"¡Pero funcionó bien en nuestro servidor de desarrollo!"
¿Cuántas veces lo escuché cuando ocurrieron problemas de rendimiento de consultas SQL aquí y allá? Yo mismo lo dije en su día. Supuse que una consulta que se ejecuta en menos de un segundo funcionaría bien en servidores de producción. Pero estaba equivocado.
¿Puede usted relacionarse con esta experiencia? Si todavía estás en este barco hoy por cualquier motivo, esta publicación es para ti. Le dará una mejor métrica para ajustar el rendimiento de su consulta SQL. Hablaremos de tres de los datos más críticos de ESTADÍSTICA IO.
Como ejemplo, utilizaremos la base de datos de muestra AdventureWorks.
Antes de comenzar a ejecutar las consultas a continuación, active STATISTICS IO. He aquí cómo hacerlo en una ventana de consulta:
USE AdventureWorks
GO
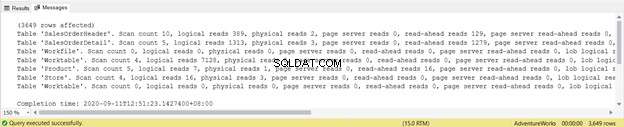
SET STATISTICS IO ONUna vez que ejecute una consulta con STATISTICS IO ON, aparecerán diferentes mensajes. Puede verlos en la pestaña Mensajes de la ventana de consulta en SQL Server Management Studio (consulte la Figura 1):
Ahora que hemos terminado con la breve introducción, profundicemos.
1. Lecturas lógicas altas
El primer punto de nuestra lista es el culpable más común:lecturas lógicas altas.
Las lecturas lógicas son el número de páginas leídas de la memoria caché de datos. Una página tiene un tamaño de 8 KB. La caché de datos, por otro lado, se refiere a la memoria RAM utilizada por SQL Server.
Las lecturas lógicas son cruciales para el ajuste del rendimiento. Este factor define cuánto necesita un SQL Server para producir el conjunto de resultados requerido. Por lo tanto, lo único que debe recordar es:cuanto más altas sean las lecturas lógicas, más tiempo necesitará funcionar SQL Server. Significa que su consulta será más lenta. Reduzca el número de lecturas lógicas y aumentará el rendimiento de sus consultas.
Pero, ¿por qué usar lecturas lógicas en lugar de tiempo transcurrido?
- El tiempo transcurrido depende de otras cosas que haga el servidor, no solo de su consulta.
- El tiempo transcurrido puede cambiar del servidor de desarrollo al servidor de producción. Esto sucede cuando ambos servidores tienen diferentes capacidades y configuraciones de hardware y software.
Confiar en el tiempo transcurrido hará que diga:"¡Pero funcionó bien en nuestro servidor de desarrollo!" tarde o temprano.
¿Por qué usar lecturas lógicas en lugar de lecturas físicas?
- Las lecturas físicas son la cantidad de páginas leídas de los discos a la caché de datos (en la memoria). Una vez que las páginas necesarias en una consulta están en la caché de datos, no es necesario volver a leerlas desde los discos.
- Cuando se vuelve a ejecutar la misma consulta, las lecturas físicas serán cero.
Las lecturas lógicas son la opción lógica para ajustar el rendimiento de las consultas SQL.
Para ver esto en acción, pasemos a un ejemplo.
Ejemplo de lecturas lógicas
Supongamos que necesita obtener la lista de clientes con pedidos enviados el 11 de julio de 2011. Se le ocurre esta consulta bastante simple a continuación:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Es sencillo. Esta consulta tendrá el siguiente resultado:

Luego, verifica el resultado de STATISTICS IO de esta consulta:

