Hay mucho que tener en cuenta al diseñar una base de datos, y muy pocos de nosotros podemos recordar todos los consejos y trucos valiosos que hemos aprendido. Entonces, echemos un vistazo a algunos recursos en línea que presentan consejos y mejores prácticas para el diseño de bases de datos. A medida que avancemos, compartiré mis propias opiniones sobre las ideas presentadas, según mi experiencia en el diseño de bases de datos.
Obviamente, este artículo no es una lista exhaustiva, pero he tratado de revisar y comentar una sección transversal de fuentes. Con suerte, encontrará la información que mejor se adapte a sus necesidades y objetivos.
Como nota al margen, me sorprendió descubrir que muchos artículos relacionados con las prácticas de diseño de bases de datos tenían muy pocos ejemplos; los recursos en línea que revisé para el artículo sobre errores y equivocaciones tenían un mayor porcentaje de ellos. Esta falta es un inconveniente, porque los ejemplos son extremadamente importantes para transmitir el mensaje.
Consejos de base de datos para diseñadores experimentados
Primero, comencemos con las fuentes que presentan consejos y mejores prácticas para el diseño avanzado de bases de datos. Estos son para diseñadores que ya están trabajando en el modelado de datos y lo han estado haciendo durante algún tiempo. Algunos artículos están dirigidos a un nivel más intermedio, pero si tratan conceptos avanzados, los he incluido en esta lista.
Pautas de la base de datos (RDBMS/SQL)
por Steve Djajasaputra | SOA, Java, desarrollo de software – BlogSpot | 16 de enero de 2013
Este artículo del Sr. Djajasaputra es bastante impresionante:enumera numerosos consejos para el esquema, los índices y las vistas; también proporciona una convención de nomenclatura bastante detallada. Y sus consejos siguen (y siguen). La amplitud es impresionante, pero casi no hay ejemplos. Algunos de sus puntos pueden considerarse discutibles, pero en general es una presentación muy sólida.
En particular, me impresionó que dé una regla precisa sobre el uso de claves primarias naturales versus artificiales (es decir, sustitutas o generadas). Mantiene esto agradable y simple, especificando que deberíamos preferir una clave natural porque es significativa. También proporciona pautas para el mejor uso de una clave artificial, específicamente, cuando la clave natural no es única o cuando necesita cambiar el valor de la clave natural. En sus propias palabras:
Primero prefiera usar la clave natural ya que es más significativa y para evitar duplicaciones (reutilice la columna existente). Pero hay casos en los que necesita una clave artificial:cuando la clave natural no es única (por ejemplo, nombres) o si necesita cambiar el valor.Como su lista de consejos es tan larga, no puedo imaginar recordarlos todos. Pero se puede hacer referencia a cada sección cuando se trabaja en el diseño, el rendimiento, los procedimientos almacenados y el control de versiones de la base de datos. También hay una sección sobre puntos específicos de Oracle que sería útil si está trabajando con Oracle o planea brindarle asistencia.
En general, este es un recurso muy valioso y completo.
9 consejos para un mejor diseño de base de datos
de Jeffrey Edison | Vertabelo Blog | 22 de septiembre de 2015
Voy a permitirme un poco de autopromoción aquí.
Este artículo de 9 consejos para un mejor diseño de base de datos se basa en mi experiencia como diseñador y arquitecto. También encontré información adicional al investigar las mejores prácticas de otros para el diseño de bases de datos.
Mi lista representa algunos de los principales problemas que pueden ocurrir al trabajar con modelos de datos. Organicé los consejos en el orden en que ocurren durante el ciclo de vida del proyecto (en lugar de por importancia o con qué frecuencia surgen), ya que eso sería más útil, al menos desde mi punto de vista. Los lectores pueden seguir esta lista de verificación de las mejores prácticas a lo largo del ciclo de vida de un proyecto.
Del artículo:
Parafraseando a Al Capone (o John Van Buren, hijo del octavo presidente de los EE. UU.), "prueba temprano, prueba a menudo". De esta manera, sigues el camino de la Integración Continua. Las pruebas en una etapa temprana de desarrollo ahorran tiempo y dinero. Al probar la base de datos, el objetivo debe ser simular un entorno de producción:"Un día en la vida de la base de datos". ¿Qué volúmenes se pueden esperar? ¿Qué interacciones de usuario son probables? ¿Se están manejando los casos límite?Al prestar atención a estos consejos, descubrí que las bases de datos se vuelven mejor diseñadas y más sólidas. Si bien ninguna de estas actividades llevará una enorme cantidad de tiempo, cada una puede tener un enorme impacto en la calidad de su modelo de datos.
