A principios de este mes, publiqué un consejo sobre algo que probablemente todos desearíamos no tener que hacer:ordenar o eliminar duplicados de cadenas delimitadas, que generalmente involucran funciones definidas por el usuario (UDF). A veces es necesario volver a ensamblar la lista (sin los duplicados) en orden alfabético y, a veces, es posible que deba mantener el orden original (podría ser la lista de columnas clave en un índice incorrecto, por ejemplo).
Para mi solución, que aborda ambos escenarios, utilicé una tabla de números, junto con un par de funciones definidas por el usuario (UDF):una para dividir la cadena y la otra para volver a ensamblarla. Puedes ver ese consejo aquí:
- Eliminar duplicados de cadenas en SQL Server
Por supuesto, hay múltiples formas de resolver este problema; Simplemente estaba proporcionando un método para probar si está atascado con esa estructura de datos. @Phil_Factor de Red-Gate siguió con una publicación rápida que muestra su enfoque, que evita las funciones y la tabla de números, optando en su lugar por la manipulación XML en línea. Dice que prefiere tener consultas de una sola declaración y evitar tanto las funciones como el procesamiento fila por fila:
- Desduplicación de listas delimitadas en SQL Server
Luego, un lector, Steve Mangiameli, publicó una solución de bucle como comentario en la sugerencia. Su razonamiento fue que el uso de una tabla de números le parecía demasiado diseñado.
Ninguno de nosotros tres abordó un aspecto de esto que generalmente será bastante importante si está realizando la tarea con la suficiente frecuencia o en cualquier nivel de escala: rendimiento .
Pruebas
Curioso por ver qué tan bien funcionarían los enfoques de bucle y XML en línea en comparación con mi solución basada en tablas de números, construí una tabla ficticia para realizar algunas pruebas; mi objetivo era 5000 filas, con una longitud de cadena promedio de más de 250 caracteres y al menos 10 elementos en cada cadena. Con un ciclo muy corto de experimentos, pude lograr algo muy parecido a esto con el siguiente código:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Esto produjo una tabla con filas de muestra con este aspecto (valores truncados):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Los datos en su conjunto tenían el siguiente perfil, que debería ser lo suficientemente bueno para descubrir posibles problemas de rendimiento:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Tenga en cuenta que cambié a varchar aquí desde nvarchar en el artículo original, porque las muestras que Phil y Steve proporcionaron asumieron varchar , cadenas con un límite de solo 255 u 8000 caracteres, delimitadores de un solo carácter, etc. Aprendí mi lección de la manera más difícil, que si va a tomar la función de alguien e incluirla en las comparaciones de rendimiento, cambie tan poco como posible – idealmente nada. En realidad, siempre usaría nvarchar y no asumir nada sobre la cadena más larga posible. En este caso, sabía que no estaba perdiendo ningún dato porque la cadena más larga tiene solo 2905 caracteres, y en esta base de datos no tengo tablas ni columnas que usen caracteres Unicode.
A continuación, creé mis funciones (que requieren una tabla de números). Un lector detectó un problema en la función de mi sugerencia, donde asumí que el delimitador siempre sería un solo carácter, y lo corregí aquí. También convertí casi todo a varchar(8000) para nivelar el campo de juego en términos de tipos y longitudes de cuerdas.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO A continuación, creé una sola función con valores de tabla en línea que combinaba las dos funciones anteriores, algo que ahora desearía haber hecho en el artículo original, para evitar la función escalar por completo. (Si bien es cierto que no todos las funciones escalares son terribles a escala, hay muy pocas excepciones).
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
También creé versiones separadas del TVF en línea que se dedicaron a cada una de las dos opciones de clasificación, para evitar la volatilidad del CASE expresión, pero resultó no tener un impacto dramático en absoluto.
Luego creé las dos funciones de Steve:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Luego puse las consultas directas de Phil en mi plataforma de prueba (tenga en cuenta que sus consultas codifican < como < para protegerlos de errores de análisis XML, pero no codifican > o & – He agregado marcadores de posición en caso de que necesite protegerse contra cadenas que puedan contener potencialmente esos caracteres problemáticos):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
El equipo de prueba consistía básicamente en esas dos consultas y también en las siguientes llamadas a funciones. Una vez que verifiqué que todos devolvían los mismos datos, intercalé el script con DATEDIFF salida y lo registró en una tabla:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Y luego realicé pruebas de rendimiento en dos sistemas diferentes (uno de cuatro núcleos con 8 GB y una máquina virtual de 8 núcleos con 32 GB), y en cada caso, tanto en SQL Server 2012 como en SQL Server 2016 CTP 3.2 (13.0.900.73).
