Esta es la quinta y última parte de la serie que cubre las soluciones al desafío del generador de series numéricas. En la Parte 1, Parte 2, Parte 3 y Parte 4 cubrí soluciones T-SQL puras. Al principio, cuando publiqué el acertijo, varias personas comentaron que la solución con mejor rendimiento probablemente sería una basada en CLR. En este artículo pondremos a prueba esta suposición intuitiva. Específicamente, cubriré las soluciones basadas en CLR publicadas por Kamil Kosno y Adam Machanic.
Muchas gracias a Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea y Paul White por compartir sus ideas y comentarios.
Haré mis pruebas en una base de datos llamada testdb. Use el siguiente código para crear la base de datos si no existe y para habilitar la E/S y las estadísticas de tiempo:
-- DB and stats
SET NOCOUNT ON;
SET STATISTICS IO, TIME ON;
GO
IF DB_ID('testdb') IS NULL CREATE DATABASE testdb;
GO
USE testdb;
GO Para simplificar, deshabilitaré la seguridad estricta de CLR y haré que la base de datos sea confiable usando el siguiente código:
-- Enable CLR, disable CLR strict security and make db trustworthy EXEC sys.sp_configure 'show advanced settings', 1; RECONFIGURE; EXEC sys.sp_configure 'clr enabled', 1; EXEC sys.sp_configure 'clr strict security', 0; RECONFIGURE; EXEC sys.sp_configure 'show advanced settings', 0; RECONFIGURE; ALTER DATABASE testdb SET TRUSTWORTHY ON; GO
Soluciones anteriores
Antes de cubrir las soluciones basadas en CLR, repasemos rápidamente el rendimiento de dos de las mejores soluciones T-SQL.
La solución T-SQL de mejor rendimiento que no usó ninguna tabla base persistente (aparte de la tabla de almacén de columnas vacía ficticia para obtener el procesamiento por lotes) y, por lo tanto, no involucró operaciones de E/S, fue la que se implementó en la función dbo.GetNumsAlanCharlieItzikBatch. Cubrí esta solución en la Parte 1.
Aquí está el código para crear la tabla de almacén de columnas vacía ficticia que usa la consulta de la función:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE); GO
Y aquí está el código con la definición de la función:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Primero probemos la función solicitando una serie de 100 millones de números, con el agregado MAX aplicado a la columna n:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Recuerde, esta técnica de prueba evita transmitir 100 millones de filas a la persona que llama y también evita el esfuerzo de modo de fila involucrado en la asignación de variables cuando se utiliza la técnica de asignación de variables.
Estas son las estadísticas de tiempo que obtuve para esta prueba en mi máquina:
Tiempo de CPU =6719 ms, tiempo transcurrido =6742 ms .La ejecución de esta función no produce lecturas lógicas, por supuesto.
A continuación, probemos con el orden, utilizando la técnica de asignación de variables:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =9468 ms, tiempo transcurrido =9531 ms .Recuerde que esta función no da como resultado una ordenación al solicitar los datos ordenados por n; básicamente obtienes el mismo plan ya sea que solicites los datos solicitados o no. Podemos atribuir la mayor parte del tiempo adicional en esta prueba en comparación con la anterior a las 100 millones de asignaciones de variables basadas en el modo de fila.
La solución T-SQL de mejor rendimiento que utilizó una tabla base persistente y, por lo tanto, resultó en algunas operaciones de E/S, aunque muy pocas, fue la solución de Paul White implementada en la función dbo.GetNums_SQLkiwi. Cubrí esta solución en la Parte 4.
Este es el código de Paul para crear tanto la tabla de almacén de columnas utilizada por la función como la función misma:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Primero probémoslo sin orden usando la técnica agregada, lo que resulta en un plan de modo de lote completo:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Obtuve las siguientes estadísticas de tiempo y E/S para esta ejecución:
Tiempo de CPU =2922 ms, tiempo transcurrido =2943 ms .Tabla 'CS'. Recuento de escaneos 2, lecturas lógicas 0, lecturas físicas 0, servidor de páginas lee 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas lee 0, lob lecturas lógicas 44 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.
Tabla 'CS'. El segmento lee 2, el segmento omitió 0.