Espero que mi lista de consejos sea útil para diseñadores intermedios y avanzados.
20 prácticas recomendadas para el diseño de bases de datos
por Cagdas Basaraner | Equilibrio de código – BlogSpot | 24 de julio de 2011
El Sr. Basaraner nos presenta una interesante lista de 20 mejores prácticas de diseño de bases de datos. Hubiera preferido que hubiera agrupado algunos de estos; por ejemplo, los primeros cuatro elementos podrían cubrirse bajo "Usar buenas convenciones de nomenclatura".
Además, afirma que usar un ID generado (entero) sintético como clave principal de todas las tablas es una buena práctica. De hecho, este sigue siendo un tema debatido, con argumentos a favor y en contra. Algunas de sus prácticas recomendadas son bastante genéricas, como "Para... sistemas de bases de datos de misión crítica [sic], utilice el servicio de seguridad y recuperación ante desastres..." No estoy en desacuerdo con este punto, pero es de muy alto nivel.
En el lado positivo, este artículo fue uno de los pocos que mencionan el uso de un marco de mapeo relacional de objetos (ORM). Algunos comentaristas no estuvieron de acuerdo con la redacción del consejo, pero al menos se menciona el uso de un marco ORM:
Utilice un marco ORM (mapeo relacional de objetos) (es decir, Hibernate, iBatis...) si el código de la aplicación es lo suficientemente grande. Los problemas de rendimiento de los marcos ORM se pueden manejar mediante parámetros de configuración detallados.Aún así, esta lista podría haber sido mejorada. Debe identificar claramente los puntos que son específicos solo para algunos sistemas de gestión de bases de datos (por ejemplo, SQL Server). Estadísticas precisas sobre rendimiento, heurística o la importancia de dedicar tiempo al diseño en lugar de en mantenimiento y rediseño hubiera sido bueno También se necesitaban más ejemplos, pero eso es un problema para la mayoría de estos artículos.
Si está trabajando con SQL Server, está considerando usar un marco ORM o necesita una lista de consejos con viñetas en lugar de un artículo largo y detallado, entonces este artículo es para usted.
(Nota:este artículo también apareció en varios otros sitios, incluidos CodeBuild, Java Code Geeks y DZone).
Fundamentos de diseño de bases de datos. Diez cosas que definitivamente debes hacer
por Michelle A. Poolet | Servidor SQL Pro | 1 de marzo de 2011
Una parte de los consejos de la Sra. Poolet son bastante estándar y se pueden encontrar en muchos otros recursos, pero también hay algunos puntos poco comunes. Entre sus puntos genéricos, promueve el uso de subtipos y supertipos (con los que estoy totalmente de acuerdo) ya que esto refleja el diseño orientado a objetos y los desarrolladores pueden entenderlo fácilmente. De su artículo:
No tenga miedo de incluir entidades de supertipo y subtipo en su diseño en el CDM y en adelante. Los subtipos representan clasificaciones o categorías del supertipo... Las entidades se representan como subtipos cuando se necesita más de una sola palabra o frase para categorizar la entidad.
Si una categoría tiene vida propia, con atributos separados que describen cómo se ve y se comporta la categoría y separan las relaciones con otras entidades, entonces es hora de invocar la estructura de supertipo/subtipo . De lo contrario, se inhibirá la comprensión completa de los datos y las reglas comerciales que impulsan la recopilación de datos.
Algunos de sus comentarios hacen referencia específica a MS SQL Server incluso si los comentarios son en realidad problemas genéricos. Un punto principal que plantea la Sra. Poolet es muy específico de SQL Server:"Almacene el código que toca los datos de una base de datos como un procedimiento almacenado".
Esto está bien si solo planea admitir un único sistema de administración de bases de datos, como SQL Server. Pero para implementaciones portátiles, este no sería un buen consejo. En general, diseño para la portabilidad a al menos dos sistemas de administración con soporte de lenguaje de procedimiento almacenado diferente. Por lo tanto, evitaría esta práctica.
Este artículo es más útil para las personas que desarrollan para SQL Server y se centran en el mercado estadounidense (en lugar de un sistema internacional). Sin embargo, como estadounidense que vive en el extranjero, descubrí que algunos de sus ejemplos son demasiado "centrados en EE. UU.". Por ejemplo, es posible que un no estadounidense no entienda qué es un Zip+4 el dominio es y, por lo tanto, no entendería por qué este dominio debería tener una característica NOT NULL.
