He tenido muchas conversaciones recientemente sobre los tipos de cargas de trabajo, específicamente sobre cómo comprender si una carga de trabajo está parametrizada, es ad hoc o es una combinación. Es una de las cosas que observamos durante una auditoría de estado, y Kimberly tiene una excelente consulta de su caché de Plan y una publicación de optimización para cargas de trabajo ad hoc que es parte de nuestro conjunto de herramientas. He copiado la consulta a continuación, y si nunca antes la ha ejecutado en ninguno de sus entornos de producción, definitivamente busque algo de tiempo para hacerlo.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Si ejecuto esta consulta en un entorno de producción, es posible que obtengamos un resultado como el siguiente:
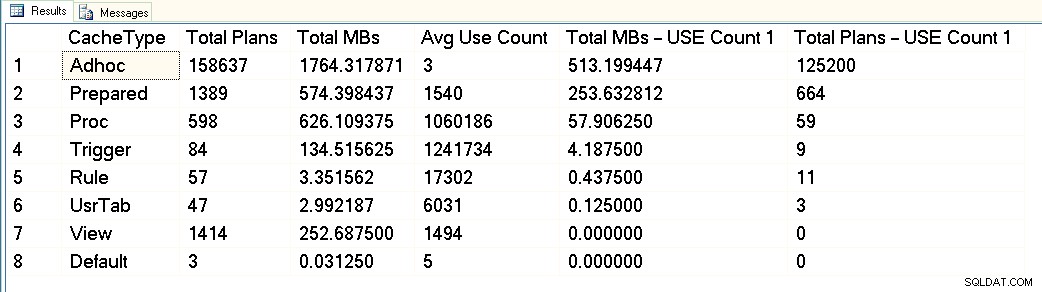
En esta captura de pantalla, puede ver que tenemos alrededor de 3 GB en total dedicados al caché del plan, y de esos 1,7 GB son para los planes de más de 158 000 consultas ad hoc. De esos 1,7 GB, aproximadamente 500 MB se utilizan para 125 000 planes que ejecutan ONE tiempo solo. Aproximadamente 1 GB del caché del plan es para planes preparados y de procedimientos, y solo ocupan alrededor de 300 MB de espacio. Pero tenga en cuenta el recuento de uso promedio:más de 1 millón para procedimientos. Al observar este resultado, categorizaría esta carga de trabajo como mixta:algunas consultas parametrizadas, algunas adhoc.
La publicación de blog de Kimberly analiza las opciones para administrar un caché de plan lleno de muchas consultas ad hoc. Planear el exceso de caché es solo un problema con el que tiene que lidiar cuando tiene una carga de trabajo ad hoc, y en esta publicación quiero explorar el efecto que puede tener en la CPU como resultado de todas las compilaciones que deben ocurrir. Cuando una consulta se ejecuta en SQL Server, pasa por compilación y optimización, y hay una sobrecarga asociada con este proceso, que con frecuencia se manifiesta como costo de CPU. Una vez que un plan de consulta está en caché, se puede reutilizar. Las consultas que están parametrizadas pueden terminar reutilizando un plan que ya está en caché, porque el texto de la consulta es exactamente el mismo. Cuando se ejecuta una consulta ad hoc, solo reutilizará el plan en caché si tiene el exacto mismo texto y valores de entrada .
