ACTUALIZACIÓN:2 de septiembre de 2021 (Publicado originalmente el 26 de julio de 2012.)
Muchas cosas cambian en el transcurso de algunas versiones principales de nuestra plataforma de base de datos favorita. SQL Server 2016 nos trajo STRING_SPLIT, una función nativa que elimina la necesidad de muchas de las soluciones personalizadas que necesitábamos antes. También es rápido, pero no es perfecto. Por ejemplo, solo admite un delimitador de un solo carácter y no devuelve nada para indicar el orden de los elementos de entrada. He escrito varios artículos sobre esta función (y STRING_AGG, que llegó en SQL Server 2017) desde que se escribió esta publicación:
- Sorpresas y suposiciones de rendimiento:STRING_SPLIT()
- STRING_SPLIT() en SQL Server 2016:seguimiento n.º 1
- STRING_SPLIT() en SQL Server 2016:seguimiento n.º 2
- Código de reemplazo de cadena dividida de SQL Server con STRING_SPLIT
- Comparación de métodos de división/concatenación de cadenas
- Resuelva viejos problemas con las nuevas funciones STRING_AGG y STRING_SPLIT de SQL Server
- Tratar con el delimitador de un solo carácter en la función STRING_SPLIT de SQL Server
- Por favor, ayuda con las mejoras de STRING_SPLIT
- Una forma de mejorar STRING_SPLIT en SQL Server, y usted puede ayudar
Voy a dejar el contenido a continuación aquí para la posteridad y la relevancia histórica, y también porque parte de la metodología de prueba es relevante para otros problemas además de dividir cadenas, pero consulte algunas de las referencias anteriores para obtener información sobre cómo debe dividir cadenas en versiones modernas y compatibles de SQL Server, así como esta publicación, que explica por qué dividir cadenas tal vez no sea un problema que desee que la base de datos resuelva en primer lugar, con función nueva o no.
- Dividir cadenas:ahora con menos T-SQL
Sé que muchas personas están aburridas del problema de las "cadenas divididas", pero aún parece surgir casi a diario en foros y sitios de preguntas y respuestas como Stack Overflow. Este es el problema donde la gente quiere pasar una cadena como esta:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Dentro del procedimiento, quieren hacer algo como esto:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Esto no funciona porque @FavoriteTeams es una sola cadena y lo anterior se traduce en:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); Por lo tanto, SQL Server intentará encontrar un equipo llamado Patriots, Red Sox, Bruins , y supongo que no existe tal equipo. Lo que realmente quieren aquí es el equivalente a:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Pero dado que no hay un tipo de matriz en SQL Server, no es así como se interpreta la variable en absoluto:sigue siendo una cadena simple y única que contiene algunas comas. Dejando a un lado el cuestionable diseño del esquema, en este caso la lista separada por comas debe "dividirse" en valores individuales, y esta es la pregunta que con frecuencia genera muchos "nuevos" debates y comentarios sobre la mejor solución para lograr precisamente eso.
La respuesta parece ser, casi invariablemente, que debe usar CLR. Si no puede usar CLR, y sé que hay muchos de ustedes que no pueden, debido a la política corporativa, el jefe de pelo puntiagudo o la terquedad, entonces use una de las muchas soluciones que existen. Y existen muchas soluciones alternativas.
¿Pero cuál deberías usar?
Voy a comparar el rendimiento de algunas soluciones y me centraré en la pregunta que todos siempre hacen:"¿Cuál es la más rápida?" No voy a profundizar en la discusión sobre *todos* los métodos potenciales, porque varios ya han sido eliminados debido al hecho de que simplemente no escalan. Y puede que vuelva a visitar esto en el futuro para examinar el impacto en otras métricas, pero por ahora solo me centraré en la duración. Estos son los contendientes que voy a comparar (usando SQL Server 2012, 11.00.2316, en una máquina virtual con Windows 7 con 4 CPU y 8 GB de RAM):
CLR
Si desea usar CLR, definitivamente debe tomar prestado el código de su compañero MVP Adam Machanic antes de pensar en escribir el suyo propio (he escrito antes sobre cómo reinventar la rueda, y también se aplica a fragmentos de código gratuitos como este). Pasó mucho tiempo ajustando esta función CLR para analizar eficientemente una cadena. Si actualmente está utilizando una función CLR y no es así, le recomiendo que la implemente y la compare:la probé con una rutina CLR basada en VB mucho más simple que era funcionalmente equivalente, pero el enfoque de VB funcionó tres veces peor que la de Adán.