Para ilustrar esto, hice un modelo de datos para ambas direcciones estadounidenses y no estadounidenses. Asumiremos que nuestro modelo de datos puede requerir que las entidades estén vinculadas a más de una dirección:por ejemplo, una para facturación, otra para envío. La primera dirección estaría asociada a un método de pago; en este caso, la dirección se usaría para verificar su derecho a autorizar ese pago. La dirección de envío, obviamente, es donde se entregará el pedido.
Vamos a crear una dirección estadounidense como parte de un modelo de base de datos de pedidos de clientes. (Nota:este no es un modelo completo, sino un ejemplo de almacenamiento de pedidos de productos).
Wise Coders Solutions recomienda definir campos separados para números de casas y nombres de calles y establecer estos campos como NO NULOS; esto rechazaría cualquier dirección que no tenga un número de casa y un nombre de calle. Pero, ¿qué pasa con las personas que usan apartados de correos? Sus direcciones generalmente se escriben como "PO Box 123". ¿Deberíamos obligarlos a poner el número de apartado postal como número de casa y “PO Box” como nombre de la calle? No lo creo.
En su lugar, utilizaremos un formulario con "Línea de dirección 1" y "Línea de dirección 2". Varias personas se han opuesto al uso de números en los nombres de campo, pero para mí esta es una solución bastante obvia. Además, he definido longitudes de campo máximas (35 y 70 caracteres) que son típicas en pagos internacionales.
Tenga en cuenta que los diseños de EE. UU. y fuera de EE. UU. tienen un campo para regiones dentro de un país, pero el diseño de EE. UU. requiere que se incluya una abreviatura de estado de 2 caracteres. Además, tenga en cuenta que el diseño de EE. UU. no permite direcciones en otros países.
Si le preocupa el uso global de su base de datos, debe pensar globalmente durante la fase de diseño. ¿Están nuestras bases de datos preparadas para el uso multinacional de nuestras aplicaciones?
Lecciones aprendidas de un diseño de almacenamiento de datos deficiente
por Michelle A. Poolet | Servidor SQL Pro | 15 de junio de 2009
Este artículo analiza el almacén de datos (DWH) y algunos de sus problemas de diseño e implementación. Hay un ligero enfoque en SQL Server, pero es una descripción general bastante ortodoxa del diseño para el almacenamiento de datos y la inteligencia comercial. Tener la aceptación y crear interfaces fáciles de usar puede no ser el más útil de los consejos, pero no estoy en desacuerdo con ellos, simplemente no creo que sean parte del diseño de DWH.
La Sra. Poolet afirma que el proceso de extracción, transformación y carga (ETL) debe realizar controles de calidad de los datos y potencialmente "limpiar" los datos hasta que haya un estándar aceptable de calidad de datos. En mi opinión, esto corre el riesgo de crear un almacén de datos que no refleje adecuadamente la información extraída del sistema de origen. La limpieza de datos debe realizarse en los sistemas de origen. ETL solo debe transformar los datos para que puedan cargarse en el almacén de datos.
Como nota positiva, la recomendación de reciclar o crear rutinas ETL reutilizables es muy relevante. Además, estoy de acuerdo con la Sra. Poolet sobre la escalabilidad. Sus comentarios sobre la gestión de riesgos y el cumplimiento, en particular la Ley Sarbanes-Oxley, parecen bastante específicos; Supongo que estos provienen de su área de negocios.
Finalmente, tiene una buena lista de verificación de puntos relacionados con dimensiones, tablas de hechos y opciones de esquema durante el diseño OLAP (procesamiento analítico en línea). Estos parecen ser muy relevantes durante el proceso de diseño de la base de datos. Me hubiera gustado que esta lista fuera más larga, con más detalles o ejemplos, pero me alegró que se incluyeran estos consejos prácticos.
