La carga de transformación de extracción (ETL) es la columna vertebral de cualquier almacén de datos. En el almacén de datos, los datos mundiales se gestionan mediante el proceso ETL, que consta de tres procesos, Extracción-Extracción/Adquisición de datos de fuentes, Transformación-cambio de datos en el formato requerido y Carga-empuje de datos al destino, generalmente en un almacén de datos o un centro de datos.
¡Aprenda SSIS y comience su prueba gratuita hoy!
SQL Server Integration Services (SSIS) es la herramienta de la familia ETL que es útil para desarrollar y administrar un almacén de datos empresarial. Un almacén de datos, por su propia caracterización, funciona con un gran volumen de datos y el rendimiento es un gran desafío cuando se administra un gran volumen de datos para cualquier Arquitecto o DBA.
Consideraciones de mejora de ETL
Hoy hablaré sobre la facilidad con la que puede mejorar el rendimiento de ETL o diseñar un sistema ETL de alto rendimiento con la ayuda de SSIS. Para una mejor comprensión, dividiré diez métodos en dos categorías diferentes; primero, las consideraciones de tiempo de diseño del paquete SSIS y, segundo, la configuración de diferentes valores de propiedad de los componentes disponibles en el paquete SSIS.
Consideraciones en tiempo de diseño del paquete SSIS
#1 Extraer datos en paralelo:SSIS proporciona la forma de extraer datos en paralelo utilizando contenedores de secuencia en el flujo de control. Puede diseñar un paquete de tal manera que pueda extraer datos de tablas o archivos no dependientes en paralelo, lo que ayudará a reducir el tiempo total de ejecución de ETL.
#2 Extraiga los datos requeridos:extraiga solo el conjunto de datos requerido de cualquier tabla o archivo. Debe evitar la tendencia de extraer todo lo disponible en la fuente por ahora que usará en el futuro; consume ancho de banda de la red, consume recursos del sistema (E/S y CPU), requiere almacenamiento adicional y degrada el rendimiento general del sistema ETL.
Si su sistema ETL es de naturaleza realmente dinámica y sus requisitos cambian con frecuencia, sería mejor considerar otros enfoques de diseño, como ETL basado en metadatos, etc., en lugar de diseñar para incorporar todo al mismo tiempo.
#3 Evite el uso de componentes de transformación asincrónicos:SSIS es una herramienta rica con un conjunto de componentes de transformación para lograr tareas complejas durante la ejecución de ETL, pero al mismo tiempo le cuesta mucho si estos componentes no se utilizan correctamente.
Hay dos categorías de componentes de transformación disponibles en SSIS:Synchronous y Asíncrono .
Las transformaciones sincrónicas son aquellos componentes que procesan cada fila y empujan hacia abajo al siguiente componente/destino, utiliza la memoria intermedia asignada y no requiere memoria adicional, ya que es una relación directa entre la fila de datos de entrada/salida que encaja completamente en la memoria asignada. Los componentes como la búsqueda, las columnas derivadas y la conversión de datos, etc. entran en esta categoría.
Las transformaciones asincrónicas son aquellos componentes que primero almacenan datos en la memoria intermedia y luego procesan operaciones como Ordenar y Agregar. Se requiere memoria de búfer adicional para completar la tarea y, hasta que la memoria de búfer esté disponible, retiene todos los datos en la memoria y bloquea la transacción, también conocida como transformación de bloqueo. Para completar la tarea, el motor SSIS (motor de canalización de flujo de datos) asignará memoria de búfer adicional, que nuevamente es una sobrecarga para el sistema ETL. Componentes como ordenar, agregar, fusionar, unir, etc. entran en esta categoría.
En general, debe evitar las transformaciones asíncronas, pero aún así, si se encuentra en una situación en la que no tiene otra opción, debe saber cómo manejar los valores de propiedad disponibles de estos componentes. Hablaré de ellos más adelante en este artículo.
#4 Uso óptimo de eventos en controladores de eventos:para realizar un seguimiento del progreso de la ejecución del paquete o realizar cualquier otra acción adecuada en un evento específico, SSIS proporciona un conjunto de eventos. Los eventos son muy útiles, pero el uso excesivo de eventos tendrá un costo adicional en la ejecución de ETL.
Aquí, debe validar todas las características antes de habilitar un evento en el paquete SSIS.