Probemos la función con orden usando la técnica de asignación de variables:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Al igual que con la solución anterior, esta solución también evita la clasificación explícita en el plan y, por lo tanto, obtiene el mismo plan ya sea que solicite los datos ordenados o no. Pero nuevamente, esta prueba incurre en una penalización adicional principalmente debido a la técnica de asignación de variables utilizada aquí, lo que da como resultado que la parte de asignación de variables en el plan se procese en modo fila.
Aquí están las estadísticas de tiempo y E/S que obtuve para esta ejecución:
Tiempo de CPU =6985 ms, tiempo transcurrido =7033 ms .Tabla 'CS'. Recuento de escaneos 2, lecturas lógicas 0, lecturas físicas 0, servidor de páginas lee 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas lee 0, lob lecturas lógicas 44 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.
Tabla 'CS'. El segmento lee 2, el segmento omitió 0.
Soluciones CLR
Tanto Kamil Kosno como Adam Machanic primero proporcionaron una solución simple de solo CLR y luego crearon una combinación CLR+T-SQL más sofisticada. Comenzaré con las soluciones de Kamil y luego cubriré las soluciones de Adam.
Soluciones de Kamil Kosno
Aquí está el código CLR utilizado en la primera solución de Kamil para definir una función llamada GetNums_KamilKosno1:
using System;
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsKamil1
{
[Microsoft.SqlServer.Server.SqlFunction(FillRowMethodName = "GetNums_KamilKosno1_Fill", TableDefinition = "n BIGINT")]
public static IEnumerator GetNums_KamilKosno1(SqlInt64 low, SqlInt64 high)
{
return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0) : new GetNumsCS(low.Value, high.Value);
}
public static void GetNums_KamilKosno1_Fill(Object o, out SqlInt64 n)
{
n = (long)o;
}
private class GetNumsCS : IEnumerator
{
public GetNumsCS(long from, long to)
{
_lowrange = from;
_current = _lowrange - 1;
_highrange = to;
}
public bool MoveNext()
{
_current += 1;
if (_current > _highrange) return false;
else return true;
}
public object Current
{
get
{
return _current;
}
}
public void Reset()
{
_current = _lowrange - 1;
}
long _lowrange;
long _current;
long _highrange;
}
} La función acepta dos entradas llamadas low y high y devuelve una tabla con una columna BIGINT llamada n. La función es del tipo de transmisión, devolviendo una fila con el siguiente número en la serie por solicitud de fila de la consulta de llamada. Como puede ver, Kamil eligió el método más formalizado para implementar la interfaz IEnumerator, que implica implementar los métodos MoveNext (hace avanzar el enumerador para obtener la siguiente fila), Current (obtiene la fila en la posición actual del enumerador) y Reset (establece el enumerador a su posición inicial, que es antes de la primera fila).
La variable que contiene el número actual en la serie se llama _actual. El constructor establece _current en el límite inferior del rango solicitado menos 1, y lo mismo ocurre con el método Reset. El método MoveNext avanza _current en 1. Luego, si _current es mayor que el límite superior del rango solicitado, el método devuelve falso, lo que significa que no se volverá a llamar. De lo contrario, devuelve verdadero, lo que significa que se volverá a llamar. El método Current devuelve naturalmente _current. Como puedes ver, una lógica bastante básica.
Llamé al proyecto de Visual Studio GetNumsKamil1 y usé la ruta C:\Temp\ para ello. Aquí está el código que usé para implementar la función en la base de datos testdb:
DROP FUNCTION IF EXISTS dbo.GetNums_KamilKosno1; DROP ASSEMBLY IF EXISTS GetNumsKamil1; GO CREATE ASSEMBLY GetNumsKamil1 FROM 'C:\Temp\GetNumsKamil1\GetNumsKamil1\bin\Debug\GetNumsKamil1.dll'; GO CREATE FUNCTION dbo.GetNums_KamilKosno1(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE(n BIGINT) ORDER(n) AS EXTERNAL NAME GetNumsKamil1.GetNumsKamil1.GetNums_KamilKosno1; GO
Observe el uso de la cláusula ORDER en la instrucción CREATE FUNCTION. La función emite las filas en orden n, por lo que cuando las filas deben ingerirse en el plan en orden n, según esta cláusula, SQL Server sabe que puede evitar una ordenación en el plan.
Probemos la función, primero con la técnica agregada, cuando no se necesita ordenar:
SELECT MAX(n) AS mx FROM dbo.GetNums_KamilKosno1(1, 100000000);
Obtuve el plan que se muestra en la Figura 1.