Resultados
Los resultados que observé se resumen en el siguiente gráfico, que muestra la duración en milisegundos de cada tipo de consulta, promediada en orden alfabético y original, las cuatro combinaciones de servidor/versión y una serie de 15 ejecuciones para cada permutación. Haga clic para ampliar:
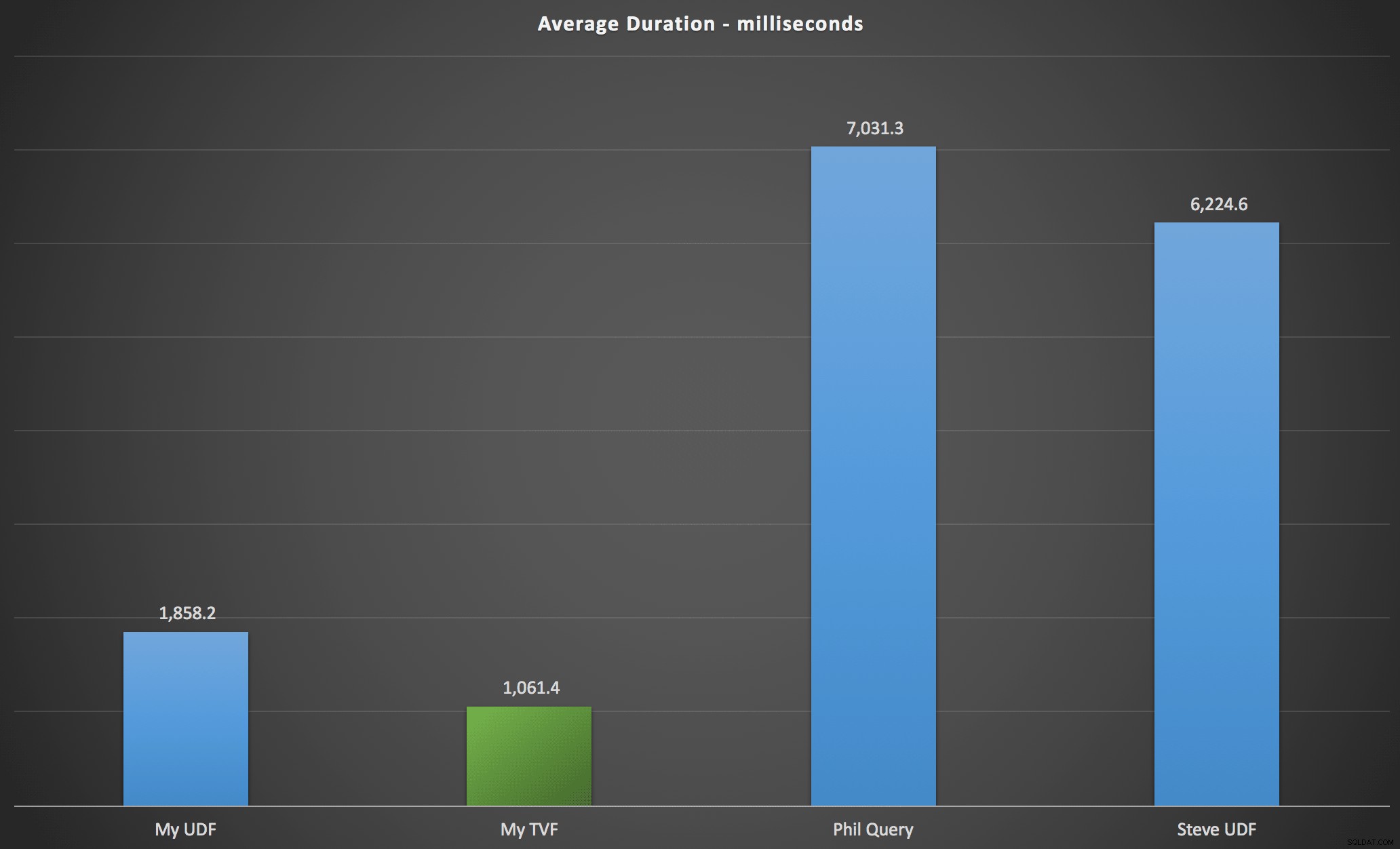
Esto muestra que la tabla de números, aunque se consideró sobrediseñada, en realidad arrojó la solución más eficiente (al menos en términos de duración). Esto fue mejor, por supuesto, con el único TVF que implementé más recientemente que con las funciones anidadas del artículo original, pero ambas soluciones dan vueltas alrededor de las dos alternativas.