Configuración
Para nuestras pruebas, generaremos una cadena aleatoria en TSQL y la concatenaremos a una consulta para que cada ejecución tenga un valor literal diferente. Envolví esto en un procedimiento almacenado que llama a la consulta usando Dynamic String Execution (EXEC @QueryString), por lo que se comporta como una declaración ad hoc. Llamarlo desde dentro de un procedimiento almacenado significa que podemos ejecutarlo un número conocido de veces.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
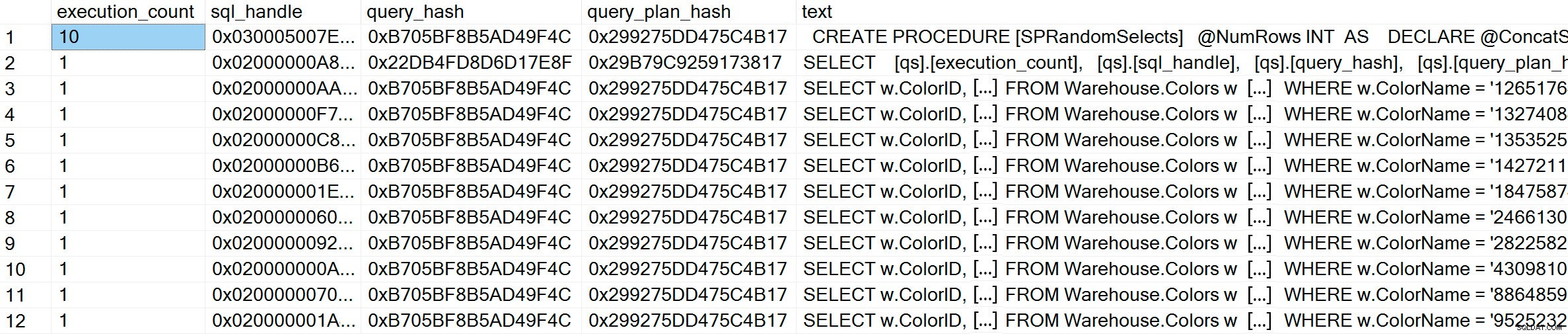
GO Después de ejecutar, si revisamos el caché del plan, podemos ver que tenemos 10 entradas únicas, cada una con un recuento_ejecución de 1 (amplía la imagen si es necesario para ver los valores únicos del predicado):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Ahora creamos un procedimiento almacenado casi idéntico que ejecuta la misma consulta, pero parametrizado:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO Dentro del caché del plan, además de las 10 consultas ad hoc, vemos una entrada para la consulta parametrizada que se ha ejecutado 10 veces. Debido a que la entrada está parametrizada, incluso si se pasan cadenas muy diferentes al parámetro, el texto de consulta es exactamente el mismo:
Pruebas
Ahora que entendemos lo que sucede en el caché del plan, creemos más carga. Usaremos un archivo de línea de comando que llama al mismo archivo .sql en 10 subprocesos diferentes, y cada archivo llama al procedimiento almacenado 10 000 veces. Borraremos la memoria caché del plan antes de comenzar y capturaremos el % de CPU total y las compilaciones de SQL por segundo con PerfMon mientras se ejecutan los scripts.
Contenido del archivo adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Contenido del archivo parametrizado.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
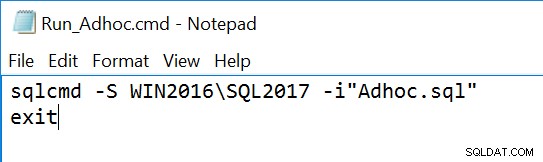
Archivo de comando de ejemplo (visto en el Bloc de notas) que llama al archivo .sql:
Archivo de comando de ejemplo (visto en el Bloc de notas) que crea 10 subprocesos, cada uno de los cuales llama al archivo Run_Adhoc.cmd:
Después de ejecutar cada conjunto de consultas 100 000 veces en total, si observamos el caché del plan, vemos lo siguiente:

Hay más de 10 000 planes ad hoc en la caché de planes. Quizás se pregunte por qué no hay un plan para las 100 000 consultas ad hoc que se ejecutaron, y tiene que ver con cómo funciona la memoria caché del plan (su tamaño se basa en la memoria disponible, cuando caducan los planes no utilizados, etc.). Lo que es crítico es que entonces existen muchos planes ad hoc, en comparación con lo que vemos para el resto de los tipos de caché.