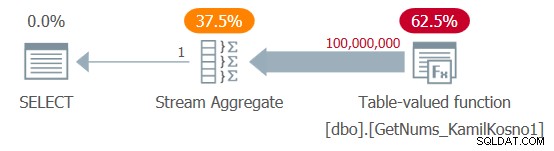 Figura 1:Plan para la función dbo.GetNums_KamilKosno1
Figura 1:Plan para la función dbo.GetNums_KamilKosno1
No hay mucho que decir sobre este plan, aparte del hecho de que todos los operadores usan el modo de ejecución de filas.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =37375 ms, tiempo transcurrido =37488 ms .Y, por supuesto, no hubo lecturas lógicas involucradas.
Probemos la función con orden, usando la técnica de asignación de variables:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_KamilKosno1(1, 100000000) ORDER BY n;
Obtuve el plan que se muestra en la Figura 2 para esta ejecución.
 Figura 2:Plan para la función dbo.GetNums_KamilKosno1 con ORDER BY
Figura 2:Plan para la función dbo.GetNums_KamilKosno1 con ORDER BY
Observe que no hay clasificación en el plan ya que la función se creó con la cláusula ORDER(n). Sin embargo, se hace algún esfuerzo para garantizar que las filas se emitan realmente desde la función en el orden prometido. Esto se hace usando los operadores Segmento y Proyecto de secuencia, que se usan para calcular los números de fila, y el operador Afirmar, que aborta la ejecución de la consulta si la prueba falla. Este trabajo tiene una escala lineal, a diferencia de la escala n log n que hubiera obtenido si se hubiera requerido una ordenación, pero aún así no es barato. Obtuve las siguientes estadísticas de tiempo para esta prueba:
Tiempo de CPU =51531 ms, tiempo transcurrido =51905 ms .Los resultados podrían sorprender a algunos, especialmente a aquellos que asumieron intuitivamente que las soluciones basadas en CLR funcionarían mejor que las de T-SQL. Como puede ver, los tiempos de ejecución son un orden de magnitud más largos que con nuestra solución T-SQL de mejor rendimiento.
La segunda solución de Kamil es un híbrido CLR-T-SQL. Más allá de las entradas baja y alta, la función CLR (GetNums_KamilKosno2) agrega una entrada de paso y devuelve valores entre bajo y alto que están separados entre sí. Aquí está el código CLR que Kamil usó en su segunda solución:
using System;
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsKamil2
{
[Microsoft.SqlServer.Server.SqlFunction(DataAccess = Microsoft.SqlServer.Server.DataAccessKind.None, IsDeterministic = true, IsPrecise = true, FillRowMethodName = "GetNums_Fill", TableDefinition = "n BIGINT")]
public static IEnumerator GetNums_KamilKosno2(SqlInt64 low, SqlInt64 high, SqlInt64 step)
{
return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0, step.Value) : new GetNumsCS(low.Value, high.Value, step.Value);
}
public static void GetNums_Fill(Object o, out SqlInt64 n)
{
n = (long)o;
}
private class GetNumsCS : IEnumerator
{
public GetNumsCS(long from, long to, long step)
{
_lowrange = from;
_step = step;
_current = _lowrange - _step;
_highrange = to;
}
public bool MoveNext()
{
_current = _current + _step;
if (_current > _highrange) return false;
else return true;
}
public object Current
{
get
{
return _current;
}
}
public void Reset()
{
_current = _lowrange - _step;
}
long _lowrange;
long _current;
long _highrange;
long _step;
}
} Llamé al proyecto VS GetNumsKamil2, lo coloqué en la ruta C:\Temp\ también y usé el siguiente código para implementarlo en la base de datos testdb:
-- Create assembly and function
DROP FUNCTION IF EXISTS dbo.GetNums_KamilKosno2;
DROP ASSEMBLY IF EXISTS GetNumsKamil2;
GO
CREATE ASSEMBLY GetNumsKamil2
FROM 'C:\Temp\GetNumsKamil2\GetNumsKamil2\bin\Debug\GetNumsKamil2.dll';
GO
CREATE FUNCTION dbo.GetNums_KamilKosno2