Así que tomé la función de Adam, compilé el código en una DLL (usando csc) e implementé solo ese archivo en el servidor. Luego agregué el siguiente ensamblaje y función a mi base de datos:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Esta es la función típica que uso para escenarios únicos en los que sé que la entrada es "segura", pero no es una función que recomiendo para entornos de producción (más información a continuación).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Una advertencia muy fuerte tiene que ir junto con el enfoque XML:solo se puede usar si puede garantizar que su cadena de entrada no contiene caracteres XML ilegales. Un nombre con <,> o &y la función explotará. Entonces, independientemente del rendimiento, si va a utilizar este enfoque, tenga en cuenta las limitaciones:no debe considerarse una opción viable para un divisor de cadenas genérico. Lo incluyo en este resumen porque es posible que tenga un caso en el que puede confiar en la entrada; por ejemplo, se puede usar para listas de números enteros o GUID separados por comas.
Tabla de números
Esta solución utiliza una tabla de Números, que debe crear y completar usted mismo. (Llevamos mucho tiempo solicitando una versión integrada). La tabla Números debe contener suficientes filas para exceder la longitud de la cadena más larga que dividirá. En este caso, usaremos 1 000 000 de filas:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (El uso de la compresión de datos reducirá drásticamente la cantidad de páginas requeridas, pero obviamente solo debe usar esta opción si está ejecutando Enterprise Edition. En este caso, los datos comprimidos requieren 1360 páginas, en comparación con 2102 páginas sin compresión, aproximadamente un 35 % de ahorro). )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Expresión de tabla común
Esta solución utiliza un CTE recursivo para extraer cada parte de la cadena del "resto" de la parte anterior. Como una CTE recursiva con variables locales, notará que esta tenía que ser una función con valores de tabla de varias declaraciones, a diferencia de las otras que están todas en línea.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Separador de Jeff Moden Una función basada en el divisor de Jeff Moden con cambios menores para admitir cadenas más largas
En SQLServerCentral, Jeff Moden presentó una función divisora que rivalizaba con el rendimiento de CLR, por lo que pensé que era justo incluir una variación con un enfoque similar en este resumen. Tuve que hacer algunos cambios menores en su función para manejar nuestra cadena más larga (500 000 caracteres), y también hice que las convenciones de nombres fueran similares:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Aparte, para aquellos que usan la solución de Jeff Moden, pueden considerar usar una tabla de números como la anterior y experimentar con una ligera variación en la función de Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Esto intercambiará lecturas ligeramente más altas por una CPU ligeramente más baja, por lo que puede ser mejor dependiendo de si su sistema ya está vinculado a la CPU o a la E/S).
Comprobación de cordura
Solo para asegurarnos de que estamos en el camino correcto, podemos verificar que las cinco funciones arrojan los resultados esperados:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Y, de hecho, estos son los resultados que vemos en los cinco casos...

Los datos de prueba
Ahora que sabemos que las funciones se comportan como se esperaba, podemos llegar a la parte divertida:probar el rendimiento con varios números de cadenas que varían en longitud. Pero primero necesitamos una mesa. Creé el siguiente objeto simple:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Llené esta tabla con un conjunto de cadenas de diferentes longitudes, asegurándome de que se utilizaría aproximadamente el mismo conjunto de datos para cada prueba:primero 10 000 filas donde la cadena tiene 50 caracteres de largo, luego 1000 filas donde la cadena tiene 500 caracteres de largo , 100 filas donde la cadena tiene una longitud de 5000 caracteres, 10 filas donde la cadena tiene una longitud de 50 000 caracteres y así sucesivamente hasta 1 fila de 500 000 caracteres. Hice esto tanto para comparar la misma cantidad de datos generales que procesan las funciones, como para tratar de mantener mis tiempos de prueba algo predecibles.
Uso una tabla #temp para poder simplemente usar GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Crear y completar esta tabla tomó alrededor de 20 segundos en mi máquina, y la tabla representa aproximadamente 6 MB de datos (alrededor de 500,000 caracteres por 2 bytes, o 1 MB por string_type, más la sobrecarga de fila e índice). No es una tabla enorme, pero debería ser lo suficientemente grande como para resaltar cualquier diferencia en el rendimiento entre las funciones.
