En todo el mundo, el sitio del portal de empleo es una característica bien conocida del panorama de Internet. Grandes jugadores como Indeed y Monster han convertido la búsqueda de empleo y el reclutamiento en una verdadera industria en línea. Profundicemos en las características elementales aprovechadas por los portales de empleo y construyamos un modelo de datos que pueda respaldarlas.
A la gente le encanta ahorrar tiempo mediante el uso de innovaciones tecnológicas; el portal de empleo en línea es otra versión de trabajar de manera más inteligente, no más difícil. Tanto los buscadores de empleo como las empresas se dan cuenta del valor de realizar su búsqueda en línea:obtienen un mejor alcance a velocidades más altas y costos más bajos.
La industria de los portales de empleo está bastante estabilizada ahora, al menos con respecto a los volúmenes de tráfico. Los buscadores de empleo están utilizando estos portales para encontrar puestos en muchas industrias, yendo más allá de TI a sectores como ingeniería, ventas, manufactura y servicios financieros. Sin embargo, están recibiendo una dura competencia de las redes sociales y sitios de redes profesionales como LinkedIn. Pero aún hay oportunidades por explorar, como expandir su penetración a áreas rurales y ciudades más pequeñas.
Entonces, como dijimos, vamos a explorar este tema desde la perspectiva del diseño de la base de datos. Empecemos por enumerar las expectativas fundamentales de un portal de empleo.
¿Qué espera la gente de un portal de empleo en línea?
Tanto los empleadores como los solicitantes de empleo esperan las siguientes funcionalidades de un sitio de trabajo en línea:
- Las personas pueden registrarse como solicitantes de empleo, crear sus perfiles y buscar trabajos que coincidan con sus habilidades.
- Los usuarios pueden cargar sus currículos existentes. Si no tienen uno, deberían poder completar un formulario y tener un currículum creado para ellos.
- Las personas pueden postularse directamente a los trabajos publicados.
- Las empresas pueden registrarse, publicar trabajos y buscar perfiles de buscadores de empleo.
- Múltiples representantes de una empresa deberían poder registrarse y publicar trabajos.
- Los representantes de la empresa pueden ver una lista de solicitantes de empleo y pueden contactarlos, iniciar una entrevista o realizar alguna otra acción relacionada con su puesto.
- Los usuarios registrados deberían poder buscar trabajos y filtrar los resultados según la ubicación, las habilidades requeridas, el salario, el nivel de experiencia, etc.
Construcción del modelo de datos
Después de considerar los requisitos anteriores, se me ocurrieron tres amplias categorías funcionales:
- Gestión de usuarios – Cómo gestiona el portal a los usuarios, es decir, buscadores de empleo, personal de recursos humanos y reclutadores independientes o consultores. (A los efectos de este modelo, los representantes de recursos humanos individuales y los reclutadores independientes o consultores se tratan como empresas, al menos en términos de cómo usan el portal).
- Creación de perfiles – Cómo el portal permite a los solicitantes de empleo y organizaciones crear perfiles y currículums.
- Publicar y buscar trabajos – Cómo el portal facilita el proceso de publicación, búsqueda y solicitud de empleo.
Veamos cada una de estas áreas por separado.
1. Administración de usuarios
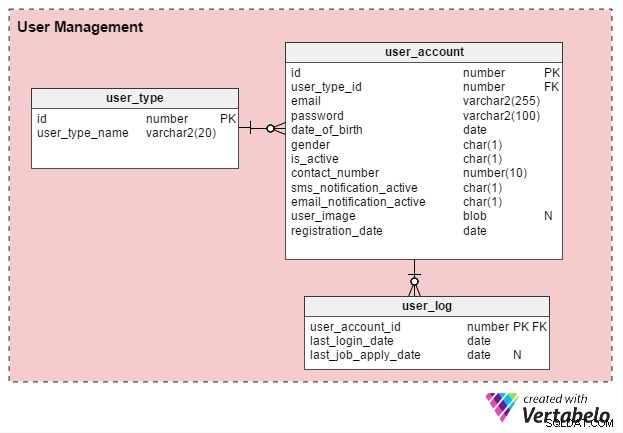
Existen principalmente dos tipos de usuarios del portal de empleo en línea:buscadores de empleo individuales y reclutadores de recursos humanos (o consultores de contratación independientes). Vamos a crear una tabla llamada user_type para almacenar estos registros. Para empezar, tendrá dos registros, uno para buscadores de empleo y otro para reclutadores. (Siempre podemos crear tipos de registros adicionales según sea necesario).