(@low AS BIGINT = 1, @high AS BIGINT, @step AS BIGINT)
RETURNS TABLE(n BIGINT)
ORDER(n)
AS EXTERNAL NAME GetNumsKamil2.GetNumsKamil2.GetNums_KamilKosno2;
GO Como ejemplo para usar la función, aquí hay una solicitud para generar valores entre 5 y 59, con un paso de 10:
SELECT n FROM dbo.GetNums_KamilKosno2(5, 59, 10);
Este código genera el siguiente resultado:
n --- 5 15 25 35 45 55
En cuanto a la parte de T-SQL, Kamil usó una función llamada dbo.GetNums_Hybrid_Kamil2, con el siguiente código:
CREATE OR ALTER FUNCTION dbo.GetNums_Hybrid_Kamil2(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT TOP (@high - @low + 1) V.n
FROM dbo.GetNums_KamilKosno2(@low, @high, 10) AS GN
CROSS APPLY (VALUES(0+GN.n),(1+GN.n),(2+GN.n),(3+GN.n),(4+GN.n),
(5+GN.n),(6+GN.n),(7+GN.n),(8+GN.n),(9+GN.n)) AS V(n);
GO Como puede ver, la función T-SQL invoca la función CLR con las mismas entradas @low y @high que obtiene, y en este ejemplo usa un tamaño de paso de 10. La consulta usa CROSS APPLY entre el resultado de la función CLR y un constructor de valores de tabla que genera los números finales agregando valores en el rango de 0 a 9 al comienzo del paso. El filtro TOP se utiliza para garantizar que no obtenga más de la cantidad de números que solicitó.
Importante: Debo enfatizar que Kamil asume aquí que el filtro TOP se aplica en función del orden del número de resultados, lo que no está realmente garantizado ya que la consulta no tiene una cláusula ORDER BY. Si agrega una cláusula ORDER BY para admitir TOP, o sustituye TOP con un filtro WHERE para garantizar un filtro determinista, esto podría cambiar completamente el perfil de rendimiento de la solución.
En cualquier caso, primero probemos la función sin orden usando la técnica agregada:
SELECT MAX(n) AS mx FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000);
Obtuve el plan que se muestra en la Figura 3 para esta ejecución.
 Figura 3:Plan para la función dbo.GetNums_Hybrid_Kamil2
Figura 3:Plan para la función dbo.GetNums_Hybrid_Kamil2
Nuevamente, todos los operadores en el plan usan el modo de ejecución de filas.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =13985 ms, tiempo transcurrido =14069 ms .Y, naturalmente, no hay lecturas lógicas.
Probemos la función con orden:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000) ORDER BY n;
Obtuve el plan que se muestra en la Figura 4.
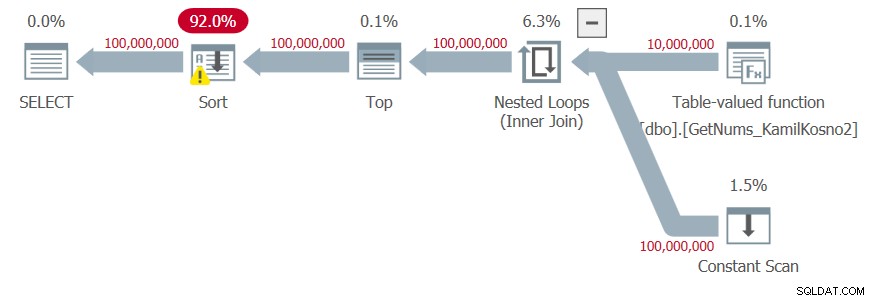 Figura 4:Plan para la función dbo.GetNums_Hybrid_Kamil2 con ORDER BY
Figura 4:Plan para la función dbo.GetNums_Hybrid_Kamil2 con ORDER BY
Dado que los números de resultado son el resultado de la manipulación del límite inferior del paso devuelto por la función CLR y el delta agregado en el constructor de valores de tabla, el optimizador no confía en que los números de resultado se generen en el orden solicitado y agrega clasificación explícita al plan.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =68703 ms, tiempo transcurrido =84538 ms .Entonces parece que cuando no se necesita un orden, la segunda solución de Kamil funciona mejor que la primera. Pero cuando se necesita orden, es al revés. De cualquier manera, las soluciones T-SQL son más rápidas. Personalmente, confiaría en la corrección de la primera solución, pero no en la segunda.
Soluciones de Adam Machanic
La primera solución de Adam también es una función CLR básica que sigue incrementando un contador. Solo que en lugar de usar el enfoque formalizado más complicado como lo hizo Kamil, Adam usó un enfoque más simple que invoca el comando de rendimiento por fila que debe devolverse.
