La estrategia general que utiliza el motor de base de datos de SQL Server para mantener una vista indexada sincronizada con sus tablas base, que describí con más detalle en mi última publicación, es realizar mantenimiento incremental de la vista cada vez que se produce una operación de cambio de datos en una de las tablas a las que se hace referencia en la vista. En términos generales, la idea es:
- Recopilar información sobre los cambios en la tabla base
- Aplicar las proyecciones, los filtros y las uniones definidas en la vista
- Agregue los cambios por clave agrupada de vista indexada
- Decida si cada cambio debe resultar en una inserción, actualización o eliminación en la vista
- Calcular los valores para cambiar, agregar o eliminar en la vista
- Aplicar los cambios de vista
O, aún más sucintamente (aunque a riesgo de una gran simplificación):
- Calcular los efectos de vista incremental de las modificaciones de datos originales;
- Aplica esos cambios a la vista
Por lo general, esta es una estrategia mucho más eficiente que reconstruir la vista completa después de cada cambio de datos subyacente (la opción segura pero lenta), pero depende de que la lógica de actualización incremental sea correcta para cada cambio de datos concebible, contra cada posible definición de vista indexada.
Como sugiere el título, este artículo se ocupa de un caso interesante en el que la lógica de actualización incremental falla, lo que da como resultado una vista indexada corrupta que ya no coincide con los datos subyacentes. Antes de llegar al error en sí, debemos revisar rápidamente los agregados escalares y vectoriales.
Agregados escalares y vectoriales
En caso de que no esté familiarizado con el término, hay dos tipos de agregados. Un agregado que está asociado con una cláusula GROUP BY (incluso si la lista de grupos está vacía) se conoce como un agregado vectorial. . Un agregado sin una cláusula GROUP BY se conoce como agregado escalar .
Mientras que se garantiza que un agregado vectorial produzca una sola fila de salida para cada grupo presente en el conjunto de datos, los agregados escalares son un poco diferentes. Agregados escalares siempre producir una única fila de salida, incluso si el conjunto de entrada está vacío.
Ejemplo de agregado de vectores
El siguiente ejemplo de AdventureWorks calcula dos agregados vectoriales (una suma y un recuento) en un conjunto de entrada vacío:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Estas consultas producen el siguiente resultado (sin filas):

El resultado es el mismo, si reemplazamos la cláusula GROUP BY con un conjunto vacío (requiere SQL Server 2008 o posterior):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Los planes de ejecución son idénticos también en ambos casos. Este es el plan de ejecución para la consulta de conteo:
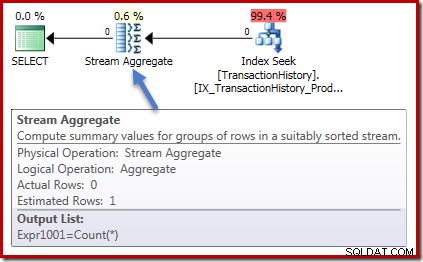
Cero filas de entrada a Stream Aggregate y cero filas de salida. El plan de ejecución de la suma se ve así:

Nuevamente, cero filas hacia el agregado y cero filas hacia afuera. Todo lo bueno y sencillo hasta ahora.
Agregados escalares
Ahora mire lo que sucede si eliminamos completamente la cláusula GROUP BY de las consultas:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
En lugar de un resultado vacío, el agregado COUNT produce un cero y SUM devuelve un NULL:
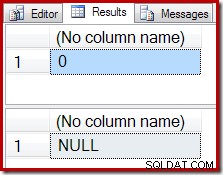
El plan de ejecución de conteo confirma que las filas de entrada cero producen una sola fila de salida de Stream Aggregate:
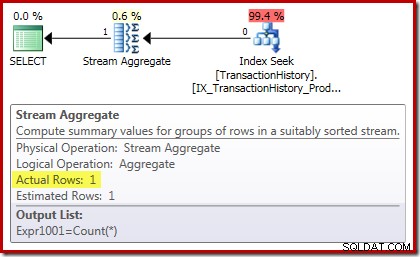
El plan de ejecución de la suma es aún más interesante:
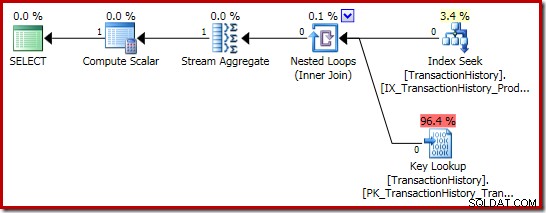
Las propiedades de Stream Aggregate muestran un agregado de conteo que se calcula además de la suma que solicitamos:
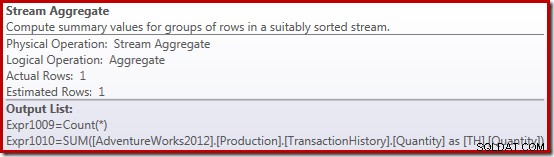
El nuevo operador Compute Scalar se usa para devolver NULL si el recuento de filas recibidas por Stream Aggregate es cero; de lo contrario, devuelve la suma de los datos encontrados:
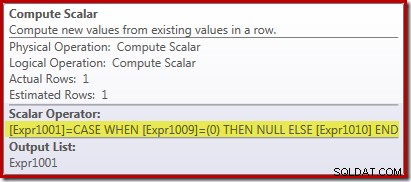
Todo esto puede parecer un poco extraño, pero así es como funciona:
- Un vector agregado de cero filas devuelve cero filas;
- Un agregado escalar siempre produce exactamente una fila de salida, incluso para una entrada vacía;
- El conteo escalar de cero filas es cero; y
- La suma escalar de cero filas es NULL (no cero).