Los usuarios deben registrarse antes de poder utilizar el portal. La user_account table almacena los detalles básicos de su cuenta. Anteriormente consideré nombrar esta tabla como "usuario", pero como usuario es una palabra clave definida por el sistema en casi todas las bases de datos, prefiero quedarme con "cuenta_usuario".
La user_account la tabla tiene las siguientes columnas:
- identificación – Esta es tanto la clave principal de la tabla como un identificador único para cada usuario. Otras tablas del modelo de datos harán referencia a este ID.
- id_tipo_usuario – Esto significa si el usuario es un buscador de empleo o un reclutador.
- correo electrónico – Esta columna contiene la dirección de correo electrónico del usuario. Actúa como otra ID de usuario para el portal.
- contraseña – Esto almacena una contraseña de cuenta encriptada (creada por los usuarios durante el registro).
- fecha_de_nacimiento y género – Como sugieren sus nombres, estas columnas contienen la fecha de nacimiento y el sexo de los usuarios.
- es_activo – Inicialmente, esta columna sería "Y", pero los usuarios pueden configurar su perfil como inactivo o "N". Esta columna almacena su elección.
- número_de_contacto – Este es el número de teléfono (generalmente móvil) proporcionado durante el registro. Los usuarios pueden recibir notificaciones por SMS (texto) en este número. Puede ser el mismo número (o no) que la lista de solicitantes de empleo en su perfil o currículum.
- sms_notification_active y email_notification_active – Estas columnas almacenan las preferencias de los usuarios con respecto a recibir notificaciones a través de mensajes de texto y/o correo electrónico.
- imagen_de_usuario – Este es un atributo de tipo BLOB que almacena la imagen de perfil de cada usuario. Dado que este portal solo permite una imagen de perfil por usuario, tiene sentido almacenarla aquí.
- fecha_de_registro – Esta columna mantiene un registro de cuando el usuario se registró en el portal.
Crearemos una tabla más, user_log , que almacena un registro de la última fecha de inicio de sesión de los usuarios y su última fecha de solicitud de empleo. Hay muchas características que se pueden construir a partir de este conocimiento. Por ejemplo, podemos usar esta información para responder a la pregunta ¿El usuario X está buscando trabajo activamente? ? Si es así, se les puede ofrecer un producto para crear un currículum eficaz. Los usuarios que no estén buscando trabajo de forma activa no recibirán dicha oferta.
2. Construyendo Perfiles
Podemos dividir esta sección en dos áreas:perfiles de empresa u organizaciones y perfiles de buscadores de empleo.
Perfiles de empresa
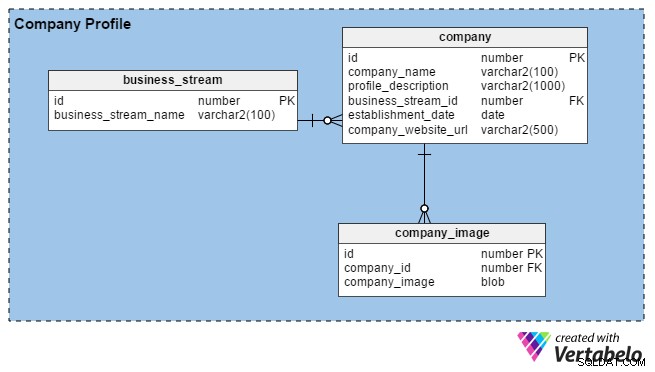
Por lo general, los equipos de recursos humanos crean perfiles de empresa ingresando detalles sobre su organización e imágenes de sus oficinas, edificios, etc. Su principal objetivo es atraer buenos talentos. Cuando los reclutadores se registran en el portal, también pueden crear perfiles de sus empresas (o su marca personal, si son independientes) al proporcionar algunos detalles básicos como cuánto tiempo han estado en el negocio, su ubicación y su flujo comercial principal ( por ejemplo, fabricación, servicios de TI, finanzas, etc.).