Las Pruebas
Con las funciones en su lugar, y la tabla correctamente rellena con grandes cadenas para masticar, finalmente podemos ejecutar algunas pruebas reales para ver cómo se comportan las diferentes funciones con datos reales. Para medir el rendimiento sin tener en cuenta la sobrecarga de la red, utilicé SQL Sentry Plan Explorer, ejecuté cada conjunto de pruebas 10 veces, recopilé las métricas de duración y promedié.
La primera prueba simplemente extrajo los elementos de cada cadena como un conjunto:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Los resultados muestran que a medida que las cadenas se hacen más grandes, la ventaja de CLR realmente brilla. En el extremo inferior, los resultados fueron mixtos, pero nuevamente el método XML debería tener un asterisco junto a él, ya que su uso depende de la confianza en la entrada segura de XML. Para este caso de uso específico, la tabla Números tuvo el peor desempeño consistentemente:
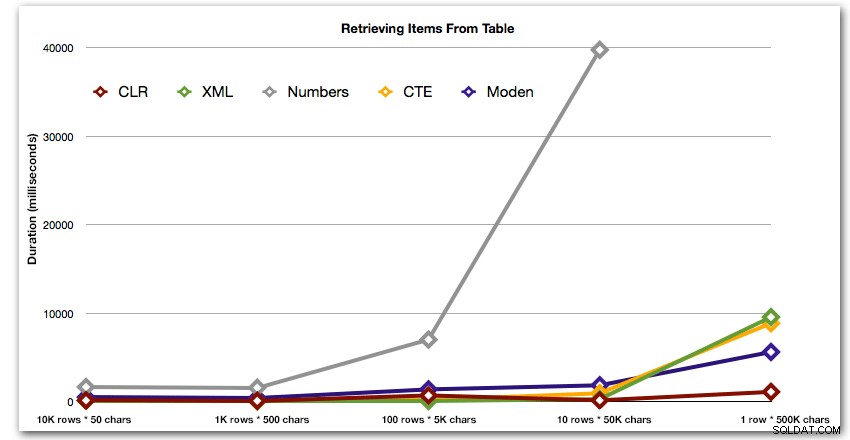
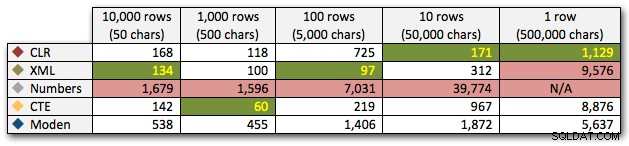
Duración, en milisegundos
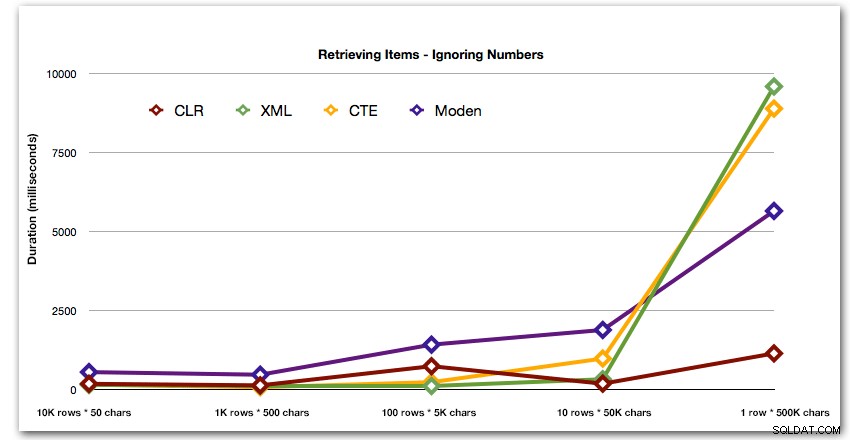
Después del desempeño hiperbólico de 40 segundos para la tabla de números contra 10 filas de 50,000 caracteres, la descarté de la ejecución para la última prueba. Para mostrar mejor el rendimiento relativo de los cuatro mejores métodos en esta prueba, eliminé los resultados de Números del gráfico por completo:
A continuación, comparemos cuando realizamos una búsqueda con el valor separado por comas (por ejemplo, devolver las filas donde una de las cadenas es 'foo'). Nuevamente, usaremos las cinco funciones anteriores, pero también compararemos el resultado con una búsqueda realizada en tiempo de ejecución usando LIKE en lugar de molestarnos en dividir.