11 reglas importantes de diseño de bases de datos que sigo
por Shivprasad Koirala | Proyecto de código | 25 de febrero de 2014
Me gusta mucho el consejo sensato y claro al principio de este artículo. Conceptos como "considerar la naturaleza de la aplicación" y "dividir sus datos en partes lógicas" son acertados. Estas son ayudas importantes al crear su modelo de datos. Como dice el Sr. Koirala:
Cuando comienza el diseño de su base de datos, lo primero que debe analizar es la naturaleza de la aplicación para la que está diseñando, si es Transaccional o Analítica. Encontrará muchos desarrolladores que aplican reglas de normalización de forma predeterminada sin pensar en la naturaleza de la aplicación y luego se involucran en problemas de rendimiento y personalización.Sin embargo, hay un par de puntos que no me convencen. Por ejemplo, tome la centralización de pares Nombre-Valor en una sola tabla. Este diseño de One True Lookup Table (OTLT) se debate, pero generalmente se considera una mala práctica o al menos un diseño antipatrón. Estoy del lado del grupo anti-OTLT; estas tablas introducen numerosos problemas. Podríamos emplear la analogía del desarrollo de software de usar un solo enumerador para representar todos los valores posibles de todas las constantes posibles como equivalente a esta práctica.
Para recordarle, la tabla OTLT generalmente se parece a esto, con entradas de múltiples dominios en la misma tabla. Estoy de acuerdo con el grupo anti-OTLT; estas tablas introducen numerosos problemas.
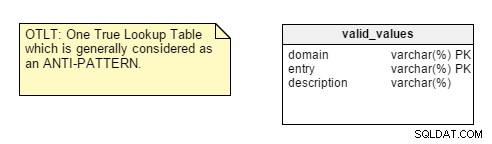
Además, algunos puntos parecen un poco esotéricos, como “cuidado con los datos separados por separadores”. Si bien este es un punto válido, no es uno en el que suelo pensar al crear un nuevo modelo de datos.
El Sr. Koirala tiene un par de elementos de diseño OLAP que generalmente no se mencionan en otras listas de mejores prácticas. Su inclusión de un diseño de dimensión y hecho puede ser útil, pero también podría ser peligroso para los diseñadores novatos.
Este artículo es interesante si está pasando del modelado de datos inicial al más avanzado. Le ayudará a considerar la naturaleza analítica frente a la transaccional de sus modelos futuros.
Grandes datos:cinco consejos sencillos para el rendimiento del diseño de bases de datos
por Dave Beulke | davebeulke.com | 19 de marzo de 2013

El artículo del Sr. Beulke analiza los consejos de diseño centrados en el rendimiento. Muestra cómo verificar la normalización adecuada:ni demasiado ni demasiado poco. (La normalización excesiva tendrá un impacto negativo en el rendimiento de la base de datos).
Además, el uso de claves comerciales naturales en lugar de claves primarias generadas es un buen consejo cuando desea evitar la traducción de una clave comercial a una ID de fila generada para cada acceso a la base de datos.
El uso de estándares de nomenclatura y tipos de columnas adecuados también es un buen consejo. El punto sobre el uso excesivo de columnas anulables es sólido:crear todas las columnas como anulables es un error, pero definir una columna como anulable puede ser necesario para una función comercial particular. En palabras del autor:
¿Son todas las columnas NULLable? Dentro de las definiciones de las columnas de la base de datos, se deben analizar, evaluar y crear prototipos de buenos dominios de datos, rangos y valores para la aplicación empresarial. Tener buenos valores predeterminados, un alcance limitado de valores y siempre un valor es lo mejor para el rendimiento y la lógica de la aplicación. Las columnas anulables solo son buenas cuando los datos son desconocidos o aún no tienen un valor. Los datos de la fecha de muerte de alguien son el ejemplo clásico de una columna NULLable porque se desconoce a menos que ya estén muertos. Asegúrese de que el diseño de su base de datos represente datos que se conocen y solo use un mínimo de columnas NULLable.Los consejos del Sr. Beulke son todos muy sólidos, aunque algo poco originales. Me hubiera gustado tener más elementos de Big Data, ese es, después de todo, el título del artículo. Al final, sentí que el artículo carecía de profundidad y amplitud, y no tenía ejemplos para aclarar los puntos. Sin embargo, ofrece valiosos consejos relacionados con la normalización y las claves naturales.