Aquí está el código CLR de Adam para su primera solución, definiendo una función de transmisión llamada GetNums_AdamMachanic1:
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsAdam1
{
[Microsoft.SqlServer.Server.SqlFunction(
FillRowMethodName = "GetNums_AdamMachanic1_fill",
TableDefinition = "n BIGINT")]
public static IEnumerable GetNums_AdamMachanic1(SqlInt64 min, SqlInt64 max)
{
var min_int = min.Value;
var max_int = max.Value;
for (; min_int <= max_int; min_int++)
{
yield return (min_int);
}
}
public static void GetNums_AdamMachanic1_fill(object o, out long i)
{
i = (long)o;
}
}; La solución es tan elegante en su simplicidad. Como puede ver, la función acepta dos entradas llamadas min y max que representan los puntos de límite alto y bajo del rango solicitado, y devuelve una tabla con una columna BIGINT llamada n. La función inicializa las variables llamadas min_int y max_int con los valores de los parámetros de entrada de la función respectiva. Luego, la función ejecuta un ciclo tan largo como min_int <=max_int, que en cada iteración produce una fila con el valor actual de min_int e incrementa min_int en 1. Eso es todo.
Llamé al proyecto GetNumsAdam1 en VS, lo coloqué en C:\Temp\ y usé el siguiente código para implementarlo:
-- Create assembly and function DROP FUNCTION IF EXISTS dbo.GetNums_AdamMachanic1; DROP ASSEMBLY IF EXISTS GetNumsAdam1; GO CREATE ASSEMBLY GetNumsAdam1 FROM 'C:\Temp\GetNumsAdam1\GetNumsAdam1\bin\Debug\GetNumsAdam1.dll'; GO CREATE FUNCTION dbo.GetNums_AdamMachanic1(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE(n BIGINT) ORDER(n) AS EXTERNAL NAME GetNumsAdam1.GetNumsAdam1.GetNums_AdamMachanic1; GO
Usé el siguiente código para probarlo con la técnica agregada, para los casos en que el orden no importa:
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic1(1, 100000000);
Obtuve el plan que se muestra en la Figura 5 para esta ejecución.
 Figura 5:Plan para la función dbo.GetNums_AdamMachanic1
Figura 5:Plan para la función dbo.GetNums_AdamMachanic1
El plan es muy similar al plan que viste anteriormente para la primera solución de Kamil, y lo mismo se aplica a su desempeño. Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =36687 ms, tiempo transcurrido =36952 ms .Y, por supuesto, no se necesitaban lecturas lógicas.
Probemos la función con orden, usando la técnica de asignación de variables:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_AdamMachanic1(1, 100000000) ORDER BY n;
Obtuve el plan que se muestra en la Figura 6 para esta ejecución.
 Figura 6:Plan para la función dbo.GetNums_AdamMachanic1 con ORDER BY
Figura 6:Plan para la función dbo.GetNums_AdamMachanic1 con ORDER BY
Una vez más, el plan se parece al que vio anteriormente para la primera solución de Kamil. No hubo necesidad de una clasificación explícita ya que la función se creó con la cláusula ORDER, pero el plan incluye algo de trabajo para verificar que las filas se devuelvan en el orden prometido.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =55047 ms, tiempo transcurrido =55498 ms .En su segunda solución, Adam también combinó una parte CLR y una parte T-SQL. Aquí está la descripción de Adam de la lógica que usó en su solución:
“Estaba tratando de pensar en cómo solucionar el problema de la charla de SQLCLR, y también el desafío central de este generador de números en T-SQL, que es el hecho de que no podemos simplemente crear filas mágicas.
CLR es una buena respuesta para la segunda parte pero, por supuesto, se ve obstaculizada por el primer problema. Entonces, como compromiso, creé un T-SQL TVF [llamado GetNums_AdamMachanic2_8192] codificado con los valores de 1 a 8192. (Elección bastante arbitraria, pero demasiado grande y el QO comienza a ahogarse un poco). Luego modifiqué mi función CLR [ llamado GetNums_AdamMachanic2_8192_base] para generar dos columnas, "max_base" y "base_add", y tenía filas de salida como:
- max_base, base_add
——————
8191, 1
8192, 8192
8192, 16384
…
8192, 99991552
257, 99999744
Ahora es un bucle simple. La salida de CLR se envía al T-SQL TVF, que está configurado para devolver solo las filas "max_base" de su conjunto codificado. Y para cada fila, agrega "base_add" al valor, generando así los números necesarios. La clave aquí, creo, es que podemos generar N filas con solo una unión cruzada lógica, y la función CLR solo tiene que devolver 1/8192 de tantas filas, por lo que es lo suficientemente rápido como para actuar como generador base".