#5 Es necesario conocer el esquema de la tabla de destino cuando se trabaja con un gran volumen de datos. Debe pensarlo dos veces cuando necesite extraer un gran volumen de datos de la fuente y enviarlos a un almacén de datos o a un data mart. Es posible que vea problemas de rendimiento cuando intente insertar grandes cantidades de datos en el destino con una combinación de operaciones de inserción, actualización y eliminación (DML), ya que podría existir la posibilidad de que la tabla de destino tenga índices agrupados o no agrupados, lo que puede causar una gran cantidad de datos se mezclan en la memoria debido a las operaciones DML.
Si ETL tiene problemas de rendimiento debido a una gran cantidad de operaciones DML en una tabla que tiene un índice, debe realizar los cambios apropiados en el diseño de ETL, como eliminar los índices agrupados existentes en la fase previa a la ejecución y volver a crear todos los índices. en la fase posterior a la ejecución. Puede encontrar otras alternativas mejores para resolver el problema según su situación.
Configurar las propiedades de los componentes
#6 Controle la ejecución paralela de una tarea configurando MaxConcurrentExecutables y Subprocesos del motor propiedad. El paquete SSIS y las tareas de flujo de datos tienen una propiedad para controlar la ejecución paralela de una tarea:MaxConcurrentExecutables es la propiedad de nivel de paquete y tiene un valor predeterminado de -1 , lo que significa que la cantidad máxima de tareas que se pueden ejecutar es igual a la cantidad total de procesadores en la máquina más dos;
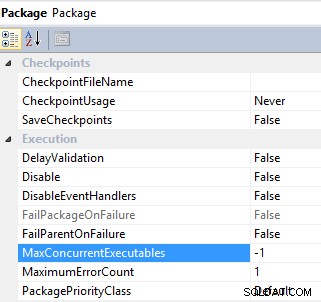
Paquete
Subprocesos del motor es una propiedad de nivel de tarea de flujo de datos y tiene un valor predeterminado de 10, que especifica el número total de subprocesos que se pueden crear para ejecutar la tarea de flujo de datos.
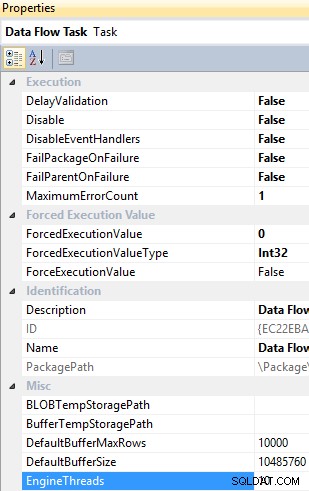
Tarea de flujo de datos
Puede cambiar los valores predeterminados de estas propiedades según las necesidades de ETL y la disponibilidad de recursos.
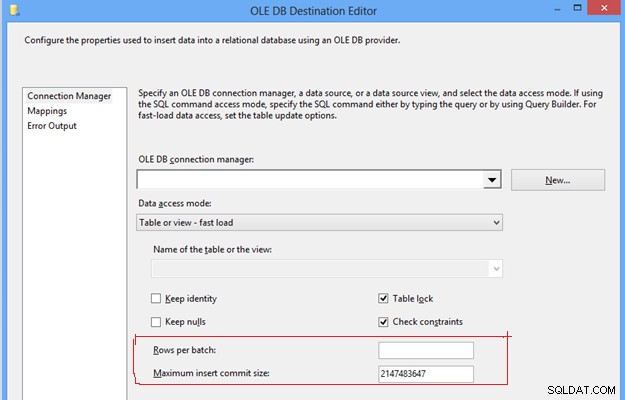
#7 Configure la opción de modo de acceso a datos en Destino OLEDB. En la tarea de flujo de datos SSIS podemos encontrar el destino OLEDB, que proporciona un par de opciones para enviar datos a la tabla de destino, en el modo de acceso a datos; primero, la opción “Tabla o vista”, que inserta una fila a la vez; en segundo lugar, la opción "Tabla o vista de carga rápida", que utiliza internamente la declaración de inserción masiva para enviar datos a la tabla de destino, lo que siempre proporciona un mejor rendimiento en comparación con otras opciones. Una vez que elige la opción de "carga rápida", le brinda más control para administrar el comportamiento de la tabla de destino durante una operación de envío de datos, como Mantener identidad, Mantener nulos, Bloqueo de tabla y Verificar restricciones.
