Las funciones OVER y PARTITION BY son funciones que se utilizan para dividir un conjunto de resultados de acuerdo con criterios específicos.
Este artículo explica cómo se pueden usar estas dos funciones en conjunto para recuperar datos particionados de formas muy específicas.
Preparación de algunos datos de muestra
Para ejecutar nuestras consultas de muestra, primero creemos una base de datos llamada "studentdb".
Ejecute el siguiente comando en su ventana de consulta:
CREATE DATABASE schooldb;
A continuación, debemos crear la tabla "student" dentro de la base de datos "studentdb". La tabla de estudiantes tendrá cinco columnas:id, nombre, edad, sexo y puntuación total.
Como siempre, asegúrese de tener una buena copia de seguridad antes de experimentar con un nuevo código. Consulte este artículo sobre cómo realizar copias de seguridad de las bases de datos de SQL Server si no está seguro.
Ejecute la siguiente consulta para crear la tabla de estudiantes.
USE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
) Finalmente, necesitamos insertar algunos datos ficticios para que podamos trabajar en la base de datos.
USE schooldb
INSERT INTO student
VALUES ('Jolly', 'Female', 20, 500),
('Jon', 'Male', 22, 545),
('Sara', 'Female', 25, 600),
('Laura', 'Female', 18, 400),
('Alan', 'Male', 20, 500),
('Kate', 'Female', 22, 500),
('Joseph', 'Male', 18, 643),
('Mice', 'Male', 23, 543),
('Wise', 'Male', 21, 499),
('Elis', 'Female', 27, 400); Ahora estamos listos para trabajar en un problema y ver a quién podemos usar Over y Partition By para resolverlo.
Problema
Tenemos 10 registros en la tabla de estudiantes y queremos mostrar el nombre, identificación y género de todos los estudiantes, y además también queremos mostrar el número total de estudiantes que pertenecen a cada género, la edad promedio de los estudiantes de cada género y la suma de los valores en la columna total_score para cada género.
El conjunto de resultados que estamos buscando es el siguiente:
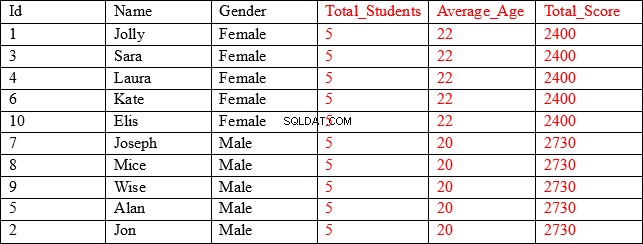
Como puede ver, las primeras tres columnas (que se muestran en negro) contienen valores individuales para cada registro, mientras que las últimas tres columnas (que se muestran en rojo) contienen valores agregados agrupados por la columna de género. Por ejemplo, en la columna Edad_promedio, las primeras cinco filas muestran la edad promedio y la puntuación total de todos los registros donde el género es Mujer.
Nuestro conjunto de resultados contiene resultados agregados combinados con columnas no agregadas.
Para recuperar los resultados agregados, agrupados por una columna en particular, podemos usar la cláusula GROUP BY como de costumbre.
USE schooldb SELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Veamos cómo podemos recuperar Total_Students, Average_Age y Total_Score de los estudiantes agrupados por género.
Verá los siguientes resultados:

Ahora ampliemos esto y agreguemos 'id' y 'nombre' (las columnas no agregadas en la instrucción SELECT) y veamos si podemos obtener el resultado deseado.
USE schooldb SELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_Score FROM student GROUP BY gender
Cuando ejecute la consulta anterior, verá un error:

El error dice que la columna de identificación de la tabla de estudiantes no es válida dentro de la declaración SELECT ya que estamos usando la cláusula GROUP BY en la consulta.
Esto significa que tendremos que aplicar una función agregada en la columna id o tendremos que usarla en la cláusula GROUP BY. En resumen, este esquema no resuelve nuestro problema.
Solución mediante declaración JOIN
Una solución a esto sería hacer uso de la declaración JOIN para unir las columnas con resultados agregados a las columnas que contienen resultados no agregados.
Para hacerlo, necesita una subconsulta que recupere el género, Total_Students, Average_Age y Total_Score de los estudiantes agrupados por género. Estos resultados se pueden unir a los resultados obtenidos de la subconsulta con la instrucción SELECT externa. Esto se aplicará a la columna de género de la subconsulta que contiene el resultado agregado y la columna de género de la tabla de estudiantes. La instrucción SELECT externa incluiría columnas no agregadas, es decir, 'id' y 'nombre', como se muestra a continuación.
USE schooldb SELECT id, name, Aggregation.gender, Aggregation.Total_students, Aggregation.Average_Age, Aggregation.Total_Score FROM student INNER JOIN (SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_score) AS Total_Score FROM student GROUP BY gender) AS Aggregation on Aggregation.gender = student.gender
La consulta anterior le dará el resultado deseado, pero no es la solución óptima. Tuvimos que usar una instrucción JOIN y una subconsulta que aumenta la complejidad del script. Esta no es una solución elegante ni eficiente.
Un mejor enfoque es usar las cláusulas OVER y PARTITION BY en conjunto.
Solución utilizando OVER y PARTITION BY
Para usar las cláusulas OVER y PARTITION BY, simplemente necesita especificar la columna por la que desea particionar sus resultados agregados. Esto se explica mejor con el uso de un ejemplo.
Echemos un vistazo a cómo lograr nuestro resultado usando OVER y PARTITION BY.
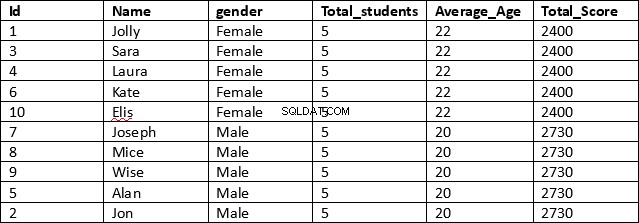
USE schooldb SELECT id, name, gender, COUNT(gender) OVER (PARTITION BY gender) AS Total_students, AVG(age) OVER (PARTITION BY gender) AS Average_Age, SUM(total_score) OVER (PARTITION BY gender) AS Total_Score FROM student
Este es un resultado mucho más eficiente. En la primera línea del script se recuperan las columnas de id, nombre y género. Estas columnas no contienen resultados agregados.
A continuación, para las columnas que contienen resultados agregados, simplemente especificamos la función agregada, seguida de la cláusula OVER y luego, dentro del paréntesis, especificamos la cláusula PARTITION BY seguida del nombre de la columna en la que queremos que se dividan nuestros resultados, como se muestra. a continuación.
Referencias
- Microsoft:comprensión de la cláusula OVER
- DBA de medianoche:introducción a OVER y PARTITION BY
- StackOverflow:diferencia entre PARTICIÓN POR y GRUPO POR