Diez prácticas recomendadas para el diseño de bases de datos
por Ann All | Aplicaciones empresariales hoy | 15 de julio de 2014
Diez mejores prácticas de diseño de bases de datos se presenta en realidad como una serie de diapositivas. Ms. All incluye información de desarrolladores experimentados, como Michael Blaha. Alienta la reutilización de sus mejores prácticas y patrones. Estos se entienden y prueban, y en ese sentido son preferibles a los modelos de datos que deben crearse desde cero. Del artículo de la Sra. All:
Por ejemplo, a menudo hago ingeniería inversa de bases de datos:bases de datos de una aplicación que se va a reemplazar, así como bases de datos de aplicaciones relacionadas. Estas bases de datos existentes a menudo no tienen un modelo de datos disponible. Pero un modelo de datos está implícito en el esquema de la base de datos y se puede extraer, al menos parcialmente, con técnicas de ingeniería inversa de la base de datos. … Hay representaciones de datos probadas y verdaderas que ocurren a menudo y no necesitan ser recreadas desde cero.Esta es una breve presentación de diapositivas que los diseñadores de modelos de datos pueden escanear rápidamente y obtener los consejos que resuenan con ellos. Para mí, la punta de reutilización es una de mis favoritas.
Mejores prácticas de base de datos
por Cunningham &Cunningham, Inc.
Estas mejores prácticas comenzaron muy bien, pero luego entraron en algunos problemas complicados. No estoy convencido de que los consejos ofrecidos sean siempre acertados.
En el lado positivo, hay muy buenas descripciones de "mejores prácticas" controvertidas, como usar siempre claves sustitutas generadas automáticamente y usar o evitar procedimientos almacenados. Como ejemplo:
Un autor anterior escribió:"En general, evite las claves primarias que tienen significado. Los nombres no son únicos, y muchos identificadores aparentemente únicos, como los números de seguridad social, en realidad no lo son, debido a problemas de confiabilidad de datos del mundo real". En resumen, esta es una recomendación para tener siempre una SurrogateKey generada automáticamente (generalmente numérica) en lugar de una LogicalKey basada en dominio. Esta es una respuesta bastante sencilla a un problema complejo, aunque es suficiente en varios casos y es al menos preferible a no tener ninguna clave primaria.(Nota del autor:no he podido encontrar este "autor anterior" al buscar estas dos oraciones en Google).
Y se proporciona un enlace a un artículo resumido sobre los argumentos principales de cada lado del debate de claves automáticas versus claves de dominio.
Por otro lado, encontré los consejos para "dividir el sistema operativo, los datos y el inicio de sesión en diferentes discos físicos" y "usar RAID" un poco arcanos. No me malinterpreten:este es probablemente un buen consejo en algunas circunstancias, pero no lo incluiría en mi lista de los 20 principales.
Consejos de diseño de bases de datos
por Wise Coders
Hay algunos consejos únicos e interesantes en esta colección, como una recomendación para cerrar transacciones lo antes posible.
Sin embargo, no estoy completamente de acuerdo con todos los consejos de diseño aquí. Por ejemplo:
Suponga un campo 'Estado' con valores 'Activo', 'Inactivo' e 'Inactivo'. Puede guardar el valor como el nombre completo, pero esto puede ser ineficiente. Almacenar una enumeración o un char(1) con valores posibles 'a', 'i', 'd', por ejemplo, usará menos espacio en la base de datos.Esto es controvertido, por decir lo menos:otras fuentes recomiendan no emplear "códigos secretos" como este. En su lugar, use una tabla separada para almacenar estos códigos de estado.
Además, las estadísticas asociadas con las sugerencias de rendimiento son cuestionables y no hay ejemplos en el artículo.
En una nota positiva, esta es una buena lista corta de consejos que deberían ser accesibles para los modeladores de bases de datos intermedios.
Recursos para diseñadores principiantes de bases de datos
Ahora examinemos algunos artículos para aquellos que recién se inician en el diseño de bases de datos.
Los fundamentos de un buen diseño de base de datos en el desarrollo web
por Kayla Knight | Unextrapixel.com | 17 de marzo de 2011
Aquí avanzamos un poco más, con consejos que van desde la funcionalidad hasta las herramientas de modelado.
La Sra. Knight nos guía a través de una introducción al diseño de bases de datos. Su artículo es interesante porque enfatiza las bases de datos para el desarrollo web. Aun así, sus puntos son bastante universales y se pueden aplicar al diseño de bases de datos en muchas situaciones.