La lógica parece bastante sencilla.
Aquí está el código usado para definir la función CLR llamada GetNums_AdamMachanic2_8192_base:
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsAdam2
{
private struct row
{
public long max_base;
public long base_add;
}
[Microsoft.SqlServer.Server.SqlFunction(
FillRowMethodName = "GetNums_AdamMachanic2_8192_base_fill",
TableDefinition = "max_base int, base_add int")]
public static IEnumerable GetNums_AdamMachanic2_8192_base(SqlInt64 min, SqlInt64 max)
{
var min_int = min.Value;
var max_int = max.Value;
var min_group = min_int / 8192;
var max_group = max_int / 8192;
for (; min_group <= max_group; min_group++)
{
if (min_int > max_int)
yield break;
var max_base = 8192 - (min_int % 8192);
if (min_group == max_group && max_int < (((max_int / 8192) + 1) * 8192) - 1)
max_base = max_int - min_int + 1;
yield return (
new row()
{
max_base = max_base,
base_add = min_int
}
);
min_int = (min_group + 1) * 8192;
}
}
public static void GetNums_AdamMachanic2_8192_base_fill(object o, out long max_base, out long base_add)
{
var r = (row)o;
max_base = r.max_base;
base_add = r.base_add;
}
}; Llamé al proyecto VS GetNumsAdam2 y lo coloqué en la ruta C:\Temp\ como con los otros proyectos. Aquí está el código que usé para implementar la función en la base de datos testdb:
-- Create assembly and function DROP FUNCTION IF EXISTS dbo.GetNums_AdamMachanic2_8192_base; DROP ASSEMBLY IF EXISTS GetNumsAdam2; GO CREATE ASSEMBLY GetNumsAdam2 FROM 'C:\Temp\GetNumsAdam2\GetNumsAdam2\bin\Debug\GetNumsAdam2.dll'; GO CREATE FUNCTION dbo.GetNums_AdamMachanic2_8192_base(@max_base AS BIGINT, @add_base AS BIGINT) RETURNS TABLE(max_base BIGINT, base_add BIGINT) ORDER(base_add) AS EXTERNAL NAME GetNumsAdam2.GetNumsAdam2.GetNums_AdamMachanic2_8192_base; GO
Aquí hay un ejemplo para usar GetNums_AdamMachanic2_8192_base con el rango de 1 a 100M:
SELECT * FROM dbo.GetNums_AdamMachanic2_8192_base(1, 100000000);
Este código genera el siguiente resultado, que se muestra aquí en forma abreviada:
max_base base_add -------------------- -------------------- 8191 1 8192 8192 8192 16384 8192 24576 8192 32768 ... 8192 99966976 8192 99975168 8192 99983360 8192 99991552 257 99999744 (12208 rows affected)
Aquí está el código con la definición de la función T-SQL GetNums_AdamMachanic2_8192 (abreviado):
CREATE OR ALTER FUNCTION dbo.GetNums_AdamMachanic2_8192(@max_base AS BIGINT, @add_base AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT TOP (@max_base) V.i + @add_base AS val
FROM (
VALUES
(0),
(1),
(2),
(3),
(4),
...
(8187),
(8188),
(8189),
(8190),
(8191)
) AS V(i);
GO Importante: También aquí, debo enfatizar que, de manera similar a lo que dije sobre la segunda solución de Kamil, Adam asume aquí que el filtro SUPERIOR extraerá las filas superiores según el orden de aparición de filas en el constructor de valores de tabla, lo cual no está realmente garantizado. Si agrega una cláusula ORDER BY para admitir TOP o cambia el filtro a un filtro WHERE, obtendrá un filtro determinista, pero esto puede cambiar completamente el perfil de rendimiento de la solución.