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Estos resultados muestran que, para cadenas pequeñas, CLR fue en realidad el más lento y que la mejor solución será realizar un escaneo usando LIKE, sin molestarse en dividir los datos en absoluto. Una vez más, eliminé la solución de la tabla de Números del quinto enfoque, cuando estaba claro que su duración aumentaría exponencialmente a medida que aumentaba el tamaño de la cadena:
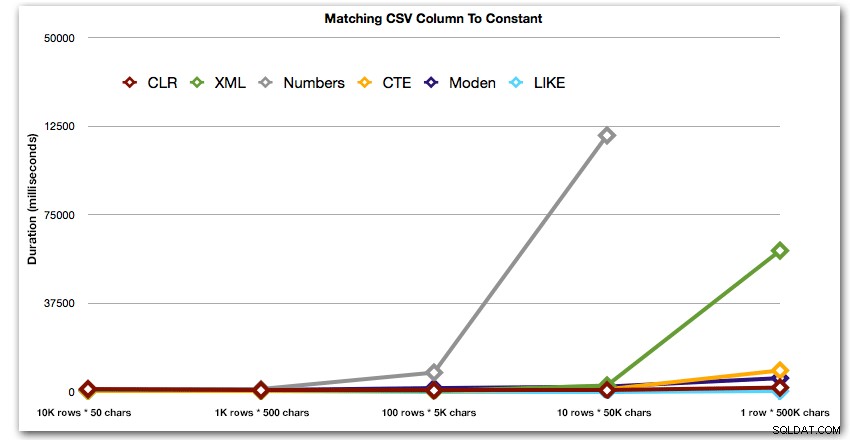
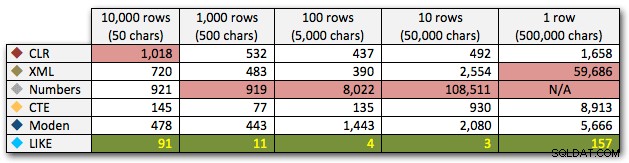
Duración, en milisegundos
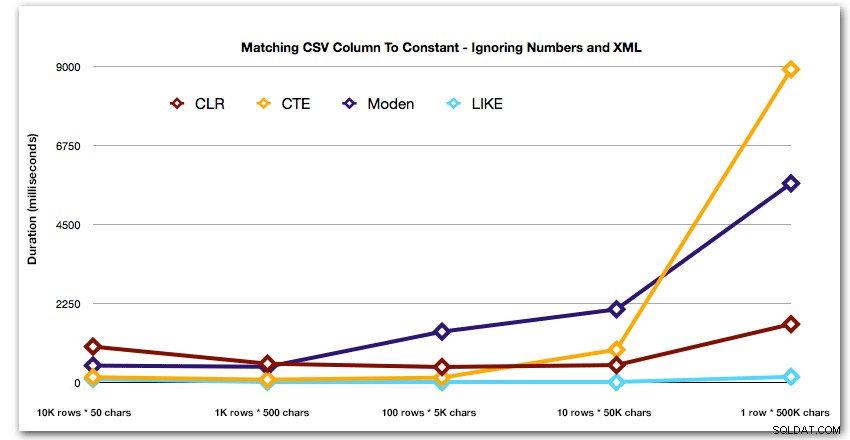
Y para demostrar mejor los patrones de los 4 resultados principales, eliminé las soluciones de Números y XML del gráfico:
A continuación, veamos cómo replicar el caso de uso desde el comienzo de esta publicación, donde intentamos encontrar todas las filas en una tabla que existen en la lista que se está pasando. Al igual que con los datos en la tabla que creamos anteriormente, Vamos a crear cadenas que varían en longitud de 50 a 500 000 caracteres, almacenarlas en una variable y luego verificar una vista de catálogo común para ver si existe en la lista.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Estos resultados muestran que, para este patrón, varios métodos ven aumentar su duración exponencialmente a medida que aumenta el tamaño de la cadena. En el extremo inferior, XML mantiene un buen ritmo con CLR, pero esto también se deteriora rápidamente. CLR es consistentemente el claro ganador aquí:
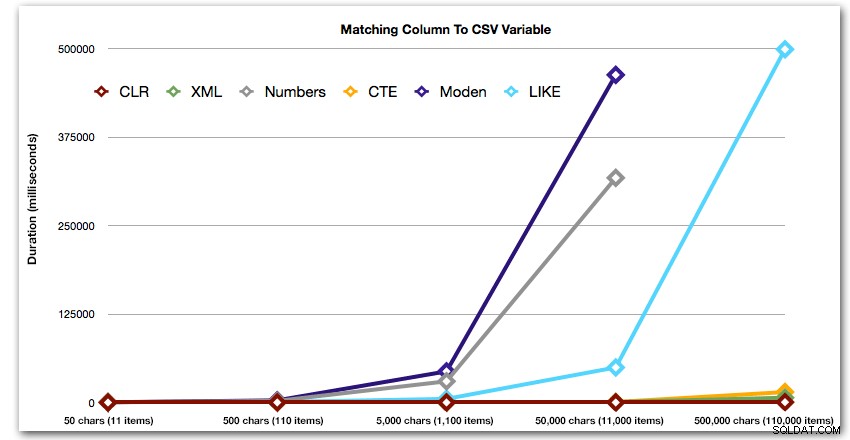
Duración, en milisegundos
Y nuevamente sin los métodos que explotan hacia arriba en términos de duración:
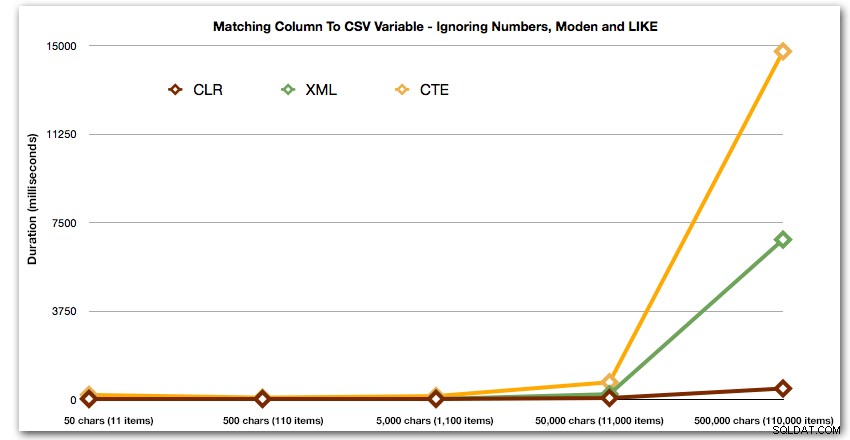
Finalmente, comparemos el costo de recuperar los datos de una sola variable de longitud variable, ignorando el costo de leer los datos de una tabla. De nuevo, generaremos cadenas de longitud variable, de 50 a 500 000 caracteres, y luego devolveremos los valores como un conjunto:
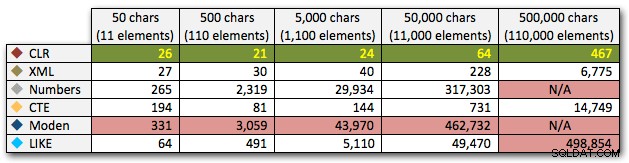