El artículo comienza pidiéndonos que pensemos en términos generales sobre la funcionalidad, no solo sobre la base de datos:
Piense fuera de la base de datos. Trate de pensar en lo que tendrá que hacer el sitio web. Por ejemplo, si se necesita un sitio web de membresía, el primer instinto puede ser comenzar a pensar en todos los datos que cada usuario necesitará almacenar. Olvídalo, eso es para más tarde. Más bien, anote que los usuarios y su información deberán almacenarse en la base de datos, ¿y qué más? ¿Qué tendrán que hacer esos miembros en el sitio? ¿Harán publicaciones, subirán archivos o fotos, o enviarán mensajes? Luego, la base de datos necesitará un lugar para archivos/fotos, publicaciones y mensajes.A partir de ahí, la Sra. Knight lleva al lector a las herramientas de diseño de bases de datos y los pasos involucrados en el proceso. Su artículo ofrece ejemplos y enlaces a otros recursos.
Creo que este artículo sería una excelente introducción para los diseñadores de bases de datos principiantes, y debería funcionar bien con las chicas geek. serie.
Explorando consejos de diseño de bases de datos
por Doug Lowe | Para Dummies
La lista de "tontos" del Sr. Lowe es una amplia serie de consejos básicos de diseño. Puede encontrar muchos de estos en otros lugares, pero es útil tenerlos en un solo lugar. No encontrará nada único o muy controvertido, excepto una recomendación para usar procedimientos almacenados. Siempre cuestiono esta fuerte declaración, ya que estoy muy preocupado por la portabilidad del modelo de datos para múltiples sistemas DBM.
Este es uno de los consejos de sentido común del Sr. Lowe:
Evite campos con nombres como CustomerType, donde el valor del campo es una de varias constantes que no están definidas en ninguna otra parte de la base de datos, como R para minorista o W para mayorista. Es posible que tenga solo estos dos tipos de clientes en la actualidad, pero las necesidades de la aplicación pueden cambiar en el futuro y requerir un tercer tipo de cliente.Estas recomendaciones son más apropiadas cuando se trabaja con SQL Server.
Cinco consejos sencillos para el diseño de bases de datos
por Lamont Adams | RepúblicaTecnológica | 25 de junio de 2001
La palabra clave para este recurso es “simple”. Puedes encontrar esta información, con más explicaciones y ejemplos, en otros artículos.
Sin embargo, el consejo del Sr. Adams de "Quitar las llaves del usuario" es un punto interesante, rara vez mencionado en otros lugares. Continúa:
Al decidir qué campo o campos usar como claves en una tabla, siempre tenga en cuenta los campos que editarán los usuarios. Por lo general, es una mala idea elegir un campo editable por el usuario como clave.El significado del Sr. Adams es que debe considerar el requisito potencial del usuario para editar campos al decidir qué campos usar como claves. Me hubiera gustado tener más explicaciones sobre las alternativas, como claves sintéticas/generadas, pero el concepto es bueno.
No estoy de acuerdo con el punto final. Recomienda un "factor de engaño" para cada mesa que diseñe:
No hay mucho peor que descubrir, o ser informado, que a su base de datos "terminada" le falta un campo para una información crucial. En una empresa para la que trabajé, esto era algo tan común que comenzamos a referirnos a los "congelamientos de bases de datos" como "granizados de bases de datos".En mi opinión, esto es básicamente "agregar un par de campos de texto adicionales al final". Esto parece contradecir algunos de los otros consejos del Sr. Adams, específicamente aquellos relacionados con la comprensión de las necesidades comerciales y el uso de nombres significativos. Estos campos adicionales de fudge simplemente se llamarían algo así como "extra1" o "extra2". ¿Cuál es su necesidad comercial? ¿Y cómo son estos nombres significativos? Si bien me gustan la mayoría de sus consejos de diseño, este "factor de engaño" no es algo a lo que me adhiero.
Diseño de base de datos:menciones de honor
Obviamente, hay otros artículos que describen consejos y mejores prácticas para el diseño de bases de datos. Puede encontrar material adicional en los siguientes enlaces:
Diseño de bases de datos relacionales:una introducción a las mejores prácticas | de Digital Ethos | 24 de diciembre de 2012
Prácticas recomendadas para el diseño de esquemas de bases de datos (principiantes) | de Jim Murphy | 28 de marzo de 2011
Mejores prácticas de TI:diseño de bases de datos | por la Universidad de Nebraska–Lincoln
Recursos de diseño de bases de datos en línea:¿Adónde irías?
Como se mencionó, esta lista definitivamente no pretende ser un examen exhaustivo de todos los artículos de diseño de bases de datos en Internet. Más bien, hemos identificado varios artículos que creemos que son útiles o que tienen un enfoque particular que puede resultarle útil.
No dude en recomendar artículos adicionales.