Es ese martes del mes, ya sabes, en el que ocurre la fiesta de bloque de bloggers conocida como T-SQL Tuesday. Este mes está organizado por Russ Thomas (@SQLJudo) y el tema es "Llamando a todos los sintonizadores y entusiastas". Voy a tratar un problema relacionado con el rendimiento aquí, aunque me disculpo porque podría no estar completamente en línea con las pautas que Russ estableció en su invitación (no voy a usar sugerencias, marcas de rastreo o guías de planes) .
En SQLBits la semana pasada, hice una presentación sobre disparadores, y mi buen amigo y colega MVP Erland Sommarskog asistió. En un momento, sugerí que antes de crear un nuevo disparador en una tabla, debería verificar si ya existen disparadores y considerar combinar la lógica en lugar de agregar un disparador adicional. Mis razones fueron principalmente por la mantenibilidad del código, pero también por el rendimiento. Erland me preguntó si alguna vez había probado para ver si había alguna sobrecarga adicional al tener varios disparadores disparados para la misma acción, y tuve que admitir que no, no había hecho nada extenso. Así que voy a hacer eso ahora.
En AdventureWorks2014, creé un conjunto simple de tablas que básicamente representan sys.all_objects (~2700 filas) y sys.all_columns (~9500 filas). Quería medir el efecto en la carga de trabajo de varios enfoques para actualizar ambas tablas; básicamente, tiene usuarios que actualizan la tabla de columnas y usa un disparador para actualizar una columna diferente en la misma tabla y algunas columnas en la tabla de objetos.
- T1:línea base :suponga que puede controlar todo el acceso a los datos a través de un procedimiento almacenado; en este caso, las actualizaciones contra ambas tablas se pueden realizar directamente, sin necesidad de disparadores. (Esto no es práctico en el mundo real, porque no puede prohibir de manera confiable el acceso directo a las tablas).
- T2:disparador único contra otra tabla :suponga que puede controlar la declaración de actualización en la tabla afectada y agregar otras columnas, pero las actualizaciones de la tabla secundaria deben implementarse con un disparador. Actualizaremos las tres columnas con una declaración.
- T3:disparador único contra ambas tablas :En este caso, tenemos un activador con dos instrucciones, una que actualiza la otra columna de la tabla afectada y otra que actualiza las tres columnas de la tabla secundaria.
- T4:disparador único contra ambas tablas :Como T3, pero esta vez, tenemos un disparador con cuatro declaraciones, una que actualiza la otra columna en la tabla afectada y una declaración para cada columna actualizada en la tabla secundaria. Esta podría ser la forma en que se maneja si los requisitos se agregan con el tiempo y una declaración separada se considera más segura en términos de prueba de regresión.
- T5:dos disparadores :Un activador actualiza solo la tabla afectada; el otro usa una sola declaración para actualizar las tres columnas en la tabla secundaria. Esta podría ser la forma en que se hace si los otros factores desencadenantes no se notan o si está prohibido modificarlos.
- T6:Cuatro disparadores :Un activador actualiza solo la tabla afectada; los otros tres actualizan cada columna en la tabla secundaria. Nuevamente, esta podría ser la forma en que se hace si no sabe que existen otros factores desencadenantes, o si tiene miedo de tocar los otros factores desencadenantes debido a problemas de regresión.
Estos son los datos de origen con los que estamos tratando:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Ahora, para cada una de las 6 pruebas, ejecutaremos nuestras actualizaciones 1000 veces y mediremos el tiempo
T1:Línea base