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Estos resultados también muestran que CLR es bastante plano en términos de duración, hasta 110 000 elementos en el conjunto, mientras que los otros métodos mantienen un ritmo decente hasta algún tiempo después de los 11 000 elementos:
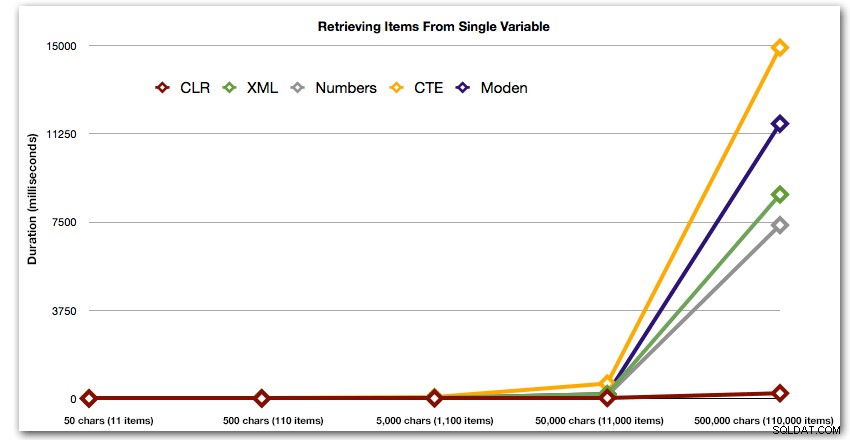
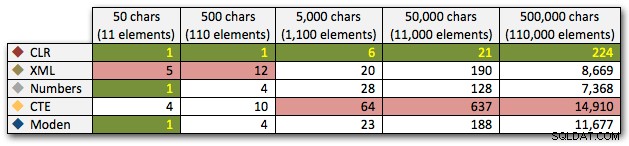
Duración, en milisegundos
Conclusión
En casi todos los casos, la solución CLR claramente supera a los otros enfoques; en algunos casos es una victoria aplastante, especialmente a medida que aumenta el tamaño de las cadenas; en algunos otros, es un acabado fotográfico que podría fallar de cualquier manera. En la primera prueba, vimos que XML y CTE superaron a CLR en el extremo inferior, por lo que si este es un caso de uso típico *y* está seguro de que sus cadenas están en el rango de 1 a 10,000 caracteres, uno de esos enfoques podría ser una mejor opción. Si los tamaños de sus cadenas son menos predecibles que eso, CLR probablemente siga siendo su mejor apuesta en general:pierde unos pocos milisegundos en el extremo inferior, pero gana mucho en el extremo superior. Estas son las elecciones que haría, según la tarea, con el segundo lugar resaltado para los casos en los que CLR no es una opción. Tenga en cuenta que XML es mi método preferido solo si sé que la entrada es segura para XML; estas pueden no ser necesariamente sus mejores alternativas si tiene menos fe en su aporte.
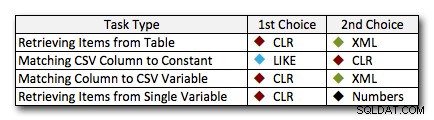
La única excepción real en la que CLR no es mi elección general es el caso en el que en realidad está almacenando listas separadas por comas en una tabla y luego encuentra filas donde una entidad definida está en esa lista. En ese caso específico, probablemente recomendaría primero rediseñar y normalizar correctamente el esquema, de modo que esos valores se almacenen por separado, en lugar de usarlo como una excusa para no usar CLR para dividir.
