Esta publicación proporciona nueva información sobre las condiciones previas para carga masiva mínimamente registrada al usar INSERT...SELECT en tablas indexadas .
La instalación interna que habilita estos casos se llama FastLoadContext . Se puede activar desde SQL Server 2008 hasta 2014 inclusive usando el indicador de seguimiento documentado 610. Desde SQL Server 2016 en adelante, FastLoadContext está habilitado de forma predeterminada; la marca de seguimiento no es necesaria.
Sin FastLoadContext , las únicas inserciones de índice que se pueden registrar mínimamente son esos en un vacío índice agrupado sin índices secundarios, como se trata en la segunda parte de esta serie. El registro mínimo las condiciones para las tablas de montones no indexadas se trataron en la primera parte.
Para obtener más información, consulte la Guía de carga de rendimiento de datos y el Tiger Team notas sobre los cambios de comportamiento para SQL Server 2016.
Contexto de carga rápida
Como recordatorio rápido, RowsetBulk instalación (cubierta en las partes 1 y 2) permite minimly-logged carga masiva para:
- Montón vacío y no vacío tablas con:
- Bloqueo de mesa; y
- Sin índices secundarios.
- Tablas agrupadas vacías , con:
- Bloqueo de mesa; y
- Sin índices secundarios; y
DMLRequestSort=trueen el inserto de índice agrupado operador.
El FastLoadContext la ruta del código agrega soporte para registrados mínimamente y concurrente carga masiva en:
- Vacío y no vacío agrupado índices de árbol b.
- Vacío y no vacío no agrupado índices b-tree mantenidos por un dedicado Inserción de índice operador del plan.
El FastLoadContext también requiere DMLRequestSort=true en el operador del plan correspondiente en todos los casos.
Es posible que haya notado una superposición entre RowsetBulk y FastLoadContext para tablas agrupadas vacías sin índices secundarios. Un TABLOCK la sugerencia no es necesaria con FastLoadContext , pero no es obligatorio estar ausente o. Como consecuencia, una inserción adecuada con TABLOCK aún puede calificar para registro mínimo a través de FastLoadContext si falla el RowsetBulk detallado pruebas.
FastLoadContext se puede deshabilitar en SQL Server 2016 usando el indicador de seguimiento documentado 692. El evento extendido del canal de depuración fastloadcontext_enabled se puede usar para monitorear FastLoadContext uso por partición de índice (conjunto de filas). Este evento no se activa para RowsetBulk cargas.
registro mixto
Un solo INSERT...SELECT declaración usando FastLoadContext puede registrar por completo algunas filas mientras registro mínimo otros.
Las filas se insertan una a la vez por el inserto de índice operador y completamente conectado en los siguientes casos:
- Todas las filas añadidas a la primera página de índice, si el índice estaba vacío al inicio de la operación.
- Filas añadidas a existentes páginas de índice.
- Filas movidas entre páginas por una división de página.
De lo contrario, las filas del flujo de inserción ordenado se agregan a una página completamente nueva. mediante un sistema optimizado y registrado mínimamente ruta de código Una vez que se escriben tantas filas como sea posible en la nueva página, se vincula directamente a la estructura de índice de destino existente.
La página recién agregada no necesariamente estar lleno (aunque obviamente ese es el caso ideal) porque SQL Server debe tener cuidado de no agregar filas a la nueva página que lógicamente pertenecen a un existente Página de inicio. La nueva página se 'unirá' al índice como una unidad, por lo que no podemos tener filas en la nueva página que pertenezcan a otra parte. Esto es principalmente un problema al agregar filas dentro de el rango de clave de índice existente, en lugar de antes del inicio o después del final del rango de clave de índice existente.
Todavía es posible para agregar nuevas páginas dentro el rango de clave de índice existente, pero las nuevas filas deben clasificarse por encima de la clave más alta en el precedente página de índice existente y ordenar por debajo de la clave más baja en los siguientes página de índice existente. Para tener la mejor oportunidad de lograr un registro mínimo en estas circunstancias, asegúrese de que las filas insertadas no se superpongan con las filas existentes en la medida de lo posible.
Condiciones DMLRequestSort
Recuerda que FastLoadContext solo se puede activar si DMLRequestSort se establece en verdadero para el inserto de índice correspondiente operador en el plan de ejecución.
Hay dos rutas de código principales que pueden configurar DMLRequestSort a verdadero para inserciones de índice. Cualquier camino devolviendo verdadero es suficiente.
1. Insertar FOptimize
El sqllang!CUpdUtil::FOptimizeInsert el código requiere:
- Más de 250 filas estimado para ser insertado; y
- Más de 2 páginas estimado insertar tamaño de datos; y
- El índice objetivo debe tener menos de 3 hojas .