El punto importante para nuestros propósitos actuales es que los agregados escalares siempre producen una sola fila de salida, incluso si eso significa crear una de la nada. Además, la suma escalar de cero filas es NULL, no cero.
Estos comportamientos son todos "correctos" por cierto. Las cosas son como son porque SQL Standard originalmente no definió el comportamiento de los agregados escalares, dejándolo a la implementación. SQL Server conserva su implementación original por motivos de compatibilidad con versiones anteriores. Los agregados de vectores siempre han tenido comportamientos bien definidos.
Vistas indexadas y agregación de vectores
Ahora considere una vista indexada simple que incorpore un par de agregados (vectoriales):
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Las siguientes consultas muestran el contenido de la tabla base, el resultado de consultar la vista indexada y el resultado de ejecutar la consulta de vista en la tabla subyacente a la vista:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Los resultados son:
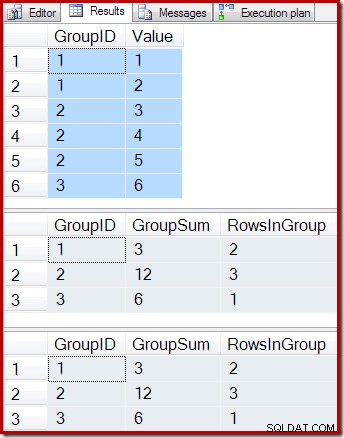
Como era de esperar, la vista indexada y la consulta subyacente devuelven exactamente los mismos resultados. Los resultados seguirán estando sincronizados después de todos los cambios posibles en la tabla base T1. Para recordarnos cómo funciona todo esto, consideremos el caso simple de agregar una sola fila nueva a la tabla base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); El plan de ejecución de esta inserción contiene toda la lógica necesaria para mantener sincronizada la vista indexada:
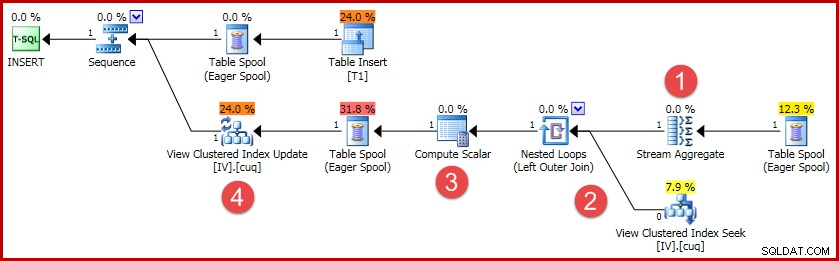
Las principales actividades del plan son:
- Stream Aggregate calcula los cambios por clave de vista indexada
- La unión externa a la vista vincula el resumen de cambios a la fila de la vista de destino, si corresponde
- El cálculo escalar decide si cada cambio requerirá una inserción, actualización o eliminación en la vista y calcula los valores necesarios.
- El operador de actualización de vista realiza físicamente cada cambio en el índice agrupado de vista.
Hay algunas diferencias de planes para diferentes operaciones de cambio en la tabla base (por ejemplo, actualizaciones y eliminaciones), pero la idea general detrás de mantener la vista sincronizada sigue siendo la misma:agregue los cambios por clave de vista, busque la fila de la vista si existe, luego realice una combinación de operaciones de inserción, actualización y eliminación en el índice de vista según sea necesario.
Independientemente de los cambios que realice en la tabla base en este ejemplo, la vista indexada permanecerá correctamente sincronizada:las consultas anteriores NOEXPAND y EXPAND VIEWS siempre devolverán el mismo conjunto de resultados. Así es como deberían funcionar siempre las cosas.
