claramente, es suficiente usar la función YEAR(orderdate) como el elemento del conjunto de agrupación, así:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Este código genera el siguiente resultado:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Pero, ¿qué pasaría si quisiera clasificar los datos por año fiscal de su organización? Algunas organizaciones utilizan un año fiscal para fines contables, presupuestarios y de informes financieros, no alineados con el año calendario. Supongamos, por ejemplo, que el año fiscal de su organización opera en un calendario fiscal de octubre a septiembre y se denota por el año calendario en el que finaliza el año fiscal. Entonces, un evento que tuvo lugar el 3 de octubre de 2018 pertenece al año fiscal que comenzó el 1 de octubre de 2018, finalizó el 30 de septiembre de 2019 y se denota por el año 2019.
Esto es bastante fácil de lograr con la función DATE_BUCKET, así:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Y aquí está el código usando el equivalente lógico personalizado de la función DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Este código genera el siguiente resultado:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Usé variables aquí para el ancho del cubo y el punto de origen para generalizar el código, pero puede reemplazarlas con constantes si siempre usa las mismas y luego simplificar el cálculo según corresponda.
Como una ligera variación de lo anterior, suponga que su año fiscal se extiende desde el 15 de julio de un año calendario hasta el 14 de julio del siguiente año calendario, y se denota por el año calendario al que pertenece el comienzo del año fiscal. Entonces, un evento que tuvo lugar el 18 de julio de 2018 pertenece al año fiscal 2018. Un evento que tuvo lugar el 14 de julio de 2018 pertenece al año fiscal 2017. Usando la función DATE_BUCKET, lograría esto así:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Puede ver los cambios en comparación con el ejemplo anterior en los comentarios.
Y aquí está el código que usa el equivalente lógico personalizado a la función DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Este código genera el siguiente resultado:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Obviamente, existen métodos alternativos que podría utilizar en casos específicos. Tome el ejemplo anterior al último, donde el año fiscal va de octubre a septiembre y se denota por el año calendario en el que finaliza el año fiscal. En tal caso, podría usar la siguiente expresión, mucho más simple:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Y luego su consulta se vería así:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Sin embargo, si desea una solución generalizada que funcione en muchos más casos y que pueda parametrizar, naturalmente querrá usar la forma más general. Si tiene acceso a la función DATE_BUCKET, genial. Si no lo hace, puede usar el equivalente lógico personalizado.
Conclusión
La función DATE_BUCKET es una función bastante útil que le permite dividir en cubos los datos de fecha y hora. Es útil para manejar datos de series temporales, pero también para dividir en cubos cualquier dato que involucre atributos de fecha y hora. En este artículo, expliqué cómo funciona la función DATE_BUCKET y brindé un equivalente lógico personalizado en caso de que la plataforma que está utilizando no lo admita.