Estas condiciones son las mismas que RowsetBulk en un índice agrupado vacío, con un requisito adicional de no más de dos páginas de nivel de hoja de índice. Tenga en cuenta que esto se refiere al tamaño del índice existente antes del inserto, no el tamaño estimado de los datos que se agregarán.
El siguiente guión es una modificación de la demostración utilizada en partes anteriores de esta serie. Muestra registro mínimo cuando se rellenan menos de tres páginas de índice antes la prueba INSERT...SELECT carreras. El esquema de la tabla de prueba es tal que caben 130 filas en una sola página de 8 KB cuando la versión de fila está desactivada para la base de datos. El multiplicador en el primer TOP La cláusula se puede cambiar para determinar el número de páginas de índice existentes antes la prueba INSERT...SELECT se ejecuta:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
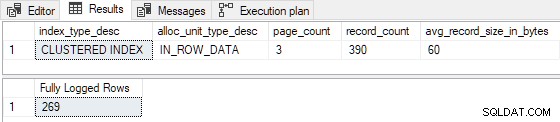
GO Cuando el índice agrupado está precargado con 3 páginas , la inserción de prueba está completamente registrada (registros de detalles del registro de transacciones omitidos por brevedad):
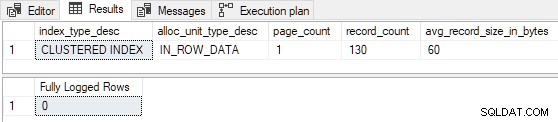
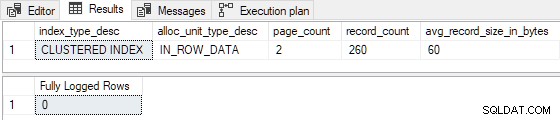
Cuando la tabla está precargada con solo 1 o 2 páginas , el inserto de prueba está registrado mínimamente :
Cuando la tabla no está precargada con cualquier página, la prueba es equivalente a ejecutar la demostración de la tabla agrupada vacía de la segunda parte, pero sin el TABLOCK pista:
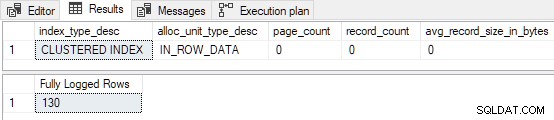
Las primeras 130 filas están completamente registradas . Esto se debe a que el índice estaba vacío antes de comenzar y caben 130 filas en la primera página. Recuerde, la primera página siempre se registra por completo cuando FastLoadContext se utiliza y el índice estaba vacío de antemano. Las 139 filas restantes se insertan con registro mínimo .
Si un TABLOCK se agrega una sugerencia al inserto, todas las páginas se registran mínimamente (incluido el primero) ya que la carga del índice agrupado vacío ahora califica para el RowsetBulk mecanismo (a costa de tomar un Sch-M bloquear).
2. FIlas de demanda clasificadas por rendimiento
Si FOptimizeInsert las pruebas fallan, DMLRequestSort aún puede establecerse en verdadero por un segundo conjunto de pruebas en sqllang!CUpdUtil::FDemandRowsSortedForPerformance código. Estas condiciones son un poco más complejas, por lo que será útil definir algunos parámetros:
P– número de páginas existentes a nivel de hoja en el índice objetivo .I– estimado número de filas para insertar.R=P/I(páginas de destino por fila insertada).T– número de particiones de destino (1 para no particionado).
La lógica para determinar el valor de DMLRequestSort es entonces:
- Si
P <= 16devuelve falso , de lo contrario :<último> - Si
R < 8:<último> - Si
P > 524devolver verdadero , de lo contrario falso .
R >= 8 :<último> T > 1 y I > 250 devolver verdadero , de lo contrario falso .
El procesador de consultas evalúa las pruebas anteriores durante la compilación del plan. Hay una condición final evaluado por el código del motor de almacenamiento (IndexDataSetSession::WakeUpInternal ) en tiempo de ejecución:
DMLRequestSortactualmente es verdadero; yI >= 100.
A continuación, dividiremos toda esta lógica en partes manejables.
Más de 16 páginas objetivo existentes
La primera prueba P <= 16 significa que los índices con menos de 17 páginas hoja existentes no calificarán para FastLoadContext a través de esta ruta de código. Para ser absolutamente claro en este punto, P es el número de páginas de nivel de hoja en el índice de destino antes el INSERT...SELECT se ejecuta.
Para demostrar esta parte de la lógica, cargaremos previamente la tabla agrupada de prueba con 16 páginas. de datos. Esto tiene dos efectos importantes (recuerde que ambas rutas de código deben devolver falso para terminar con un falso valor para DMLRequestSort ):
- Asegura que el anterior
FOptimizeInsertla prueba falla , porque no se cumple la tercera condición (P < 3). - El
P <= 16condición enFDemandRowsSortedForPerformancetampoco no cumplirse.