Finalmente, aquí está la función T-SQL más externa, dbo.GetNums_AdamMachanic2, a la que llama el usuario final para obtener la serie numérica:
CREATE OR ALTER FUNCTION dbo.GetNums_AdamMachanic2(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT Y.val AS n
FROM ( SELECT max_base, base_add
FROM dbo.GetNums_AdamMachanic2_8192_base(@low, @high) ) AS X
CROSS APPLY dbo.GetNums_AdamMachanic2_8192(X.max_base, X.base_add) AS Y
GO Esta función usa el operador CROSS APPLY para aplicar la función T-SQL interna dbo.GetNums_AdamMachanic2_8192 por fila devuelta por la función CLR interna dbo.GetNums_AdamMachanic2_8192_base.
Primero probemos esta solución usando la técnica agregada cuando el orden no importa:
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic2(1, 100000000);
Obtuve el plan que se muestra en la Figura 7 para esta ejecución.
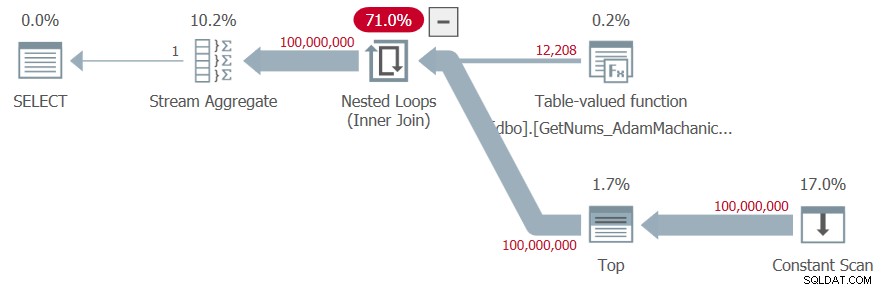 Figura 7:Plan para la función dbo.GetNums_AdamMachanic2
Figura 7:Plan para la función dbo.GetNums_AdamMachanic2
Obtuve las siguientes estadísticas de tiempo para esta prueba:
SQL Server tiempo de análisis y compilación :tiempo de CPU =313 ms, tiempo transcurrido =339 ms .SQL Server tiempo de ejecución :tiempo de CPU =8859 ms, tiempo transcurrido =8849 ms .
No se necesitaron lecturas lógicas.
El tiempo de ejecución no es malo, pero tenga en cuenta el alto tiempo de compilación debido al gran constructor de valores de tabla utilizado. Pagaría un tiempo de compilación tan alto independientemente del tamaño del rango que solicite, por lo que esto es especialmente complicado cuando se usa la función con rangos muy pequeños. Y esta solución es aún más lenta que las de T-SQL.
Probemos la función con orden:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_AdamMachanic2(1, 100000000) ORDER BY n;
Obtuve el plan que se muestra en la Figura 8 para esta ejecución.
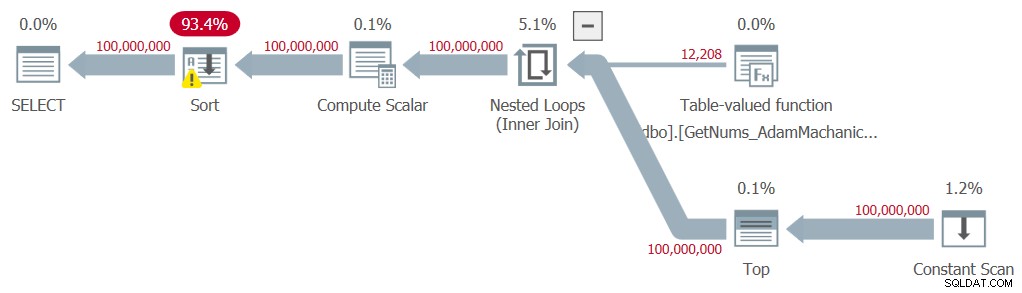 Figura 8:Plan para la función dbo.GetNums_AdamMachanic2 con ORDER BY
Figura 8:Plan para la función dbo.GetNums_AdamMachanic2 con ORDER BY
Al igual que con la segunda solución de Kamil, se necesita una ordenación explícita en el plan, lo que genera una penalización de rendimiento significativa. Aquí están las estadísticas de tiempo que obtuve para esta prueba:
Tiempo de ejecución:tiempo de CPU =54891 ms, tiempo transcurrido =60981 ms .Además, todavía existe la alta penalización de tiempo de compilación de aproximadamente un tercio de segundo.
