Esta tampoco es una buena fragmentación
El mes pasado escribí sobre la fragmentación inesperada de índices agrupados, por lo que, esta vez, me gustaría discutir algunas de las cosas que puede hacer para evitar que ocurra la fragmentación de índices. Asumiré que ha leído la publicación anterior y está familiarizado con los términos que definí allí, y en el resto de este artículo, cuando digo 'fragmentación' me refiero tanto a la fragmentación lógica como a los problemas de baja densidad de página.
Elija una buena clave de clúster
La estructura de datos más costosa para operar para eliminar la fragmentación es el índice agrupado de una tabla, porque es la estructura más grande ya que contiene todos los datos de la tabla. Desde la perspectiva de la fragmentación, tiene sentido elegir una clave de clúster que coincida con el patrón de inserción de la tabla, por lo que no hay posibilidad de que se produzca una inserción en una página donde no hay espacio y, por lo tanto, provoque una división de la página e introduzca fragmentación.
Lo que constituye la mejor clave de clúster para cualquier tabla dada es un tema de mucho debate, pero en general no se equivocará si su clave de clúster tiene las siguientes propiedades simples:
- Angosto (es decir, con la menor cantidad de columnas posible)
- Estático (es decir, nunca lo actualizas)
- Único
- Cada vez más
Es la propiedad cada vez mayor que es la más importante para la prevención de la fragmentación, ya que evita inserciones aleatorias que pueden causar divisiones de página en páginas que ya están llenas. Ejemplos de una elección de clave de este tipo son las columnas de identidad int y bigint, o incluso un GUID secuencial de la función NEWSEQUENTIALID().
Con estos tipos de claves, las filas nuevas tendrán un valor de clave garantizado que será más alto que todos los demás en la tabla, por lo que el punto de inserción de la fila nueva estará al final de la página más a la derecha en la estructura del índice agrupado. Eventualmente, las nuevas filas llenarán esa página y se agregará otra página al lado derecho del índice, pero sin que se produzca una división de página dañina.
Ahora, si tiene una clave de índice agrupada que no aumenta constantemente, puede ser un procedimiento muy complejo y desagradable cambiarla a una clave que aumenta constantemente, así que no se preocupe; en su lugar, puede usar un factor de relleno como discutí a continuación.
Por cierto, para obtener una visión mucho más profunda de cómo elegir una clave de clúster y todas sus ramificaciones, consulte la categoría del blog Clave de clúster de Kimberly (leer de abajo hacia arriba).
No actualice las columnas de clave de índice
Cada vez que se actualiza una columna clave, no se trata de una simple actualización en el lugar, aunque muchos lugares en línea y en libros dicen que lo es (están equivocados). Una columna de clave no se puede actualizar en su lugar, ya que el nuevo valor de clave significaría que la fila está en el orden de clave incorrecto para el índice. En su lugar, una actualización de columna clave se traduce en una eliminación de fila completa más una inserción de fila completa con el nuevo valor clave. Si la página en la que se insertará la nueva fila no tiene suficiente espacio, se producirá una división de la página, lo que provocará la fragmentación.
Evitar las actualizaciones de la columna clave debería ser fácil de hacer para el índice agrupado, ya que es un diseño deficiente que requiere actualizar la clave del clúster de una fila de la tabla. Sin embargo, para los índices no agrupados, es inevitable si las actualizaciones de la tabla involucran columnas en las que hay un índice no agrupado. Para esos casos, deberá usar un factor de relleno.
No actualizar columnas de longitud variable
Este es más fácil decirlo que hacerlo. Si tiene que usar columnas de longitud variable y es posible que se actualicen, entonces es posible que crezcan y requieran más espacio para la fila actualizada, lo que lleva a una división de página si la página ya está llena.