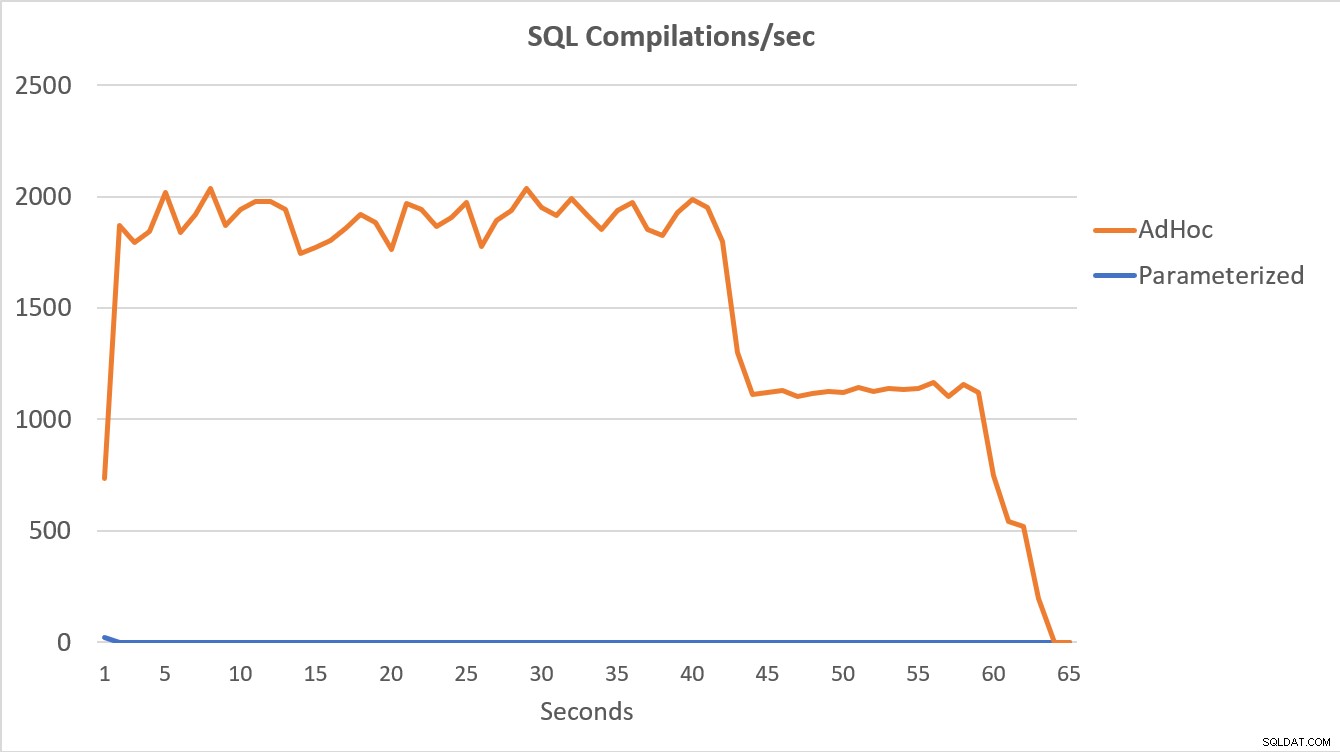
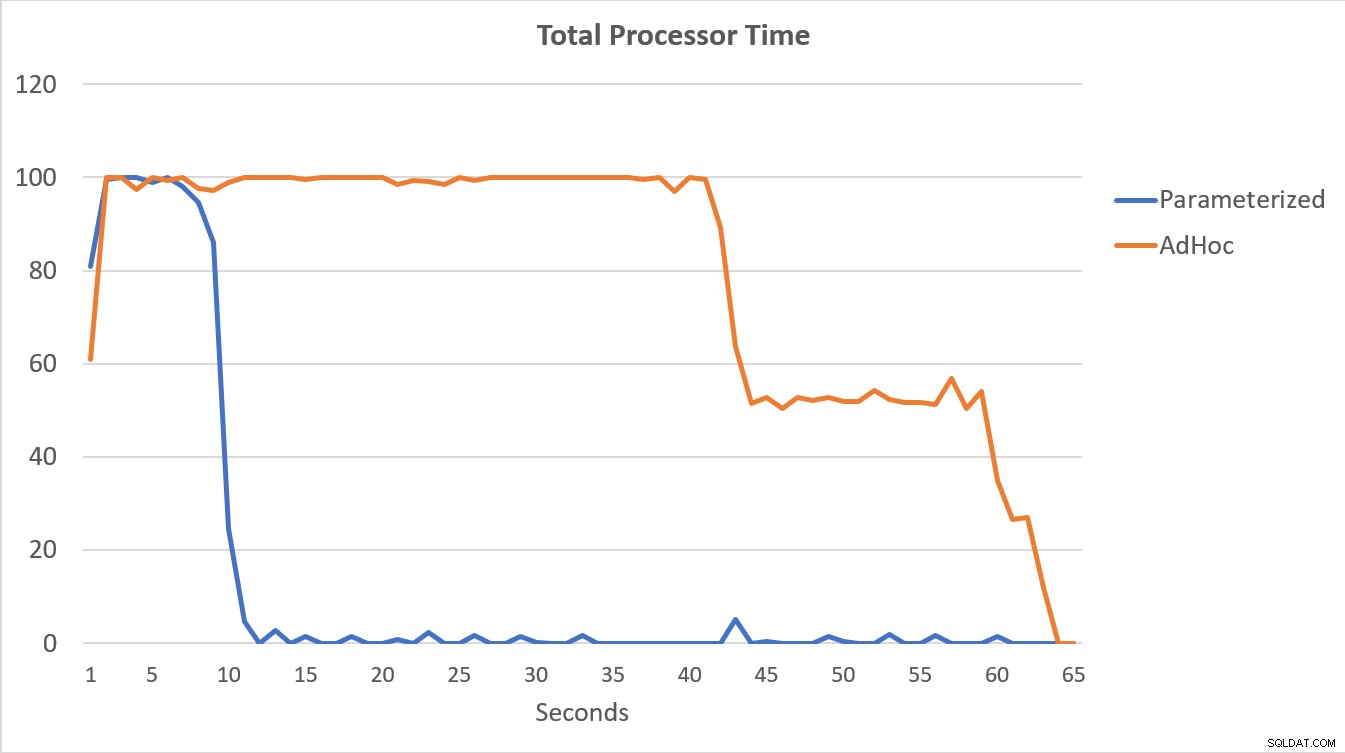
Los datos de PerfMon, graficados a continuación, son muy reveladores. La ejecución de las 100 000 consultas parametrizadas se completó en menos de 15 segundos y hubo un pequeño pico en Compilaciones/seg al principio, que apenas se nota en el gráfico. La misma cantidad de ejecuciones ad hoc tardaron un poco más de 60 segundos en completarse, con compilaciones por segundo aumentando cerca de 2000 antes de caer cerca de 1000 alrededor de la marca de 45 segundos, con CPU cerca o al 100 % durante la mayor parte del tiempo.
Resumen
Nuestra prueba fue extremadamente simple ya que solo enviamos variaciones para uno consulta adhoc, mientras que en un entorno de producción, podríamos tener cientos o miles de variaciones diferentes para cientos o miles de diferentes consultas ad hoc. El impacto en el rendimiento de estas consultas ad hoc no es solo el aumento de la caché del plan que se produce, aunque la caché del plan es un excelente lugar para comenzar si no está familiarizado con el tipo de carga de trabajo que tiene. Un gran volumen de consultas ad hoc puede impulsar las compilaciones y, por lo tanto, la CPU, que a veces se puede enmascarar agregando más hardware, pero puede llegar un punto en el que la CPU se convierta en un cuello de botella. Si cree que esto podría ser un problema, o un problema potencial, en su entorno, busque identificar qué consultas ad hoc se ejecutan con más frecuencia y vea qué opciones tiene para parametrizarlas. No me malinterpreten:existen problemas potenciales con las consultas parametrizadas (p. ej., la estabilidad del plan debido a la asimetría de los datos), y ese es otro problema con el que tendrá que trabajar. Independientemente de su carga de trabajo, es importante comprender que rara vez existe un método de "configúrelo y olvídese" para la codificación, la configuración, el mantenimiento, etc. realizar de forma fiable. Una de las tareas de un DBA es estar al tanto de ese cambio y gestionar el rendimiento lo mejor posible, ya sea relacionado con desafíos de rendimiento ad hoc o parametrizados.