Por lo tanto, esperamos FastLoadContext para no estar habilitado. El script de demostración modificado es:
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Las 269 filas están completamente registradas como se predijo:
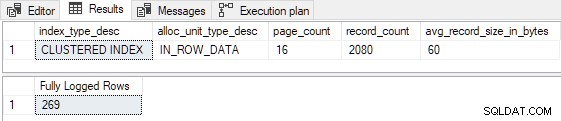
Tenga en cuenta que no importa qué tan alto establezcamos el número de nuevas filas para insertar, el script anterior nunca producir registro mínimo por la P <= 16 prueba (y P < 3 prueba en FOptimizeInsert ).
Si elige ejecutar la demostración usted mismo con una mayor cantidad de filas, comente la sección que muestra los registros de transacciones individuales; de lo contrario, esperará mucho tiempo y SSMS puede fallar. (Para ser justos, podría hacer eso de todos modos, pero ¿por qué aumentar el riesgo?)
Proporción de páginas por fila insertada
Si hay 17 o más páginas hoja en el índice existente, el anterior P <= 16 la prueba no fallará. La siguiente sección de lógica se ocupa de la proporción de páginas existentes a filas recién insertadas . Esto también debe pasar para lograr registro mínimo . Como recordatorio, las condiciones relevantes son:
- Relación
R=P/I. - Si
R < 8:<último> - Si
P > 524devolver verdadero , de lo contrario falso .
También debemos recordar la prueba final del motor de almacenamiento para al menos 100 filas:
I >= 100.
Reorganizando un poco esas condiciones, todas de lo siguiente debe ser cierto:
P > 524(páginas de índice existentes)I >= 100(filas insertadas estimadas)P / I < 8(relaciónR)
Hay múltiples formas de cumplir con esas tres condiciones simultáneamente. Elijamos los valores mínimos posibles para P (525) y I (100) dando una R valor de (525/100) =5,25. Esto satisface el (R < 8 prueba), por lo que esperamos que esta combinación resulte en registro mínimo :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
INSERT...SELECT de 100 filas es de hecho mínimamente registrado :
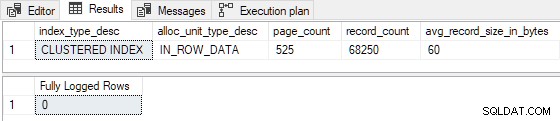
Reduciendo el estimado filas insertadas a 99 (rompiendo I >= 100 ), y/o reduciendo el número de páginas de índice existentes a 524 (rompiendo P > 524 ) genera un registro completo . También podríamos hacer cambios tales que R no es inferior a 8 para producir registro completo . Por ejemplo, establecer P = 1000 y I = 125 da R = 8 , con los siguientes resultados:
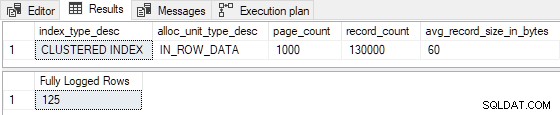
Las 125 filas insertadas fueron completamente registradas como se esperaba. (Esto no se debe al registro completo de la primera página, ya que el índice no estaba vacío de antemano).
Proporción de páginas para índices particionados
Si todas las pruebas anteriores fallan, la prueba restante requiere R >= 8 y puede solo estar satisfecho cuando el número de particiones (T ) es mayor que 1 y hay más de 250 estimados filas insertadas (I ). Recordar:
- Si
R >= 8:<último> - Si
T > 1yI > 250devolver verdadero , de lo contrario falso .
Una sutileza:para particionado índices, la regla que dice que todas las filas de la primera página están completamente registradas (para un índice inicialmente vacío) se aplica por partición . Para un objeto con 15 000 particiones, eso significa 15 000 "primeras" páginas totalmente registradas.
Resumen y pensamientos finales
Las fórmulas y el orden de evaluación descritos en el cuerpo se basan en la inspección del código mediante un depurador. Se presentaron en una forma que representa fielmente el tiempo y el orden utilizados en el código real.
Es posible reordenar y simplificar un poco esas condiciones, para producir un resumen más conciso de los requisitos prácticos para registro mínimo al insertar en un árbol b usando INSERT...SELECT . Las expresiones refinadas a continuación usan los siguientes tres parámetros:
P=número de existentes índice de páginas a nivel de hoja.I=estimado número de filas para insertar.S=estimado inserte el tamaño de los datos en páginas de 8 KB.
Carga masiva de conjuntos de filas
- Utiliza
sqlmin!RowsetBulk. - Requiere un vacío objetivo de índice agrupado con
TABLOCK(o equivalente). - Requiere
DMLRequestSort = trueen el inserto de índice agrupado operador. DMLRequestSortse establecetruesiI > 250yS > 2.- Todas las filas insertadas se registran mínimamente .
