
Mike Donnelly (@SQLMD) organiza el martes de T-SQL de este mes y resume el tema de la siguiente manera:
El tema de este mes es sencillo, pero muy abierto. Debes aprender algo nuevo y luego escribir una publicación de blog explicándolo.Bueno, desde el momento en que Mike anunció el tema, realmente no me propuse aprender nada nuevo, y a medida que se acercaba el fin de semana y sabía que el lunes me asaltaría con el deber de jurado, pensé que tendría que sentarme aquí. mes fuera.
Luego, Martin Smith me enseñó algo que nunca supe, o que supe hace mucho pero que he olvidado (a veces no sabes lo que no sabes, y a veces no puedes recordar lo que nunca supiste y lo que no puedes). recordar). Mi recuerdo fue que cambiar una columna de NOT NULL a NULL debería ser una operación solo de metadatos, con escrituras en cualquier página que se posponen hasta que esa página se actualice por otras razones, ya que NULL el mapa de bits realmente no necesitaría existir hasta que al menos una fila pudiera convertirse en NULL .
En esa misma publicación, @ypercube también me recordó esta cita pertinente de Books Online (error tipográfico y todo):
La modificación de una columna de NOT NULL a NULL no se admite como una operación en línea cuando la columna modificada es referenciada por índices no agrupados."No es una operación en línea" puede interpretarse como "no es una operación solo de metadatos", lo que significa que en realidad será una operación de tamaño de datos (cuanto mayor sea su índice, más tiempo llevará).
Me propuse probar esto con un experimento bastante simple (pero largo) contra una columna de destino específica para convertir de NOT NULL a NULL . Crearía 3 tablas, todas con una clave principal agrupada, pero cada una con un índice no agrupado diferente. Uno tendría la columna de destino como columna clave, el segundo como INCLUDE columna, y la tercera no haría referencia a la columna de destino en absoluto.
Aquí están mis tablas y cómo las rellené:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Cada tabla tenía 100 000 filas, los índices agrupados tenían 310 páginas y los índices no agrupados tenían 272 páginas (test1 y test2 ) o 174 páginas (test3 ). (Estos valores son fáciles de obtener de sys.dm_db_index_physical_stats .)
A continuación, necesitaba una forma sencilla de capturar las operaciones registradas a nivel de página:elegí sys.fn_dblog() , aunque podría haber cavado más profundo y mirar las páginas directamente. No me molesté en jugar con los valores de LSN para pasarlos a la función, ya que no estaba ejecutando esto en producción y no me importaba mucho el rendimiento, así que después de las pruebas simplemente descargué los resultados de la función, excluyendo cualquier dato que se registró antes de ALTER TABLE operaciones.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Ahora podía ejecutar mis pruebas, que eran mucho más simples que la configuración.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Ahora podría examinar las operaciones que se registraron en cada caso:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Los resultados parecen sugerir que se toca cada página de hoja del índice no agrupado en los casos en que la columna de destino se menciona en el índice de alguna manera, pero tales operaciones no ocurren en el caso en que la columna de destino no se menciona en ningún caso. índice no agrupado:
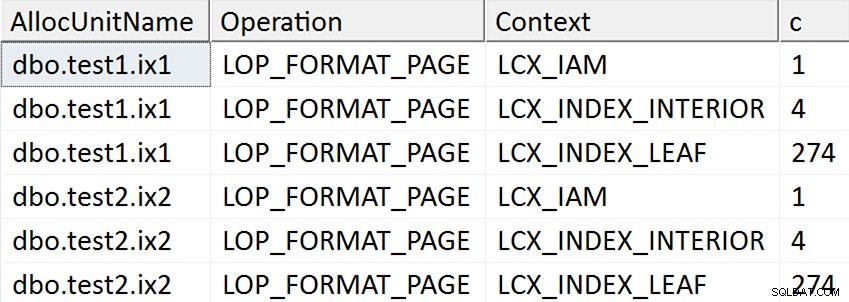
De hecho, en los dos primeros casos, se asignan nuevas páginas (puedes validarlo con DBCC IND , como hizo Spörri en su respuesta), por lo que la operación puede ocurrir en línea, pero eso no significa que sea rápida (ya que todavía tiene que escribir una copia de todos esos datos y hacer el NULL cambio de mapa de bits como parte de escribir cada página nueva y registrar toda esa actividad).
Creo que la mayoría de la gente sospecharía que cambiar una columna de NOT NULL a NULL sería solo metadatos en todos los escenarios, pero he demostrado aquí que esto no es cierto si la columna está referenciada por un índice no agrupado (y suceden cosas similares ya sea una clave o INCLUDE columna). Quizás esta operación también se puede forzar a ser ONLINE en Azure SQL Database hoy, o será posible en la próxima versión principal? Esto no necesariamente hará que las operaciones físicas reales sucedan más rápido, pero evitará el bloqueo como resultado.
No probé ese escenario (y el análisis de si realmente está en línea es más difícil en Azure de todos modos), ni lo probé en un montón. Algo que puedo revisar en una publicación futura. Mientras tanto, tenga cuidado con cualquier suposición que pueda hacer sobre las operaciones solo de metadatos.