El portal permite a los reclutadores de recursos humanos y consultoría cargar tantas imágenes como deseen (a diferencia de los buscadores de empleo, que solo pueden cargar una). Por lo tanto, hemos creado la company_image tabla para almacenar múltiples imágenes para cada cuenta de reclutador. El id_empresa La columna de esta tabla es una clave externa que hace referencia al identificador único utilizado en la company mesa.
En la company tabla, tenemos las siguientes columnas:
- identificación – La clave principal de esta tabla también se utiliza para identificar empresas de forma única.
- nombre_de_la_empresa – Como sugiere el nombre de la columna, contiene el nombre legal de una empresa.
- perfil_descripción – Contiene una breve descripción de cada empresa.
- negocio_stream_id – Esta columna muestra a qué flujo de negocios pertenece una empresa. Por ejemplo, una empresa de exploración de petróleo y gas puede contratar ingenieros de TI, pero su flujo de negocios principal sigue siendo "Petróleo y gas".
- fecha_establecimiento – Esta columna le indica la antigüedad de una empresa.
- url_sitio_web_empresa – Esta es una columna obligatoria (no anulable). Contiene un puntero al sitio web oficial de la empresa para que los solicitantes de empleo puedan encontrar más información.
Finalmente, el business_stream la tabla tiene solo dos atributos, una identificación que es la clave principal para esta tabla y una descripción del flujo comercial principal de la empresa (business_stream_name ).
Perfiles de buscadores de empleo
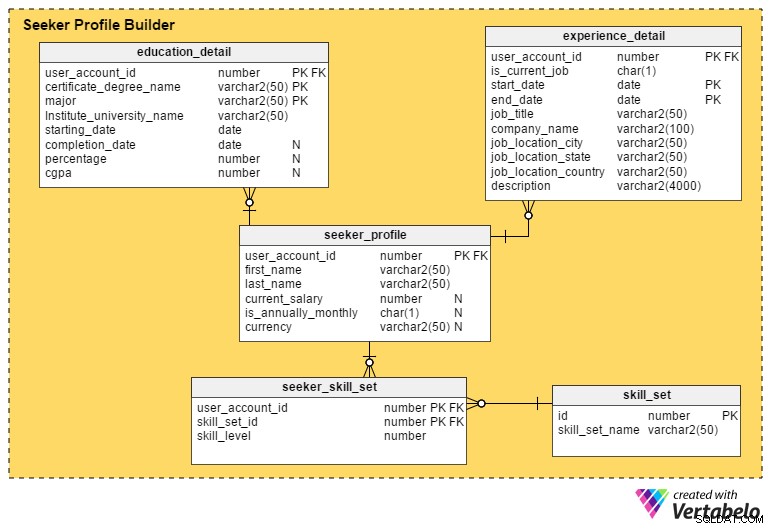
Esta es la sección más crítica de un portal de empleo. A menos que un portal capture tantos detalles como sea posible de los buscadores de empleo, es difícil para los reclutadores preseleccionar los perfiles o candidatos.
El seeker_profile La tabla contiene detalles adicionales que no se capturaron durante el proceso de registro. Contiene estos campos:
- id_de_cuenta_de_usuario – Esta columna se refiere desde
user_accounttabla, y actúa como la clave principal para esta tabla. Garantiza que habrá un máximo de un perfil por solicitante de empleo. - nombre y apellido – Como sugieren los nombres, estas columnas contienen el nombre y apellido del solicitante de empleo.