Vistas indexadas y agregación escalar
Ahora pruebe este ejemplo, donde la vista indexada usa agregación escalar (sin cláusula GROUP BY en la vista):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Esta es una vista indexada perfectamente legal; no se encuentran errores al crearlo. Sin embargo, hay una pista de que podríamos estar haciendo algo un poco extraño:cuando llega el momento de materializar la vista creando el índice agrupado único requerido, no hay una columna obvia para elegir como clave. Normalmente, elegiríamos las columnas de agrupación de la cláusula GROUP BY de la vista, por supuesto.
El script anterior elige arbitrariamente la columna NumRows. Esa elección no es importante. Siéntase libre de crear el índice agrupado único como quiera. La vista siempre contendrá exactamente una fila debido a los agregados escalares, por lo que no hay posibilidad de una violación de clave única. En ese sentido, la elección de la clave de índice de vista es redundante, pero no obstante necesaria.
Reutilizando las consultas de prueba del ejemplo anterior, podemos ver que la vista indexada funciona correctamente:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
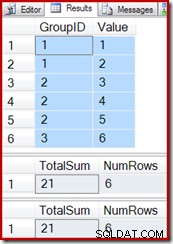
La inserción de una nueva fila en la tabla base (como hicimos con la vista indexada del agregado vectorial) también sigue funcionando correctamente:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); El plan de ejecución es similar, pero no del todo idéntico:
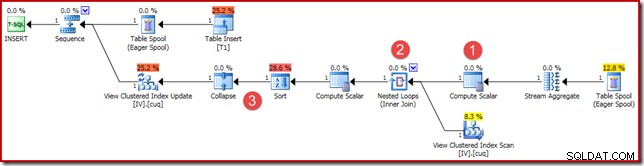
Las principales diferencias son:
- Este nuevo Compute Scalar está ahí por las mismas razones que cuando comparamos los resultados de la agregación vectorial y escalar anteriormente:garantiza que se devuelva una suma NULL (en lugar de cero) si el agregado opera en un conjunto vacío. Este es el comportamiento requerido para una suma escalar sin filas.
- La combinación externa que se vio anteriormente se reemplazó por una combinación interna. Siempre habrá exactamente una fila en la vista indexada (debido a la agregación escalar), por lo que no se trata de necesitar una combinación externa para probar si una fila de vista coincide o no. La única fila presente en la vista siempre representa el conjunto completo de datos. Esta unión interna no tiene predicado, por lo que técnicamente es una unión cruzada (a una tabla con una sola fila garantizada).
- Los operadores Sort y Collapse están presentes por razones técnicas cubiertas en mi artículo anterior sobre el mantenimiento de vistas indexadas. No afectan el correcto funcionamiento del mantenimiento de la vista indexada aquí.
De hecho, muchos tipos diferentes de operaciones de cambio de datos se pueden realizar con éxito en la tabla base T1 en este ejemplo; los efectos se reflejarán correctamente en la vista indexada. Las siguientes operaciones de cambio en la tabla base se pueden realizar manteniendo la vista indexada correcta:
- Eliminar filas existentes
- Actualizar filas existentes
- Insertar filas nuevas
Esta puede parecer una lista completa, pero no lo es.
El error revelado
El problema es bastante sutil y se relaciona (como debería esperar) con los diferentes comportamientos de los agregados vectoriales y escalares. Los puntos clave son que un agregado escalar siempre producirá una fila de salida, incluso si no recibe filas en su entrada, y la suma escalar de un conjunto vacío es NULL, no cero.
Para causar un problema, todo lo que tenemos que hacer es insertar o eliminar filas en la tabla base.
Esa declaración no es tan loca como podría parecer a primera vista.
El punto es que una consulta de inserción o eliminación que no afecta las filas de la tabla base actualizará la vista, porque el Agregado de flujo escalar en la parte de mantenimiento de la vista indexada del plan de consulta producirá una fila de salida incluso cuando se presente sin entrada. El Compute Scalar que sigue al Stream Aggregate también generará una suma NULL cuando el conteo de filas sea cero.