Conclusión
Fue interesante probar las soluciones basadas en CLR para el desafío de la serie numérica porque muchas personas asumieron inicialmente que la solución con mejor rendimiento probablemente sería una basada en CLR. Kamil y Adam usaron enfoques similares, con el primer intento utilizando un bucle simple que incrementa un contador y produce una fila con el siguiente valor por iteración, y el segundo intento más sofisticado que combina partes de CLR y T-SQL. Personalmente, no me siento cómodo con el hecho de que tanto en la segunda solución de Kamil como en la de Adam se basaron en un filtro TOP no determinista, y cuando lo convertí en uno determinista en mi propia prueba, tuvo un impacto adverso en el rendimiento de la solución. . Either way, our two T-SQL solutions perform better than the CLR ones, and do not result in explicit sorting in the plan when you need the rows ordered. So I don’t really see the value in pursuing the CLR route any further. Figure 9 has a performance summary of the solutions that I presented in this article.
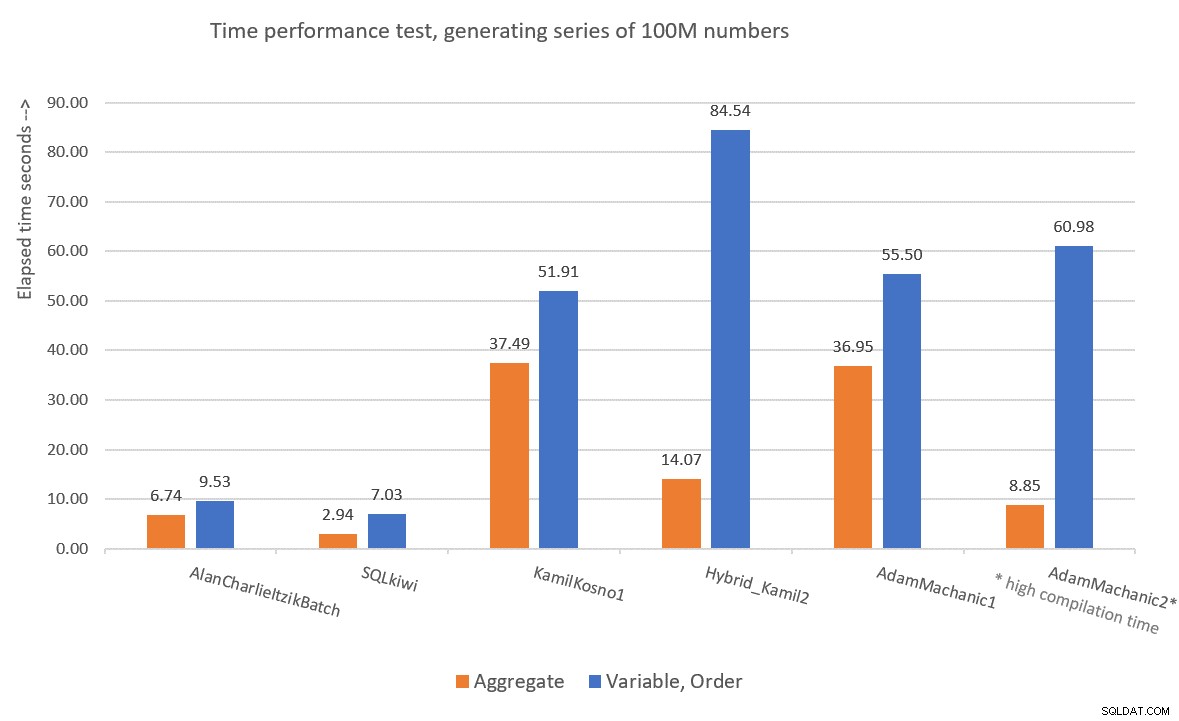 Figure 9:Time performance comparison
Figure 9:Time performance comparison
To me, GetNums_AlanCharlieItzikBatch should be the solution of choice when you require absolutely no I/O footprint, and GetNums_SQKWiki should be preferred when you don’t mind a small I/O footprint. Of course, we can always hope that one day Microsoft will add this critically useful tool as a built-in one, and hopefully if/when they do, it will be a performant solution that supports batch processing and parallelism. So don’t forget to vote for this feature improvement request, and maybe even add your comments for why it’s important for you.
I really enjoyed working on this series. I learned a lot during the process, and hope that you did too.