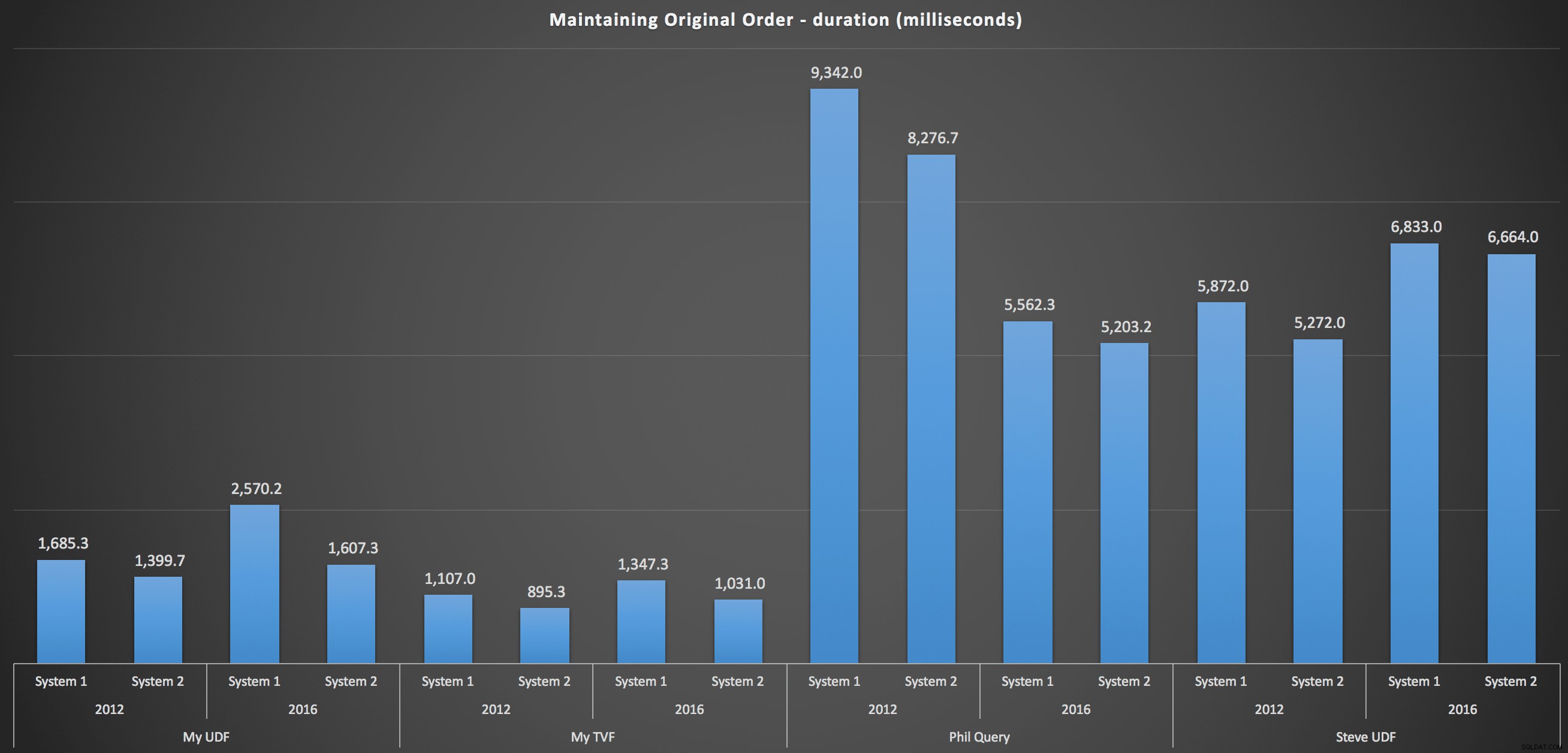
Para entrar en más detalles, aquí están los desgloses para cada máquina, versión y tipo de consulta, para mantener el orden original:
…y para volver a armar la lista en orden alfabético:
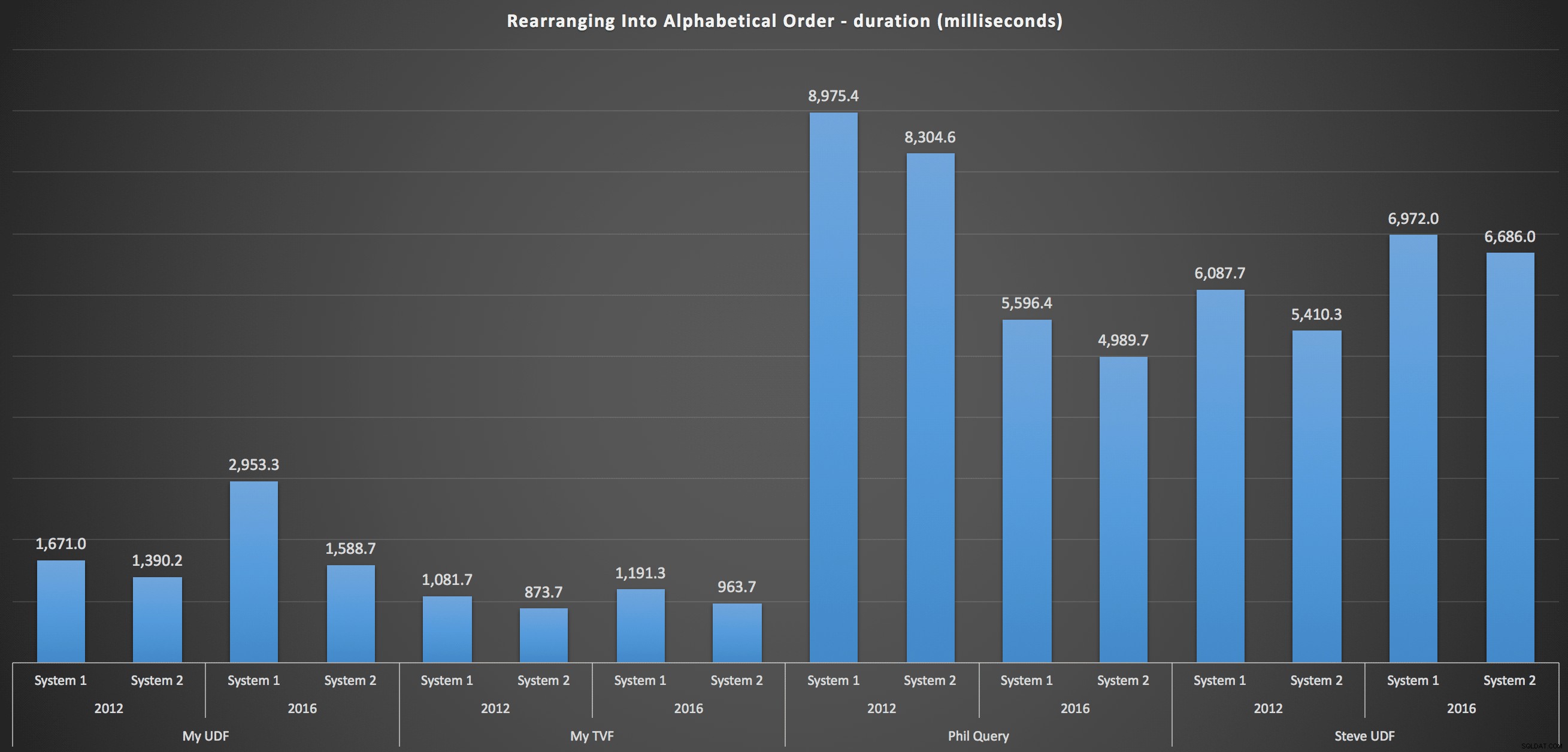
Estos muestran que la elección de clasificación tuvo poco impacto en el resultado:ambos gráficos son prácticamente idénticos. Y eso tiene sentido porque, dada la forma de los datos de entrada, no hay ningún índice que pueda imaginar que haga que la clasificación sea más eficiente:es un enfoque iterativo sin importar cómo lo divida o cómo devuelva los datos. Pero está claro que algunos enfoques iterativos pueden ser generalmente peores que otros, y no es necesariamente el uso de un UDF (o una tabla de números) lo que los hace así.
Conclusión
Hasta que tengamos la funcionalidad nativa de división y concatenación en SQL Server, usaremos todo tipo de métodos poco intuitivos para realizar el trabajo, incluidas las funciones definidas por el usuario. Si está manejando una sola cadena a la vez, no verá mucha diferencia. Pero a medida que sus datos aumenten, valdrá la pena probar varios enfoques (y de ninguna manera estoy sugiriendo que los métodos anteriores sean los mejores que encontrará; ni siquiera miré CLR, por ejemplo, o otros enfoques T-SQL de esta serie).