La siguiente secuencia de comandos demuestra el error en acción:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
El resultado de ese script se muestra a continuación:
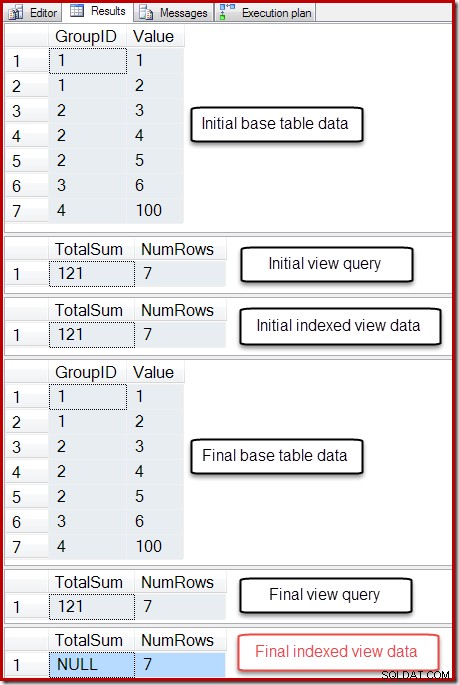
El estado final de la columna Total Sum de la vista indexada no coincide con la consulta de vista subyacente o los datos de la tabla base. La suma NULL ha dañado la vista, lo que se puede confirmar ejecutando DBCC CHECKTABLE (en la vista indexada).
El plan de ejecución responsable de la corrupción se muestra a continuación:
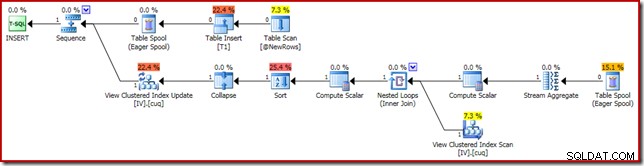
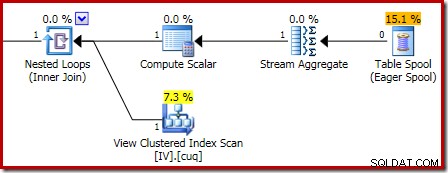
Al acercar se muestra la entrada de cero filas para Stream Aggregate y la salida de una fila:
Si desea probar el script de corrupción anterior con una eliminación en lugar de una inserción, aquí hay un ejemplo:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
La eliminación no afecta las filas de la tabla base, pero aún cambia la columna de suma de la vista indexada a NULL.
Generalizar el error
Probablemente pueda generar cualquier cantidad de consultas de inserción y eliminación de la tabla base que no afecten a las filas y provoquen que esta vista indexada se dañe. Sin embargo, el mismo problema básico se aplica a una clase más amplia de problemas que solo las inserciones y eliminaciones que no afectan las filas de la tabla base.
Es posible, por ejemplo, producir la misma corrupción utilizando una inserción que hace agregar filas a la tabla base. El ingrediente esencial es que ninguna fila agregada debe calificar para la vista . Esto dará como resultado una entrada vacía para Stream Aggregate y la salida de fila NULL que causa corrupción del siguiente Compute Scalar.
Una forma de lograr esto es incluir una cláusula WHERE en la vista que rechace algunas de las filas de la tabla base:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Dada la nueva restricción en los ID de grupo incluidos en la vista, la siguiente inserción agregará filas a la tabla base, pero aún corromperá la vista indexada con una suma NULL:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; El resultado muestra la corrupción del índice ahora familiar:
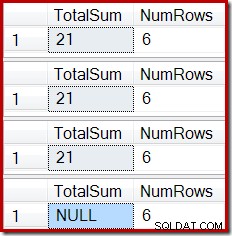
Se puede producir un efecto similar utilizando una vista que contiene una o más uniones internas. Siempre que se rechacen las filas agregadas a la tabla base (por ejemplo, al no poder unirse), Stream Aggregate no recibirá filas, Compute Scalar generará una suma NULL y es probable que la vista indexada se corrompa.
Reflexiones finales
Este problema no ocurre para las consultas de actualización (al menos hasta donde puedo decir), pero esto parece ser más por accidente que por diseño:el Stream Aggregate problemático todavía está presente en los planes de actualización potencialmente vulnerables, pero el Compute Scalar que genera la suma NULL no se agrega (o quizás se optimiza). Avíseme si logra reproducir el error mediante una consulta de actualización.
Hasta que se corrija este error (o, quizás, los agregados escalares no se permitan en las vistas indexadas), tenga mucho cuidado al usar agregados en una vista indexada sin una cláusula GROUP BY.
Este artículo fue motivado por un elemento de Connect enviado por Vladimir Moldovanenko, quien tuvo la amabilidad de dejar un comentario en una publicación de blog anterior mía (que se refiere a una corrupción de vista indexada diferente causada por la declaración MERGE). Vladimir estaba usando agregados escalares en una vista indexada por buenas razones, así que no se apresure a juzgar este error como un caso límite que nunca encontrará en un entorno de producción. Mi agradecimiento a Vladimir por alertarme sobre su elemento Connect.