- salario_actual – Este atributo contiene el salario actual del solicitante de empleo. Es anulable porque es posible que las personas no quieran divulgarlo.
- es_anualmente_mensual – Esto define si el monto de su salario es por año o por mes.
- moneda – Esto almacena la moneda del salario.
El education_detail tabla almacena el historial educativo de cada solicitante de empleo, según lo proporcionado por ellos. Tiene una clave principal compuesta formada por user_account_id , certificado_título_nombre y mayor columnas Esto asegura que los usuarios ingresen solo uno registro para cada grado o certificado. La tabla contiene estos atributos:
- id_de_cuenta_de_usuario – Esta columna se refiere desde
user_accounty sirve como clave principal para esta tabla. - certificado_título_nombre – Este es el tipo de certificado o título; p.ej. bachillerato, bachillerato, grado, posgrado o cédula profesional.
- mayor – Esta columna contiene el curso de estudio principal para el certificado o título – p. una licenciatura con especialización en informática.
- nombre_universidad_instituto – Este es el instituto, escuela o universidad que otorgó el título o certificado.
- fecha_de_inicio – Este atributo almacena la fecha en que el usuario fue aceptado en un programa educativo.
- fecha_de_finalización – Esta es la fecha en que se otorgó el título o certificado. Sin embargo, este atributo admite valores NULL; es posible que las personas aún estén completando su programa mientras buscan trabajo, o pueden haber abandonado el programa por completo.
- porcentaje y cgpa – Estas columnas almacenan el porcentaje de calificación o CGPA (promedio de calificaciones acumulativo) obtenido por los usuarios en su curso de grado o certificado.
La experience_detail tabla mantiene registros de la experiencia profesional pasada y actual de los usuarios. Contiene las siguientes columnas importantes:
- id_de_cuenta_de_usuario – Esta columna se refiere desde
user_accounttable y es la clave principal para esta tabla. - es_trabajo_actual – Esta es una columna indicadora que representa el trabajo actual del usuario. Esta columna también juega un papel importante en la derivación de las ubicaciones actuales de los usuarios y cuánto tiempo han ocupado su puesto actual.
- fecha_de_inicio – Esto almacena cuando un usuario inicia un trabajo.
- fecha_finalización – Esto almacena cuando un usuario finaliza un trabajo.
- job_title:contiene información sobre el puesto de trabajo del usuario.
- nombre_de_la_empresa – Este atributo contiene el nombre de la empresa relevante asociado con un trabajo.
- ubicación_empleo_ciudad – Esto significa la ciudad donde se encuentra el trabajo.
- estado_ubicación_trabajo – Esto significa el estado donde se encuentra el trabajo.
- trabajo_ubicación_país – Esto significa el país donde se encuentra el trabajo.
- descripción – Esta columna almacena detalles sobre funciones y responsabilidades laborales, desafíos y logros.
Los buscadores de empleo pueden poseer múltiples habilidades. Para mantener registros de todos estos conjuntos de habilidades, crearemos la tabla seeker_skill_set . Las columnas son:
- id_de_cuenta_de_usuario – Esta columna se refiere desde
user_accounttable y es la clave principal para esta tabla. - skill_set_id – Esta ID indica qué conjunto de habilidades posee el usuario.
- nivel_de_habilidad – Este atributo numérico cuantifica la experiencia de los buscadores de empleo en una habilidad particular. Un número del 1 (principiante) al 10 (experto) indica su nivel de experiencia.
Finalmente, el skill_set La tabla contiene descripciones de todas las habilidades a las que se hace referencia en el skill_set_id de la tabla anterior. atributo. Contiene solo dos columnas, un skill_set_name y su id relacionado .