Este es el escenario en el que tenemos la suerte de evitar los factores desencadenantes (de nuevo, no muy realista). En este caso, mediremos las lecturas y la duración de este lote. Pongo /*real*/ en el texto de la consulta para que pueda extraer fácilmente las estadísticas solo para estas declaraciones, y no cualquier declaración dentro de los disparadores, ya que, en última instancia, las métricas se acumulan en las declaraciones que invocan los disparadores. También tenga en cuenta que las actualizaciones reales que estoy haciendo realmente no tienen ningún sentido, así que ignore que estoy configurando la intercalación en el nombre del servidor/instancia y el objeto principal_id al session_id de la sesión actual .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:disparador único
Para esto necesitamos el siguiente disparador simple, que solo actualiza dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Entonces nuestro lote solo necesita actualizar las dos columnas en la tabla principal:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:disparador único contra ambas tablas
Para esta prueba, nuestro activador se ve así:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Y ahora el lote que estamos probando simplemente tiene que actualizar la columna original en la tabla principal; el otro es manejado por el gatillo:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:disparador único contra ambas tablas
Esto es como T3, pero ahora el activador tiene cuatro declaraciones:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO El lote de prueba no ha cambiado:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:Dos disparadores
Aquí tenemos un activador para actualizar la tabla principal y un activador para actualizar la tabla secundaria:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO El lote de prueba vuelve a ser muy básico:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Cuatro disparadores
Esta vez tenemos un disparador para cada columna que se ve afectada; uno en la tabla principal y tres en las tablas secundarias.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Y el lote de prueba:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Medición del impacto de la carga de trabajo
Finalmente, escribí una consulta simple contra sys.dm_exec_query_stats para medir las lecturas y la duración de cada prueba:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Resultados
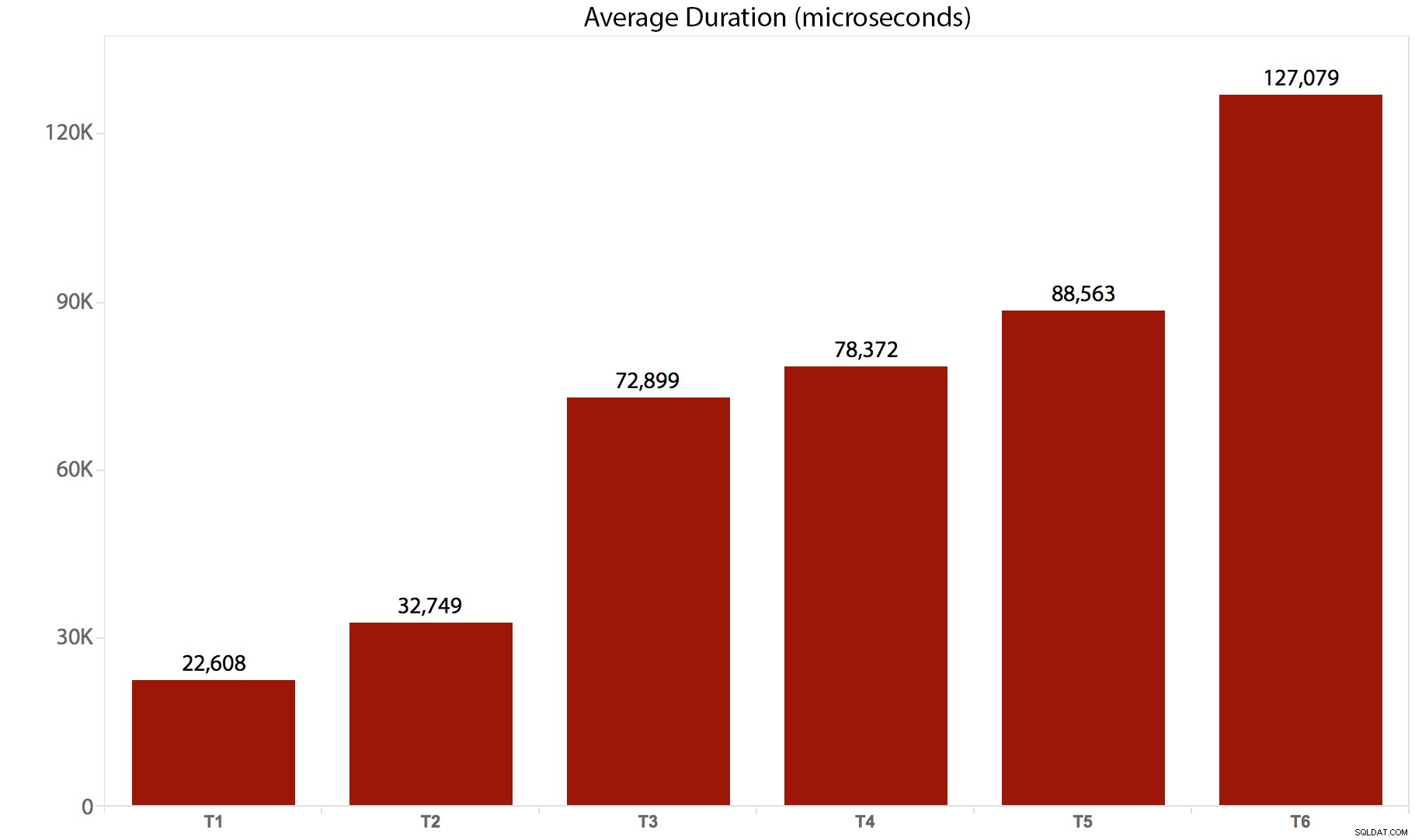
Realicé las pruebas 10 veces, recopilé los resultados y promedié todo. Así es como se descompuso:
| Prueba/Lote | Duración media (microsegundos) | Total de lecturas (8K páginas) |
|---|---|---|
| T1 :ACTUALIZAR /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :ACTUALIZAR /*real*/ dbo.tr2 … | 32.749 | 11,331,628 |
| T3 :ACTUALIZAR /*real*/ dbo.tr3 … | 72.899 | 22,838,308 |
| T4 :ACTUALIZAR /*real*/ dbo.tr4 … | 78.372 | 44.463.275 |
| T5 :ACTUALIZAR /*real*/ dbo.tr5 … | 88.563 | 41.514.778 |
| T6 :ACTUALIZAR /*real*/ dbo.tr6 … | 127.079 | 100,330,753 |
Y aquí hay una representación gráfica de la duración:
Conclusión
Está claro que, en este caso, hay una sobrecarga sustancial para cada disparador que se invoca:todos estos lotes finalmente afectaron la misma cantidad de filas, pero en algunos casos, las mismas filas se tocaron varias veces. Probablemente realizaré más pruebas de seguimiento para medir la diferencia cuando la misma fila nunca se toque más de una vez; un esquema más complicado, quizás, en el que se deben tocar otras 5 o 10 tablas cada vez, y estas declaraciones diferentes podrían ser en un solo gatillo o en múltiples. Mi conjetura es que las diferencias de gastos generales se verán más impulsadas por cosas como la simultaneidad y el número de filas afectadas que por los gastos generales del activador en sí, pero ya veremos.
¿Quieres probar la demostración tú mismo? Descarga el guión aquí.