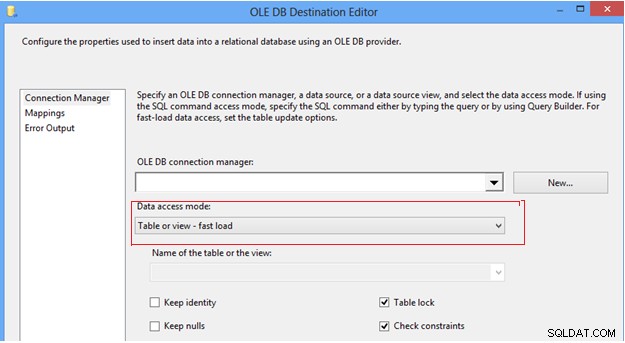
Editor de destinos OLE DB
Se recomienda encarecidamente que utilice la opción de carga rápida para insertar datos en la tabla de destino para mejorar el rendimiento de ETL.
#8, Configurar filas por lote y tamaño máximo de confirmación de inserción en el destino OLEDB. Estas dos configuraciones son importantes para controlar el rendimiento de tempdb y el registro de transacciones porque con los valores predeterminados dados de estas propiedades, enviará datos a la tabla de destino en un lote y una transacción. Requerirá un uso excesivo de tembdb y registro de transacciones, lo que se convierte en un problema de rendimiento de ETL debido al consumo excesivo de memoria y almacenamiento en disco.
Editor de destino OLE DB
Para mejorar el rendimiento de ETL, puede poner un valor entero positivo en ambas propiedades en función del volumen de datos anticipado, lo que ayudará a dividir una gran cantidad de datos en varios lotes, y los datos en un lote pueden volver a comprometerse en la tabla de destino según el valor específico. Evitará el uso excesivo de tempdb y el registro de transacciones, lo que ayudará a mejorar el rendimiento de ETL.
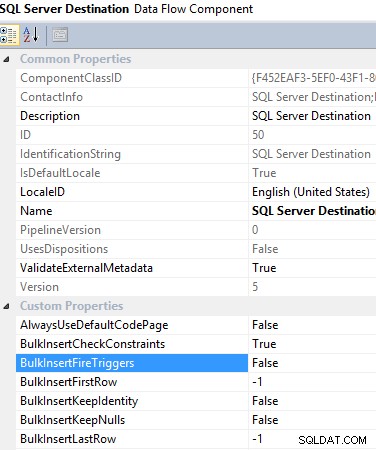
#9 Uso de SQL Server Destination en una tarea de flujo de datos. Cuando desee insertar datos en una base de datos local de SQL Server, se recomienda encarecidamente utilizar SQL Server Destination, ya que proporciona muchos beneficios para superar las limitaciones de otras opciones, lo que lo ayuda a mejorar el rendimiento de ETL. Por ejemplo, utiliza la función de inserción masiva integrada en SQL Server, pero le brinda la opción de aplicar la transformación antes de cargar los datos en la tabla de destino. Aparte de eso, le da la opción de habilitar/deshabilitar el activador que se activará al cargar datos, lo que también ayuda a reducir la sobrecarga de ETL.
Componente de flujo de datos de destino de SQL Server
# 10 Evite el encasillamiento implícito. Cuando los datos provienen de un archivo sin formato, el administrador de conexiones de archivos sin formato trata todas las columnas como un tipo de datos de cadena (DS_STR), incluidas las columnas numéricas. Como sabe, SSIS usa memoria de búfer para almacenar todo el conjunto de datos y aplica la transformación necesaria antes de insertar los datos en la tabla de destino. Ahora, cuando todas las columnas son tipos de datos de cadena, requerirá más espacio en el búfer, lo que reducirá el rendimiento de ETL.
Para mejorar el rendimiento de ETL, debe convertir todas las columnas numéricas en el tipo de datos apropiado y evitar la conversión implícita, lo que ayudará al motor SSIS a acomodar más filas en un solo búfer.
Resumen de las mejoras de rendimiento de ETL
En este artículo, exploramos la facilidad con la que se puede controlar el rendimiento de ETL en cualquier momento. Estas son 10 formas comunes de mejorar el rendimiento de ETL. Puede haber más métodos basados en diferentes escenarios a través de los cuales se puede mejorar el rendimiento.
En general, con la ayuda de la categorización puede identificar cómo manejar la situación. Si se encuentra en la fase de diseño de un almacén de datos, es posible que deba concentrarse en ambas categorías, pero si admite algún sistema heredado, primero trabaje de cerca en la segunda categoría.