- Un
Sch-Mel bloqueo impide el acceso simultáneo a la tabla.
Contexto de carga rápida
- Utiliza
sqlmin!FastLoadContext. - Habilita registro mínimo inserciones en índices de árbol b:
- Agrupados o no agrupados.
- Con o sin bloqueo de mesa.
- Índice objetivo vacío o no.
- Requiere
DMLRequestSort = trueen el inserto de índice asociado operador del plan. - Solo filas escritas en marca nuevas páginas se cargan de forma masiva y se registran mínimamente .
- La primera página de un índice vacío anteriormente la partición siempre está completamente registrada .
- Mínimo absoluto de
I >= 100. - Requiere el indicador de seguimiento 610 antes de SQL Server 2016.
- Disponible de forma predeterminada desde SQL Server 2016 (la marca de seguimiento 692 se desactiva).
DMLRequestSort se establece true para:
- Cualquier índice (particionado o no) si:
I > 250yP < 3yS > 2; oI >= 100yP > 524yP < I * 8
Solo para índices particionados (con> 1 partición), DMLRequestSort también se establece en true si:
I > 250yP > 16yP >= I * 8
Hay algunos casos interesantes que surgen de esos FastLoadContext condiciones:
- Todos se inserta en un no particionado índice con entre 3 y 524 (inclusive) las páginas hoja existentes se registrarán por completo independientemente del número y el tamaño total de las filas añadidas. Esto afectará más notablemente a las inserciones grandes en tablas pequeñas (pero no vacías).
- Todos se inserta en un particionado índice con entre 3 y 16 las páginas existentes serán completamente registradas .
- Inserciones grandes a grandes sin particiones los índices pueden no estar registrados mínimamente debido a la desigualdad
P < I * 8. CuandoPes grande, un estimado correspondientemente grande número de filas insertadas (I) es requerido. Por ejemplo, un índice con 8 millones de páginas no puede admitir registro mínimo al insertar 1 millón de filas o menos.
Índices no agrupados
Las mismas consideraciones y cálculos aplicados a los índices agrupados en las demostraciones se aplican a no agrupados índices b-tree también, siempre que el índice sea mantenido por un operador de plan dedicado (un ancho o por índice plan). Índices no agrupados mantenidos por un operador de tabla base (por ejemplo, Inserción de índice agrupado ) no son elegibles para FastLoadContext .
Tenga en cuenta que los parámetros de fórmula deben evaluarse nuevamente para cada no agrupado operador de índice:tamaño de fila calculado, número de páginas de índice existentes y estimación de cardinalidad.
Comentarios generales
Cuidado con las estimaciones de baja cardinalidad en el inserto de índice operador, ya que estos afectarán el I y S parámetros Si no se alcanza un umbral debido a un error de estimación de cardinalidad, la inserción se registrará por completo .
Recuerda que DMLRequestSort está almacenado en caché con el plan — no se evalúa en cada ejecución de un plan reutilizado. Esto puede introducir una forma del conocido problema de sensibilidad de parámetros (también conocido como "olfateo de parámetros").
El valor de P (páginas de hoja de índice) no se actualiza al comienzo de cada declaración. La implementación actual almacena en caché el valor de todo el lote . Esto puede tener efectos secundarios inesperados. Por ejemplo, una TRUNCATE TABLE en el mismo lote como INSERT...SELECT no restablecerá P a cero para los cálculos descritos en este artículo; seguirán usando el valor pretruncado y una recompilación no ayudará. Una solución consiste en enviar cambios grandes en lotes separados.
Banderas de rastreo
Es posible forzar FDemandRowsSortedForPerformance para devolver verdadero configurando undocumented and unsupported trace flag 2332, como escribí en Optimización de consultas T-SQL que cambian datos. Cuando TF 2332 está activo, el número de filas estimadas para insertar aún debe ser al menos 100 . TF 2332 afecta al registro mínimo decisión para FastLoadContext solo (es efectivo para montones particionados hasta DMLRequestSort se refiere, pero no tiene efecto en el montón en sí, ya que FastLoadContext solo se aplica a los índices).
A ancho/por índice La forma del plan para el mantenimiento de índices no agrupados se puede forzar para las tablas de almacén de filas utilizando el indicador de seguimiento 8790 (no documentado oficialmente, pero mencionado en un artículo de la base de conocimientos, así como en mi artículo vinculado a TF2332 justo arriba).
Lectura relacionada
Todo por Sunil Agarwal del equipo de SQL Server:
- ¿Qué son las optimizaciones de importación masiva?
- Optimizaciones de importación masiva (registro mínimo)
- Cambios mínimos de registro en SQL Server 2008
- Cambios mínimos de registro en SQL Server 2008 (parte 2)
- Cambios mínimos de registro en SQL Server 2008 (parte 3)