3. Publicación y búsqueda de trabajos
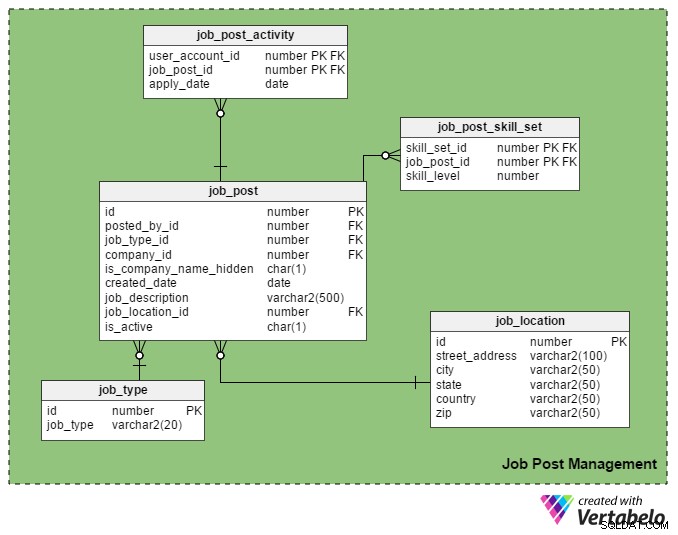
Este es el principal USP (Unique Selling Point) de un portal de empleo. Solo los reclutadores registrados pueden publicar un trabajo en el portal y solo los solicitantes de empleo registrados pueden postularse para ellos.
El job_post table es la tabla principal en esta área temática. Como puede suponer, contiene detalles sobre puestos de trabajo. Todas las demás tablas de esta sección se crean a su alrededor y se vinculan con ella.
- identificación – Esta es la clave principal de esta tabla. A cada puesto de trabajo se le asigna un número único, y este número se menciona en otras tablas.
- publicado_por_id – Esta columna contiene el register_user_id del reclutador que ha publicado el trabajo.
- job_type_id – Esta columna indica si la duración del trabajo es permanente o temporal (contrato).
- id_empresa – Esta columna almacena el ID de la empresa relacionada con el puesto de trabajo. Es una referencia a la
companymesa. - is_company_name_hidden – Esta es una columna indicadora que muestra si el nombre de la empresa debe mostrarse a los solicitantes de empleo. Los reclutadores pueden preferir no mostrar los nombres de las empresas en su publicación. En su lugar, utilizan términos como "Empresa global de automóviles", "Empresa de TI con sede en California", etc.
- fecha_de_creación – Esto almacena la fecha en que se publica el trabajo.
- descripción_del_trabajo – Contiene una breve descripción del trabajo.
- job_ubicación_id – Esto se refiere a un atributo en el
job_locationtabla que almacena la ubicación real del trabajo:dirección, ciudad, estado, país y código postal. - es_activo – Esto significa si un trabajo todavía está abierto. Los reclutadores pueden marcar sus publicaciones como inactivas tan pronto como se llenen los puestos.
El job_post_skill_set La tabla almacena detalles sobre los conjuntos de habilidades necesarios para un trabajo. La estructura de la tabla es idéntica al seeker_skill_set mesa.
Y la última tabla de esta sección, la job_post_activity tabla, contiene detalles sobre qué solicitantes de empleo solicitan un trabajo y cuándo.
¿Qué agregaría a este modelo de datos del portal de empleo en línea?
Los portales de empleo en línea de hoy en día hacen más que proporcionar una plataforma para publicar y solicitar puestos de trabajo. A menudo incluyen otros servicios profesionales como:
- Un panel de control personal para realizar un seguimiento de las solicitudes de empleo
- Actualizaciones en tiempo real de las aplicaciones
- Creadores de currículums en video
- Servicios expertos de redacción de currículums
- LinkedIn u otros creadores de perfiles de redes sociales
- Informes de salarios de puestos de trabajo, empresas, industrias o ubicaciones geográficas
Si quisiéramos incorporar estas características en nuestro sistema, ¿qué cambios adicionales necesitaríamos hacer? ¿Se te ocurren otros imprescindibles en un portal de empleo?
Háganos saber sus puntos de vista en la sección de comentarios.