El resultado muestra las lecturas lógicas de cada una de las cuatro tablas utilizadas en la consulta. En total, la suma de las lecturas lógicas es 729. También puede ver lecturas físicas con una suma total de 21. Sin embargo, intente volver a ejecutar la consulta y será cero.
Eche un vistazo más de cerca a las lecturas lógicas de SalesOrderHeader . ¿Te preguntas por qué tiene 689 lecturas lógicas? Tal vez, pensó en inspeccionar el plan de ejecución de la siguiente consulta:
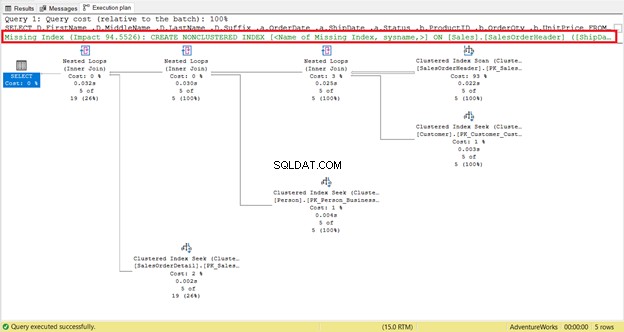
Por un lado, hay un escaneo de índice que ocurrió en SalesOrderHeader con un costo del 93%. ¿Qué podría estar pasando? Supongamos que comprobó sus propiedades:
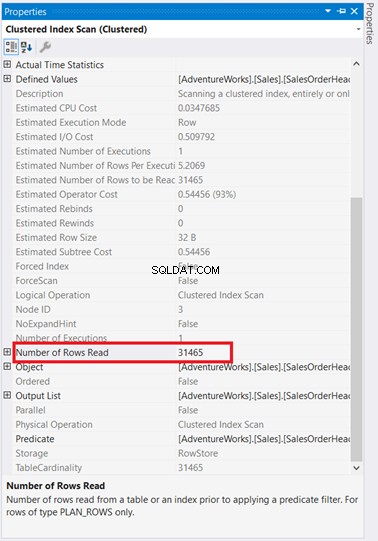
¡Guau! ¿31,465 filas leídas por solo 5 filas devueltas? ¡Es absurdo!
Reducción del número de lecturas lógicas
No es tan difícil disminuir esas 31,465 filas leídas. SQL Server ya nos dio una pista. Proceda a lo siguiente:
PASO 1:Siga la recomendación de SQL Server y agregue el índice que falta
¿Notó la recomendación de índice faltante en el plan de ejecución (Figura 4)? ¿Eso solucionará el problema?
Hay una forma de averiguarlo:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Vuelva a ejecutar la consulta y vea los cambios en las lecturas lógicas de STATISTICS IO.

Como puede ver en STATISTICS IO (Figura 6), hay una enorme disminución en las lecturas lógicas de 689 a 17. Las nuevas lecturas lógicas generales son 57, lo que representa una mejora significativa de las 729 lecturas lógicas. Pero para estar seguros, inspeccionemos el plan de ejecución nuevamente.
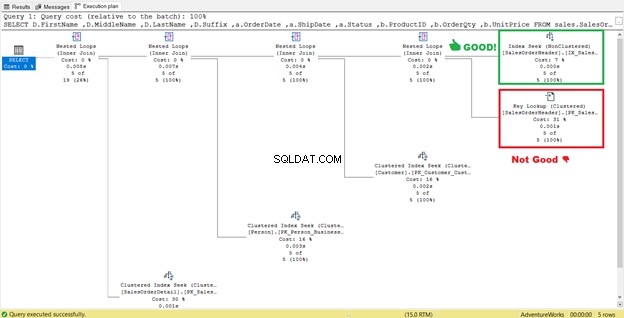
Parece que hay una mejora en el plan que resulta en lecturas lógicas reducidas. El escaneo de índice ahora es una búsqueda de índice. SQL Server ya no necesitará inspeccionar fila por fila para obtener los registros con Shipdate='07/11/2011' . Pero algo sigue acechando en ese plan, y no está bien.
Necesitas el paso 2.
PASO 2:Modifique el índice y agregue a las columnas incluidas:fecha de pedido, estado e ID de cliente
¿Ve ese operador Key Lookup en el plan de ejecución (Figura 7)? Significa que el índice no agrupado creado no es suficiente:el procesador de consultas necesita usar el índice agrupado nuevamente.
Comprobemos sus propiedades.
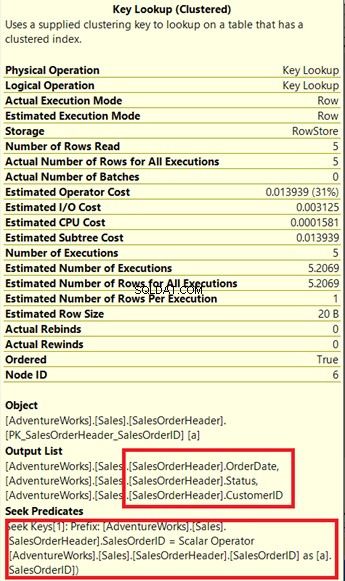
Tenga en cuenta el cuadro adjunto debajo de la Lista de salida . Sucede que necesitamos OrderDate , Estado y ID de cliente en el conjunto de resultados. Para obtener esos valores, el procesador de consultas usó el índice agrupado (consulte Buscar predicados ) para llegar a la mesa.
Necesitamos eliminar esa búsqueda de claves. La solución es incluir la OrderDate , Estado y ID de cliente columnas en el índice creado anteriormente.
- Haga clic con el botón derecho en IX_SalesOrderHeader_ShipDate en SSMS.
- Seleccione Propiedades .
- Haga clic en las columnas incluidas pestaña.
- Agregar Fecha de pedido , Estado y ID de cliente .
- Haga clic en Aceptar .
Después de volver a crear el índice, vuelva a ejecutar la consulta. ¿Se eliminará Búsqueda de claves? y reducir las lecturas lógicas?