Si no puede usar CLR por otras razones, estas pruebas no revelan un "segundo lugar" claro; mis respuestas anteriores se basaron en la escala general y no en ningún tamaño de cadena específico. Cada solución aquí fue finalista en al menos un escenario, por lo que si bien CLR es claramente la opción cuando puede usarlo, lo que debe usar cuando no puede es más una respuesta de "depende":tendrá que juzgar en función de su(s) caso(s) de uso y las pruebas anteriores (o construyendo sus propias pruebas) qué alternativa es mejor para usted.
Anexo:una alternativa a la división en primer lugar
Los enfoques anteriores no requieren cambios en su(s) aplicación(es) existente(s), asumiendo que ya están ensamblando una cadena separada por comas y arrojándola a la base de datos para tratarla. Una opción que debe considerar, si CLR no es una opción y/o puede modificar las aplicaciones, es usar parámetros con valores de tabla (TVP). Aquí hay un ejemplo rápido de cómo utilizar un TVP en el contexto anterior. Primero, cree un tipo de tabla con una sola columna de cadena:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Luego, el procedimiento almacenado puede tomar este TVP como entrada y unirse al contenido (o usarlo de otras formas; este es solo un ejemplo):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Ahora, en su código C#, por ejemplo, en lugar de crear una cadena separada por comas, complete una tabla de datos (o use cualquier colección compatible que ya contenga su conjunto de valores):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Puede considerar que esto es una precuela de una publicación de seguimiento.
Por supuesto, esto no funciona bien con JSON y otras API; a menudo, la razón por la que se pasa una cadena separada por comas a SQL Server en primer lugar.