Hay algunas cosas que podría hacer para evitar la fragmentación en este caso:
- Usar un factor de relleno
- Use una columna de longitud fija en su lugar, si la sobrecarga de todos los bytes de relleno adicionales es un problema menor que la fragmentación o el uso de un factor de relleno
- Use un valor de marcador de posición para 'reservar' espacio para la columna:este es un truco que puede usar si la aplicación ingresa una nueva fila y luego regresa para completar algunos de los detalles, lo que provoca una expansión de columna de longitud variable
- Realice una eliminación más una inserción en lugar de una actualización
Usar un factor de relleno
Como puede ver, muchas de las formas de evitar la fragmentación son desagradables, ya que implican cambios en la aplicación o en el esquema, por lo que usar un factor de relleno es una manera fácil de mitigar la fragmentación.
Un factor de relleno de índice es una configuración para el índice que especifica cuánto espacio vacío dejar en cada página de nivel de hoja cuando se crea, reconstruye o reorganiza el índice. La idea es que haya suficiente espacio libre en la página para permitir inserciones aleatorias o crecimientos de filas (a partir de la adición de una etiqueta de control de versiones o la actualización de columnas de longitud variable) sin que la página se llene y requiera una división de página. Sin embargo, eventualmente la página se llenará y, por lo tanto, el espacio libre debe actualizarse periódicamente mediante la reconstrucción o reorganización del índice (lo que generalmente se denomina mantenimiento del índice). El truco está en encontrar el factor de relleno correcto para usar, junto con la periodicidad correcta del mantenimiento del índice.
Puede leer más sobre cómo establecer un factor de relleno en MSDN aquí. No caiga en la trampa de configurar el factor de relleno para toda la instancia (usando sp_configure), ya que eso significa que todos los índices se reconstruirán o reorganizarán usando ese valor de factor de relleno, incluso aquellos índices que no tengan problemas de fragmentación. No desea que sus índices agrupados grandes, con claves agradables en constante aumento, tengan el 30% de su espacio de nivel de hoja desperdiciado preparándose para inserciones aleatorias que nunca sucederán. Es mucho mejor averiguar qué índices se ven realmente afectados por la fragmentación y solo establecer un factor de relleno para ellos.
No hay una respuesta correcta o una fórmula mágica que pueda darte para esto. La práctica generalmente aceptada es establecer un factor de relleno de 70 (lo que significa dejar un 30 % de espacio libre) para aquellos índices en los que la fragmentación es un problema, controlar la rapidez con la que se produce la fragmentación y luego modificar el factor de relleno o la frecuencia de mantenimiento del índice. (o ambos).
Sí, esto significa que está desperdiciando espacio deliberadamente en los índices para evitar la fragmentación, pero es una buena compensación dado lo costosas que son las divisiones de página y lo perjudicial que puede ser la fragmentación para el rendimiento. Y sí, a pesar de lo que algunos puedan decir, esto sigue siendo importante incluso si usa SSD.
Resumen
Hay algunas cosas simples que puede hacer para evitar que ocurra la fragmentación, pero tan pronto como ingresa a índices no agrupados, o usa aislamiento de instantáneas o secundarios legibles, la fragmentación asoma su fea cabeza y debe intentar prevenirla.
Ahora no se deje llevar por la idea de que debe establecer un factor de relleno de 70 en todas sus instancias; debe elegirlas y configurarlas con cuidado, como describí anteriormente.
Y no se olvide de SQL Sentry Fragmentation Manager, que puede usar (como un complemento de Performance Advisor) para ayudar a determinar dónde están los problemas de fragmentación y luego abordarlos. Por ejemplo, en la pestaña Índices, puede ordenar fácilmente sus índices primero por la fragmentación más alta (y, si lo desea, aplicar un filtro a la columna de recuento de filas para ignorar las tablas más pequeñas):
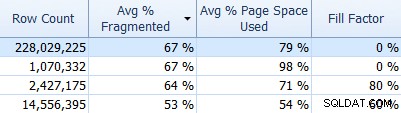
Y luego vea si esos índices están usando el factor de relleno predeterminado (0%), o quizás un factor de relleno no predeterminado, que podría no ser una buena combinación para sus datos y patrones DML. Te dejaré adivinar cuáles en la captura de pantalla anterior estaría más interesado en investigar. Implementar factores de relleno de índice más apropiados es la forma más sencilla de abordar cualquier problema que detecte.