¡Funcionó! De 17 lecturas lógicas a 2 (Figura 9).
Y la búsqueda de claves ?
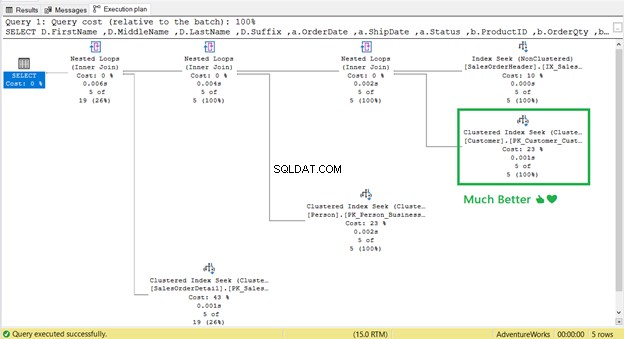
¡Se fue! Búsqueda de índice agrupado ha reemplazado Búsqueda de claves.
La comida para llevar
Entonces, ¿qué hemos aprendido?
Una de las formas principales de reducir las lecturas lógicas y mejorar el rendimiento de las consultas SQL es crear un índice apropiado. Pero hay una trampa. En nuestro ejemplo, redujo las lecturas lógicas. A veces, lo contrario será correcto. También puede afectar el rendimiento de otras consultas relacionadas.
Por lo tanto, siempre verifique las ESTADÍSTICAS IO y el plan de ejecución después de crear el índice.
2. Lecturas lógicas de Lob alto
Es muy similar al punto n.º 1, pero tratará con tipos de datos texto , ntext , imagen , varchar (máximo ), nvarchar (máximo ), varbinario (máximo ), o almacén de columnas páginas de índice.
Veamos un ejemplo:generar lecturas lógicas de lob.
Ejemplo de lecturas lógicas de Lob
Suponga que desea mostrar un producto con su precio, color, imagen en miniatura y una imagen más grande en una página web. Por lo tanto, se le ocurre una consulta inicial como la que se muestra a continuación:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorLuego, lo ejecuta y ve el resultado como el siguiente:

Como usted es un chico (o chica) con mentalidad de alto rendimiento, inmediatamente revisa el IO de ESTADÍSTICAS. Aquí está:

Se siente como un poco de suciedad en los ojos. 665 lob lecturas lógicas? No puedes aceptar esto. Sin mencionar 194 lecturas lógicas cada una de ProductPhoto y ProductProductPhoto mesas. De hecho, cree que esta consulta necesita algunos cambios.
Reducción de las lecturas lógicas de Lob
La consulta anterior devolvió 97 filas. Las 97 bicicletas. ¿Crees que esto es bueno para mostrar en una página web?
Un índice puede ayudar, pero ¿por qué no simplificar primero la consulta? De esta manera, puede ser selectivo sobre lo que devolverá SQL Server. Puede reducir las lecturas lógicas de lob.
- Agregue un filtro para la subcategoría de productos y deje que el cliente elija. Luego incluya esto en la cláusula WHERE.
- Eliminar la Subcategoría de producto ya que agregará un filtro para la subcategoría de productos.
- Eliminar la foto grande columna. Consulta esto cuando el usuario selecciona un producto específico.
- Usar paginación. El cliente no podrá ver las 97 bicicletas a la vez.
Con base en estas operaciones descritas anteriormente, cambiamos la consulta de la siguiente manera:
- Eliminar Subcategoría de producto y Foto grande columnas del conjunto de resultados.
- Use OFFSET y FETCH para acomodar la paginación en la consulta. Consulta solo 10 productos a la vez.
- Añadir ProductSubcategoryID en la cláusula WHERE según la selección del cliente.
- Eliminar la Subcategoría de producto columna en la cláusula ORDER BY.
La consulta ahora será similar a esto:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Con los cambios realizados, ¿mejorarán las lecturas lógicas de lob? ESTADÍSTICAS IO ahora informa:

Foto del producto la tabla ahora tiene 0 lecturas lógicas de lob:de 665 lecturas lógicas de lob a ninguna. Esa es una mejora.
Para llevar
Una de las formas de reducir las lecturas lógicas de lob es reescribir la consulta para simplificarla.
Elimine las columnas innecesarias y reduzca las filas devueltas a las menos necesarias. Cuando sea necesario, use OFFSET y FETCH para buscar.
Para asegurarse de que los cambios en la consulta hayan mejorado las lecturas lógicas de lob y el rendimiento de la consulta SQL, siempre verifique STATISTICS IO.
3. Lecturas lógicas altas de la mesa de trabajo/archivo de trabajo
Finalmente, son lecturas lógicas de Worktable y archivo de trabajo . Pero, ¿qué son estas tablas? ¿Por qué aparecen cuando no los usas en tu consulta?
Tener mesa de trabajo y archivo de trabajo aparecer en STATISTICS IO significa que SQL Server necesita mucho más trabajo para obtener los resultados deseados. Se recurre al uso de tablas temporales en tempdb , a saber, Mesas de trabajo y archivos de trabajo . No es necesariamente dañino tenerlos en la salida STATISTICS IO, siempre que las lecturas lógicas sean cero y no causen problemas al servidor.
Estas tablas pueden aparecer cuando hay un ORDEN POR, GROUP BY, CROSS JOIN o DISTINCT, entre otros.
Ejemplo de lecturas lógicas de tabla de trabajo/archivo de trabajo
Suponga que necesita consultar todas las tiendas sin ventas de ciertos productos.
Inicialmente se te ocurre lo siguiente:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDEsta consulta devolvió 3649 filas:
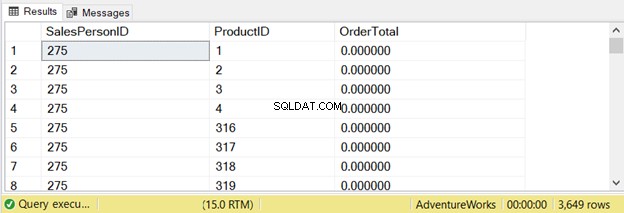
Veamos lo que dice el IO de ESTADÍSTICAS:

Vale la pena notar que la Mesa de trabajo las lecturas lógicas son 7128. Las lecturas lógicas generales son 8853. Si revisa el plan de ejecución, verá muchos paralelismos, coincidencias de hash, colas de impresión y escaneos de índice.
Reducción de las lecturas lógicas de la tabla de trabajo/archivo de trabajo
No pude construir una sola instrucción SELECT con un resultado satisfactorio. Por lo tanto, la única opción es dividir la instrucción SELECT en múltiples consultas. Ver a continuación:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsEs varias líneas más largo y utiliza tablas temporales. Ahora, veamos lo que revela el IO de ESTADÍSTICAS:
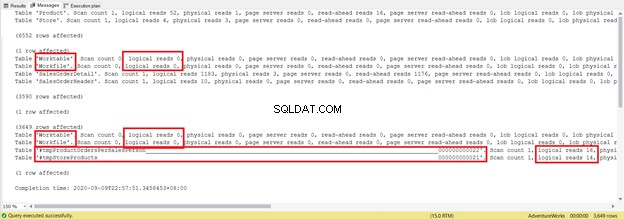
Trate de no concentrarse en la longitud de este informe estadístico; solo es frustrante. En su lugar, agregue lecturas lógicas de cada tabla.
Para un total de 1279, es una disminución significativa, ya que fueron 8853 lecturas lógicas de la instrucción SELECT única.
No hemos agregado ningún índice a las tablas temporales. Es posible que necesite uno si se agregan muchos más registros a SalesOrderHeader y Detalle del pedido de venta . Pero entiendes el punto.
Para llevar
A veces, 1 declaración SELECT parece buena. Sin embargo, detrás de escena, lo contrario es cierto. Mesas de trabajo y archivos de trabajo con lecturas lógicas altas retrasan el rendimiento de su consulta SQL.
Si no puede pensar en otra forma de reconstruir la consulta y los índices son inútiles, pruebe el enfoque de "divide y vencerás". Las Mesas de Trabajo y archivos de trabajo aún puede aparecer en la pestaña Mensaje de SSMS, pero las lecturas lógicas serán cero. Por lo tanto, el resultado general será de lecturas menos lógicas.
El resultado final en el rendimiento de consultas SQL y ESTADÍSTICAS IO
¿Cuál es el problema con estas 3 desagradables estadísticas de E/S?
La diferencia en el rendimiento de las consultas SQL será como la noche y el día si presta atención a estos números y los reduce. Solo hemos presentado algunas formas de reducir las lecturas lógicas como:
- crear índices apropiados;
- simplificación de consultas:eliminación de columnas innecesarias y minimización del conjunto de resultados;
- dividir una consulta en varias consultas.
Hay más como actualizar estadísticas, desfragmentar índices y configurar el FACTOR DE RELLENO correcto. ¿Puedes agregar más a esto en la sección de comentarios?
Si te gusta esta publicación, compártela en tus redes sociales favoritas.